Cosa sono le Dynamic Table di Snowflake?
In Snowflake una Dynamic Table è una tabella che materializza il risultato di una query SQL e si mantiene aggiornata automaticamente secondo una pianificazione. Come una view, l'SQL che la definisce può avere una complessità significativa: join tra più tabelle, diversi tipi di join (left join, full join, prodotto cartesiano), union, calcoli e così via. A differenza di una view, però, che non persiste mai i dati, il risultato di una dynamic table viene salvato come tabella fisica.
Le Dynamic Table si aggiornano con la frequenza che si specifica, chiamata "target lag" o target_lag. Per questo motivo, leggere da una dynamic table è spesso molto più performante che leggere da una view ricca di join complessi.
Le dynamic table sono un modo semplice ed economico per costruire pipeline di dati performanti e sempre aggiornate.
In cosa differiscono le Dynamic Table dalle Materialized View?
In Snowflake una Materialized View è una view costruita su una singola tabella. Viene persistita come tabella fisica, quindi è veloce da interrogare, ma si mantiene aggiornata in tempo reale, proprio come una view.
Di seguito le differenze principali tra Materialized View e Dynamic Table.
Join
In Snowflake una Materialized View non può contenere join. Una limitazione importante, che ne riduce drasticamente l'utilità.
Una Dynamic Table in Snowflake assomiglia molto di più a una Materialized View di altri database, come PostgreSQL, dove le restrizioni sull'SQL utilizzabile sono pochissime. In Postgres, però, una Materialized View va aggiornata manualmente con il comando refresh materialized view, mentre una Dynamic Table in Snowflake si aggiorna automaticamente in base al target lag.
Frequenza di aggiornamento
Le materialized view in Snowflake hanno il vantaggio di essere sempre aggiornate. Sono in tempo reale e non richiedono alcuna azione per essere mantenute aggiornate.
Le Dynamic Table, invece, si aggiornano secondo una pianificazione. L'utente finale deve quindi essere consapevole di quanto siano freschi i dati.
Query Rewrite
Quando si interrogano le tabelle di base di una materialized view, l'ottimizzatore di query di Snowflake può riscrivere la query in modo da usare la materialized view al loro posto.
Quando si interrogano i dati di base di una dynamic table, invece, Snowflake non riscrive la query per usare la dynamic table.
Le mie considerazioni sulle differenze
Le materialized view hanno due vantaggi (dati sempre freschi e query rewrite), ma il vincolo di basarsi su un'unica tabella ne riduce talmente l'utilità che, nella pratica, si finirà per ricorrere molto più spesso a una dynamic table.
Scegliete una materialized view quando dovete solo aggregare, aggiungere calcoli o trasformare una singola tabella.
Scegliete una Dynamic Table per i casi d'uso più complessi.
Come creare una Dynamic Table
Una dynamic table si crea in modo simile al familiare CTAS, con l'aggiunta di alcuni parametri: target_lag, warehouse e molti altri parametri opzionali riportati di seguito.
Sintassi completa, ripresa dalla documentazione di Snowflake:
CREATE [ OR REPLACE ] [ TRANSIENT ] DYNAMIC TABLE [ IF NOT EXISTS ] <name> (
-- Column definition
<col_name> <col_type>
[ [ WITH ] MASKING POLICY <policy_name> [ USING ( <col_name> , <cond_col1> , ... ) ] ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ COMMENT '<string_literal>' ]
-- Additional column definitions
[ , <col_name> <col_type> [ ... ] ]
)
TARGET_LAG = { '<num> { seconds | minutes | hours | days }' | DOWNSTREAM }
WAREHOUSE = <warehouse_name>
[ REFRESH_MODE = { AUTO | FULL | INCREMENTAL } ]
[ INITIALIZE = { ON_CREATE | ON_SCHEDULE } ]
Espandi codice
create or replace dynamic table my_table
target_lag = '1 Day'
warehouse = 'TRANSFORMING'
refresh_mode = 'incremental'
as
select
customers.name,
count(*) as total_orders
from orders
inner join customers
using (customer_id)
group by 1
In pratica, la vostra istruzione create avrà più o meno questo aspetto:
Il refresh parte subito, perché il valore predefinito di initialize è on_create.
Vediamo nel dettaglio i due argomenti che userete più spesso: target_lag e refresh_mode.
Target Lag
Il target lag è il ritardo massimo che i dati possono accumulare rispetto alle modifiche nei dati di origine. Si esprime con un numero intero e un'unità di tempo (seconds, minutes, hours, days). Ad esempio, 5 minutes è un target lag valido.
