¿Qué son las Dynamic Tables de Snowflake?
En Snowflake, una Dynamic Table es una tabla que materializa el resultado de una consulta SQL y se mantiene actualizada de forma automática según un schedule. Al igual que una view, el SQL para crearla puede incluir bastante complejidad: unir varias tablas, distintos tipos de join (left join, full join, cartesiano), uniones, cálculos, etc. Pero a diferencia de una view, que nunca persiste los datos, el resultado de una dynamic table se guarda como una tabla física.
Las Dynamic Tables se refrescan con la frecuencia que tú definas, lo que se conoce como "target lag" o target_lag. Por eso, hacer un select sobre una dynamic table suele ser mucho más rápido que leer una view con muchos joins complejos.
Las dynamic tables son una forma simple y económica de armar pipelines de datos eficientes que siempre se mantienen al día.
¿En qué se diferencian las Dynamic Tables de las Materialized Views?
En Snowflake, una Materialized View es una view de una sola tabla. Se almacena como una tabla física, por lo que consultarla es rápido, pero se mantiene actualizada en tiempo real, igual que una view.
Estas son las diferencias clave entre Materialized Views y Dynamic Tables.
Joins
En Snowflake, una Materialized View no admite joins. Es una limitación importante que reduce mucho su utilidad.
Una Dynamic Table en Snowflake se parece mucho más a una Materialized View en otras bases de datos, como PostgreSQL, donde casi no hay restricciones sobre el SQL que puedes escribir. Sin embargo, en Postgres, una Materialized View debe refrescarse manualmente con el comando refresh materialized view, mientras que una Dynamic Table en Snowflake se refresca automáticamente según el target lag.
Frecuencia de refresco
Las materialized views en Snowflake tienen la ventaja de estar siempre actualizadas. Son en tiempo real y no requieren ninguna acción para refrescarse.
Las Dynamic Tables, en cambio, se refrescan según un schedule. El usuario final puede necesitar saber qué tan frescos están los datos.
Reescritura de consultas
Al consultar las tablas base de una materialized view, el optimizador de consultas de Snowflake puede reescribir tu consulta para usar la materialized view en su lugar.
Al consultar los datos base de una dynamic table, Snowflake no reescribe la consulta para usar la dynamic table.
Mi opinión sobre las diferencias
Aunque las materialized views tienen dos ventajas (siempre frescas y reescritura de consultas), el hecho de que solo puedan basarse en una tabla limita tanto su utilidad que lo más común será recurrir a una dynamic table.
Usa una materialized view cuando solo necesites agregar, sumar cálculos o transformar una sola tabla.
Usa una Dynamic Table para casos de uso más complejos.
Cómo crear una Dynamic Table
Una dynamic table se crea de forma parecida al conocido CTAS, pero con algunos parámetros adicionales: target_lag, warehouse y varios opcionales más que se muestran abajo.
Sintaxis completa, tomada de la documentación de Snowflake:
CREATE [ OR REPLACE ] [ TRANSIENT ] DYNAMIC TABLE [ IF NOT EXISTS ] <name> (
-- Column definition
<col_name> <col_type>
[ [ WITH ] MASKING POLICY <policy_name> [ USING ( <col_name> , <cond_col1> , ... ) ] ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT '<string_literal>' ]
-- Additional column definitions
[ , <col_name> <col_type> [ ... ] ]
)
TARGET_LAG = { '<num> { seconds | minutes | hours | days }' | DOWNSTREAM }
WAREHOUSE = <warehouse_name>
[ REFRESH_MODE = { AUTO | FULL | INCREMENTAL } ]
[ INITIALIZE = { ON_CREATE | ON_SCHEDULE } ]
Expandir código
create or replace dynamic table my_table
target_lag = '1 Day'
warehouse = 'TRANSFORMING'
refresh_mode = 'incremental'
as
select
customers.name,
count(*) as total_orders
from orders
inner join customers
using (customer_id)
group by 1
En la práctica, tu sentencia create puede verse así:
El refresco se inicializa de inmediato, porque el valor por defecto de initialize es on_create.
Veamos a fondo los dos argumentos propios que más vas a usar: target_lag y refresh_mode.
Target Lag
El target lag es el tiempo máximo que quieres que los datos vayan por detrás de los cambios en los datos de origen. Se expresa con un número entero y la unidad de tiempo (seconds, minutes, hours, days). Por ejemplo, 5 minutes es un target lag válido.
