Qu'est-ce qu'une Dynamic Table Snowflake ?
Dans Snowflake, une Dynamic Table est une table qui matérialise le résultat d'une requête SQL et qui se maintient automatiquement à jour selon une planification. Comme pour une vue, le SQL utilisé pour créer la dynamic table peut atteindre une complexité importante : jointures multiples, différents types de jointures (left join, full join, cartésienne), unions, calculs, etc. Mais contrairement à une vue, qui ne persiste jamais les données, le résultat d'une dynamic table est stocké sous forme de table physique.
Les Dynamic Tables sont rafraîchies à une fréquence que vous définissez, appelée target lag ou target_lag. Lire (select) depuis une dynamic table est donc souvent bien plus performant que lire une vue comportant de nombreuses jointures complexes.
Les dynamic tables constituent un moyen simple et économique de créer des pipelines de données performants qui restent en permanence à jour.
En quoi les Dynamic Tables diffèrent-elles des vues matérialisées ?
Dans Snowflake, une vue matérialisée repose sur une table unique. Elle est persistée sous forme de table physique, ce qui la rend rapide à interroger, tout en restant à jour en temps réel, comme une vue classique.
Voici les principales différences entre les vues matérialisées et les Dynamic Tables.
Jointures
Dans Snowflake, une vue matérialisée ne peut pas contenir de jointures. Cette limitation majeure en restreint fortement l'utilité.
Une Dynamic Table dans Snowflake se rapproche bien davantage d'une vue matérialisée telle qu'on la connaît dans d'autres bases de données, comme PostgreSQL, où les restrictions sur le SQL sont minimes. Cependant, dans Postgres, une vue matérialisée doit être rafraîchie manuellement avec la commande refresh materialized view, alors qu'une Dynamic Table dans Snowflake peut l'être automatiquement en fonction du target lag.
Fréquence de rafraîchissement
Les vues matérialisées dans Snowflake offrent l'avantage d'être toujours à jour. Elles fonctionnent en temps réel, sans aucune action de votre part.
Les Dynamic Tables, en revanche, se rafraîchissent selon une planification. L'utilisateur final doit donc avoir conscience de la fraîcheur des données.
Réécriture de requête
Lorsque vous interrogez les tables de base d'une vue matérialisée, l'optimiseur de Snowflake peut réécrire votre requête pour s'appuyer sur la vue matérialisée.
En revanche, lorsque vous interrogez les données de base d'une dynamic table, Snowflake ne réécrit pas la requête pour exploiter la dynamic table.
Mon avis sur ces différences
Si les vues matérialisées présentent deux atouts (fraîcheur permanente et réécriture de requête), le fait qu'elles reposent obligatoirement sur une table unique limite tellement leur utilité que la dynamic table reste, dans la pratique, le choix le plus fréquent.
Utilisez une vue matérialisée lorsque vous vous limitez à des agrégations, des calculs ou des transformations sur une table unique.
Utilisez une Dynamic Table pour les cas d'usage plus complexes.
Comment créer une Dynamic Table
Une dynamic table se crée à la manière d'un CTAS classique, mais avec quelques paramètres supplémentaires : target_lag, warehouse, et plusieurs autres paramètres optionnels présentés ci-dessous.
Syntaxe complète, reprise de la documentation Snowflake :
CREATE [ OR REPLACE ] [ TRANSIENT ] DYNAMIC TABLE [ IF NOT EXISTS ] <name> (
-- Column definition
<col_name> <col_type>
[ [ WITH ] MASKING POLICY <policy_name> [ USING ( <col_name> , <cond_col1> , ... ) ] ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT '<string_literal>' ]
-- Additional column definitions
[ , <col_name> <col_type> [ ... ] ]
)
TARGET_LAG = { '<num> { seconds | minutes | hours | days }' | DOWNSTREAM }
WAREHOUSE = <warehouse_name>
[ REFRESH_MODE = { AUTO | FULL | INCREMENTAL } ]
[ INITIALIZE = { ON_CREATE | ON_SCHEDULE } ]
Développer le code
create or replace dynamic table my_table
target_lag = '1 Day'
warehouse = 'TRANSFORMING'
refresh_mode = 'incremental'
as
select
customers.name,
count(*) as total_orders
from orders
inner join customers
using (customer_id)
group by 1
Concrètement, votre instruction create pourra ressembler à ceci :
Le rafraîchissement est initialisé immédiatement, car la valeur par défaut de initialize est on_create.
Penchons-nous sur les deux arguments spécifiques que vous utiliserez le plus souvent : target_lag et refresh_mode.
Target Lag
Le target lag correspond au délai maximal toléré entre les données et les modifications de la source. Il s'exprime sous la forme d'un entier accompagné d'une unité temporelle (secondes, minutes, heures, jours). Par exemple, 5 minutes est un target lag valide.