Se concatenate una dynamic table sopra un'altra dynamic table, potete impostare target_lag = downstream per tutte le dynamic table della catena, tranne l'ultima, che deve avere una pianificazione temporale. Vediamo l'esempio qui sotto:
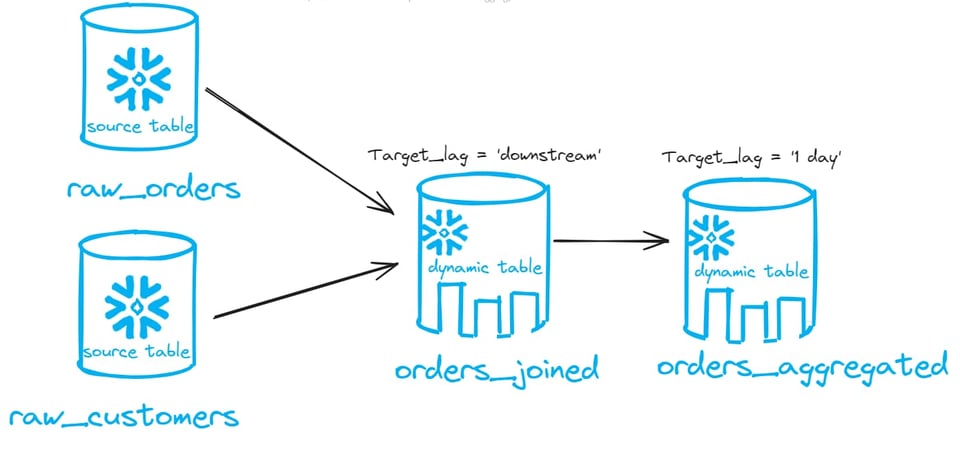
Nell'immagine sopra abbiamo due dynamic table concatenate. La prima (orders_joined) ha un target lag pari a downstream. La seconda (orders_aggregated) ha un target lag di 1 giorno. In questo modo l'intero DAG si aggiornerà una volta al giorno, senza che dobbiate preoccuparvi di impostare una pianificazione per ciascuna tabella.
- Se l'ultima dynamic table del vostro DAG ha un target lag pari a
downstream, i dati non si aggiorneranno mai! - Snowflake riporta questa avvertenza nella documentazione: il target lag non è una garanzia, ma un obiettivo che Snowflake cerca di rispettare. I dati nelle dynamic table vengono aggiornati il più possibile entro il target lag, ma il valore può essere superato a causa di fattori come la dimensione del warehouse, la dimensione dei dati, la complessità della query e altri elementi simili.
Refresh Mode
La Refresh Mode può essere auto, full o incremental. La modalità predefinita è auto: tenta un refresh incrementale e, se non riesce, ripiega su un refresh completo.
Le Dynamic Table si aggiornano in modo incrementale in base ai changes nei dati di origine. Non dovete fornire alcuna informazione sulla chiave primaria né indicare come rilevare i cambiamenti: ci pensa Snowflake, come per magia! Per maggiori informazioni sui Changes, consultate la documentazione di Snowflake e il nostro articolo sugli Streams.
Vale la pena ricordare che le Dynamic Table sono parenti strette degli Streams di Snowflake, perché sotto al cofano utilizzano la stessa tecnologia di change tracking, i changes. Non a caso, queste funzionalità sono curate dallo stesso team in Snowflake!
Le Dynamic Table sono un modo dichiarativo e user friendly per costruire una pipeline.
Gli Streams sono imperativi e richiedono un lavoro di personalizzazione molto più consistente per far funzionare la pipeline.
Limitazioni della refresh mode incrementale
Una dynamic table non può essere aggiornata in modo incrementale se:
- Viene usata una funzione SQL non supportata, come
current_timestamporandom. - Viene usato un costrutto SQL non supportato:
pivot,unpivot,union,minus,intersect,except.union allè supportato per l'incrementale! Tranne in alcuni casi limite.
- Vengono usate clausole
partion_bynon identiche in diverse window function. - Viene modificato più del 5% dei dati. Attenzione, è un punto critico!
- Vengono usati operatori di subquery come
in,any,all,exists.
Ci sono diverse altre limitazioni a cui prestare attenzione: qui sopra ho elencato solo quelle che, a mio parere, incontrerete più spesso. Per la spiegazione completa delle limitazioni del Refresh incrementale per le Dynamic Table, vi rimando a questa pagina.
L'auto refresh può sembrare una buona scelta… ma…
Se create con successo una Dynamic Table in modalità incremental e un giorno Snowflake non riesce ad aggiornarla in modo incrementale a causa di una delle limitazioni documentate, il refresh fallirà. E lo farà in modo silenzioso, a meno che non abbiate predisposto un meccanismo di alerting per monitorare i refresh. Per evitare questo grattacapo, potete usare auto e lasciare che Snowflake esegua un full refresh quando necessario. A quel punto, conviene monitorare le dynamic table per capire come Snowflake sta gestendo gli aggiornamenti.