Si encadenas una dynamic table sobre otra, puedes configurar target_lag = downstream en todas las dynamic tables de la cadena, salvo la última, que debe tener un schedule de tiempo. Mira el ejemplo de abajo:
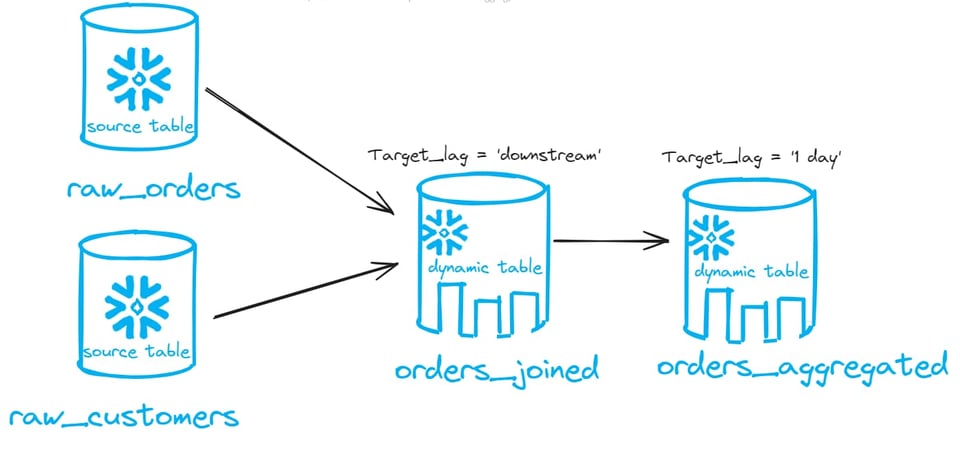
En la imagen anterior tenemos dos dynamic tables encadenadas. La primera (orders_joined) tiene un target lag de downstream. La segunda (orders_aggregated) tiene un target lag de 1 día. En este caso, todo el DAG se actualiza una vez al día. No tienes que preocuparte por definir un schedule en cada tabla.
- Si la última dynamic table de tu DAG tiene un target lag de
downstream, ¡tus datos nunca se van a refrescar! - Snowflake hace esta aclaración en la documentación: el target lag no es una garantía. Es un objetivo que Snowflake intenta cumplir. Los datos de las dynamic tables se refrescan lo más cerca posible del target lag. Sin embargo, el target lag puede superarse por factores como el tamaño del warehouse, el volumen de datos, la complejidad de la consulta y otros similares.
Refresh Mode
El Refresh Mode puede ser auto, full o incremental. El modo por defecto es auto, que intenta refrescar de forma incremental y recurre a full si no puede.
Las Dynamic Tables se refrescan de forma incremental a partir de los changes en los datos de origen. No tienes que dar ninguna información sobre una primary key ni sobre cómo detectar los cambios: Snowflake lo hace todo por ti, ¡como por arte de magia! Para más información sobre Changes, consulta la documentación de Snowflake y nuestro blog post sobre Streams.
Vale la pena mencionar que las Dynamic Tables están relacionadas con los Streams en Snowflake, ya que por debajo usan la misma tecnología de change tracking: changes. De hecho, ¡estas funcionalidades las mantiene el mismo equipo dentro de Snowflake!
Las Dynamic Tables son una forma declarativa y amigable de construir un pipeline.
Los Streams son imperativos y requieren mucha más personalización para que el pipeline funcione.
Limitaciones del modo de refresco incremental
Una dynamic table no se puede refrescar de forma incremental si:
- Se usa una función SQL no soportada como
current_timestamporandom. - Se usa una construcción SQL no soportada:
pivot,unpivot,union,minus,intersect,except.- ¡
union allsí está soportado para incremental! Salvo en algunos casos extremos.
- ¡
- Se usan cláusulas
partion_byno idénticas en distintas funciones de ventana. - Cambia más del 5% de los datos. ¡Esta hay que vigilarla de cerca!
- Se usan operadores de subconsulta como
in,any,all,exists.
Hay varias limitaciones más a tener en cuenta. Arriba solo listé las que creo que vas a enfrentar con más frecuencia. Para ver la explicación completa de las limitaciones del Incremental Refresh en Dynamic Tables, te recomiendo leer esta página.
El auto refresh puede ser una buena opción… pero…
Si logras crear una Dynamic Table con incremental y un día Snowflake no puede refrescarla de forma incremental por alguna de las limitaciones documentadas, el refresco fallará. Y fallará en silencio, salvo que hayas armado algún mecanismo de alertas para monitorear los refrescos. Para evitar ese dolor de cabeza, puedes usar auto y dejar que Snowflake haga un full refresh cuando sea necesario. Después, monitorea tus dynamic tables para ver cómo Snowflake está manejando los refrescos.
