En un post anterior explicamos cómo los query tags de Snowflake y los comentarios permiten asociar metadatos arbitrarios a cada query. Ahora te mostramos cómo sumar query tags o comentarios a tus modelos dbt para darle seguimiento a su costo y rendimiento en el tiempo.
¿Por qué darle seguimiento al costo y rendimiento de los modelos dbt?
La popularidad de dbt se disparó en los últimos 5 años y hoy es el framework más usado para construir y administrar modelos de datos dentro del data warehouse. Sin embargo, correr muchas transformaciones sobre grandes volúmenes de datos en el warehouse no es barato. Ya sea con dbt o con cualquier otra herramienta de transformación basada en SQL, los costos asociados a estas transformaciones suelen representar una parte importante del gasto de cómputo de los clientes de Snowflake.
A medida que los clientes buscan entender, monitorear y reducir mejor su gasto en la nube de datos, se vuelve cada vez más importante tener mayor visibilidad sobre el costo de cada modelo dbt. Además, como cada vez más equipos usan dbt para impulsar aplicaciones y decisiones críticas del negocio, monitorear el rendimiento de los modelos resulta indispensable para cumplir con los SLAs.
Al combinar Snowflake con dbt, estas capacidades de monitoreo no vienen listas para usar. Sumando metadatos a los modelos dbt vía query tags o comentarios, se pueden cubrir esas funciones esenciales de monitoreo.
Configurar query tags en dbt
En nuestro post sobre query tags repasamos las tres opciones para configurarlos en dbt:
- Definirlo de forma global en tu
profiles.yml - Agregar un
query_tagpor modelo en tudbt_project.ymlo en la configuración del modelo - Crear un macro
set_query_tagque asigne dinámicamente el query tag a cada modelo del proyecto.
La opción #3 es, por mucho, la mejor: evita que los usuarios tengan que asignar los tags a mano. Si quieres empezar a asignar query tags de forma dinámica a cada modelo, puedes implementar un macro personalizado como el que está aquí para agregar metadatos detallados a cada query que emite dbt.
Configurar query comments en dbt (enfoque recomendado)
Para los metadatos relacionados con dbt recomendamos usar query comments en lugar de query tags, ya que los metadatos generados automáticamente pueden superar de vez en cuando el límite de 2000 caracteres de los query tags.
dbt trae esta configuración lista para usar. En tu dbt_project.yml puedes agregar lo siguiente:
1query-comment: append: true # Snowflake removes prefixed comments
Esto agregará un comentario al final de tu query:
1create view analytics.analytics.orders as ( select ... ); /* {"app": "dbt", "dbt_version": "0.15.0rc2", "profile_name": "debug", "target_name": "dev", "node_id": "model.dbt2.my_model"} */
Para incluir metadatos más completos en el query comment puedes instalar nuestro paquete dbt-snowflake-monitoring. Este paquete deja disponibles los siguientes metadatos para todas las queries de dbt:
1{ "dbt_snowflake_query_tags_version": "2.0.0", "app": "dbt", "dbt_version": "1.4.0", "project_name": "my_project", "target_name": "dev", "target_database": "dev", "target_schema": "larry_goldings", "invocation_id": "c784c7d0-5c3f-4765-805c-0a377fefcaa0", "node_name": "orders", "node_alias": "orders", "node_package_name": "my_project", "node_original_file_path": "models/staging/orders.sql", "node_database": "dev", "node_schema": "mart", "node_id": "model.my_project.orders", "node_resource_type": "model", "materialized": "incremental", "is_incremental": true, "node_refs": [ "raw_orders", "product_mapping" ], "dbt_cloud_project_id": "146126", "dbt_cloud_job_id": "184124", "dbt_cloud_run_id": "107122910", "dbt_cloud_run_reason_category": "other", "dbt_cloud_run_reason": "Kicked off from UI by [email protected]", }
Con esta información puedes monitorear costo y rendimiento desde varias dimensiones interesantes: proyecto dbt, nombre del modelo, entorno (dev o prod), tipo de materialización y más.
Monitorear el rendimiento de los modelos dbt
Si usas query tags, puedes monitorear el rendimiento de tus modelos dbt con una variante de la siguiente query:
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. from snowflake.account_usage.query_history where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Si usas query comments, primero hay que extraer los metadatos del texto del comentario:
1with query_history as ( select *, regexp_substr(query_text, '/\\*\\s({"app":\\s"dbt".*})\\s\\*/', 1, 1, 'ie') as _dbt_json_meta, try_parse_json(_dbt_json_meta) as dbt_metadata from snowflake.account_usage.query_history ) select date_trunc('day', start_time) as date, dbt_metadata['model_name']::string as model_name, count(distinct dbt_metadata['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. ... from query_history where dbt_metadata is not null and start_time > current_date - 30 group by 1,2
Si usas nuestro paquete dbt-snowflake-monitoring, este parseo del query comment se hace de forma automática.