Snowflake, però, mette in guardia sull'utilizzo della refresh mode auto:
Per garantire un comportamento coerente, impostate esplicitamente la refresh mode su tutte le tabelle di produzione. Il comportamento di
AUTOpotrebbe cambiare tra una release di Snowflake e l'altra, con conseguenti variazioni inattese di performance nelle pipeline di produzione.
Monitorare le Dynamic Table
Monitorare le Dynamic Table
La scheda Data in Snowsight
Il modo più semplice per monitorare le Dynamic Table è l'interfaccia di Snowsight.
Nella scheda Data della barra laterale sinistra di Snowsight, navigate fino alla vostra dynamic table. Cliccatela, poi aprite la scheda Refresh History.
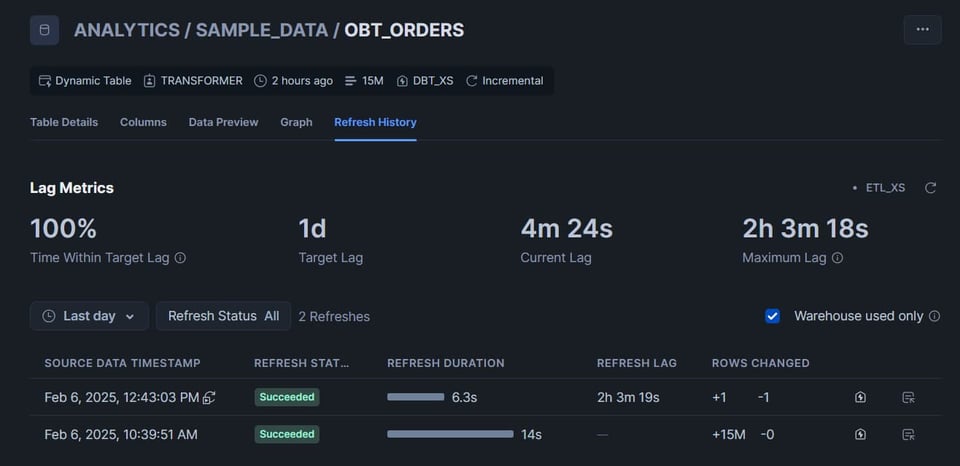
Alcuni punti particolarmente utili da segnalare:
- La sezione Lag Metrics è molto pratica. Qui potete verificare se il lag ha mai superato il target lag, quanto sono freschi i dati attuali e il valore massimo di lag registrato sulla tabella.
- Nella sezione dei dati della refresh history, sul lato destro trovate un link al query profile del refresh (l'icona con il fulmine dentro una casa). Strumento prezioso per fare troubleshooting sui refresh lenti!
Per il monitoraggio automatico dei refresh falliti, date un'occhiata ai nostri articoli su come inviare alert a Slack e Microsoft Teams.
La scheda Monitoring in Snowsight
Oltre a monitorare i singoli DAG selezionando una dynamic table dalla scheda Data, potete anche vedere lo stato di tutte le dynamic table in un unico punto, dalla scheda "Monitoring".
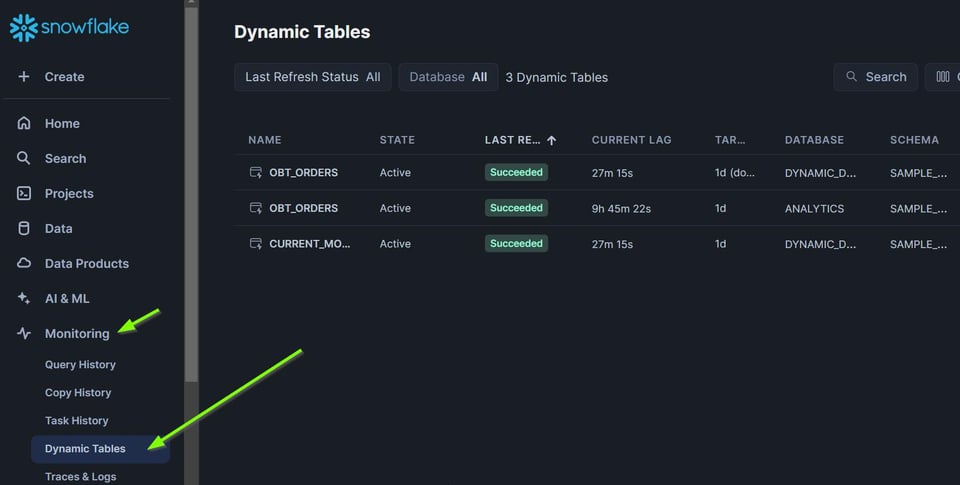
Da qui potete ordinare per "Refresh Status" e individuare i refresh falliti.
