Snowflakeのダイナミックテーブルとは?
Snowflakeのダイナミックテーブル(Dynamic Table)は、SQLクエリの結果をマテリアライズし、スケジュールに沿って自動的に最新状態へ保つテーブルです。ビューと同じように、定義するSQLには複数テーブルの結合、さまざまな結合タイプ(left join、full join、Cartesian)、union、計算など、かなり複雑な処理を含められます。一方で、データを保持しないビューとは違い、ダイナミックテーブルは結果を物理テーブルとして永続化します。
更新頻度は「target lag」(target_lag)として指定します。そのため、複雑な結合が多いビューをそのまま読むより、ダイナミックテーブルからSELECT(読み取り)するほうがパフォーマンス面で有利になるケースが多くあります。
ダイナミックテーブルは、常に最新状態を保つ高性能なデータパイプラインを、シンプルかつコスト効率よく構築する手段です。
ダイナミックテーブルとマテリアライズドビューの違い
Snowflakeのマテリアライズドビュー(Materialized View)は、単一テーブルに対するビューです。物理テーブルとして永続化されるためクエリは高速ですが、ビューと同様にリアルタイムで最新状態が維持されます。
マテリアライズドビューとダイナミックテーブルの主な違いは次のとおりです。
結合(Join)
Snowflakeのマテリアライズドビューでは結合が使えません。これはマテリアライズドビューの使い勝手を大きく損なう、かなり厳しい制約です。
Snowflakeのダイナミックテーブルは、PostgreSQLなど他のデータベースのマテリアライズドビューに近く、書けるSQLにほとんど制限がありません。ただしPostgresではマテリアライズドビューを refresh materialized view コマンドで手動更新する必要があるのに対し、Snowflakeのダイナミックテーブルはtarget lagに基づいて自動的に更新されます。
更新頻度
Snowflakeのマテリアライズドビューは、常に最新状態が保たれる点が強みです。リアルタイムで反映され、ユーザー側で更新操作をする必要はありません。
一方ダイナミックテーブルは、スケジュールに沿って更新されます。エンドユーザーはデータの鮮度を意識する必要が出てくる場合があります。
クエリの書き換え
マテリアライズドビューのベーステーブルにクエリを投げると、Snowflakeのクエリオプティマイザがクエリを書き換え、代わりにマテリアライズドビューを参照することがあります。
これに対し、ダイナミックテーブルの元データに対するクエリは、Snowflakeが書き換えてダイナミックテーブルを使うことはありません。
違いについての私見
マテリアライズドビューには「常に最新」「クエリ書き換え」という2つの利点がありますが、単一テーブルしか対象にできない制約が大きく、結果としてダイナミックテーブルを選ぶ場面のほうが圧倒的に多くなるはずです。
単一テーブルを集計したり、計算列を加えたり、変換だけを行う用途ならマテリアライズドビューを使いましょう。
もっと複雑なユースケースには、ダイナミックテーブルが向いています。
ダイナミックテーブルの作成方法
ダイナミックテーブルは、おなじみのCTASに似た書き方で作成できますが、target_lag や warehouse といった追加パラメータがあり、その他のオプションパラメータも下記のように指定できます。
Snowflake公式ドキュメントから引用した完全な構文は次のとおりです。
CREATE [ OR REPLACE ] [ TRANSIENT ] DYNAMIC TABLE [ IF NOT EXISTS ] <name> (
-- Column definition
<col_name> <col_type>
[ [ WITH ] MASKING POLICY <policy_name> [ USING ( <col_name> , <cond_col1> , ... ) ] ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT '<string_literal>' ]
-- Additional column definitions
[ , <col_name> <col_type> [ ... ] ]
)
TARGET_LAG = { '<num> { seconds | minutes | hours | days }' | DOWNSTREAM }