Eso sí, Snowflake advierte sobre el uso del modo auto:
Para un comportamiento consistente, define explícitamente el refresh mode en todas las tablas de producción. El comportamiento de
AUTOpuede cambiar entre versiones de Snowflake, lo que puede provocar cambios inesperados en el rendimiento si se usa en pipelines de producción.
Monitoreo de Dynamic Tables
La pestaña Data en Snowsight
La forma más fácil de monitorear las Dynamic Tables es desde la UI de Snowsight.
En la pestaña Data del menú lateral izquierdo de Snowsight, navega hasta tu dynamic table. Haz clic en ella y luego en la pestaña Refresh History.
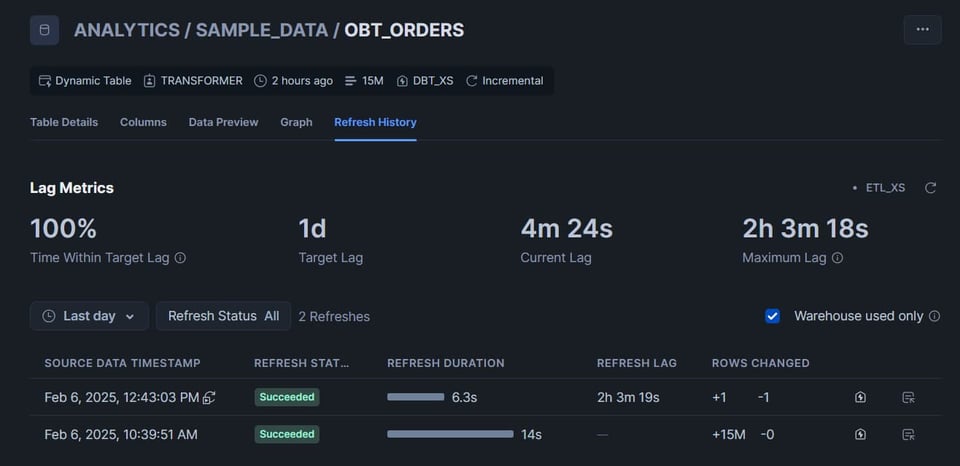
Algunos puntos súper útiles a destacar:
- La sección Lag Metrics es muy práctica. Ahí puedes ver si el lag alguna vez superó el target lag, qué tan frescos están los datos actuales y el lag máximo que tuvo la tabla.
- En la sección de refresh history, a la derecha vas a encontrar un hipervínculo al query profile del refresco. (El ícono del rayo dentro de una casa). ¡Súper útil para diagnosticar refrescos largos!
Para un monitoreo automatizado de fallos en los refrescos, revisa nuestros artículos sobre cómo enviar alertas a Slack y Microsoft Teams.
La pestaña Monitoring en Snowsight
No solo puedes monitorear DAGs individuales seleccionando cualquier dynamic table desde la pestaña Data: también puedes ver el estado de todas las dynamic tables en un solo lugar desde la pestaña "Monitoring".
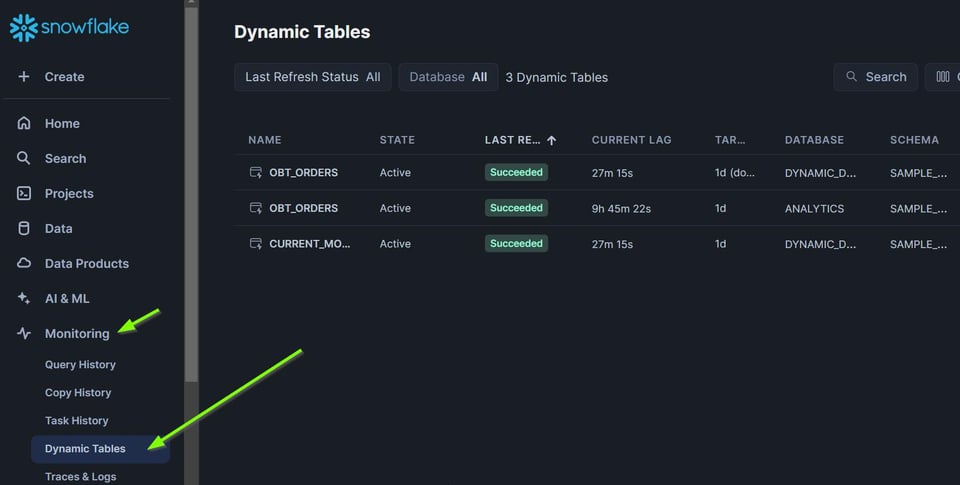
Aquí puedes ordenar por "Refresh Status" para identificar los refrescos fallidos.