Modificare / aggiornare una dynamic table
Snowflake mette a disposizione diverse proprietà aggiornabili tramite alter dynamic table. Ecco l'elenco completo dalla documentazione di Snowflake:
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { SUSPEND | RESUME }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> RENAME TO <new_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> SWAP WITH <target_dynamic_table_name>
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> REFRESH [ COPY SESSION ]
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { clusteringAction }
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> { tableColumnCommentAction }
ALTER DYNAMIC TABLE <name> { SET | UNSET } COMMENT = '<string_literal>'
ALTER DYNAMIC TABLE [ IF EXISTS ] <name> dataGovnPolicyTagAction
Espandi codice
Esempi: come modificare una Dynamic Table
-- Suspend the dynamic table / turn of automatic updates
alter dynamic table my_dynamic_table suspend
-- turn auto updates back on
alter dynamic table my_dynamic_table resume
-- update target lag
alter dynamic table my_dynamic_table set target_lag = '2 Days'
-- change target_lag from time interval to downstream
alter dynamic table my_dynamic_table set target_lag = 'downstream'
-- change refresh_mode from incremental to full
alter dynamic table my_dynamic_table set refresh_mode = 'full'
Espandi codice
Modificare l'SQL di una Dynamic Table
Va sottolineato che non è possibile aggiungere una colonna o modificare l'SQL con il comando alter: bisogna sostituire la tabella per intero. Lo si può fare con un drop table my_dynamic_table seguito dalla ricreazione, oppure usando create or replace nel DDL: create or replace dynamic table my_dynamic_table...
Esempio di pipeline di dati end-to-end
Costruiamo un esempio semplice, che chiunque possa seguire. Copieremo i dati di esempio dal database snowflake_sample_data (purtroppo non è possibile clonare né creare dynamic table a partire da dati provenienti da una share, quindi ci limiteremo a duplicare i dati e poi a creare le dynamic table).
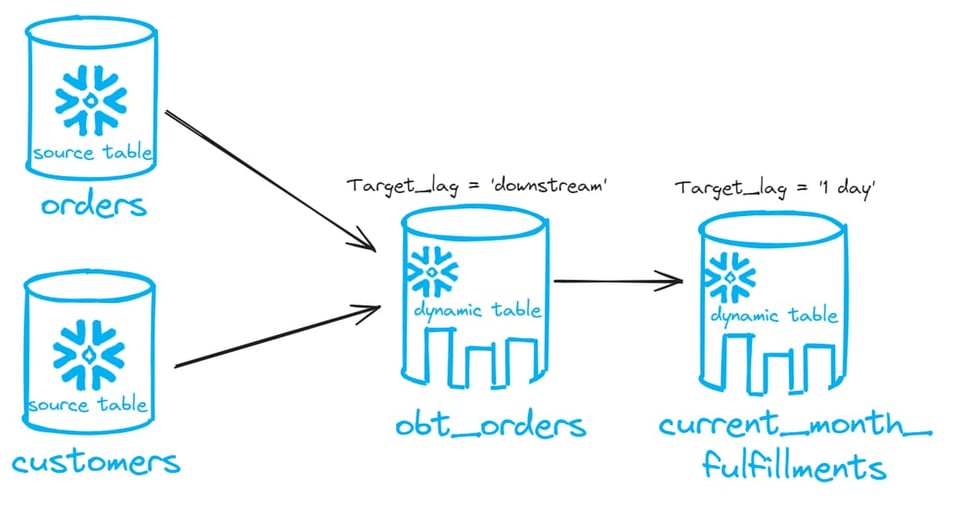
Ecco un'immagine del DAG che andremo a costruire:
Setup
Creiamo qualche nuovo oggetto in modo da partire tutti dallo stesso punto.
use role sysadmin;
create warehouse example_wh_xs
warehouse_size = xsmall
auto_suspend = 60
auto_resume = true;
use role securityadmin;
create role example_role;
grant role example_role to user jeff; -- swap in your user
grant all on warehouse example_wh_xs to role example_role;
use role sysadmin;
create database dynamic_demo;
Espandi codice
Ora copiamo alcuni dati di esempio nel nuovo database (anche qui, clone non funzionerà!).
use schema dynamic_demo.sample_data;
create or replace table orders as
select * from
snowflake_sample_data.tpch_sf10.orders;
create or replace table customer as
select * from
snowflake_sample_data.tpch_sf10.customer;
Adesso creiamo due dynamic table: una che effettua il join tra le due nuove tabelle e una che aggrega i dati. La prima dynamic table del DAG avrà un target lag pari a downstream, la seconda un target lag di 1 giorno. Sarà quest'ultima a governare il lag dell'intero DAG.