Si vous empilez une dynamic table par-dessus une autre, vous pouvez définir target_lag = downstream pour toutes les dynamic tables de la chaîne, à l'exception de la dernière, qui doit disposer d'une planification temporelle. Prenons l'exemple ci-dessous :
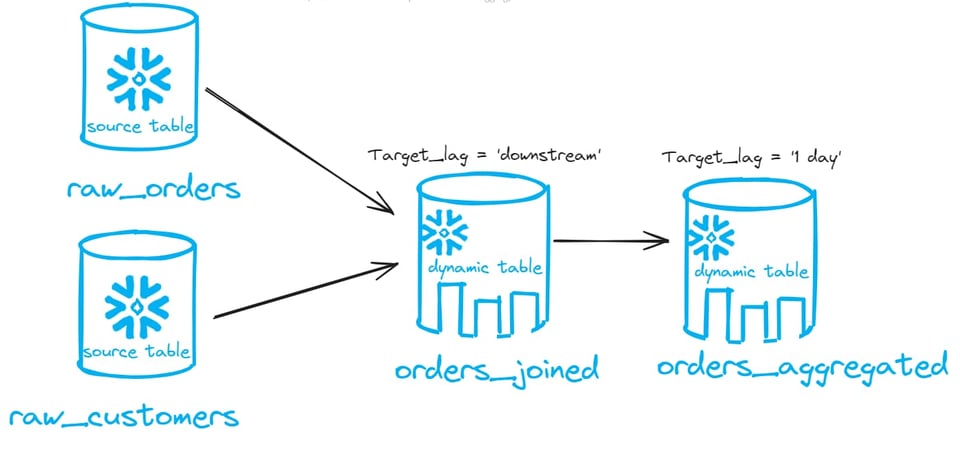
Sur l'image ci-dessus, deux dynamic tables sont chaînées. La première (orders_joined) a un target lag de downstream. La seconde (orders_aggregated) a un target lag d'un jour. Dans ce cas, l'ensemble du DAG est mis à jour une fois par jour. Vous n'avez pas à configurer une planification sur chaque table.
- Si la dernière dynamic table de votre DAG a un target lag de
downstream, vos données ne seront jamais rafraîchies ! - Snowflake le précise dans sa documentation : le target lag n'est pas une garantie. C'est plutôt un objectif que Snowflake s'efforce d'atteindre. Les données des dynamic tables sont rafraîchies au plus près du target lag. Toutefois, ce dernier peut être dépassé en raison de facteurs tels que la taille du warehouse, la volumétrie des données, la complexité des requêtes et autres éléments similaires.
Refresh Mode
Le Refresh Mode peut prendre les valeurs auto, full ou incremental. Le mode par défaut est auto : Snowflake tente un rafraîchissement incrémental et bascule en full s'il n'y parvient pas.
Les Dynamic Tables se rafraîchissent de manière incrémentale en fonction des changes dans les données sources. Vous n'avez rien à fournir concernant une clé primaire ou la détection des modifications : Snowflake s'en charge intégralement, comme par magie ! Pour en savoir plus sur les Changes, consultez la documentation Snowflake ainsi que notre article sur les Streams.
À noter que les Dynamic Tables sont apparentées aux Streams de Snowflake, puisqu'elles s'appuient sur la même technologie de suivi des modifications, changes. Ces fonctionnalités sont d'ailleurs maintenues par la même équipe chez Snowflake !
Les Dynamic Tables offrent une approche déclarative et conviviale pour construire un pipeline.
Les Streams sont impératifs et exigent davantage de personnalisation pour faire fonctionner le pipeline.
Limites du mode de rafraîchissement incrémental
Une dynamic table ne peut pas être rafraîchie de manière incrémentale dans les cas suivants :
- Une fonction SQL non prise en charge comme
current_timestampourandomest utilisée. - Une construction SQL non prise en charge est utilisée :
pivot,unpivot,union,minus,intersect,except.union allest pris en charge en incrémental ! Sauf dans certains cas limites.
- Des clauses
partion_bydifférentes sont utilisées dans plusieurs fonctions de fenêtrage. - Plus de 5 % des données sont modifiées. Un point particulièrement crucial à surveiller !
- Des opérateurs de sous-requête comme
in,any,all,existssont utilisés.
D'autres limitations méritent d'être surveillées ! Ci-dessus, je n'ai listé que celles auxquelles vous serez le plus souvent confronté. Pour une explication complète des limitations du rafraîchissement incrémental des Dynamic Tables, consultez cette page.
