In un articolo precedente abbiamo visto come i query tag di Snowflake e i commenti permettano di associare metadati arbitrari a ogni query. In questo articolo vediamo come aggiungere query tag o commenti ai propri modelli dbt per tenerne sotto controllo costi e performance nel tempo.
Perché monitorare costi e performance dei modelli dbt?
Negli ultimi cinque anni dbt ha conosciuto una crescita straordinaria, affermandosi come il framework più diffuso per costruire e gestire i modelli di dati all'interno del data warehouse. Eseguire molte trasformazioni su dataset di grandi dimensioni nel warehouse, però, ha un costo tutt'altro che trascurabile. Che si utilizzi dbt o un altro strumento di trasformazione basato su SQL, queste operazioni rappresentano in genere una quota significativa della spesa di compute dei clienti Snowflake.
Mentre le aziende cercano di comprendere, monitorare e ridurre la spesa sul data cloud, diventa sempre più importante avere visibilità sui costi associati a ciascun modello dbt. Inoltre, poiché dbt viene impiegato sempre più spesso per alimentare applicazioni e decisioni business critical, monitorare le performance dei modelli è ormai indispensabile per garantire il rispetto degli SLA.
Usando Snowflake e dbt, queste funzionalità di monitoraggio non sono disponibili out of the box. Aggiungendo metadati ai modelli dbt tramite query tag o commenti, però, è possibile colmare questa lacuna e ottenere il controllo necessario.
Impostare i query tag in dbt
Nel nostro articolo sui query tag abbiamo illustrato le tre opzioni per impostarli in dbt:
- Impostarli a livello globale nel file
profiles.yml - Aggiungere un
query_tagper ciascun modello neldbt_project.ymlo nella config del modello - Creare una macro
set_query_tagche imposti dinamicamente il query tag per ogni modello del progetto.
La terza opzione è di gran lunga la migliore, perché evita di dover impostare i tag a mano. Per iniziare a impostare dinamicamente i query tag per ogni modello, può utilizzare una macro personalizzata come quella disponibile qui e arricchire ogni query eseguita da dbt con metadati dettagliati.
Impostare i query comment in dbt (approccio consigliato)
Per i metadati relativi a dbt consigliamo di usare i query comment anziché i query tag, poiché i metadati generati automaticamente possono superare il limite di 2000 caratteri previsto per i query tag.
dbt offre questa impostazione out of the box. Nel dbt_project.yml può aggiungere quanto segue:
1query-comment: append: true # Snowflake removes prefixed comments
In questo modo verrà accodato un commento alla query:
1create view analytics.analytics.orders as ( select ... ); /* {"app": "dbt", "dbt_version": "0.15.0rc2", "profile_name": "debug", "target_name": "dev", "node_id": "model.dbt2.my_model"} */
Per inserire metadati più completi nel query comment, può installare il nostro package dbt-snowflake-monitoring, che mette a disposizione i seguenti metadati per tutte le query dbt:
1{ "dbt_snowflake_query_tags_version": "2.0.0", "app": "dbt", "dbt_version": "1.4.0", "project_name": "my_project", "target_name": "dev", "target_database": "dev", "target_schema": "larry_goldings", "invocation_id": "c784c7d0-5c3f-4765-805c-0a377fefcaa0", "node_name": "orders", "node_alias": "orders", "node_package_name": "my_project", "node_original_file_path": "models/staging/orders.sql", "node_database": "dev", "node_schema": "mart", "node_id": "model.my_project.orders", "node_resource_type": "model", "materialized": "incremental", "is_incremental": true, "node_refs": [ "raw_orders", "product_mapping" ], "dbt_cloud_project_id": "146126", "dbt_cloud_job_id": "184124", "dbt_cloud_run_id": "107122910", "dbt_cloud_run_reason_category": "other", "dbt_cloud_run_reason": "Kicked off from UI by [email protected]", }
Con queste informazioni potrà analizzare costi e performance secondo dimensioni di grande utilità: progetto dbt, nome del modello, ambiente (dev o prod), tipo di materializzazione e molto altro.
Monitorare le performance dei modelli dbt
Con i query tag può monitorare le performance dei modelli dbt partendo da una variante della query seguente:
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. from snowflake.account_usage.query_history where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Se invece usa i query comment, dovrà prima estrarre i metadati dal testo del commento:
1with query_history as ( select *, regexp_substr(query_text, '/\\*\\s({"app":\\s"dbt".*})\\s\\*/', 1, 1, 'ie') as _dbt_json_meta, try_parse_json(_dbt_json_meta) as dbt_metadata from snowflake.account_usage.query_history ) select date_trunc('day', start_time) as date, dbt_metadata['model_name']::string as model_name, count(distinct dbt_metadata['invocation_id']) as num_executions, avg(total_elapsed_time/1000) as avg_total_elapsed_time_s, approx_percentile(total_elapsed_time/1000, 0.95) as p95_total_elapsed_time_s, avg(execution_time/1000) as avg_execution_time_s, approx_percentile(execution_time/1000, 0.95) as p95_execution_time_s -- optionally repeat for other query time metrics, like: -- compilation_time, queued_provisioning_time, queued_overload_time, etc. ... from query_history where dbt_metadata is not null and start_time > current_date - 30 group by 1,2
Con il nostro package dbt-snowflake-monitoring il parsing del query comment avviene in automatico.