create or replace dynamic table obt_orders
target_lag = 'downstream'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
select *
from orders join customer
on orders.o_custkey = customer.c_custkey;
create or replace dynamic table current_month_fulfillments
target_lag = '1 day'
warehouse = 'EXAMPLE_WH_XS'
refresh_mode = 'incremental'
as
with current_month as (
Espandi codice
Modificare i dati di origine ed eseguire la pipeline
La tabella current_month_fulfillments dovrebbe essere vuota, perché nessun ordine ha stato F o P in quel mese (controllate la clausola where nella query qui sopra).
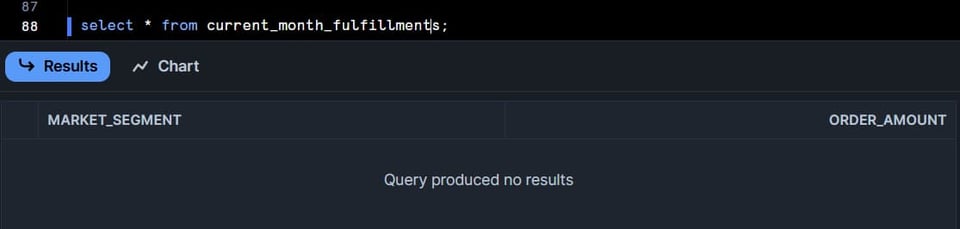
Aggiorniamo ora i dati grezzi e facciamo un refresh manuale della tabella current_month_fulfillments:
update orders set o_orderstatus = 'F'
where date_trunc('month', o_orderdate) = '1998-08-01';
-- yes, the max order month in the data is august 1998!
-- 12,466 rows updated
-- manually refresh the last table in the DAG so we don't have to wait:
alter dynamic table current_month_fulfillments refresh;
Possiamo notare che la prima tabella si è aggiornata in automatico, perché era impostata con target_lag='downstream':
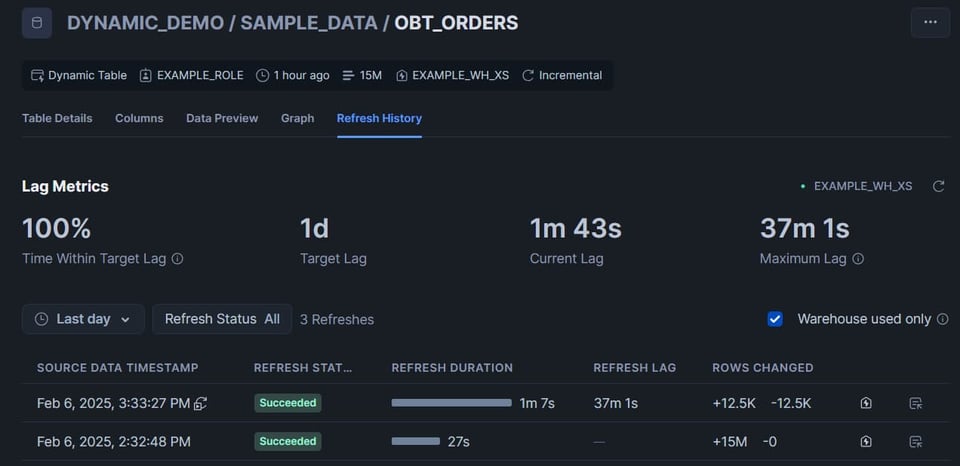
Vediamo che 12,5K righe sono state eliminate e reinserite.