Le rafraîchissement auto, un bon choix… mais…
Si vous créez une Dynamic Table avec incremental et qu'un jour Snowflake ne parvient pas à la rafraîchir de manière incrémentale en raison de l'une des limitations documentées, le rafraîchissement échouera. Et il échouera silencieusement, à moins d'avoir mis en place un mécanisme d'alerte pour surveiller les rafraîchissements. Pour éviter ce désagrément, vous pouvez opter pour auto, afin de laisser Snowflake effectuer un full refresh de votre table en cas de besoin. Surveillez ensuite vos dynamic tables pour suivre la manière dont Snowflake gère les rafraîchissements.
Snowflake émet toutefois un avertissement sur l'usage du mode auto :
Pour un comportement cohérent, définissez explicitement le refresh mode sur toutes les tables en production. Le comportement de
AUTOpeut évoluer d'une version de Snowflake à l'autre, ce qui peut entraîner des variations de performance inattendues s'il est utilisé dans des pipelines de production.
Surveillance des Dynamic Tables
L'onglet Data dans Snowsight
La manière la plus simple de surveiller les Dynamic Tables est de passer par l'interface Snowsight.
Dans l'onglet Data de la barre latérale gauche de Snowsight, accédez à votre dynamic table. Cliquez dessus, puis ouvrez l'onglet Refresh History.
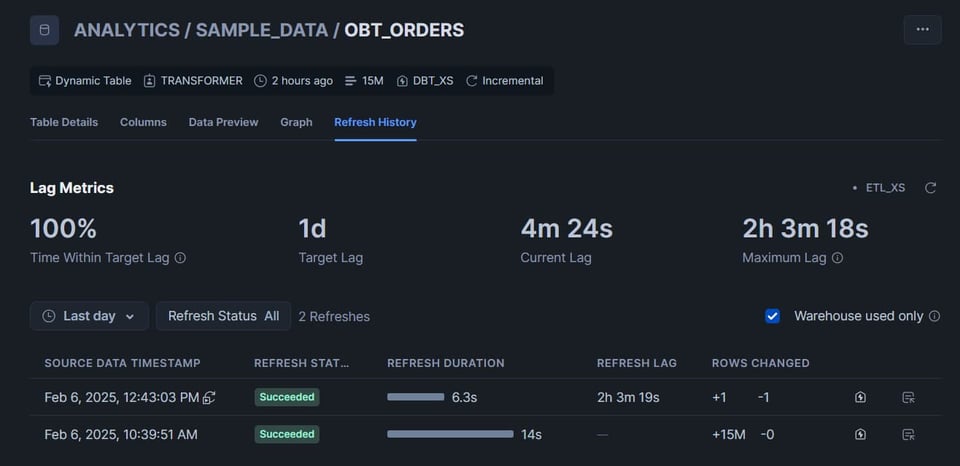
Quelques éléments particulièrement utiles à signaler :
- La section Lag Metrics se révèle très pratique. Vous y voyez si le lag a déjà dépassé le target lag, la fraîcheur actuelle des données, ainsi que le lag maximal jamais atteint sur la table.
- Dans la section d'historique de rafraîchissement, sur la droite, vous trouverez un lien vers le query profile du rafraîchissement (l'icône d'éclair dans une maison). Extrêmement utile pour diagnostiquer les rafraîchissements longs !
Pour une surveillance automatisée des échecs de rafraîchissement, consultez nos articles sur l'envoi d'alertes vers Slack et Microsoft Teams.
L'onglet Monitoring dans Snowsight
Vous pouvez non seulement surveiller chaque DAG individuellement en sélectionnant une dynamic table depuis l'onglet Data, mais aussi visualiser l'état de toutes les dynamic tables au même endroit grâce à l'onglet Monitoring.
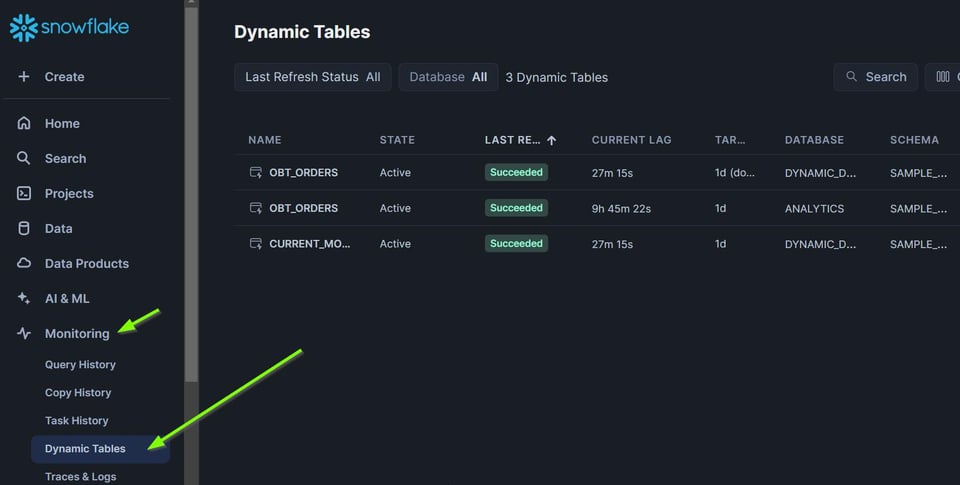
Vous pouvez y trier par Refresh Status pour repérer les rafraîchissements en échec.