Modificar / actualizar una dynamic table
Snowflake ofrece varias propiedades que pueden actualizarse con alter dynamic table. Esta es la lista completa según la documentación de Snowflake:
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { SUSPEND | RESUME }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> RENAME TO <new_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> SWAP WITH <target_dynamic_table_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> REFRESH [ COPY SESSION ]
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { clusteringAction }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { tableColumnCommentAction }
ALTER DYNAMIC TABLE <name> { SET | UNSET } COMMENT = '<string_literal>'
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> dataGovnPolicyTagAction
Expandir código
Ejemplos: cómo modificar una Dynamic Table
-- Suspend the dynamic table / turn of automatic updates
alter dynamic table my_dynamic_table suspend
-- turn auto updates back on
alter dynamic table my_dynamic_table resume
-- update target lag
alter dynamic table my_dynamic_table set target_lag = '2 Days'
-- change target_lag from time interval to downstream
alter dynamic table my_dynamic_table set target_lag = 'downstream'
-- change refresh_mode from incremental to full
alter dynamic table my_dynamic_table set refresh_mode = 'full'
Expandir código
Editar el SQL de una Dynamic Table
Es importante señalar que no puedes agregar una columna ni cambiar el SQL con el comando alter; tienes que reemplazar la tabla por completo. Esto se hace con drop table my_dynamic_table y luego recreándola. O puedes usar create or replace en el DDL: create or replace dynamic table my_dynamic_table...
Ejemplo de pipeline de datos de punta a punta
Vamos con un ejemplo simple que cualquiera pueda seguir. Para este ejemplo, vamos a copiar los datos de muestra de la base de datos snowflake_sample_data. (Lamentablemente, no se pueden clonar ni crear dynamic tables sobre datos que vienen de un share, así que simplemente duplicamos los datos y después creamos las dynamic tables).
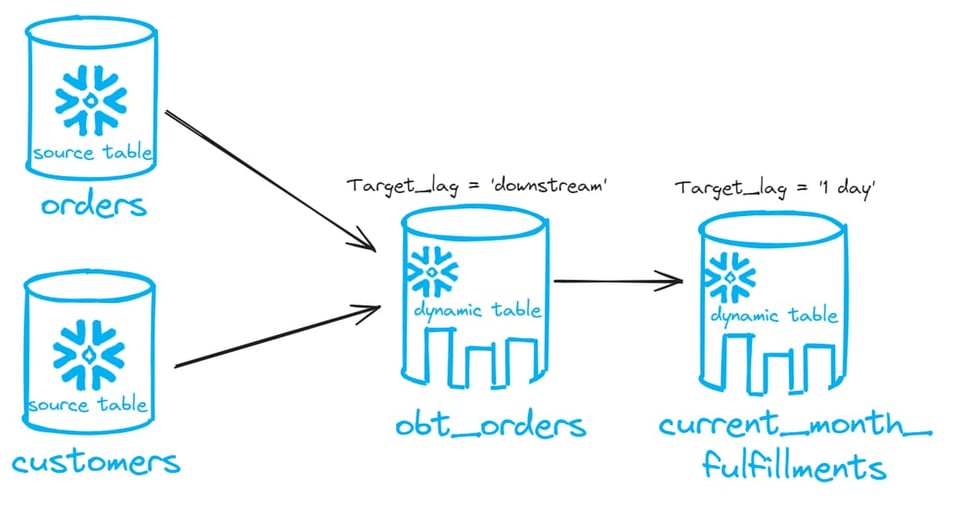
Aquí tienes una imagen del DAG que vamos a crear:
Setup
Vamos a crear algunos objetos nuevos para partir todos del mismo punto.
use role sysadmin;
create warehouse example_wh_xs
warehouse_size = xsmall
auto_suspend = 60
auto_resume = true;
use role securityadmin;
create role example_role;
grant role example_role to user jeff; -- swap in your user
grant all on warehouse example_wh_xs to role example_role;
use role sysadmin;
create database dynamic_demo;
Expandir código
Ahora copiemos algunos datos de muestra a nuestra nueva base de datos. (¡De nuevo, clonar no funciona!)
use schema dynamic_demo.sample_data;
create or replace table orders as
select * from
snowflake_sample_data.tpch_sf10.orders;
create or replace table customer as
select * from
snowflake_sample_data.tpch_sf10.customer;
Ahora creemos dos dynamic tables: una que una nuestras dos tablas nuevas y otra que agregue los datos. La primera dynamic table del DAG va a tener un target lag de downstream. La segunda tendrá un target lag de 1 día. Esto va a controlar el lag de todo el DAG.
create or replace dynamic table obt_orders
target_lag = 'downstream'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
select *
from orders join customer
on orders.o_custkey = customer.c_custkey;
create or replace dynamic table current_month_fulfillments
target_lag = '1 day'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
with current_month as (
Expandir código
Modificar los datos de origen y ejecutar el pipeline
La tabla current_month_fulfillments no debería tener datos, porque ninguna de las órdenes tiene estado F o P para ese mes. (Revisa la cláusula where de la consulta anterior).