Controllando la seconda tabella del DAG, notiamo invece che sono state inserite 5 righe:
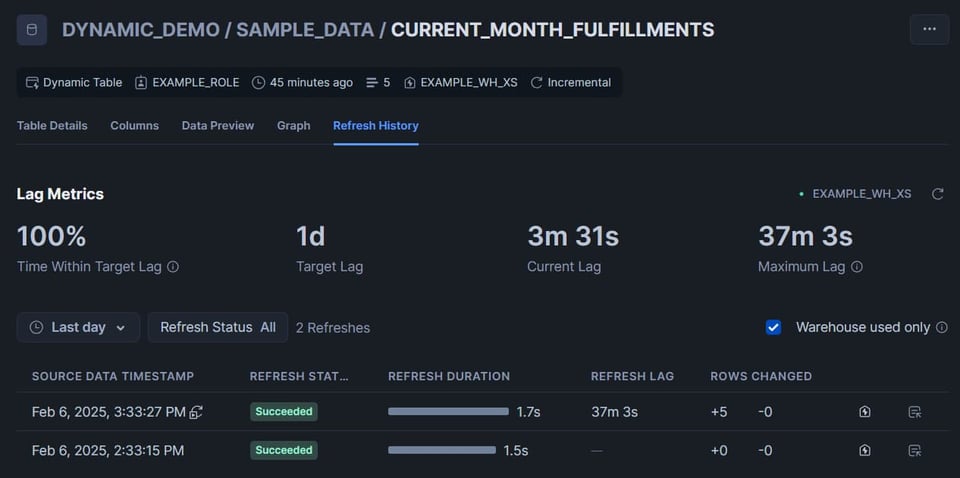
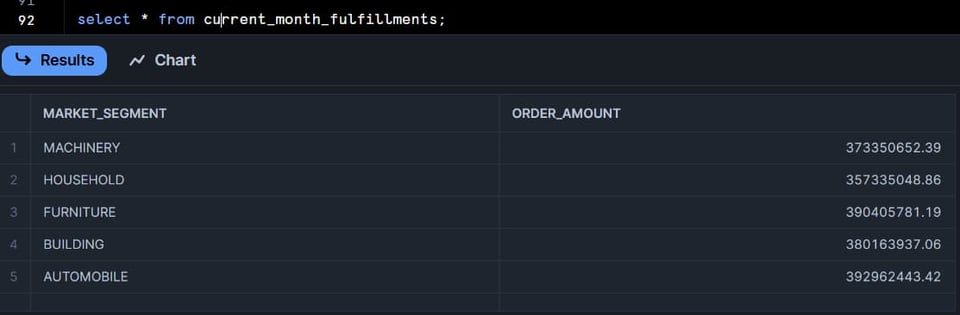
Cliccate sulla scheda "Graph", che offre un'ottima visualizzazione di tutte le tabelle del DAG. Le dynamic table mostreranno uno stato: "Succeeded" in verde o "Failed" in rosso.
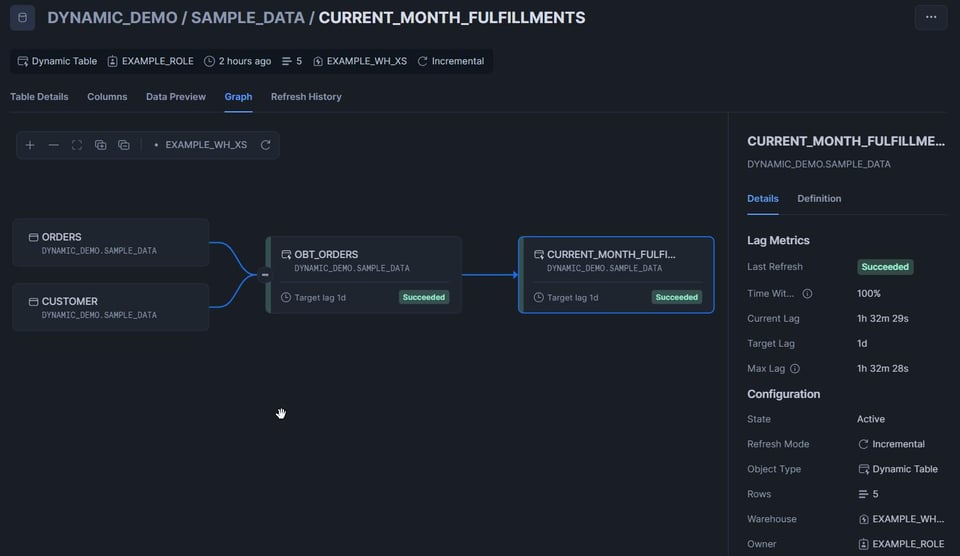
Pulizia
drop database dynamic_demo;
use role sysadmin;
drop warehouse example_wh_xs;
use role securityadmin;
drop role example_role;
Dynamic Table con dbt
Creare una dynamic table in dbt è semplicissimo: basta aggiungere questa configurazione al normale file .sql:
{{ config(
materialized="dynamic_table",
on_configuration_change="apply" | "continue" | "fail",
target_lag="downstream" | "<integer> seconds | minutes | hours | days",
snowflake_warehouse="<warehouse-name>",
refresh_mode="AUTO" | "FULL" | "INCREMENTAL",
initialize="ON_CREATE" | "ON_SCHEDULE",
) }}
Oppure in un property file:
version: 2
models:
- name: [<model-name>]
config:
materialized: dynamic_table
on_configuration_change: apply | continue | fail
target_lag: downstream | <time-delta>
snowflake_warehouse: <warehouse-name>
refresh_mode: AUTO | FULL | INCREMENTAL
initialize: ON_CREATE | ON_SCHEDULE
Come funziona con dbt
Alla prima esecuzione, dbt crea la dynamic table. Nelle esecuzioni successive rileva che la tabella esiste già e la salta. La tabella viene aggiornata solo in base al target_lag, non eseguendo dbt.