Modifier / mettre à jour une dynamic table
Snowflake propose plusieurs propriétés modifiables via alter dynamic table. Voici la liste exhaustive issue de la documentation Snowflake :
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { SUSPEND | RESUME }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> RENAME TO <new_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> SWAP WITH <target_dynamic_table_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> REFRESH [ COPY SESSION ]
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { clusteringAction }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { tableColumnCommentAction }
ALTER DYNAMIC TABLE <name> { SET | UNSET } COMMENT = '<string_literal>'
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> dataGovnPolicyTagAction
Développer le code
Exemples : comment modifier une Dynamic Table
-- Suspend the dynamic table / turn of automatic updates
alter dynamic table my_dynamic_table suspend
-- turn auto updates back on
alter dynamic table my_dynamic_table resume
-- update target lag
alter dynamic table my_dynamic_table set target_lag = '2 Days'
-- change target_lag from time interval to downstream
alter dynamic table my_dynamic_table set target_lag = 'downstream'
-- change refresh_mode from incremental to full
alter dynamic table my_dynamic_table set refresh_mode = 'full'
Développer le code
Modifier le SQL d'une Dynamic Table
Bon à savoir : vous ne pouvez ni ajouter une colonne, ni modifier le SQL via la commande alter ; il faut remplacer entièrement la table. Cela peut se faire avec drop table my_dynamic_table suivi d'une recréation. Ou bien, utilisez create or replace dans le DDL : create or replace dynamic table my_dynamic_table...
Exemple de pipeline de données de bout en bout
Construisons un exemple simple que chacun pourra reproduire. Pour cet exemple, nous allons copier les données d'exemple de la base snowflake_sample_data. (Malheureusement, il est impossible de cloner ou de créer des dynamic tables à partir de données provenant d'un share. Nous allons donc simplement dupliquer les données, puis créer les dynamic tables.)
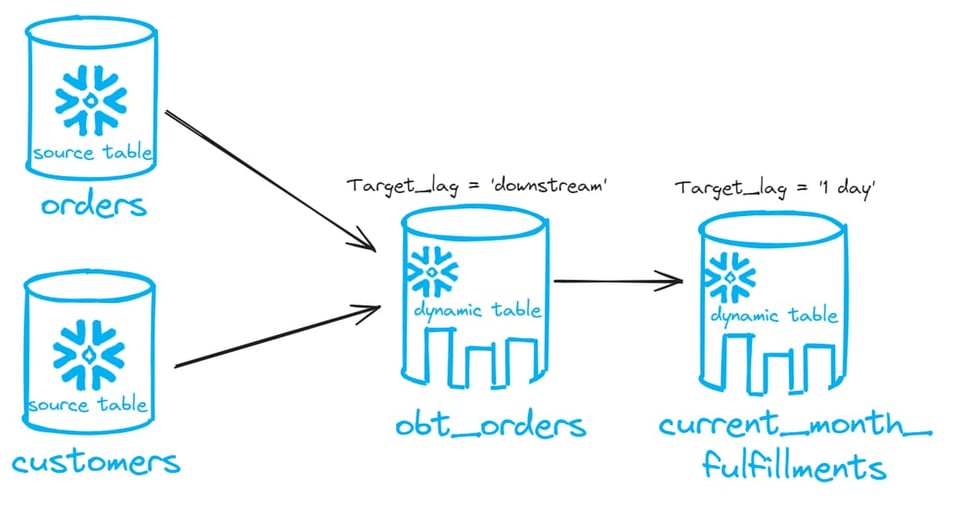
Voici une représentation du DAG que nous allons construire :
Mise en place
Créons quelques objets afin de partir tous du même point de départ.
use role sysadmin;
create warehouse example_wh_xs
warehouse_size = xsmall
auto_suspend = 60
auto_resume = true;
use role securityadmin;
create role example_role;
grant role example_role to user jeff; -- swap in your user
grant all on warehouse example_wh_xs to role example_role;
use role sysadmin;
create database dynamic_demo;
Développer le code
Copions à présent des données d'exemple dans notre nouvelle base. (Encore une fois, le clone ne fonctionnera pas !)
