Access History è una view del database Snowflake e rappresenta uno dei dataset più utili per fare l'audit dell'utilizzo del tuo account Snowflake e comprenderlo a fondo. In questo post vedremo nel dettaglio quali dati contiene l'access history e condivideremo diversi esempi che puoi eseguire subito nel tuo account.
Cosa contiene la Snowflake Access History?
L'Access History contiene 1 riga per ogni query eseguita nel tuo account. Per ciascuna query memorizza una serie di colonne relative agli oggetti consultati e/o modificati dalla query stessa.
Innanzitutto, ci sono tre colonne utili per individuare le query di interesse:
query_id: l'identificatore univoco della queryuser_name: l'utente che ha eseguito la queryquery_start_time: il momento in cui la query è stata avviata
Se servono ulteriori informazioni sulla query, come il ruolo con cui è stata eseguita o il warehouse su cui è stata lanciata, puoi unire il dataset access history alla view Snowflake Query History.
Per quanto riguarda gli oggetti consultati dalla query, la view mette a disposizione due colonne:
direct_objects_accessed: un array JSON degli oggetti dati a cui la query accede direttamentebase_objects_accessed: un array JSON degli oggetti dati a cui la query accede direttamente o indirettamente (ad esempio le tabelle sottostanti che alimentano una view)
Per gli oggetti modificati da una query, ci sono due colonne:
objects_modified: un array JSON che indica gli oggetti modificati da una query. Viene popolato per query di tipoINSERT,UPDATE,MERGE,CREATEo simili, che aggiornano/inseriscono/eliminano record in una tabellaobjects_modified_by_ddl: contiene informazioni sull'operazione DDL eseguita su un database, schema, tabella, view e/o colonna.
Direct vs. Base Objects Accessed
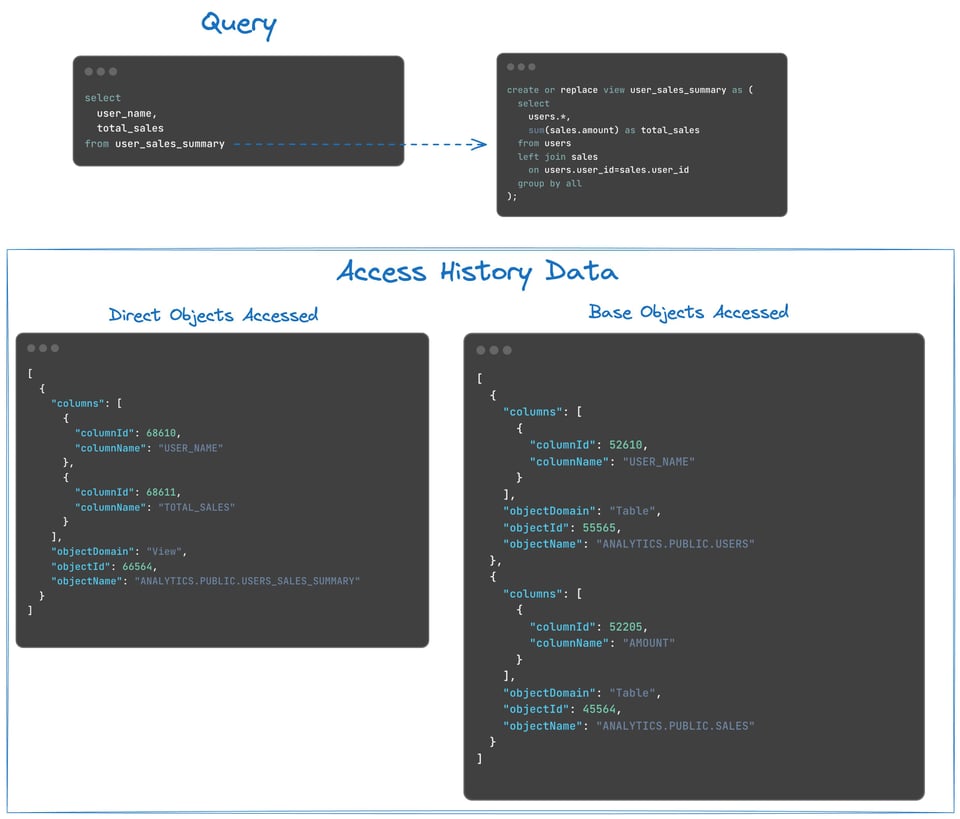
Per capire la differenza tra direct e base objects accessed, considera la seguente query, che accede a due colonne di una view chiamata user_sales_summary:
select
user_name,
total_sales
from user_sales_summary
La colonna direct_objects_accessed conterrà 1 voce relativa all'accesso diretto alla view user_sales_summary, mentre la colonna base_objects_accessed conterrà due voci per le due tabelle sottostanti (users e sales) che alimentano la view.