Come anticipato, Snowflake non consente di modificare l'SQL di una dynamic table. Di conseguenza, qualsiasi modifica alla definizione del modello richiede un --full-refresh.
Eseguendo dbt con --full-refresh, la dynamic table viene eliminata e ricreata.
Dynamic Table in dbt vs dbt Incremental
Dynamic Table:
- Il meccanismo di refresh è gestito da Snowflake, non da dbt.
- Approccio dichiarativo: si definisce solo la select, non la logica incrementale.
Incremental Model:
- Il refresh è gestito da dbt o dallo strumento che orchestra dbt.
- Approccio imperativo: bisogna definire una logica incrementale personalizzata.
- Da preferire quando serve un controllo più fine sul modo in cui una tabella viene aggiornata in incrementale.
Limitazioni delle Dynamic Table
Le dynamic table presentano diverse limitazioni. Per l'elenco completo vi rimando alla documentazione, ma queste sono quelle che, a mio avviso, incontrerete più di frequente:
- Le dynamic table non possono essere a valle di materialized view, external table o stream.
- Non è possibile creare una dynamic table temporanea.
- La documentazione di Snowflake segnala che non è possibile fare il truncate di una dynamic table. Quello che però non dice è che non è possibile eseguire nessuna operazione DML: Insert, Update e Delete falliranno tutte. Ha senso, dato che una dynamic table deve riflettere le sorgenti sottostanti e la propria definizione SQL.
- Non è possibile impostare a zero il parametro DATA_RETENTION_TIME_IN_DAYS sulle tabelle di origine, perché i
changesin Snowflake si basano sul time travel, che deve quindi essere abilitato. - Il target lag deve essere inferiore al
data_retention_time_in_daysdelle tabelle a monte. - Non è possibile usare SQL dinamico (variabili di sessione) nelle dynamic table.
- Le operazioni sulle dynamic table non vengono registrate nella vista
access_historydi Snowflake. - Non è possibile usare le sequence. Ad esempio, la definizione SQL della dynamic table non può contenere:
select my_sequence.nextval - Non è possibile usare
sampleotablesamplenella definizione della dynamic table. - Le dynamic table incrementali clonate possono eseguire un full refresh all'inizializzazione.
Best practice per le Dynamic Table
Ecco le mie principali raccomandazioni quando si lavora con le Dynamic Table:
- Scegliete il target lag più lungo che il vostro caso d'uso consente. Vi aiuterà a ridurre i costi di compute, limitando il numero di volte in cui le tabelle vengono ricalcolate (refresh).
- Concatenare le dynamic table è una buona idea: permette di costruire pipeline composte interamente da dynamic table e view, lasciando a Snowflake la gestione dei refresh.
- Impostate un target lag
downstreamsu tutte le tabelle, tranne sull'ultima del DAG.- Se avete più nodi foglia, potete usare una tabella controller per centralizzare in un'unica tabella il target lag (e altre proprietà) per il vostro account. Trovate un esempio qui.
- Usate dynamic table transient per ridurre i costi di storage.
- Aumentate il time travel sulle sorgenti.
- Ulteriori best practice del team Snowflake sono disponibili qui.
Prezzi delle Dynamic Table
Con le dynamic table vengono addebitate tre voci principali:
- I costi di compute legati al refresh delle tabelle
- I costi di storage delle dynamic table stesse
- I costi dei cloud services associati ai refresh, ma solo se superano il 10% dei costi di compute giornalieri
Come monitorare i costi delle Dynamic Table?
Snowflake consiglia di usare un warehouse dedicato per monitorare i costi delle dynamic table; personalmente, però, sconsiglio di moltiplicare i warehouse.
Meglio affidarsi a uno strumento come SELECT, che mostra automaticamente il costo di ciascuna dynamic table e come evolve nel tempo.