WAREHOUSE = <warehouse_name>
[ REFRESH_MODE = { AUTO | FULL | INCREMENTAL } ]
[ INITIALIZE = { ON_CREATE | ON_SCHEDULE } ]
コードを展開
create or replace dynamic table my_table
target_lag = '1 Day'
warehouse = 'TRANSFORMING'
refresh_mode = 'incremental'
as
select
customers.name,
count(*) as total_orders
from orders
inner join customers
using (customer_id)
group by 1
実際の create 文は、次のような形になるでしょう。
initialize のデフォルト値が on_create のため、作成と同時に更新が開始されます。
それでは、最も使う2つの固有パラメータ、target_lag と refresh_mode を詳しく見ていきましょう。
Target Lag
target lagとは、ソースデータの変更からどれだけ遅れてもよいかを示す最大時間のことです。整数と時間単位(seconds、minutes、hours、days)で指定します。たとえば 5 minutes は有効なtarget lagです。
ダイナミックテーブルを別のダイナミックテーブルの上に重ねる場合、チェーン内の最後のテーブル以外はすべて target_lag = downstream を指定し、最後のテーブルだけ時間スケジュールを設定します。次の例を見てみましょう。
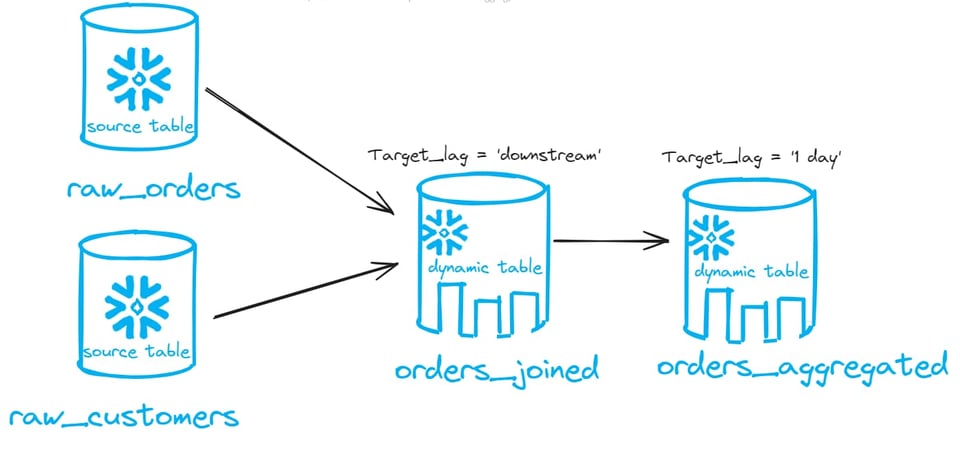
上図では、2つのダイナミックテーブルが連結されています。1つ目(orders_joined)のtarget lagは downstream、2つ目(orders_aggregated)のtarget lagは1日です。この場合、DAG全体が1日に1回更新されることになり、各テーブルごとにスケジュールを設定する必要はありません。
- DAGの末端のダイナミックテーブルのtarget lagを
downstreamにすると、データはまったく更新されなくなるので注意してください。 - Snowflakeのドキュメントでは次のように注意喚起されています。target lagは保証値ではなく、Snowflakeが達成を目指す目標値です。ダイナミックテーブルのデータはtarget lagの範囲にできる限り近づくよう更新されますが、ウェアハウスサイズ、データ量、クエリの複雑さなどの要因によって、target lagを超過することもあります。
Refresh Mode
Refresh Modeには auto、full、incremental の3種類があります。デフォルトは auto で、まずインクリメンタル更新を試み、できない場合はフル更新にフォールバックします。
ダイナミックテーブルは、ソースデータの changes に基づいてインクリメンタルに更新されます。主キーや変更検知のロジックを指定する必要はなく、Snowflakeが裏側ですべて自動的に処理してくれます。Changesの詳細はSnowflake公式ドキュメントや、当社のStreamsに関するブログ記事をご参照ください。
ちなみにダイナミックテーブルはSnowflakeのStreamsとも関連があり、内部では同じ変更追跡技術である changes を使っています。実際、これらの機能はSnowflake社内の同じチームが開発・運用しているそうです。
ダイナミックテーブルは、宣言的でユーザーフレンドリーなパイプライン構築方法です。
一方Streamsは命令的で、パイプラインを動かすために多くのカスタマイズが必要になります。
インクリメンタルリフレッシュモードの制限
次のような場合、ダイナミックテーブルはインクリメンタルに更新できません。
current_timestampやrandomなど、サポート外のSQL関数を使用している- サポート外のSQL構文(
pivot、unpivot、union、minus、intersect、except)を使用しているunion allはインクリメンタル更新でもサポートされています(一部のエッジケースを除く)
- 複数のウィンドウ関数で異なる
partion_by句を使用している - データの5%を超える変更が発生している(これは特に注意すべきポイントです!)
