Einer der ersten Stellschrauben, die sich dbt-Nutzer ansehen, wenn es um die Laufzeit ihrer dbt-Projekte geht, sind die Threads. Warum hat dieser Parameter so großen Einfluss – und welcher Wert ist der richtige? Wir erklären es Ihnen in diesem kurzen Beitrag.
Wenn Sie wenig Zeit haben, lautet die TL;DR-Antwort: "so hoch, dass Queueing entsteht". Für ein typisches dbt-Projekt erreichen Sie das mit 16 Threads. Prüfen lässt sich das während eines laufenden Runs im Queries-Tab in Snowflake.
Was steuert der dbt-Threads-Parameter?
Hintergrund: Multi-Threading in Python
Im Kern ist dbt ein Python-Prozess, der Ihre SQL-Dateien (sogenannte "Models") nimmt und sie gegen das von Ihnen genutzte Data Warehouse ausführt – in diesem Beitrag also Snowflake.
Python ist standardmäßig single-threaded und kann pro Zeitpunkt nur eine Operation ausführen. Die eigentliche Schwerstarbeit der Datenverarbeitung findet bei dbt jedoch in Snowflake statt. Der dbt-Python-Prozess ist daher weitgehend I/O-bound: Er wartet die meiste Zeit darauf, dass Snowflake das gesendete SQL ausführt. Für I/O-bound-Anwendungen setzen Python-Entwickler auf Multi-Threading, um ihre Anwendungen zu beschleunigen. Mit Multi-Threading starten Sie mehrere Threads, die jeweils eigene Operationen ausführen – Ihre Prozesse laufen damit parallel statt nacheinander.
Was sind dbt Threads?
dbt stellt diese Funktionalität über einen Parameter namens threads bereit. Dieser Parameter steuert, wie viele Threads dbt startet, um die für Ihr Projekt nötigen SQL-Operationen parallel auszuführen.
Kurz gesagt: Der Threads-Parameter legt fest, wie viele Models maximal gleichzeitig an Snowflake zur Ausführung geschickt werden.
Snowflake Virtual Warehouses: Aufbau und Auswirkungen auf die Concurrency
Zur kurzen Auffrischung der Compute-Architektur von Snowflakes Virtual Warehouses: Jeder Knoten in einem Snowflake-Warehouse stellt 8 Cores/Threads für die Query-Verarbeitung bereit. Ein X-SMALL-Warehouse hat 1 Knoten und damit 8 Cores/Threads. Ein Small-Warehouse hat das Doppelte (2 Knoten, 16 Cores), ein Medium wiederum das Doppelte eines Small (4 Knoten, 32 Cores) und so weiter.
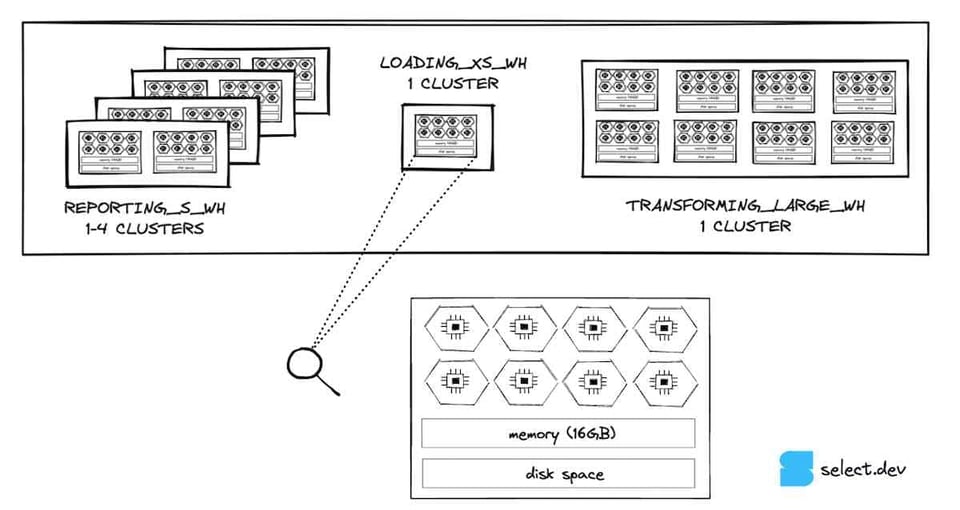
Ein X-SMALL-Warehouse kann zu jedem Zeitpunkt bis zu 8 Queries gleichzeitig ausführen. Mit zunehmender Warehouse-Größe wächst auch das Concurrency-Potenzial, also die Anzahl parallel ausführbarer Queries.
Während der dbt-Threads-Parameter also steuert, wie viele Queries dbt parallel an Snowflake schickt, entscheidet das Snowflake Virtual Warehouse selbst, wie viele davon tatsächlich parallel verarbeitet werden. Sind keine Kapazitäten mehr frei, stellt das Warehouse die Queries in eine Queue und arbeitet sie automatisch ab, sobald wieder Compute-Kapazität verfügbar ist.
Wie wirken sich dbt Threads auf die Laufzeit aus?
dbt-Projekte sind DAGs (Directed Acyclic Graphs) und oft groß und komplex: Ein Model ist meist Grundlage für mehrere andere – und umgekehrt.