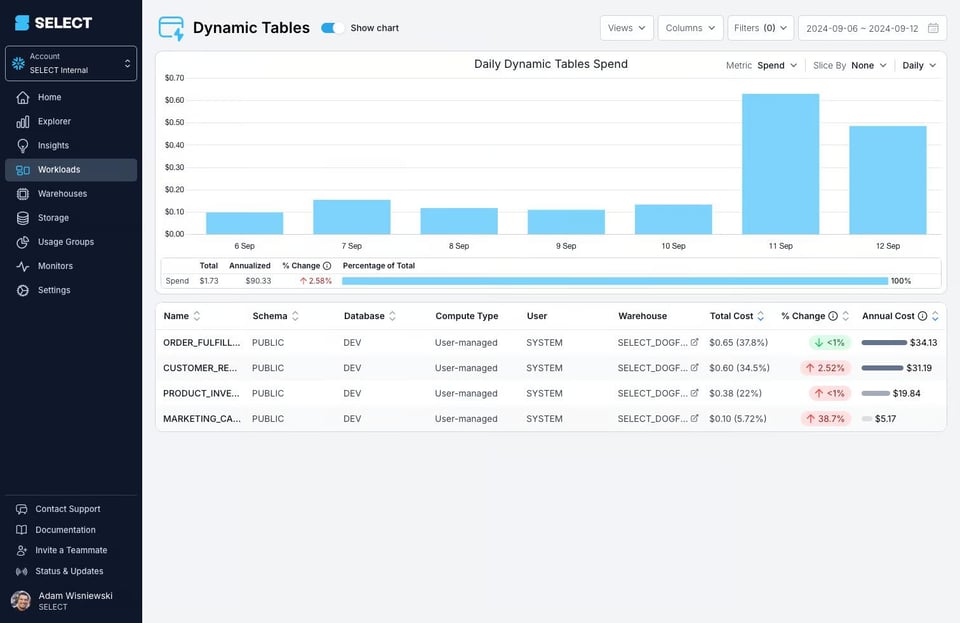
Potete inoltre visualizzare il costo dell'intero DAG di dynamic table, cosa che spesso permette di scovare problemi più ampi, come elaborazioni eseguite con frequenza eccessiva.
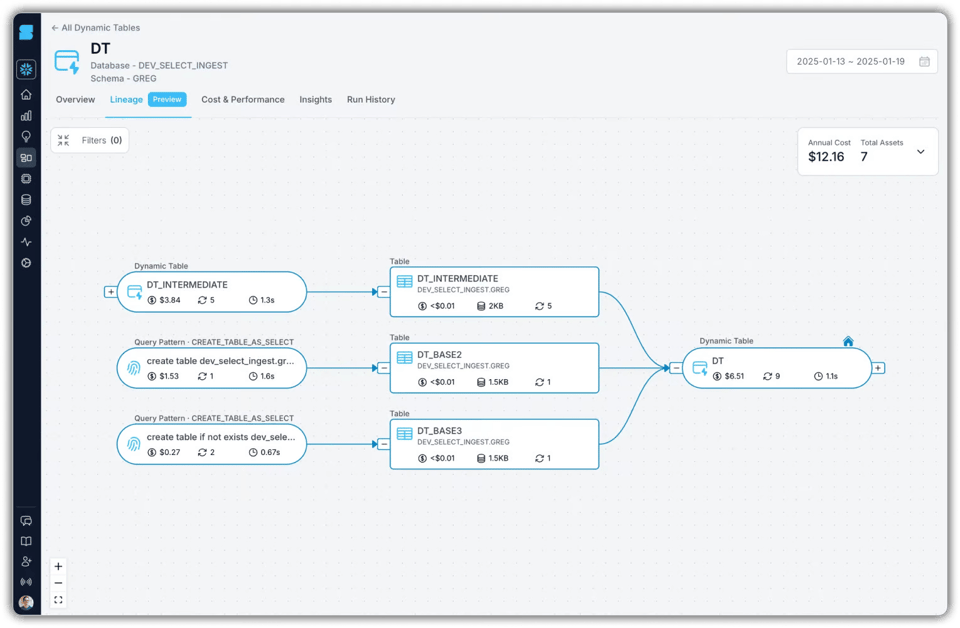
Conclusioni
Le dynamic table sono uno strumento prezioso da tenere nella cassetta degli attrezzi delle vostre pipeline di dati. Refresh automatici e la possibilità di evitare la stesura della logica incrementale ne fanno un'opzione molto interessante. Tenete però a mente le numerose limitazioni, in particolare quelle relative al refresh incrementale di cui abbiamo parlato: sono tutt'altro che trascurabili.
Speriamo che ora vi sentiate pronti a usare le dynamic table nelle vostre pipeline di dati! Saremo felici di conoscere la vostra esperienza con le dynamic table.
Jeff è un Data and Analytics Consultant con oltre 15 anni di esperienza nell'automazione degli insight e nell'uso dei dati per governare i processi di business. Sul fronte tecnologico è specializzato in Snowflake + dbt + Tableau. Sul fronte dei domini di business, ha esperienza in Public Utility, Clinical Trials, Editoria, CPG e Manifatturiero. Potete contattarlo in qualsiasi momento all'indirizzo [email protected].