in、any、all、existsといったサブクエリ演算子を使用している
このほかにも注意すべき制限がいくつかあります。ここで挙げたのは、最も遭遇しやすいと思われるものだけです。インクリメンタルリフレッシュの制限の全リストは、こちらのページでご確認ください。
autoリフレッシュは便利そうに見えるが…
incremental でダイナミックテーブルを作成できても、ある日Snowflakeが上記いずれかの制限に該当してインクリメンタル更新できなくなった場合、更新は失敗します。しかも、アラートの仕組みを別途用意していない限り、サイレントに失敗します。この厄介な状況を避けたいなら、必要に応じてSnowflakeにフル更新へ切り替えてもらえる auto を選ぶ手があります。あわせて、Snowflakeが実際にどう更新しているかをダイナミックテーブル側で監視しておきましょう。
ただし、Snowflakeは auto リフレッシュモードの使用について次のように警告しています。
動作の一貫性を確保するため、本番環境のすべてのテーブルではリフレッシュモードを明示的に設定してください。
AUTOの挙動はSnowflakeのリリース間で変わる可能性があり、本番パイプラインで使うとパフォーマンスに想定外の変化が生じる場合があります。
ダイナミックテーブルの監視
SnowsightのDataタブ
ダイナミックテーブルを監視する最も手軽な方法は、Snowsight UIの利用です。
Snowsight左サイドバーのDataタブから対象のダイナミックテーブルを開き、Refresh Historyタブをクリックします。
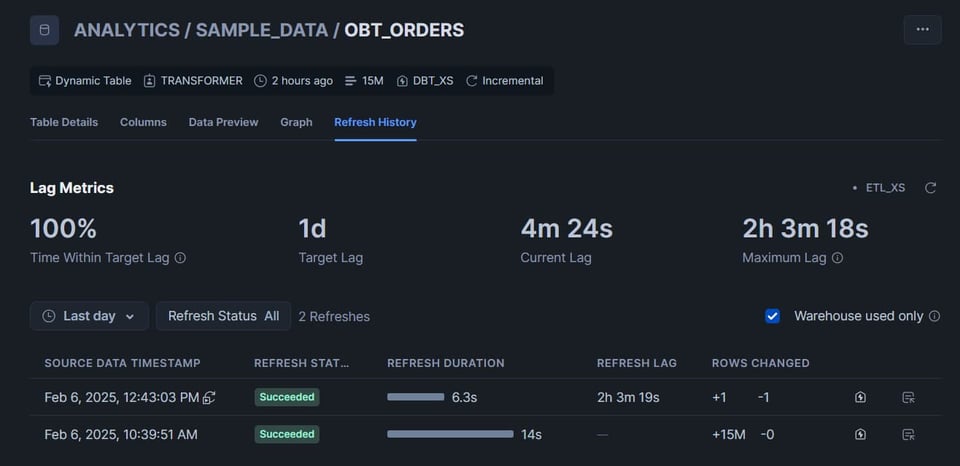
特に押さえておきたいポイントをいくつか紹介します。
- Lag Metricsセクションがとても便利です。ラグがtarget lagを超えたことがあるか、現在のデータの鮮度、テーブルで発生した最大ラグなどがひと目で分かります。
- Refresh Historyのデータセクション右側には、その更新のクエリプロファイルへのリンク(家のなかに稲妻のアイコン)があります。長時間化した更新のトラブルシューティングに非常に役立ちます。
更新失敗の自動監視については、SlackやMicrosoft Teamsへアラートを送る方法を解説した記事をご覧ください。
SnowsightのMonitoringタブ
Dataタブから個別のダイナミックテーブルを選んでDAGを監視するだけでなく、「Monitoring」タブを使えば、すべてのダイナミックテーブルのステータスを一画面で確認できます。
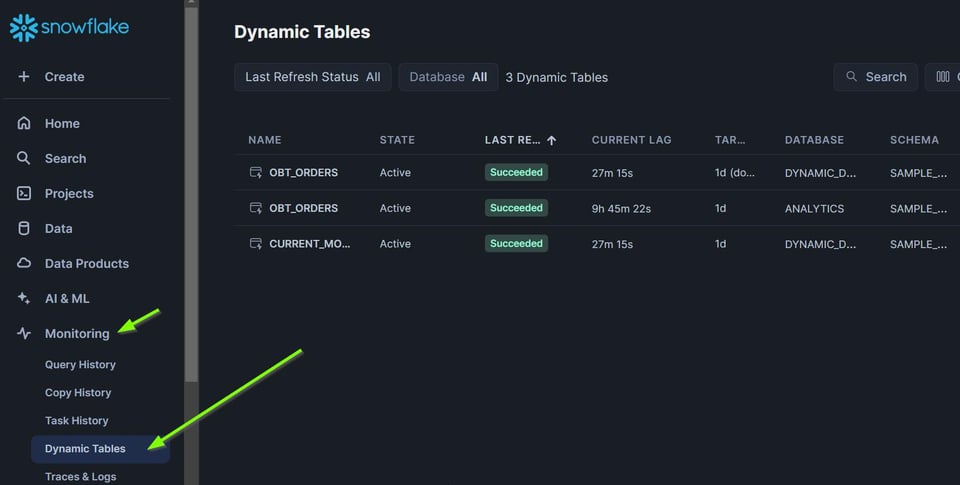
「Refresh Status」で並べ替えれば、失敗した更新をすぐに見つけられます。
ダイナミックテーブルの変更・更新
Snowflakeでは、alter dynamic table で更新できるプロパティがいくつか用意されています。以下はSnowflake公式ドキュメントからの引用で、操作の全リストです。
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { SUSPEND | RESUME }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> RENAME TO <new_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> SWAP WITH <target_dynamic_table_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> REFRESH [ COPY SESSION ]