Am anschaulichsten lässt sich die Wirkung von Threads über die beiden Extreme erklären.
Mit nur einem einzigen Thread entspricht die Laufzeit eines Projekts mit 500 Models der Summe der Einzellaufzeiten aller Models. Das dauert sehr lange, und das oder die Virtual Warehouses, die die Models ausführen, sind den Großteil dieser Zeit unterausgelastet (mehr zur Warehouse-Auslastung lesen Sie hier). Das Ergebnis: ein sehr langsames Projekt und entsprechend hohe Virtual-Warehouse-Kosten.
Stellen wir uns nun das andere Extrem vor: Wir wählen eine Thread-Zahl, die weit über der Anzahl an Models liegt, die aufgrund der Struktur und Abhängigkeiten des DAGs überhaupt jemals gleichzeitig laufen könnten. Damit sorgen wir dafür, dass dbt versucht, jede in einem Moment lauffähige Query auch tatsächlich auszuführen. Der Engpass verlagert sich so von der Laufzeit der einzelnen Models (mit Ausnahme einzelner Knoten-Abhängigkeiten) auf den Compute-Durchsatz des Virtual Warehouse – die Auslastung wird maximiert. Damit erreichen wir zwei Dinge:
- Queueing (also die vollständige Nutzung der verfügbaren Warehouse-Compute-Leistung)
- Minimierte End-to-End-Laufzeiten des Projekts
In diesem Szenario steigen die Laufzeiten einzelner Models wahrscheinlich, weil Ressourcenkonkurrenz ins Spiel kommt – entscheidend ist aber die End-to-End-Laufzeit. Bei Batch-Jobs ist Queueing positiv: Sie holen so das beste Preis-Leistungs-Verhältnis heraus.
Wie viele dbt Threads sind in Snowflake sinnvoll?
Auf Grundlage der obigen Überlegungen empfehlen wir, den dbt-Threads-Parameter so hoch zu setzen, dass auf Ihrem Warehouse Queueing entsteht. Für die meisten dbt-Projekte ist 16 ein guter Wert. Prüfen Sie aber, ob das für dbt genutzte Virtual Warehouse wirklich voll ausgelastet ist – sichtbar an etwas Query-Queuing.
Hier ein Beispiel für ein dbt-Model-Timing-Chart mit mehr als 16 Threads. Sie sehen: Snowflake kann viele dbt-Ressourcen problemlos parallel ausführen.

Auswirkungen auf das Queueing
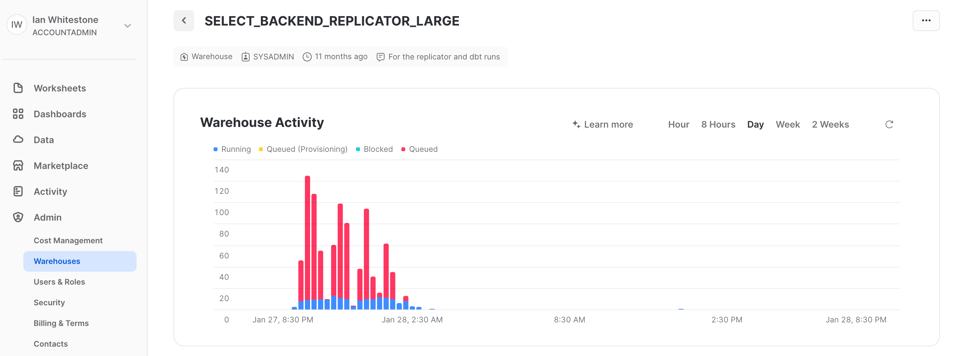
Es gibt mehrere Wege, um Query-Queuing zu prüfen. Eine Möglichkeit ist der Warehouse-Activity-Graph auf der Warehouses-Seite in der Snowsight-UI – er liefert einen schnellen Überblick, wie häufig Queueing im Warehouse auftritt. Im folgenden Screenshot aus unserem dbt-Projekt sehen Sie durchgängiges Queueing in dem Warehouse, das wir für dbt nutzen – genau so soll es sein, denn es zeigt, dass das Warehouse voll ausgelastet ist. Solange die Projektlaufzeit innerhalb Ihres SLA bleibt, ist das Queueing kein Grund zur Sorge.
Welche weiteren Faktoren beeinflussen die dbt-Laufzeiten?
Sind die dbt Threads so konfiguriert, dass der Engpass beim Compute-Durchsatz von Snowflake liegt, gibt es noch weitere Techniken, um dbt-Laufzeiten zu verbessern. Den Links unten folgen Sie für mehr Details:
- Inkrementelle Models
- Queries optimieren, indem Sie Engpässe im Snowflake Query Profile verstehen
- Warehouse-Größe und Multi-Cluster-Konfiguration
Niall Woodward·Co-Founder & CTO von SELECT
Niall ist Co-Founder & CTO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT war Niall Data Engineer bei Brooklyn Data Company und mehreren Startups. Als Open-Source-Enthusiast ist er außerdem Maintainer von SQLFluff und Erfinder der drei dbt-Packages dbt_artifacts, dbt_snowflake_monitoring und dbt_query_tags.
Ian Whitestone·Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT leitete er sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Kostentransparenz.