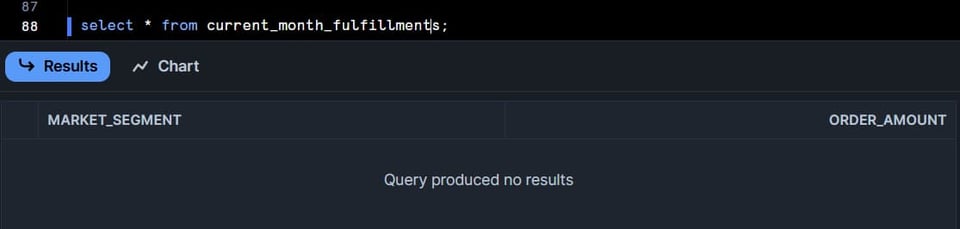
Ahora actualicemos los datos en bruto y refresquemos manualmente la tabla current_month_fulfillments:
update orders set o_orderstatus = 'F'
where date_trunc('month', o_orderdate) = '1998-08-01';
-- yes, the max order month in the data is august 1998!
-- 12,466 rows updated
-- manually refresh the last table in the DAG so we don't have to wait:
alter dynamic table current_month_fulfillments refresh;
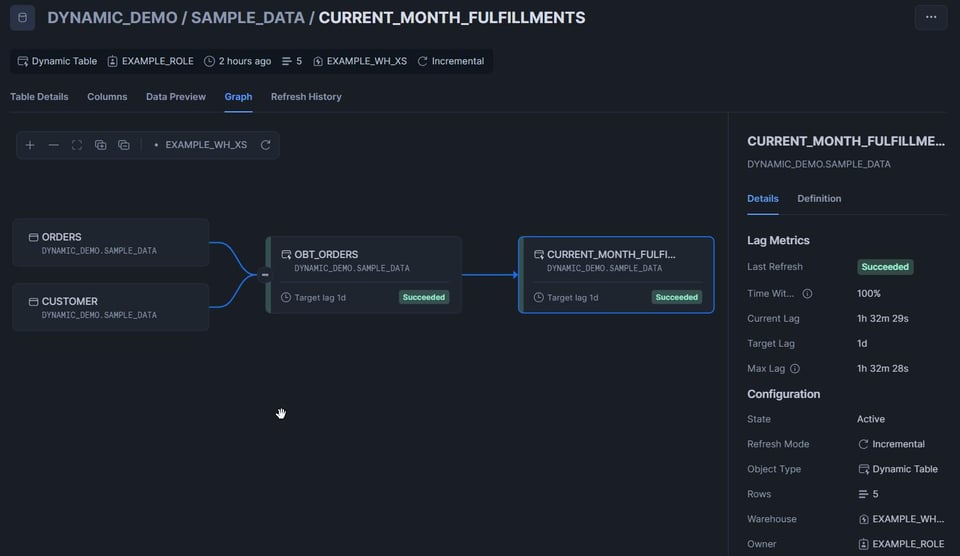
Vemos que la primera tabla se refrescó automáticamente, porque estaba configurada con target_lag='downstream':
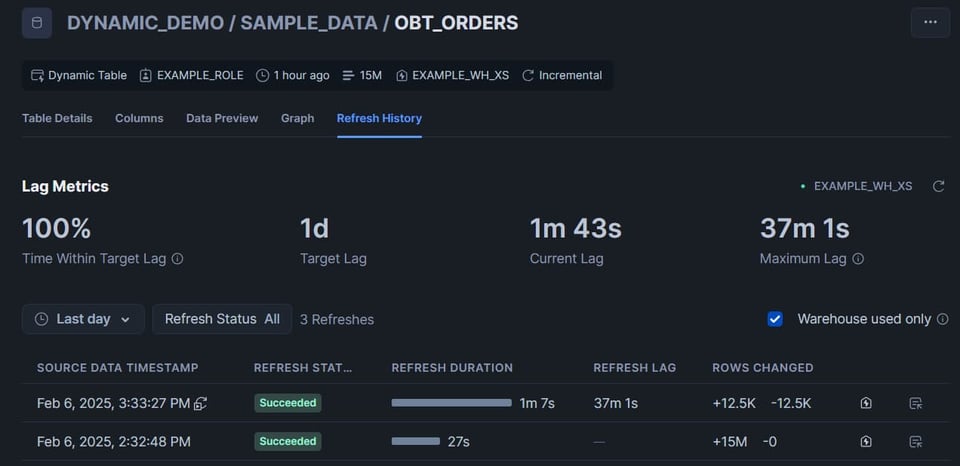
Vemos que se eliminaron y reinsertaron 12,5K filas.