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { clusteringAction }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { tableColumnCommentAction }
ALTER DYNAMIC TABLE <name> { SET | UNSET } COMMENT = '<string_literal>'
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> dataGovnPolicyTagAction
コードを展開
例:ダイナミックテーブルの変更方法
-- Suspend the dynamic table / turn of automatic updates
alter dynamic table my_dynamic_table suspend
-- turn auto updates back on
alter dynamic table my_dynamic_table resume
-- update target lag
alter dynamic table my_dynamic_table set target_lag = '2 Days'
-- change target_lag from time interval to downstream
alter dynamic table my_dynamic_table set target_lag = 'downstream'
-- change refresh_mode from incremental to full
alter dynamic table my_dynamic_table set refresh_mode = 'full'
コードを展開
ダイナミックテーブルのSQLを編集する
注意したいのは、alter コマンドではカラム追加やSQL変更ができない点です。テーブルそのものを置き換える必要があります。具体的には、drop table my_dynamic_table で削除して作り直すか、DDLで create or replace を使う方法があります(例:create or replace dynamic table my_dynamic_table...)。
エンドツーエンドのデータパイプライン例
誰でも手元で試せるシンプルな例を作ってみましょう。今回は snowflake_sample_data データベースのサンプルデータをコピーして使います。(残念ながら、共有経由のデータの上にダイナミックテーブルをcloneしたり作成したりはできないため、データを複製してからダイナミックテーブルを作成します)
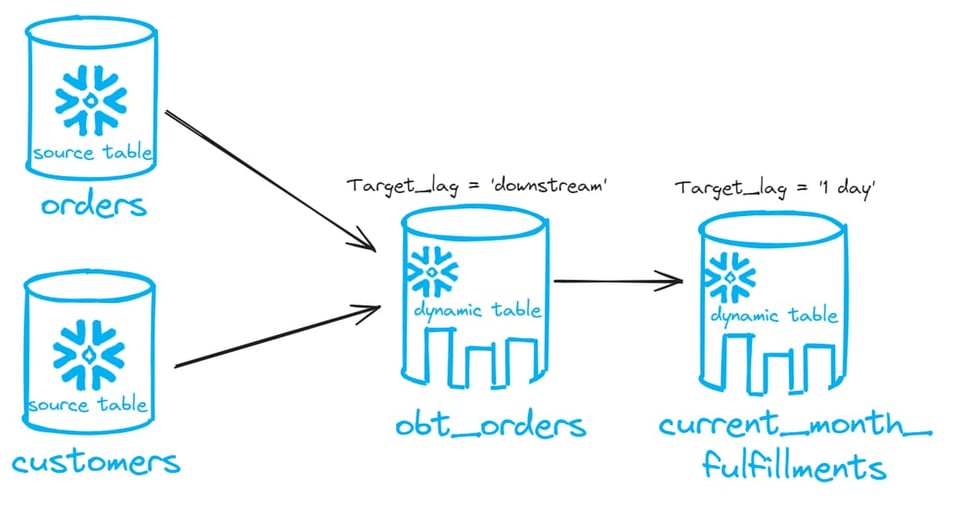
これから作るDAGは次のとおりです。
セットアップ
まずは、共通の出発点を整えるためにいくつかのオブジェクトを新規作成しておきましょう。
use role sysadmin;
create warehouse example_wh_xs
warehouse_size = xsmall
auto_suspend = 60
auto_resume = true;
use role securityadmin;
create role example_role;
grant role example_role to user jeff; -- swap in your user
grant all on warehouse example_wh_xs to role example_role;
use role sysadmin;
create database dynamic_demo;
コードを展開
続いて、新しいデータベースにサンプルデータをコピーします。(繰り返しになりますが、cloneは使えません!)
