Dans un précédent article, nous avons vu comment les query tags Snowflake et les commentaires permettent d'associer des métadonnées libres à chaque requête. Nous montrons ici comment ajouter des query tags ou des commentaires à vos modèles dbt pour en suivre les coûts et les performances dans le temps.
Pourquoi suivre les coûts et les performances des modèles dbt ?
dbt a connu un essor fulgurant ces cinq dernières années, jusqu'à devenir le framework de référence pour construire et gérer les modèles de données au sein du data warehouse. Or, exécuter de nombreuses transformations sur de gros volumes de données dans le warehouse a un coût loin d'être négligeable. Que l'on utilise dbt ou un autre outil de transformation basé sur SQL, ces transformations représentent généralement une part significative des dépenses compute des clients Snowflake.
À mesure que les clients cherchent à mieux comprendre, surveiller et réduire leurs dépenses cloud, il devient essentiel d'obtenir une visibilité fine sur le coût associé à chaque modèle dbt. Par ailleurs, dbt est de plus en plus utilisé pour alimenter des applications et des décisions critiques : suivre les performances des modèles devient donc indispensable pour garantir le respect des SLA.
Avec Snowflake et dbt, ces fonctionnalités de monitoring ne sont pas disponibles nativement. En ajoutant des métadonnées à leurs modèles dbt via des query tags ou des commentaires, les clients peuvent combler ce manque.
Définir des query tags dans dbt
Dans notre article sur les query tags, nous avons présenté les trois options pour les définir dans dbt :
- Les définir globalement dans votre
profiles.yml - Ajouter un
query_tagà chaque modèle dans votredbt_project.ymlou dans la configuration du modèle - Créer une macro
set_query_tagqui définit dynamiquement le query tag de chaque modèle du projet.
L'approche n°3 est de loin la meilleure : elle évite aux utilisateurs d'avoir à définir les tags à la main. Pour démarrer avec la définition dynamique des query tags, vous pouvez vous appuyer sur une macro personnalisée comme celle disponible ici, qui ajoute des métadonnées détaillées à chaque requête émise par dbt.
Définir des query comments dans dbt (approche recommandée)
Pour les métadonnées liées à dbt, nous recommandons d'utiliser les query comments plutôt que les query tags, car les métadonnées générées automatiquement dépassent parfois la limite de 2000 caractères imposée aux query tags.
dbt propose ce paramètre nativement. Dans votre dbt_project.yml, ajoutez simplement :
1query-comment: append: true # Snowflake removes prefixed comments
Un commentaire sera ajouté à la fin de votre requête :
1create view analytics.analytics.orders as ( select ... ); /* {"app": "dbt", "dbt_version": "0.15.0rc2", "profile_name": "debug", "target_name": "dev", "node_id": "model.dbt2.my_model"} */
Pour intégrer des métadonnées plus complètes dans ce commentaire, installez notre package dbt-snowflake-monitoring. Il rend les métadonnées suivantes disponibles pour toutes les requêtes dbt :
1{ "dbt_snowflake_query_tags_version": "2.0.0", "app": "dbt", "dbt_version": "1.4.0", "project_name": "my_project", "target_name": "dev", "target_database": "dev", "target_schema": "larry_goldings", "invocation_id": "c784c7d0-5c3f-4765-805c-0a377fefcaa0", "node_name": "orders", "node_alias": "orders", "node_package_name": "my_project", "node_original_file_path": "models/staging/orders.sql", "node_database": "dev", "node_schema": "mart", "node_id": "model.my_project.orders", "node_resource_type": "model", "materialized": "incremental", "is_incremental": true, "node_refs": [ "raw_orders", "product_mapping" ], "dbt_cloud_project_id": "146126", "dbt_cloud_job_id": "184124", "dbt_cloud_run_id": "107122910", "dbt_cloud_run_reason_category": "other", "dbt_cloud_run_reason": "Kicked off from UI by [email protected]", }
Vous pouvez ainsi suivre coûts et performances selon de nombreux axes : projet dbt, nom du modèle, environnement (dev ou prod), type de matérialisation, et bien d'autres.
Suivre les performances des modèles dbt
Avec les query tags, vous pouvez suivre les performances de vos modèles dbt en adaptant la requête ci-dessous :
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. from snowflake.account_usage.query_history where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Si vous utilisez les query comments, il faut d'abord extraire les métadonnées du texte du commentaire :
1with query_history as ( select *, regexp_substr(query_text, '/\\*\\s({"app":\\s"dbt".*})\\s\\*/', 1, 1, 'ie') as _dbt_json_meta, try_parse_json(_dbt_json_meta) as dbt_metadata from snowflake.account_usage.query_history ) select date_trunc('day', start_time) as date, dbt_metadata['model_name']::string as model_name, count(distinct dbt_metadata['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. ... from query_history where dbt_metadata is not null and start_time > current_date - 30 group by 1,2
Avec notre package dbt-snowflake-monitoring, ce parsing des commentaires est pris en charge automatiquement.