Al revisar la segunda tabla del DAG, vemos que se insertaron 5 filas:
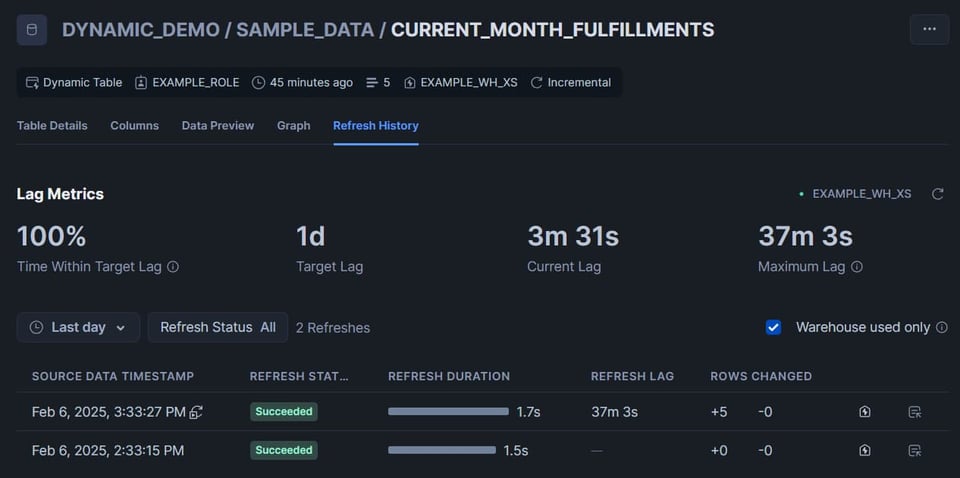
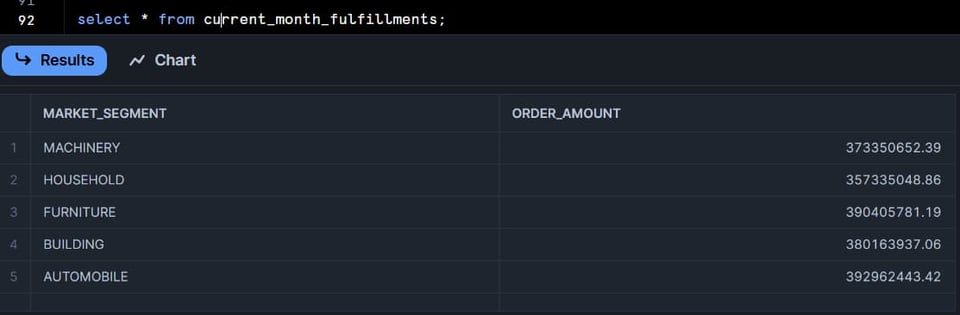
Haz clic en la pestaña "Graph", que muestra una excelente vista de todas las tablas del DAG. Las dynamic tables muestran un estado: "Succeeded" en verde o "Failed" en rojo.
Limpieza
drop database dynamic_demo;
use role sysadmin;
drop warehouse example_wh_xs;
use role securityadmin;
drop role example_role;
Dynamic Tables con dbt
Crear una dynamic table en dbt es tan simple como agregar este config a tu archivo .sql habitual:
{{ config(
materialized="dynamic_table",
on_configuration_change="apply" | "continue" | "fail",
target_lag="downstream" | "<integer> seconds | minutes | hours | days",
snowflake_warehouse="<warehouse-name>",
refresh_mode="AUTO" | "FULL" | "INCREMENTAL",
initialize="ON_CREATE" | "ON_SCHEDULE",
) }}
O en un archivo de propiedades:
version: 2
models:
- name: [<model-name>]
config:
materialized: dynamic_table
on_configuration_change: apply | continue | fail
target_lag: downstream | <time-delta>
snowflake_warehouse: <warehouse-name>
refresh_mode: AUTO | FULL | INCREMENTAL
initialize: ON_CREATE | ON_SCHEDULE
Cómo funciona con dbt
Cuando dbt se ejecuta por primera vez, crea la dynamic table. En las ejecuciones siguientes, detecta que la tabla ya existe y la omite. La tabla solo se refresca según el target_lag, no al ejecutar dbt.