Conservazione dei dati dell'Access History
Come per altre view di account usage quali la Snowflake Query History, Snowflake conserva i dati degli ultimi 365 giorni.
L'Access History è disponibile per tutti i clienti Snowflake?
La view access history è disponibile solo per i clienti Snowflake con edizione Snowflake Enterprise o superiore.
Ora che abbiamo visto le basi, passiamo ad alcuni esempi concreti che puoi eseguire nel tuo account per rispondere a diverse domande ricorrenti.
1\. Trovare tutte le tabelle consultate da un determinato utente negli ultimi 30 giorni
La query seguente mostra come trovare tutte le tabelle consultate da un determinato utente negli ultimi 30 giorni. Poiché la colonna base_objects_accessed è un array, dobbiamo usare un join lateral in combinazione con la table function flatten, in modo da espandere ogni voce dell'array in una riga separata. È un pattern che ritroverai più volte in questo post.
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30
)
Espandi codice
Nota il filtro su object_domain='Table'. Puoi adattarlo in base alle esigenze per rispondere a domande analoghe, ad esempio:
- Quali view ha consultato un utente?
- Quali funzioni ha utilizzato?
2\. Trovare tutte le tabelle consultate in uno schema
Per trovare tutte le tabelle consultate in un determinato schema, possiamo sfruttare la CTE access_history_flattened vista sopra. L'object_name presente nell'Access History è sempre il nome completamente qualificato, ossia nel formato database_name.schema_name.table_name. Di conseguenza, ne facciamo il parsing per ricavare il nome del database e dello schema, e poi filtriamo come serve:
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
),
access_history_flattened_w_names as (
select
Espandi codice
3\. Ottenere tutti gli utenti che hanno consultato una specifica tabella negli ultimi 30 giorni
Immagina di voler individuare gli utenti che potrebbero aver consultato dati sensibili in una tabella. Puoi sfruttare la view access_history per ottenere rapidamente l'elenco completo degli utenti:
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30 -- adjust as needed
),
Espandi codice
4\. Individuare le tabelle inutilizzate
In un articolo precedente ho spiegato come individuare le tabelle inutilizzate sfruttando la view access history. Per una spiegazione dettagliata puoi fare riferimento a quel post. Di seguito il codice da utilizzare:
with
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectId::integer as table_id,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from snowflake.account_usage.access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
),
table_access_history as (
select
Espandi codice
5\. Individuare le view inutilizzate
Possiamo modificare facilmente la query precedente per individuare le view non utilizzate negli ultimi 30 giorni. Basta cambiare object_domain = 'Table' in object_domain = 'View':
with
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectId::integer as table_id,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from snowflake.account_usage.access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
),
table_access_history as (
select
Espandi codice
6\. Individuare le colonne più consultate in una determinata tabella
Finora gli esempi hanno riguardato esclusivamente l'accesso a tabelle e schemi. Possiamo però scendere di un livello e analizzare l'utilizzo delle colonne per una determinata tabella, sfruttando l'array columns presente nei campi base/direct_objects_accessed. Con un ulteriore lateral flatten otteniamo un dataset con 1 riga per ogni colonna consultata in una query (vedi la CTE access_history_flattened_columns).
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30 -- adjust as needed
),
Espandi codice
7\. Ottenere tutti gli utenti che hanno consultato una specifica colonna negli ultimi 30 giorni
Partendo dall'esempio precedente, possiamo individuare facilmente gli utenti che hanno consultato una colonna specifica:
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_accessed.value:objectName::text as object_name,
objects_accessed.value:objectDomain::text as object_domain,
objects_accessed.value:columns as columns_array
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.base_objects_accessed) as objects_accessed
where
access_history.query_start_time > current_date - 30 -- adjust as needed
),
Espandi codice
8\. Individuare tutte le query che hanno modificato una tabella
Quando si indaga sul perché o sul come una determinata tabella sia cambiata, può essere utile individuare rapidamente le query o gli utenti che hanno modificato l'oggetto. Oppure, magari, vuoi capire con quale frequenza una tabella viene aggiornata. Con un approccio simile a quelli visti sopra, possiamo individuare tutte le query che hanno modificato una tabella facendo il flatten della colonna objects_modified:
with
-- This will output 1 row per table accessed in a query
access_history_flattened as (
select
access_history.query_id,
access_history.query_start_time,
access_history.user_name,
objects_modified.value:objectName::text as object_name,
objects_modified.value:objectDomain::text as object_domain
from admin.audit.access_history_last_30d as access_history, lateral flatten(access_history.objects_modified) as objects_modified
where
access_history.query_start_time > current_date - 30 -- adjust as needed
)
select
Espandi codice
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder & CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha guidato il lavoro di ottimizzazione del data warehouse e di miglioramento dell'osservabilità dei costi.