In einem früheren Beitrag haben wir gezeigt, wie sich mit Snowflake Query Tags & Comments beliebige Metadaten an jede Query hängen lassen. In diesem Beitrag zeigen wir, wie Sie Query Tags oder Comments an Ihren dbt-Modellen nutzen, um deren Kosten und Performance über die Zeit zu verfolgen.
Warum Kosten & Performance von dbt-Modellen überwachen?
dbt hat in den letzten fünf Jahren einen regelrechten Höhenflug hingelegt und ist heute das verbreitetste Framework, um Datenmodelle direkt im Data Warehouse aufzubauen und zu pflegen. Umfangreiche Transformationen auf großen Datenmengen im Warehouse sind allerdings alles andere als günstig. Ob mit dbt oder einem anderen SQL-basierten Transformationstool: Die Kosten dieser Transformationen machen bei Snowflake-Kunden typischerweise einen erheblichen Teil der Compute-Ausgaben aus.
Wer seine Data-Cloud-Ausgaben besser verstehen, überwachen und senken will, braucht zunehmend detaillierte Einblicke in die Kosten jedes einzelnen dbt-Modells. Hinzu kommt: Je mehr dbt geschäftskritische Anwendungen und Entscheidungen antreibt, desto wichtiger wird das Performance-Monitoring der Modelle, um SLAs zuverlässig einzuhalten.
Bei Snowflake und dbt sind diese zentralen Monitoring-Funktionen nicht ab Werk dabei. Mit Metadaten über Query Tags oder Comments lassen sich diese Funktionen aber selbst nachrüsten.
Query Tags in dbt setzen
In unserem Beitrag zu Query Tags haben wir die drei Möglichkeiten zum Setzen von Query Tags in dbt beschrieben:
- Global in der
profiles.ymlsetzen - Pro Modell ein
query_tagin derdbt_project.ymloder in der Model-Config hinzufügen - Ein
set_query_tag-Macro anlegen, das das Query Tag für jedes Modell im Projekt dynamisch setzt.
Variante 3 ist klar die beste, weil sie das manuelle Setzen der Tags überflüssig macht. Wenn Sie dynamische Query Tags pro Modell einführen möchten, können Sie ein eigenes Macro umsetzen – zum Beispiel das hier verlinkte – und so jeder dbt-Query detaillierte Metadaten mitgeben.
Query Comments in dbt setzen (empfohlener Ansatz)
Für dbt-bezogene Metadaten empfehlen wir Query Comments statt Query Tags, denn die automatisch erzeugten Metadaten überschreiten gelegentlich das 2000-Zeichen-Limit der Query Tags.
dbt bringt diese Einstellung von Haus aus mit. In Ihrer dbt_project.yml ergänzen Sie einfach:
1query-comment: append: true # Snowflake removes prefixed comments
Damit wird am Ende jeder Query ein Query Comment angehängt:
1create view analytics.analytics.orders as ( select ... ); /* {"app": "dbt", "dbt_version": "0.15.0rc2", "profile_name": "debug", "target_name": "dev", "node_id": "model.dbt2.my_model"} */
Für umfangreichere Metadaten im Query Comment können Sie unser Query-Package dbt-snowflake-monitoring installieren. Es stellt für alle dbt-Queries folgende Metadaten bereit:
1{ "dbt_snowflake_query_tags_version": "2.0.0", "app": "dbt", "dbt_version": "1.4.0", "project_name": "my_project", "target_name": "dev", "target_database": "dev", "target_schema": "larry_goldings", "invocation_id": "c784c7d0-5c3f-4765-805c-0a377fefcaa0", "node_name": "orders", "node_alias": "orders", "node_package_name": "my_project", "node_original_file_path": "models/staging/orders.sql", "node_database": "dev", "node_schema": "mart", "node_id": "model.my_project.orders", "node_resource_type": "model", "materialized": "incremental", "is_incremental": true, "node_refs": [ "raw_orders", "product_mapping" ], "dbt_cloud_project_id": "146126", "dbt_cloud_job_id": "184124", "dbt_cloud_run_id": "107122910", "dbt_cloud_run_reason_category": "other", "dbt_cloud_run_reason": "Kicked off from UI by [email protected]", }
Auf dieser Basis lassen sich Kosten und Performance entlang vieler relevanter Dimensionen auswerten – etwa nach dbt-Projekt, Modellname, Umgebung (dev oder prod), Materialisierungstyp und mehr.
Performance von dbt-Modellen überwachen
Mit Query Tags lässt sich die Performance Ihrer dbt-Modelle über eine Variante der folgenden Query überwachen:
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. from snowflake.account_usage.query_history where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Bei Query Comments müssen Sie die Metadaten zunächst aus dem Kommentartext parsen:
1with query_history as ( select *, regexp_substr(query_text, '/\\*\\s({"app":\\s"dbt".*})\\s\\*/', 1, 1, 'ie') as _dbt_json_meta, try_parse_json(_dbt_json_meta) as dbt_metadata from snowflake.account_usage.query_history ) select date_trunc('day', start_time) as date, dbt_metadata['model_name']::string as model_name, count(distinct dbt_metadata['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. ... from query_history where dbt_metadata is not null and start_time > current_date - 30 group by 1,2
Mit unserem Package dbt-snowflake-monitoring erledigen wir das Parsen der Query Comments automatisch für Sie.