Las dos queries anteriores solo miran los tiempos de ejecución. Otras métricas que conviene monitorear en paralelo son:
partitions_scannedypartitions_total: te indican si las queries están descartando micro-particiones de forma eficientebytes_scanned: te da una idea de cuántos datos se están procesando en el tiempo, lo que puede explicar aumentos en los tiempos de ejecuciónbytes_spilled_to_local_storageybytes_spilled_to_remote_storage: muestran si a tu modelo le conviene correr en un warehouse más grandequeued_overload_time: indica si necesitas subir elmax_cluster_countdel warehouse
Monitorear el costo de los modelos dbt
Para monitorear el costo de los modelos dbt en el tiempo, primero calcula el costo de cada query de Snowflake. Luego, con los costos por query se puede agregar el gasto por modelo:
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, sum(query_cost) as total_cost, total_cost / num_executions as avg_cost_per_execution from query_history_w_costs where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Si quieres obtener de forma automática un query history con los costos de cada query ya incluidos, puedes instalar nuestro paquete dbt-snowflake-monitoring.
Usa SELECT para monitorear el costo y rendimiento de tus modelos dbt
En SELECT aprovechamos los query tags y comentarios para que nuestros clientes puedan monitorear las queries que emite dbt desde varias dimensiones: entorno, materialización, tipo de recurso, etc. Esta visibilidad aporta muchísimo valor, porque les permite a los equipos de datos priorizar con facilidad qué modelos dbt necesitan atención extra. Abajo te mostramos un ejemplo de cómo presentamos esta información dentro del producto:
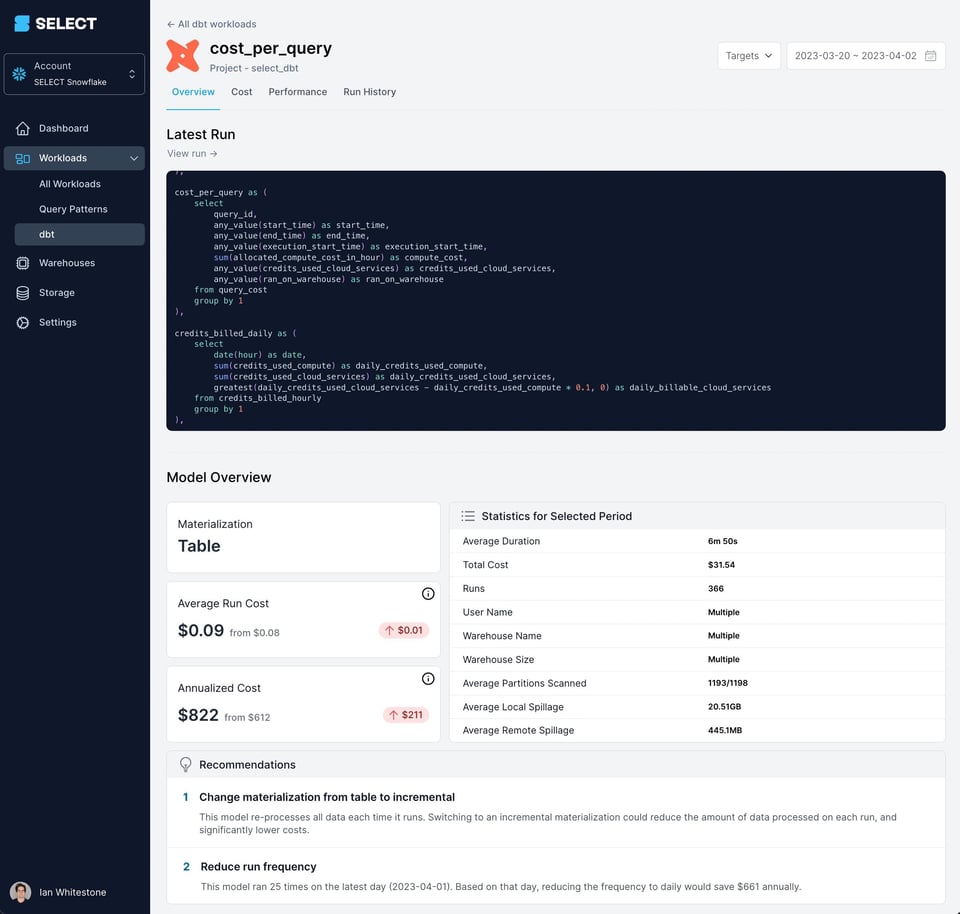
Si quieres recortar tus costos de Snowflake, entender mejor qué los está empujando o simplemente tomarle el pulso a todo, puedes obtener acceso hoy mismo o agendar una demo desde los enlaces de abajo.
Ian Whitestone·Co-founder y CEO de SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, Ian estuvo al frente de los esfuerzos para optimizar el data warehouse y aumentar la observabilidad de costos.