Access History est une vue de la base de données Snowflake qui figure parmi les datasets les plus utiles pour auditer et analyser l'utilisation de votre compte Snowflake. Dans cet article, je détaille les données contenues dans Access History, puis je partage plusieurs exemples concrets que vous pouvez exécuter dès aujourd'hui dans votre compte.
Que contient Snowflake Access History ?
Access History contient une ligne par requête exécutée dans votre compte. Pour chaque requête, plusieurs colonnes décrivent les objets consultés et/ou modifiés.
Pour commencer, trois colonnes sont particulièrement pratiques pour retrouver les requêtes qui vous intéressent :
query_id: l'identifiant unique de la requêteuser_name: l'utilisateur ayant exécuté la requêtequery_start_time: l'heure de démarrage de la requête
Si vous avez besoin d'informations supplémentaires, par exemple le rôle utilisé ou le warehouse sur lequel la requête s'est exécutée, vous pouvez joindre Access History à la vue Snowflake Query History.
Concernant les objets consultés par la requête, la vue fournit deux colonnes :
direct_objects_accessed: un tableau JSON des objets de données auxquels la requête accède directementbase_objects_accessed: un tableau JSON des objets de données auxquels la requête accède directement ou indirectement (par exemple, les tables sous-jacentes qui alimentent une vue)
Pour les objets modifiés par une requête, deux colonnes sont disponibles :
objects_modified: un tableau JSON qui précise les objets modifiés par une requête. Cette colonne est renseignée pour les requêtes de typeINSERT,UPDATE,MERGE,CREATEou similaires, qui mettent à jour, insèrent ou suppriment des enregistrements dans une tableobjects_modified_by_ddl: contient les informations relatives à l'opération DDL appliquée à une base de données, un schéma, une table, une vue et/ou une colonne.
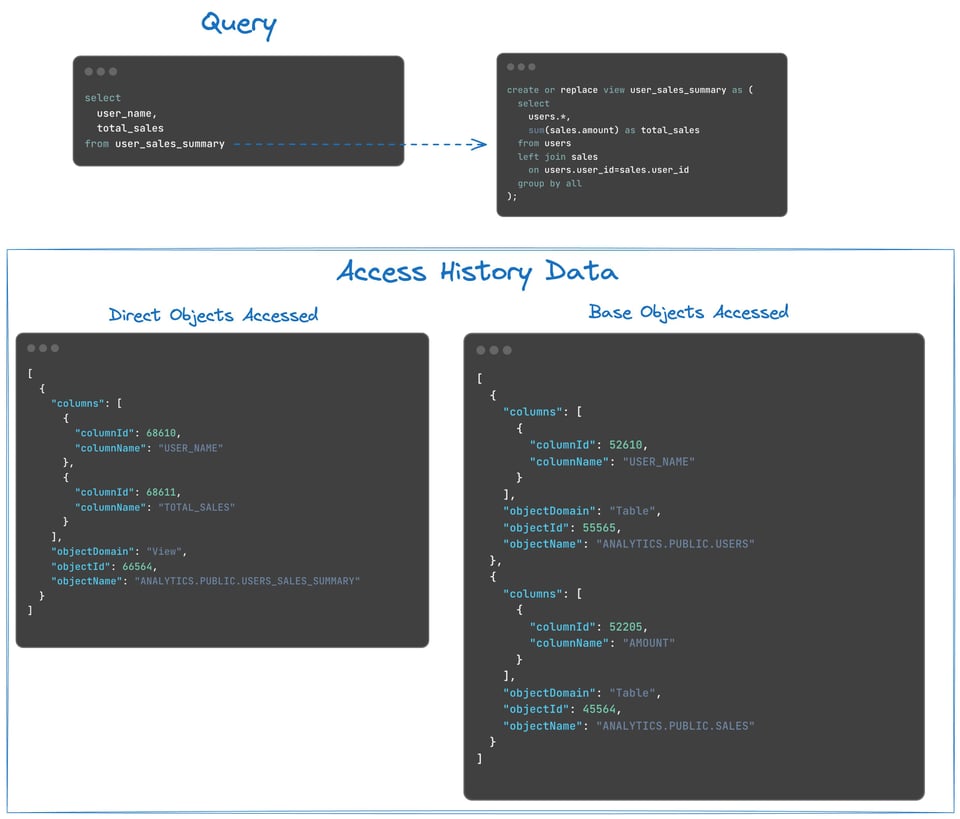
Direct vs. Base Objects Accessed
Pour saisir la différence entre direct objects accessed et base objects accessed, prenons la requête suivante, qui accède à deux colonnes d'une vue nommée user_sales_summary :
select
user_name,
total_sales
from user_sales_summary
La colonne direct_objects_accessed contiendra une entrée correspondant à l'accès direct à la vue user_sales_summary, tandis que la colonne base_objects_accessed contiendra deux entrées pour les deux tables sous-jacentes (users et sales) qui alimentent la vue.