Le due query qui sopra considerano solo i tempi di esecuzione. Tra le altre metriche che può tenere d'occhio in parallelo ci sono:
partitions_scannedepartitions_total: indicano se le query stanno eliminando in modo efficiente le micro-partizionibytes_scanned: offre un'idea del volume di dati elaborato nel tempo, utile per spiegare eventuali aumenti dei tempi di esecuzionebytes_spilled_to_local_storageebytes_spilled_to_remote_storage: segnalano se il modello potrebbe trarre vantaggio dall'esecuzione su un warehouse più grandequeued_overload_time: indica se è il caso di aumentare ilmax_cluster_countdel warehouse
Monitorare la spesa dei modelli dbt
Per tenere sotto controllo i costi dei modelli dbt nel tempo, calcoli innanzitutto il costo di ogni query Snowflake. A quel punto può sfruttare questi costi per aggregare la spesa per modello:
1select date_trunc('day', start_time) as date, try_parse_json(query_tag)['model_name']::string as model_name, count(distinct try_parse_json(query_tag)['invocation_id']) as num_executions, sum(query_cost) as total_cost, total_cost / num_executions as avg_cost_per_execution from query_history_w_costs where try_parse_json(query_tag)['app']::string = 'dbt' and start_time > current_date - 30 group by 1,2
Se desidera ottenere automaticamente una query history arricchita con il costo di ciascuna query, può installare il nostro package dbt-snowflake-monitoring.
Usare SELECT per monitorare costi e performance dei modelli dbt
In SELECT sfruttiamo query tag e commenti per consentire ai nostri clienti di analizzare le query generate da dbt secondo molteplici dimensioni: ambiente, materializzazione, tipo di risorsa e altro ancora. È un livello di visibilità di enorme valore, perché permette ai team data di capire subito su quali modelli dbt concentrare l'attenzione. Ecco un esempio di come presentiamo queste informazioni all'interno del prodotto:
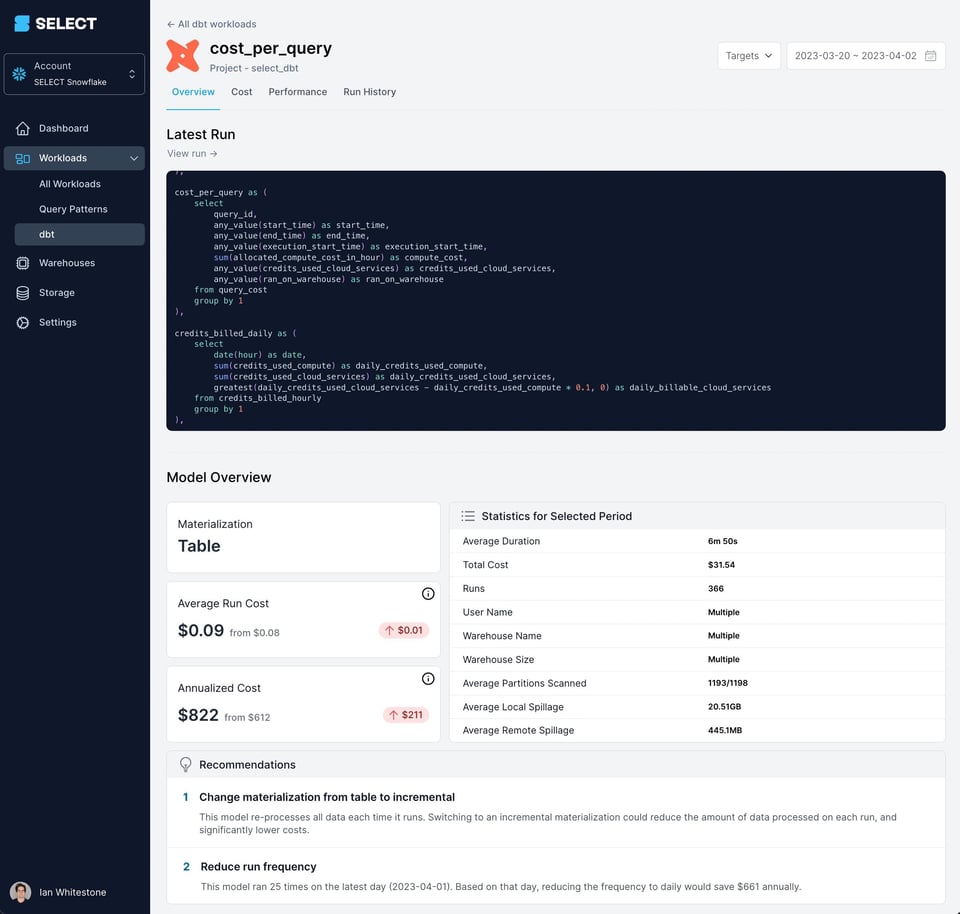
Se vuole ridurre i costi di Snowflake, capire meglio cosa li determina o semplicemente tenerli sotto controllo, può accedere oggi stesso o prenotare una demo dai link qui sotto.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder e CEO di SELECT, piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, ha guidato per sei anni team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha coordinato le attività di ottimizzazione del data warehouse e di miglioramento dell'osservabilità dei costi.