use schema dynamic_demo.sample_data;
create or replace table orders as
select * from
snowflake_sample_data.tpch_sf10.orders;
create or replace table customer as
select * from
snowflake_sample_data.tpch_sf10.customer;
次に、2つのダイナミックテーブルを作成します。1つは新規作成した2つのテーブルを結合するテーブル、もう1つはデータを集計するテーブルです。DAGの1つ目のダイナミックテーブルにはtarget lag downstream を、2つ目のダイナミックテーブルにはtarget lag 1日を設定します。これでDAG全体のラグをコントロールします。
create or replace dynamic table obt_orders
target_lag = 'downstream'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
select *
from orders join customer
on orders.o_custkey = customer.c_custkey;
create or replace dynamic table current_month_fulfillments
target_lag = '1 day'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
with current_month as (
コードを展開
ソースデータを変更してパイプラインを動かす
current_month_fulfillments テーブルにはデータが入らないはずです。対象月の注文にFまたはPステータスのものが存在しないからです。(上記クエリの where 句を確認してください)
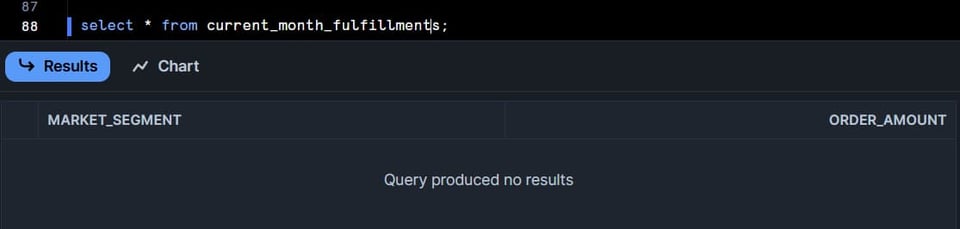
では、元データを更新してから current_month_fulfillments テーブルを手動で更新してみましょう。
update orders set o_orderstatus = 'F'
where date_trunc('month', o_orderdate) = '1998-08-01';
-- yes, the max order month in the data is august 1998!
-- 12,466 rows updated
-- manually refresh the last table in the DAG so we don't have to wait:
alter dynamic table current_month_fulfillments refresh;
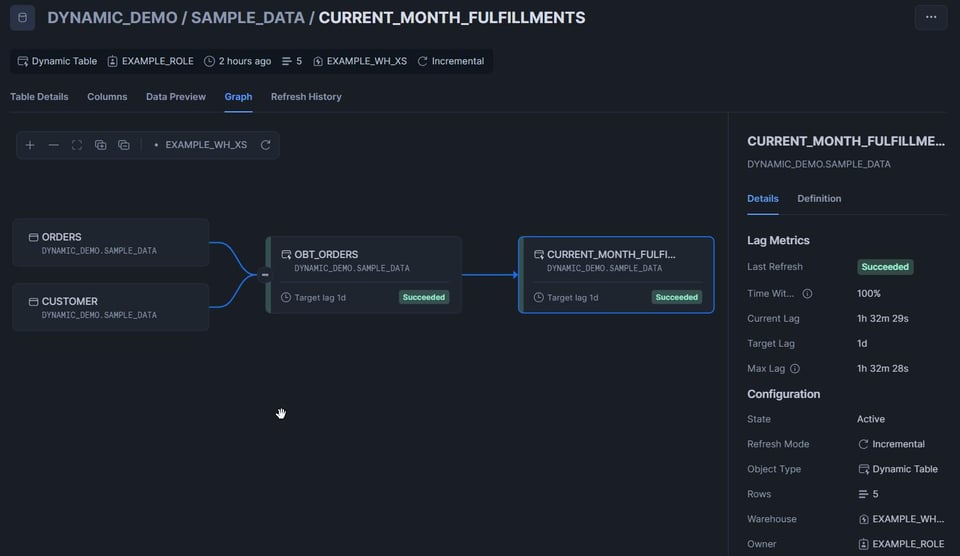
1つ目のテーブルも自動で更新されたことが分かります。target_lag='downstream' に設定していたためです。
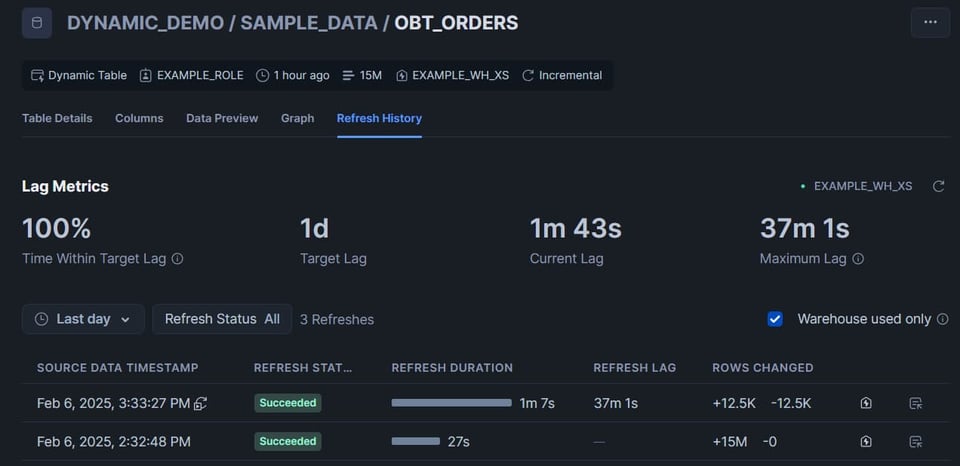
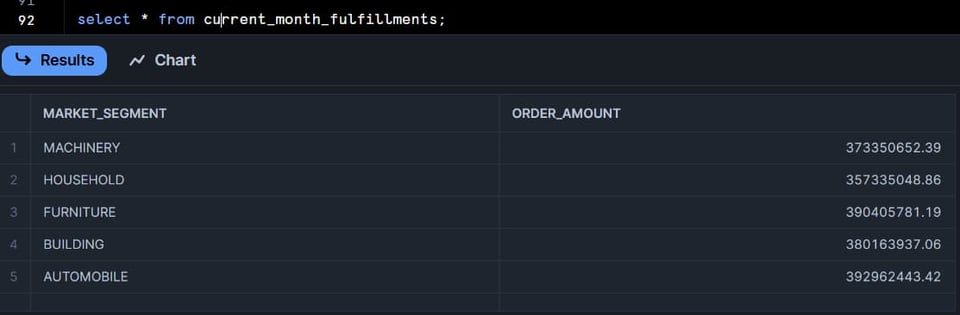
12.5K行が削除され、再挿入されたことが確認できます。