use schema dynamic_demo.sample_data;
create or replace table orders as
select * from
snowflake_sample_data.tpch_sf10.orders;
create or replace table customer as
select * from
snowflake_sample_data.tpch_sf10.customer;
Créons maintenant deux dynamic tables : une pour joindre nos deux nouvelles tables, et une autre pour agréger les données. La première dynamic table du DAG aura un target lag de downstream. La seconde aura un target lag d'un jour. Cela pilotera le lag pour l'ensemble du DAG.
create or replace dynamic table obt_orders
target_lag = 'downstream'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
select *
from orders join customer
on orders.o_custkey = customer.c_custkey;
create or replace dynamic table current_month_fulfillments
target_lag = '1 day'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
with current_month as (
Développer le code
Modifier les données sources et exécuter le pipeline
La table current_month_fulfillments devrait être vide, car aucune commande n'a le statut F ou P pour ce mois. (Vérifiez la clause where dans notre requête ci-dessus.)
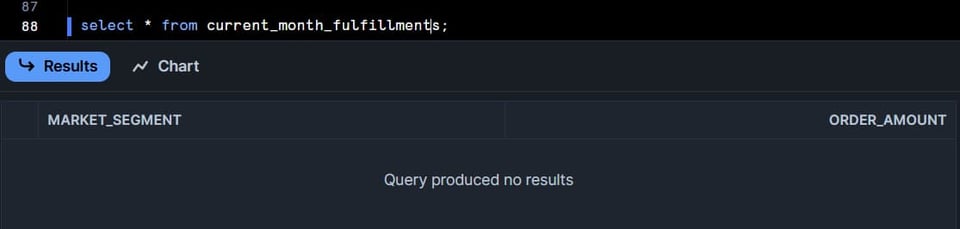
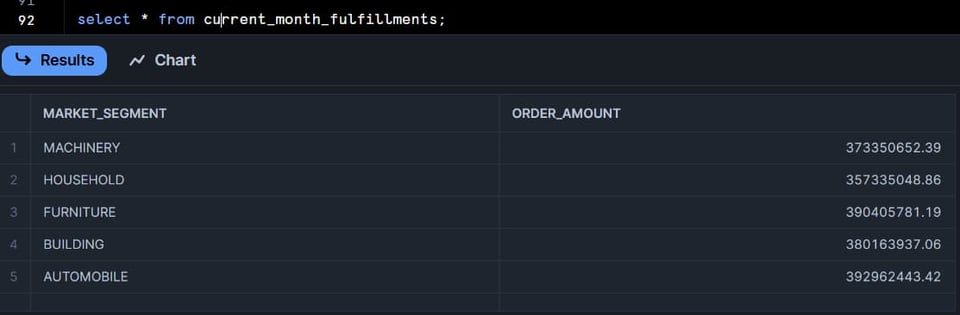
Mettons à jour les données brutes et rafraîchissons manuellement la table current_month_fulfillments :
update orders set o_orderstatus = 'F'
where date_trunc('month', o_orderdate) = '1998-08-01';
-- yes, the max order month in the data is august 1998!
-- 12,466 rows updated
-- manually refresh the last table in the DAG so we don't have to wait:
alter dynamic table current_month_fulfillments refresh;
On observe que la première table s'est rafraîchie automatiquement, puisqu'elle était configurée avec target_lag='downstream' :
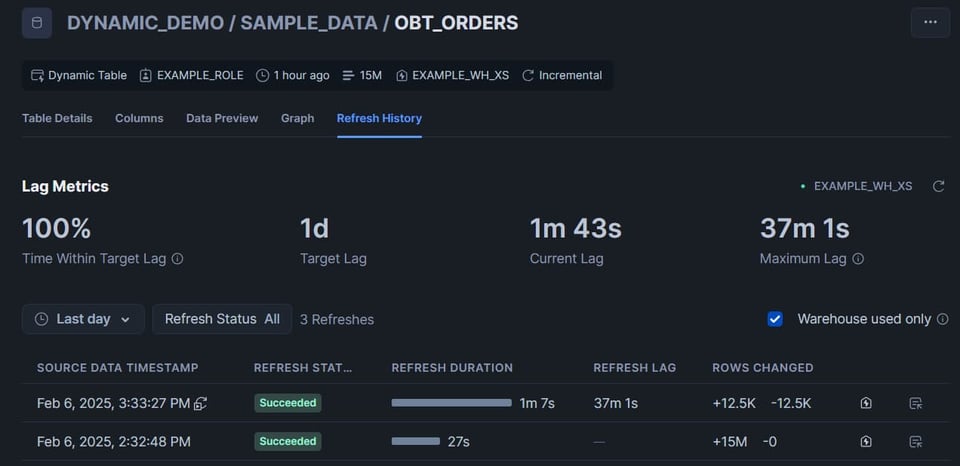
On constate que 12,5 K lignes ont été supprimées puis réinsérées.