Les deux requêtes ci-dessus se limitent aux temps d'exécution. D'autres métriques intéressantes méritent un suivi en parallèle :
partitions_scannedetpartitions_total: indiquent si vos requêtes élaguent efficacement les micro-partitionsbytes_scanned: donne une idée du volume de données traité dans le temps, ce qui peut expliquer un allongement des temps d'exécutionbytes_spilled_to_local_storageetbytes_spilled_to_remote_storage: signalent si votre modèle gagnerait à tourner sur un warehouse plus grandqueued_overload_time: signale s'il faut augmenter lemax_cluster_countdu warehouse
Suivre les coûts des modèles dbt
Pour suivre les coûts des modèles dbt dans le temps, commencez par calculer le coût de chaque requête Snowflake. Ces coûts servent ensuite à agréger les dépenses par modèle :
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, sum(query_cost) as total_cost, total_cost / num_executions as avg_cost_per_execution from query_history_w_costs where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Pour obtenir automatiquement un query history enrichi du coût de chaque requête, installez notre package dbt-snowflake-monitoring.
Suivez coûts et performances de vos modèles dbt avec SELECT
Chez SELECT, nous exploitons les query tags et les commentaires pour permettre à nos clients de suivre les requêtes émises par dbt selon de nombreux axes : environnement, matérialisation, type de ressource, etc. Cette visibilité est précieuse : elle permet aux équipes data de repérer immédiatement les modèles dbt qui méritent une attention particulière. Voici un exemple de la manière dont nous restituons ces informations dans le produit :
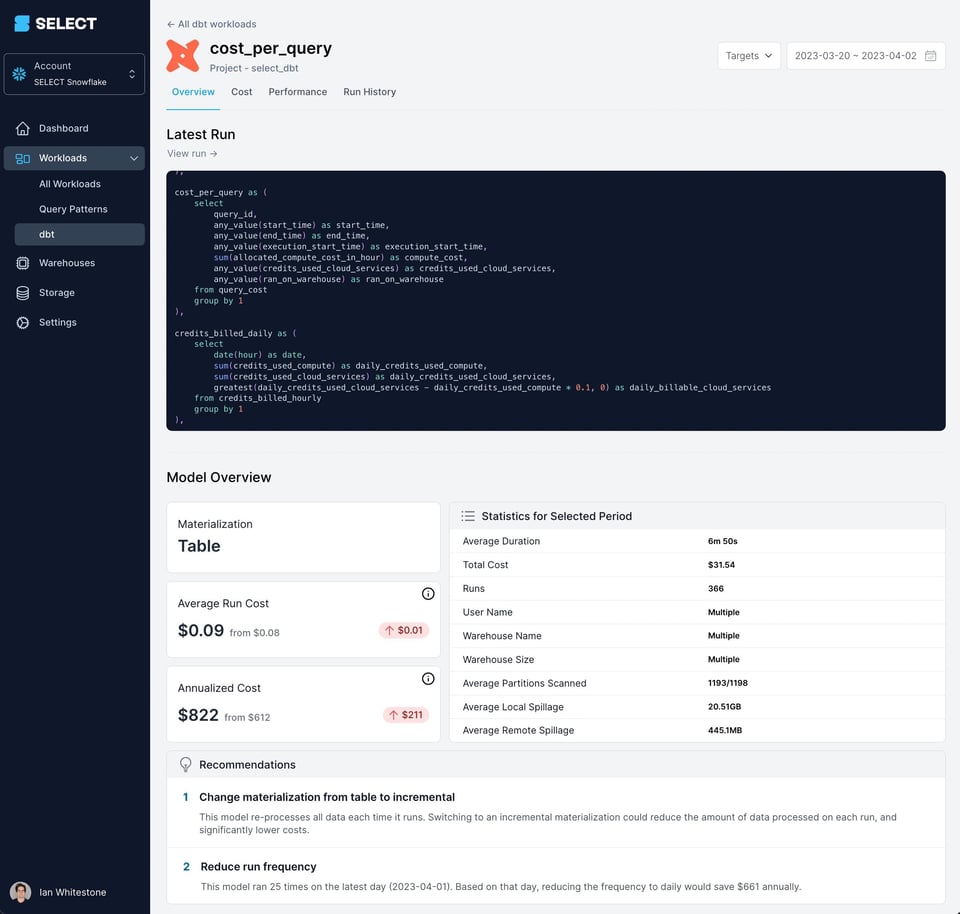
Si vous souhaitez réduire vos coûts Snowflake, mieux comprendre ce qui les alimente ou simplement garder un œil dessus, demandez votre accès dès aujourd'hui ou réservez une démo via les liens ci-dessous.
Ian Whitestone·Co-founder & CEO of SELECT
Ian est cofondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, il a passé 6 ans à la tête d'équipes full stack data science et engineering chez Shopify et Capital One. Chez Shopify, il a piloté l'optimisation du data warehouse et la mise en place de l'observabilité des coûts.