DAGの2つ目のテーブルを見てみると、5行が挿入されています。
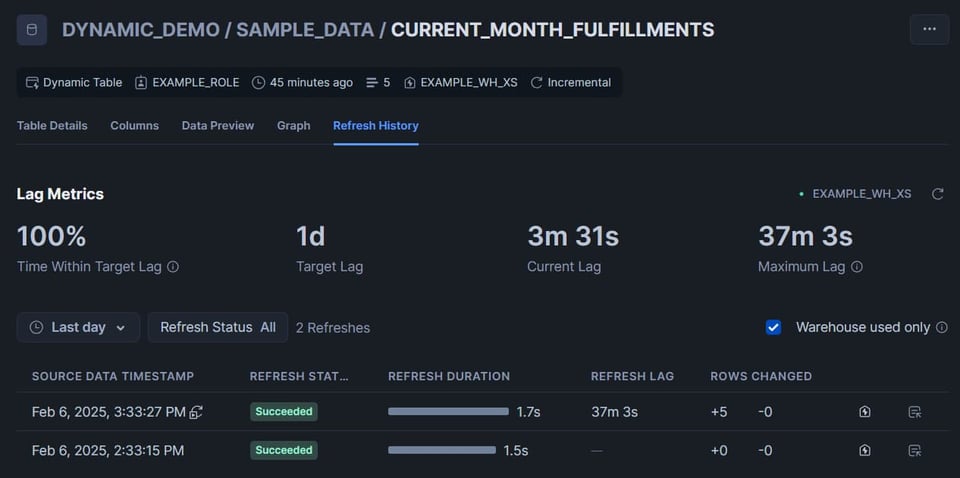
「Graph」タブをクリックすると、DAG内のすべてのテーブルを俯瞰できる便利なビューが表示されます。ダイナミックテーブルにはステータスが表示され、成功なら緑の「Succeeded」、失敗なら赤の「Failed」が示されます。
クリーンアップ
drop database dynamic_demo;
use role sysadmin;
drop warehouse example_wh_xs;
use role securityadmin;
drop role example_role;
dbtでのダイナミックテーブル
dbtでダイナミックテーブルを作成するのはとても簡単で、通常の.sqlファイルに次のconfigを追加するだけです。
{{ config(
materialized="dynamic_table",
on_configuration_change="apply" | "continue" | "fail",
target_lag="downstream" | "<integer> seconds | minutes | hours | days",
snowflake_warehouse="<warehouse-name>",
refresh_mode="AUTO" | "FULL" | "INCREMENTAL",
initialize="ON_CREATE" | "ON_SCHEDULE",
) }}
もしくは、プロパティファイルで指定する方法もあります。
version: 2
models:
- name: [<model-name>]
config:
materialized: dynamic_table
on_configuration_change: apply | continue | fail
target_lag: downstream | <time-delta>
snowflake_warehouse: <warehouse-name>
refresh_mode: AUTO | FULL | INCREMENTAL
initialize: ON_CREATE | ON_SCHEDULE
dbtでの動き方
dbtを初回実行すると、ダイナミックテーブルが作成されます。2回目以降の実行では、テーブルがすでに存在することを検知してスキップします。テーブルが更新されるのは target_lag に従ったタイミングのみで、dbtの実行では更新されません。
前述のとおり、Snowflakeはダイナミックテーブルに対するSQL変更をサポートしていません。そのため、モデル定義に変更を加える場合は --full-refresh が必須となります。
--full-refresh 付きでdbtを実行すると、ダイナミックテーブルがいったん削除され、再作成されます。
dbtのDynamic Tablesとdbt Incrementalの比較
Dynamic Tables:
- 更新のしくみはdbtではなくSnowflakeが管理する
- 宣言的:selectステートメントを書くだけでよく、インクリメンタルロジックを書く必要はない
Incremental Models:
- 更新はdbt、もしくはdbtをオーケストレーションするツールが管理する
- 命令的:インクリメンタルロジックを自分で記述する必要がある