En examinant la seconde table du DAG, on remarque que 5 lignes ont été insérées :
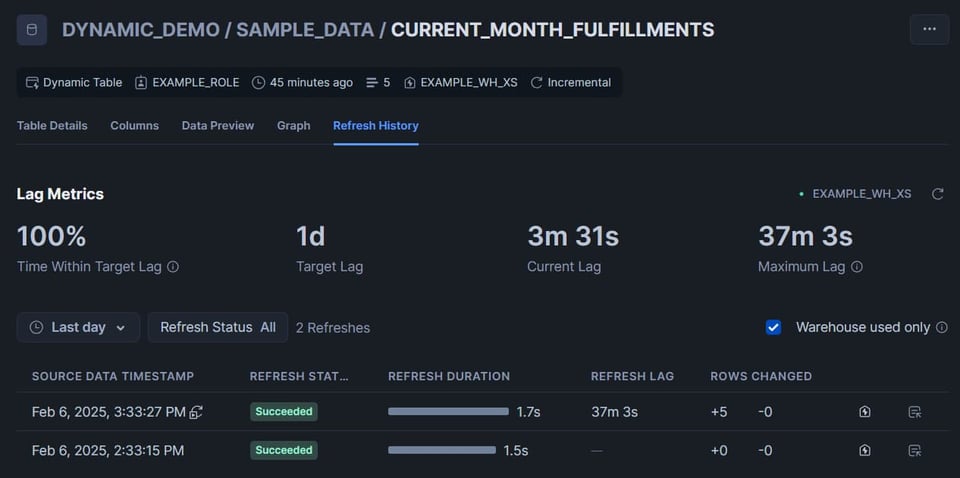
Cliquez sur l'onglet Graph, qui offre une excellente vue d'ensemble de toutes les tables du DAG. Les dynamic tables affichent un statut : Succeeded en vert ou Failed en rouge.
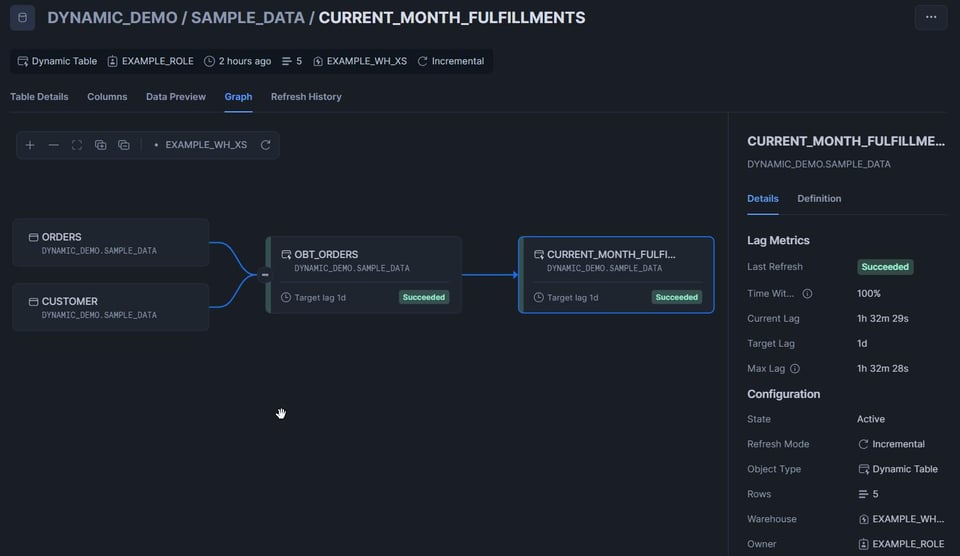
Nettoyage
drop database dynamic_demo;
use role sysadmin;
drop warehouse example_wh_xs;
use role securityadmin;
drop role example_role;
Dynamic Tables avec dbt
Créer une dynamic table dans dbt est aussi simple que d'ajouter cette configuration à votre fichier .sql habituel :
{{ config(
materialized="dynamic_table",
on_configuration_change="apply" | "continue" | "fail",
target_lag="downstream" | "<integer> seconds | minutes | hours | days",
snowflake_warehouse="<warehouse-name>",
refresh_mode="AUTO" | "FULL" | "INCREMENTAL",
initialize="ON_CREATE" | "ON_SCHEDULE",
) }}
Ou dans un fichier de propriétés :
version: 2
models:
- name: [<model-name>]
config:
materialized: dynamic_table
on_configuration_change: apply | continue | fail
target_lag: downstream | <time-delta>
snowflake_warehouse: <warehouse-name>
refresh_mode: AUTO | FULL | INCREMENTAL
initialize: ON_CREATE | ON_SCHEDULE
Fonctionnement avec dbt
Lors du premier run de dbt, la dynamic table est créée. Lors des runs suivants, dbt constate que la table existe déjà et l'ignore. La table est rafraîchie uniquement selon le target_lag, et non par l'exécution de dbt.