Beide Queries oben betrachten lediglich Laufzeiten. Ergänzend lohnt sich ein Blick auf weitere Metriken:
partitions_scanned&partitions_total: zeigen, ob die Queries Mikropartitionen effizient per Pruning ausschließenbytes_scanned: liefert ein Gefühl dafür, wie viel Daten im Zeitverlauf verarbeitet werden – ein häufiger Grund für steigende Laufzeitenbytes_spilled_to_local_storage&bytes_spilled_to_remote_storage: deuten darauf hin, ob Ihr Modell von einem größeren Warehouse profitieren würdequeued_overload_time: ein Hinweis darauf, dass Sie denmax_cluster_countIhres Warehouses erhöhen sollten
Kosten von dbt-Modellen überwachen
Um die Kosten Ihrer dbt-Modelle über die Zeit zu beobachten, berechnen Sie zunächst die Kosten jeder Snowflake-Query. Anschließend aggregieren Sie die Query-Kosten pro Modell:
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, sum(query_cost) as total_cost, total_cost / num_executions as avg_cost_per_execution from query_history_w_costs where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Wenn Sie automatisch eine Query-Historie inklusive Kosten pro Query haben möchten, installieren Sie einfach unser Package dbt-snowflake-monitoring.
SELECT für das Kosten- & Performance-Monitoring von dbt-Modellen nutzen
Bei SELECT setzen wir Query Tags & Comments ein, damit unsere Kunden ihre dbt-Queries entlang vieler Dimensionen auswerten können: Umgebung, Materialisierung, Resource Type und mehr. Diese Transparenz ist Gold wert – Data-Teams sehen auf einen Blick, welche dbt-Modelle besondere Aufmerksamkeit brauchen. Wie wir diese Informationen im Produkt aufbereiten, zeigt das folgende Beispiel:
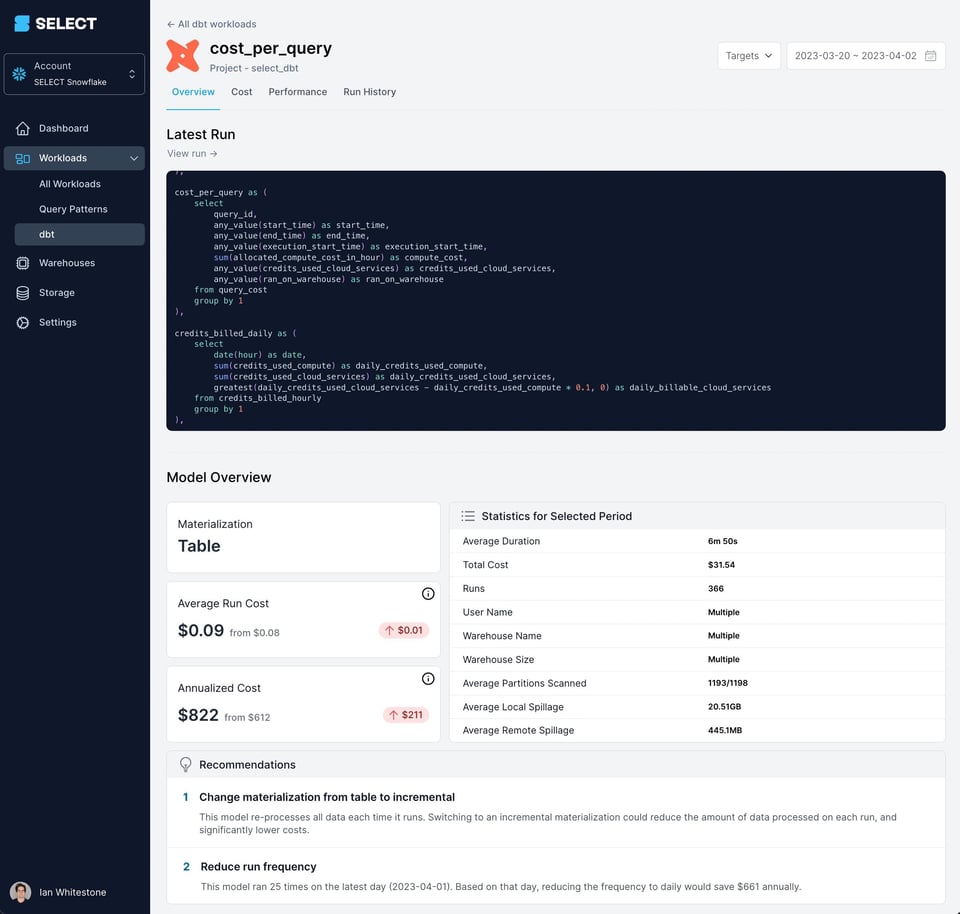
Wenn Sie Ihre Snowflake-Kosten senken, deren Treiber besser verstehen oder einfach den Überblick behalten möchten, können Sie sich über die Links unten Zugang verschaffen oder eine Demo buchen.
Ian Whitestone·Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT hat er sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One geleitet. Bei Shopify verantwortete er die Optimierung des Data Warehouse sowie den Ausbau der Kostentransparenz.