- テーブルのインクリメンタル更新方法をきめ細かく制御したい場合に向いている
ダイナミックテーブルの制限
ダイナミックテーブルには制限が少なくありません。全リストは公式ドキュメントを参照することをおすすめしますが、ここでは特に出くわしやすいものを挙げておきます。
- ダイナミックテーブルは、マテリアライズドビュー、外部テーブル、Streamsの下流には配置できません。
- 一時(temporary)ダイナミックテーブルは作成できません。
- Snowflakeのドキュメントにはダイナミックテーブルをtruncateできないと記載がありますが、実はDML操作全般ができないことには触れられていません。Insert、Update、Deleteはすべて失敗します。ダイナミックテーブルは元のソースとSQL定義に追従する必要があるため、これは当然と言えます。
- ソーステーブルのDATA_RETENTION_TIME_IN_DAYSパラメータを0に設定することはできません。Snowflakeの
changesはタイムトラベルを利用しているため、タイムトラベルが有効である必要があります。 - target lagは、上流テーブルの
data_retention_time_in_daysよりも短く設定しなければなりません。 - ダイナミックテーブル内では動的SQL(セッション変数)を使えません。
- ダイナミックテーブルに対する操作は、Snowflakeの
access_historyビューには記録されません。 - シーケンスは利用できません。たとえば、ダイナミックテーブルのSQL定義に
select my_sequence.nextvalを含めることはできません。 - ダイナミックテーブルの定義に
sampleやtablesampleは使用できません。 - インクリメンタルなダイナミックテーブルをcloneした場合、初期化時にフルリフレッシュが行われることがあります。
ダイナミックテーブルのベストプラクティス
ダイナミックテーブルを使うときに押さえておきたいおすすめポイントは次のとおりです。
- ユースケースが許す範囲で、target lagはできる限り長く設定しましょう。テーブルの再計算(更新)回数を抑えられるため、コンピュートコストの削減につながります。
- ダイナミックテーブルのチェーン化はおすすめです。パイプラインをダイナミックテーブルとビューだけで構成できるようになり、更新はすべてSnowflakeに任せられます。
- DAGの末端のテーブル以外は、すべて
downstreamをtarget lagに設定しましょう。- リーフノードが複数ある場合は、コントローラーテーブルを用意し、アカウント内のtarget lag(およびその他のプロパティ)を1つのテーブルで一元管理する方法があります。例はこちら。
- ストレージコスト削減のため、transient(一時)ダイナミックテーブルを活用しましょう。
- その代わり、ソース側のタイムトラベル期間は長めに設定しておきましょう。
- Snowflakeチームによるその他のベストプラクティスはこちらからご確認いただけます。
ダイナミックテーブルの料金
ダイナミックテーブルで課金されるのは、主に次の3点です。
- テーブル更新にかかるコンピュートコスト
- ダイナミックテーブル自体のストレージコスト
- 更新に伴うクラウドサービスコスト(1日のコンピュートコストの10%を超えた場合のみ)
ダイナミックテーブルのコストはどう監視する?