Como ya mencionamos, Snowflake no admite cambiar el SQL de una dynamic table. Por eso, cualquier cambio en la definición de tu modelo requiere un --full-refresh.
Ejecutar dbt con --full-refresh hace drop y recrea la dynamic table.
Comparación entre Dynamic Tables en dbt vs dbt Incremental
Dynamic Tables:
- El mecanismo de refresco lo gestiona Snowflake, no dbt.
- Declarativo: solo defines la sentencia select, no la lógica incremental.
Modelos Incrementales:
- El refresco lo gestiona dbt, o lo que sea que esté orquestando a dbt.
- Imperativo: tienes que definir una lógica incremental personalizada.
- Útil cuando necesitas un control más fino sobre cómo se refresca una tabla de forma incremental.
Limitaciones de las Dynamic Tables
Las dynamic tables tienen bastantes limitaciones. Para ver la lista completa, te recomiendo consultar la documentación. Pero estas son las que creo que vas a enfrentar con más frecuencia:
- Las dynamic tables no pueden estar río abajo de materialized views, external tables o streams.
- No puedes crear una dynamic table temporal.
- La documentación de Snowflake menciona que no se puede hacer truncate a una dynamic table. Pero se les escapa aclarar que tampoco se puede hacer ninguna operación DML. Insert, Update y Delete fallarán en una dynamic table. Tiene sentido, porque una dynamic table debe seguir las fuentes subyacentes y la definición SQL.
- No puedes poner el parámetro DATA_RETENTION_TIME_IN_DAYS en cero en tus tablas de origen. Esto es porque
changesen Snowflake se apoya en time travel. El time travel debe estar habilitado. - El target lag debe ser menor que el
data_retention_time_in_daysde las tablas río arriba. - No puedes usar SQL dinámico (variables de sesión) en dynamic tables.
- Las operaciones sobre dynamic tables no quedan registradas en la view
access_historyde Snowflake. - No puedes usar sequences. Por ejemplo, la definición SQL de la dynamic table no puede contener:
select my_sequence.nextval - No puedes usar
samplenitablesampleen la definición de la dynamic table. - Las dynamic tables incrementales clonadas pueden hacer full-refresh al inicializarse.
Mejores prácticas para las Dynamic Tables
Estas son mis principales recomendaciones a la hora de usar Dynamic Tables:
- Define el target lag más largo que tu caso de uso permita. Esto ayuda a reducir los costos de cómputo al minimizar la cantidad de veces que tus tablas se recalculan (refrescan).
- Encadenar dynamic tables es recomendable. Te permite armar pipelines compuestos íntegramente por dynamic tables y views, dejando que Snowflake gestione el refresco.
- Configura el target lag
downstreamen todas las tablas, salvo la última del DAG.- Si tienes varios nodos hoja, puedes usar una controller table para mantener el target lag (y otras propiedades) en una sola tabla a nivel de cuenta. Ejemplo aquí.
- Usa dynamic tables transient para reducir el costo de almacenamiento.
- Usa un time travel más alto en las fuentes.
- Encontrarás más mejores prácticas del equipo de Snowflake aquí.
Precios de las Dynamic Tables
Con las dynamic tables, te cobran por tres conceptos principales:
- Los costos de cómputo asociados al refresco de las tablas
- Los costos de almacenamiento de las propias dynamic tables
- Los costos de cloud services asociados a los refrescos, solo si superan el 10% de tus costos diarios de cómputo
¿Cómo monitorear los costos de las Dynamic Tables?
Snowflake recomienda usar un warehouse dedicado para monitorear el costo de las dynamic tables; sin embargo, yo no recomendaría multiplicar warehouses.
En su lugar, puedes usar una herramienta como SELECT, que te muestra automáticamente el costo de cada dynamic table y cómo va evolucionando con el tiempo.