Rétention des données Access History
Comme pour les autres vues d'utilisation du compte, telles que Snowflake Query History, Snowflake conserve les données des 365 derniers jours.
Access History est-elle disponible pour tous les clients Snowflake ?
La vue Access History n'est accessible qu'aux clients Snowflake disposant d'une édition Snowflake Enterprise ou supérieure.
Maintenant que les bases sont posées, passons à des exemples concrets que vous pouvez exécuter dans votre compte pour répondre à diverses questions courantes.
1\. Trouver toutes les tables consultées par un utilisateur donné sur les 30 derniers jours
La requête ci-dessous montre comment lister toutes les tables consultées par un utilisateur donné sur les 30 derniers jours. La colonne base_objects_accessed étant un tableau, il faut utiliser une jointure lateral combinée à la fonction de table flatten pour éclater chaque entrée du tableau sur une ligne distincte. Vous retrouverez ce pattern tout au long de l'article.
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30
)
Développer le code
Notez le filtre sur object_domain='Table'. Vous pouvez l'ajuster pour répondre à des questions connexes :
- Quelles vues un utilisateur a-t-il consultées ?
- Quelles fonctions a-t-il utilisées ?
2\. Trouver toutes les tables consultées dans un schéma
Pour lister toutes les tables consultées dans un schéma précis, on s'appuie sur la CTE access_history_flattened vue plus haut. Le object_name renvoyé par Access History est toujours le nom pleinement qualifié, sous la forme database_name.schema_name.table_name. Il suffit donc de parser ce nom pour en extraire la base et le schéma, puis d'appliquer le filtre voulu :
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
),
access_history_flattened_w_names as (
select
Développer le code
3\. Lister tous les utilisateurs ayant consulté une table donnée sur les 30 derniers jours
Imaginons que vous cherchiez à identifier les utilisateurs susceptibles d'avoir consulté des données sensibles dans une table. La vue Access History permet d'obtenir rapidement la liste complète des utilisateurs concernés :
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30 -- adjust as needed
),
Développer le code
4\. Identifier les tables inutilisées
J'ai déjà publié un article sur la façon d'identifier les tables inutilisées grâce à la vue Access History. Reportez-vous à ce billet pour une explication détaillée. Voici le code à utiliser :
with
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectId::integer as table_id,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from snowflake.account_usage.access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
),
table_access_history as (
select
Développer le code
5\. Identifier les vues inutilisées
On adapte facilement la requête précédente pour identifier les vues restées inutilisées sur les 30 derniers jours. Il suffit de remplacer object_domain = 'Table' par object_domain = 'View' :
with
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectId::integer as table_id,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from snowflake.account_usage.access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
),
table_access_history as (
select
Développer le code
6\. Identifier les colonnes les plus consultées dans une table donnée
Les exemples précédents portaient uniquement sur l'accès aux tables et aux schémas. On peut aller plus loin et analyser l'utilisation des colonnes d'une table en exploitant le tableau columns présent dans les champs base/direct_objects_accessed. En ajoutant un lateral flatten supplémentaire, on obtient un dataset avec une ligne par colonne consultée dans une requête (voir la CTE access_history_flattened_columns).
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30 -- adjust as needed
),
Développer le code
7\. Lister tous les utilisateurs ayant consulté une colonne précise sur les 30 derniers jours
En partant de l'exemple précédent, on identifie aisément les utilisateurs ayant consulté une colonne spécifique :
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30 -- adjust as needed
),
Développer le code
8\. Identifier toutes les requêtes ayant modifié une table
Lorsque vous cherchez à comprendre pourquoi ou comment une table a évolué, il est précieux de retrouver rapidement les requêtes ou les utilisateurs qui l'ont modifiée. Vous voulez peut-être aussi suivre la fréquence des mises à jour d'une table. En reprenant les approches précédentes, on identifie toutes les requêtes ayant modifié une table en aplatissant la colonne objects_modified :
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_modified.value:objectName::text as object_name,
objects_modified.value:objectDomain::text as object_domain
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.objects_modified) as objects_modified
where
access_history.query_start_time > current_date - 30 -- adjust as needed
)
select
Développer le code
Ian Whitestone·Co-founder & CEO of SELECT
Ian est cofondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, il a passé 6 ans à diriger des équipes full stack de data science et d'engineering chez Shopify et Capital One. Chez Shopify, il a piloté l'optimisation du data warehouse et le renforcement de l'observabilité des coûts.