Comme mentionné plus haut, Snowflake ne permet pas de modifier le SQL d'une dynamic table. Toute modification de la définition de votre modèle exige donc un --full-refresh.
Exécuter dbt avec --full-refresh supprime et recrée la dynamic table.
Dynamic Tables dans dbt comparées aux modèles incrémentaux dbt
Dynamic Tables :
- Le mécanisme de rafraîchissement est géré par Snowflake, et non par dbt.
- Approche déclarative : vous définissez uniquement l'instruction select, sans logique incrémentale.
Modèles incrémentaux :
- Le rafraîchissement est géré par dbt, ou par l'outil qui l'orchestre.
- Approche impérative : vous devez définir une logique incrémentale personnalisée.
- À privilégier lorsque vous avez besoin d'un contrôle plus fin sur la manière dont une table est rafraîchie de manière incrémentale.
Limitations des Dynamic Tables
Les dynamic tables comportent un certain nombre de limitations. Pour la liste complète, je vous renvoie à la documentation. Voici toutefois celles auxquelles vous serez le plus probablement confronté :
- Les dynamic tables ne peuvent pas se situer en aval de vues matérialisées, de tables externes ou de streams.
- Vous ne pouvez pas créer de dynamic table temporaire.
- La documentation Snowflake indique qu'il est impossible de faire un truncate sur une dynamic table. Mais elle omet de préciser qu'aucune opération DML n'est possible. Insert, Update et Delete échoueront tous sur une dynamic table. C'est logique, puisqu'une dynamic table doit refléter ses sources sous-jacentes et sa définition SQL.
- Vous ne pouvez pas fixer à zéro le paramètre DATA_RETENTION_TIME_IN_DAYS de vos tables sources. En effet,
changesdans Snowflake s'appuie sur le time travel. Le time travel doit donc être activé. - Le target lag doit être inférieur au
data_retention_time_in_daysdes tables en amont. - Vous ne pouvez pas utiliser de SQL dynamique (variables de session) dans les dynamic tables.
- Les opérations sur les dynamic tables ne sont pas capturées par la vue
access_historyde Snowflake. - Vous ne pouvez pas utiliser de séquences. Par exemple, la définition SQL de la dynamic table ne peut pas contenir :
select my_sequence.nextval - Vous ne pouvez pas utiliser
sampleoutablesampledans la définition de la dynamic table. - Les dynamic tables incrémentales clonées peuvent subir un full-refresh lors de leur initialisation.
Bonnes pratiques pour les Dynamic Tables
Voici mes principales recommandations à garder à l'esprit lorsque vous utilisez des Dynamic Tables :
- Choisissez le target lag le plus long possible compte tenu de votre cas d'usage. Vous réduirez ainsi les coûts de compute en limitant le nombre de recalculs (rafraîchissements) de vos tables.
- Le chaînage des dynamic tables est encouragé. Il vous permet de bâtir des pipelines entièrement constitués de dynamic tables et de vues, en laissant Snowflake gérer le rafraîchissement.
- Définissez un target lag
downstreamsur toutes les tables, sauf la dernière du DAG.- Si vous avez plusieurs nœuds terminaux, vous pouvez utiliser une controller table pour centraliser le target lag (et d'autres propriétés) dans une seule table pour l'ensemble de votre compte. Exemple ici.
- Utilisez des dynamic tables transient pour réduire les coûts de stockage.
- Prévoyez un time travel plus long sur les sources.
- D'autres bonnes pratiques de l'équipe Snowflake sont disponibles ici.
Tarification des Dynamic Tables
Avec les dynamic tables, vous êtes facturé sur trois postes principaux :
- Les coûts de compute liés au rafraîchissement des tables
- Les coûts de stockage des dynamic tables elles-mêmes
- Les coûts des services cloud liés aux rafraîchissements, uniquement s'ils dépassent 10 % de vos coûts de compute quotidiens
Comment surveiller les coûts des Dynamic Tables ?
Snowflake recommande d'utiliser un warehouse dédié pour suivre le coût des dynamic tables ; je déconseille toutefois de multiplier les warehouses.
Vous pouvez plutôt vous appuyer sur un outil comme SELECT, qui affiche automatiquement le coût de chaque dynamic table et son évolution dans le temps.