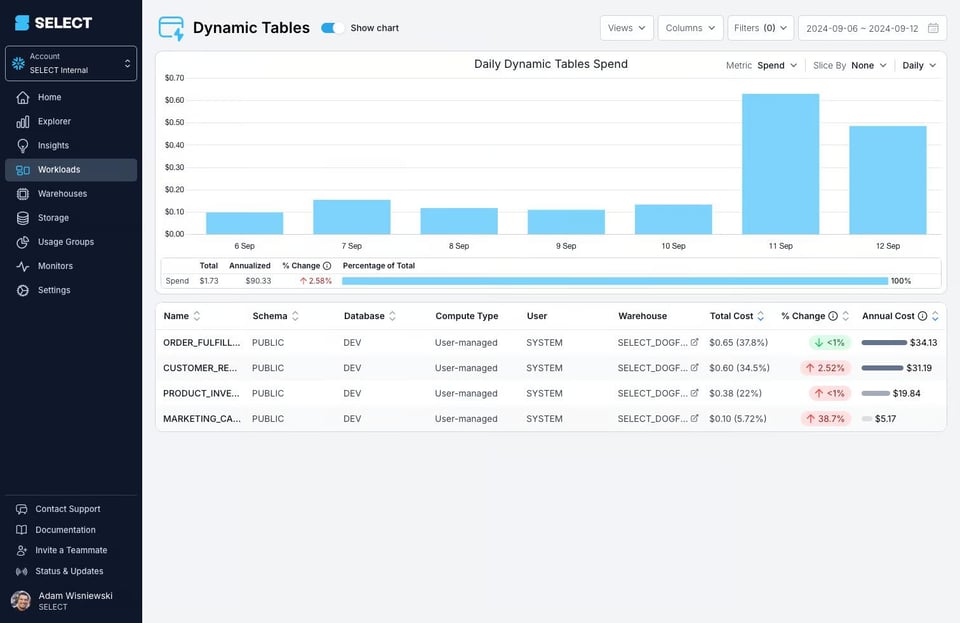
También puedes ver el costo de todo tu DAG de dynamic tables, lo que muchas veces te permite detectar problemas mayores, como procesos que se ejecutan con demasiada frecuencia.
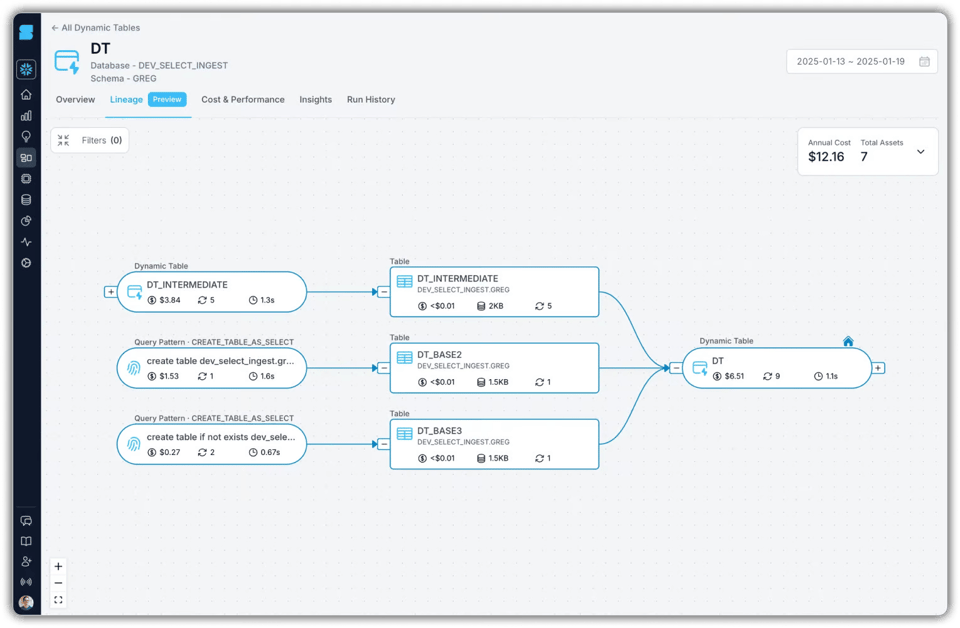
Cierre
Las dynamic tables son una excelente herramienta para sumar a tu caja de pipelines de datos. Los refrescos automáticos y la simplicidad de no tener que especificar la lógica incremental las convierten en una opción muy atractiva. Eso sí, ten en cuenta las muchas limitaciones que tienen, sobre todo las que comentamos en torno al refresco incremental, que son significativas.
¡Ojalá ahora te sientas listo para usar dynamic tables en tus pipelines de datos! Me encantaría conocer tus experiencias con ellas.
Jeff es Data & Analytics Consultant con más de 15 años de experiencia automatizando insights y usando datos para controlar procesos de negocio. Desde el lado tecnológico, se especializa en Snowflake + dbt + Tableau. Desde el lado de negocio, tiene experiencia en Servicios Públicos, Ensayos Clínicos, Publishing, CPG y Manufactura. Escríbele cuando quieras a [email protected].