Snowflakeはダイナミックテーブルのコスト監視に専用ウェアハウスを使うことを推奨していますが、私自身はウェアハウスを増やしすぎないほうがよいと考えています。
代わりにSELECTのようなツールを使えば、各ダイナミックテーブルのコストと、その推移を自動的に可視化できます。
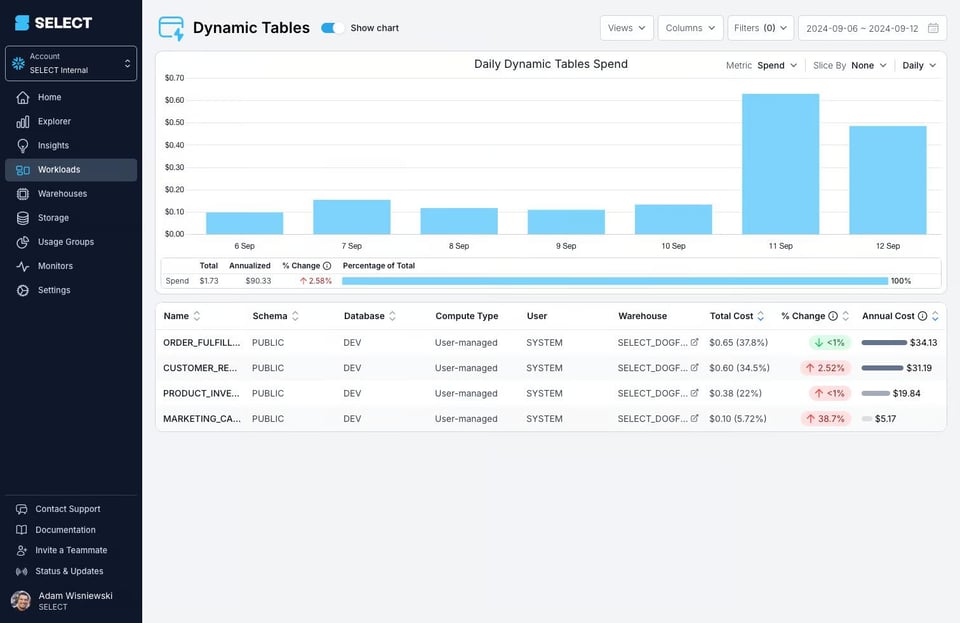
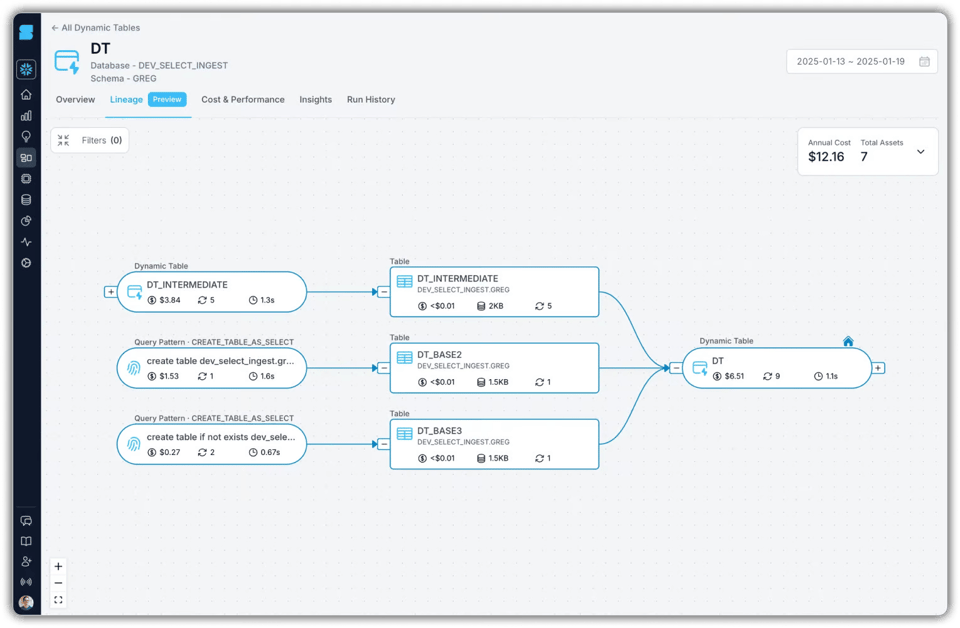
ダイナミックテーブルのDAG全体のコストも把握できるため、過剰な頻度で実行されているといった大きな問題も見つけやすくなります。
まとめ
ダイナミックテーブルは、データパイプラインの選択肢として手元に揃えておきたい優れたツールです。自動更新が組み込まれ、インクリメンタルロジックを自分で書かなくてよいシンプルさは、大きな魅力です。とはいえ、ダイナミックテーブルには多くの制限があり、特に今回取り上げたインクリメンタルリフレッシュ関連の制限は無視できないので、しっかり理解しておきましょう。
これで、データパイプラインでダイナミックテーブルを使いこなす準備は整ったのではないでしょうか。皆さんのダイナミックテーブル活用体験談もぜひお聞かせください。
Jeffはデータ・アナリティクス領域のコンサルタントで、インサイトの自動化やデータを活用した業務プロセスの制御に15年以上携わってきました。テクノロジー面ではSnowflake + dbt + Tableauを得意とし、業務領域では公益事業、臨床試験、出版、CPG、製造業などの経験があります。お気軽にご連絡ください:[email protected]