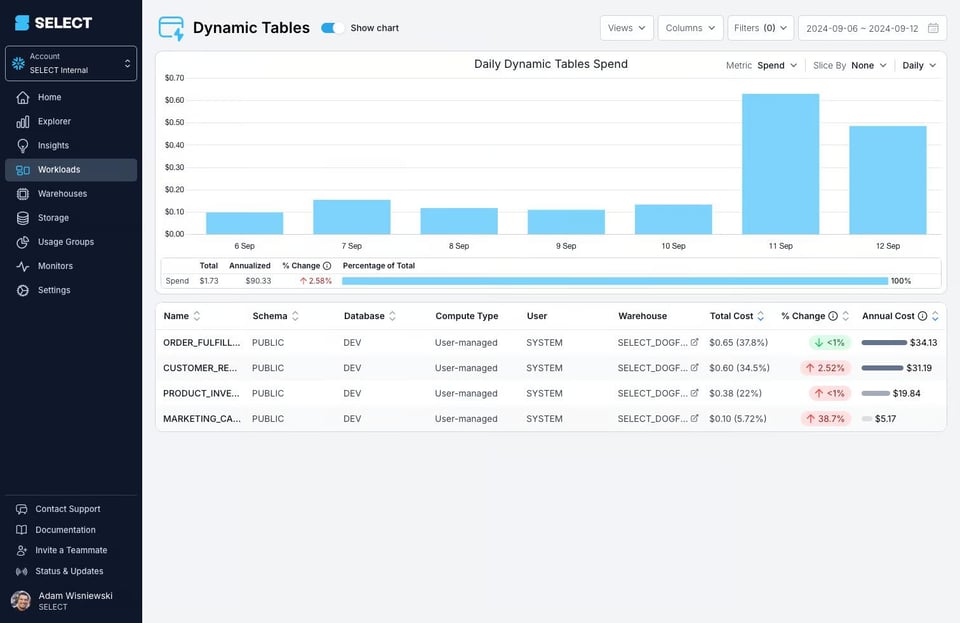
Vous pouvez aussi visualiser le coût de l'ensemble de votre DAG de dynamic tables, ce qui permet souvent de repérer des problèmes plus larges, comme des exécutions trop fréquentes.
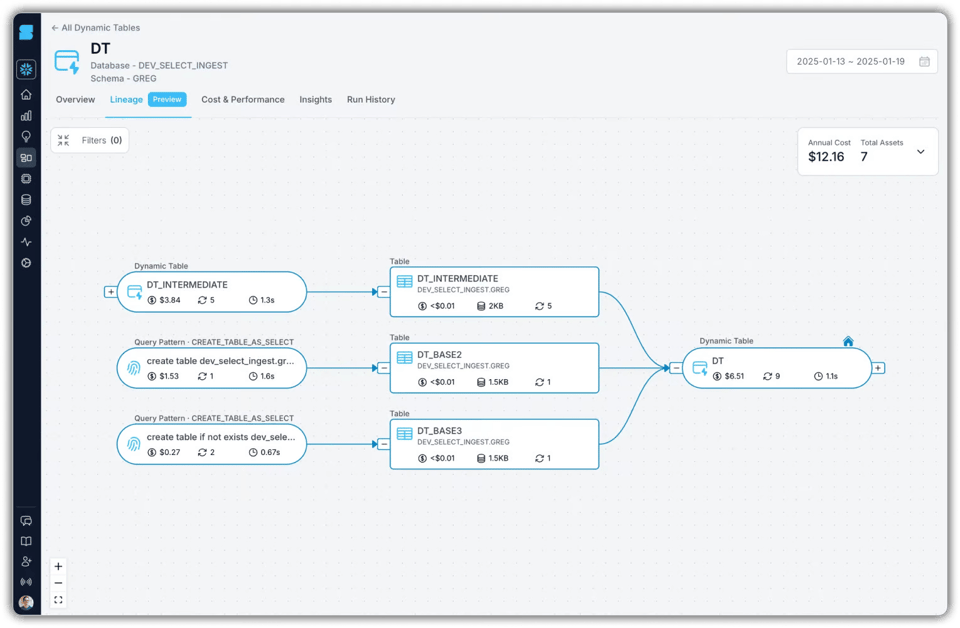
Pour conclure
Les dynamic tables sont un excellent outil à intégrer à votre boîte à outils de pipelines de données. Les rafraîchissements automatisés et le confort de ne pas avoir à spécifier de logique incrémentale en font une option particulièrement séduisante. Gardez simplement à l'esprit les nombreuses limitations des dynamic tables, en particulier celles évoquées autour du rafraîchissement incrémental, qui sont loin d'être anecdotiques.
J'espère que vous vous sentez désormais prêt à intégrer les dynamic tables à vos pipelines de données ! Je serais ravi d'échanger sur vos retours d'expérience.
Jeff est consultant Data & Analytics, fort de plus de 15 ans d'expérience dans l'automatisation des insights et l'exploitation des données pour piloter les processus métier. Côté technologie, il est spécialisé sur Snowflake + dbt + Tableau. Côté secteurs, il intervient dans les services publics, les essais cliniques, l'édition, les biens de grande consommation et l'industrie. N'hésitez pas à le contacter à tout moment : [email protected].