Le paramètre threads est l'un des premiers réglages que les utilisateurs de dbt examinent lorsqu'ils cherchent à comprendre et à réduire les temps d'exécution d'un projet dbt. Pourquoi ce paramètre a-t-il autant d'influence et quelle valeur lui attribuer ? On vous explique tout dans ce court article.
Si vous manquez de temps, la réponse en bref tient en une phrase : réglez la valeur des threads aussi haut que nécessaire pour générer de la mise en file d'attente. Une valeur de 16 suffit généralement pour un projet dbt classique, et vous pouvez le vérifier dans l'onglet des requêtes de Snowflake pendant une exécution.
Que contrôle le paramètre threads de dbt ?
Le multi-threading en Python en quelques mots
Sur le fond, dbt est essentiellement un processus Python qui prend vos fichiers SQL (vos modèles) et les exécute sur l'entrepôt de données que vous utilisez (Snowflake dans le contexte de cet article).
Par défaut, Python fonctionne en mono-thread : il ne peut effectuer qu'une opération à la fois. Avec dbt, tout le gros du traitement des données se passe côté Snowflake. Le processus Python de dbt est donc essentiellement limité par les opérations d'E/S : il passe la majeure partie de son temps à attendre que Snowflake exécute le SQL qu'il lui envoie. Pour ce type d'applications, les développeurs Python peuvent recourir au multi-threading pour gagner en rapidité. Le multi-threading permet de lancer plusieurs threads, chacun pouvant effectuer ses propres opérations : vos processus s'exécutent ainsi en parallèle plutôt qu'un à un.
Que sont les threads dbt ?
dbt expose cette fonctionnalité via un paramètre nommé threads. Ce paramètre détermine combien de threads dbt lance pour exécuter en parallèle les opérations SQL nécessaires à votre projet.
Pour résumer plus simplement : le paramètre threads définit le nombre maximal de modèles envoyés simultanément à Snowflake pour exécution.
Architecture des Virtual Warehouses Snowflake et implications sur la concurrence
Pour un rappel rapide sur l'architecture compute des virtual warehouses Snowflake, chaque nœud d'un warehouse Snowflake dispose de 8 cœurs/threads pour traiter votre requête. Un warehouse X-SMALL compte 1 nœud, donc 8 cœurs/threads. Un Small en compte deux fois plus (2 nœuds, 16 cœurs), un Medium deux fois plus qu'un Small (4 nœuds, 32 cœurs), et ainsi de suite.
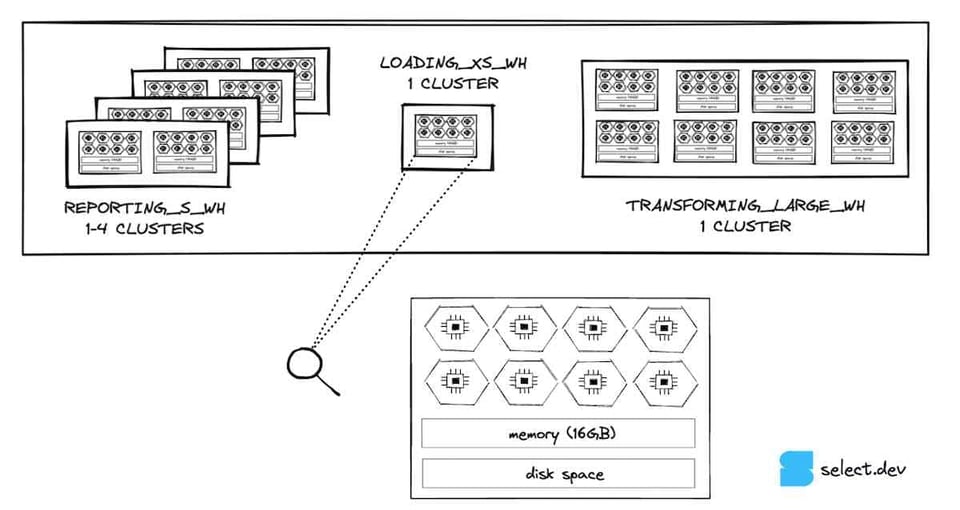
Un warehouse X-SMALL peut donc exécuter jusqu'à 8 requêtes simultanément à un instant t. Plus la taille du warehouse augmente, plus le potentiel de concurrence (le nombre de requêtes exécutables en parallèle) augmente lui aussi.
Ainsi, si le paramètre threads de dbt détermine combien de requêtes sont envoyées en parallèle à Snowflake, c'est le virtual warehouse Snowflake qui décide combien d'entre elles sont réellement traitées en parallèle. Lorsqu'un warehouse ne peut plus traiter de nouvelles requêtes, il les place en file d'attente et les exécute automatiquement dès qu'une capacité de calcul se libère.
Quel est l'impact des threads dbt sur le temps d'exécution ?
Les projets dbt sont des DAG (Directed Acyclic Graphs), souvent volumineux et complexes, où un même modèle peut servir de dépendance à plusieurs autres, et inversement.
Pour bien saisir l'impact des threads, le plus parlant est d'imaginer les deux extrêmes.
Supposons d'abord qu'un seul thread soit défini : la durée d'exécution d'un projet de 500 modèles correspondra à la somme des durées individuelles de chaque modèle. Cela prendra beaucoup de temps, et le ou les virtual warehouses qui exécutent les modèles resteront largement sous-utilisés pendant ce temps (en savoir plus sur l'utilisation des warehouses). Résultat : un projet très lent et des coûts de virtual warehouse à l'avenant.
Imaginons maintenant un nombre de threads largement supérieur au nombre de modèles pouvant tourner en même temps, compte tenu de la taille du DAG et de sa structure de dépendances. Avec ce réglage, dbt tentera d'exécuter à chaque instant toutes les requêtes éligibles. Le goulot d'étranglement du temps d'exécution se déplace alors du temps d'exécution de chaque modèle (hors dépendances en chaîne) vers le débit de calcul du virtual warehouse, ce qui maximise l'efficacité d'utilisation. On obtient ainsi deux choses :
- De la mise en file d'attente (signe que toute la capacité de calcul du warehouse est mobilisée)
- Un temps d'exécution global réduit au minimum
Dans ce cas de figure, les temps d'exécution individuels des modèles risquent d'augmenter du fait de la contention sur les ressources, mais rappelez-vous que l'objectif visé est le temps de bout en bout. Pour des traitements par lots, la mise en file d'attente est une bonne nouvelle : c'est le signe que vous tirez le meilleur parti de votre budget.
Combien de threads dbt utiliser avec Snowflake ?
Au vu de ce qui précède, nous vous recommandons de régler le paramètre threads de dbt à une valeur suffisamment élevée pour générer de la mise en file d'attente sur votre warehouse. Une valeur de 16 fait l'affaire pour la plupart des projets dbt, mais vérifiez que le virtual warehouse utilisé pour dbt est pleinement saturé en vous assurant qu'il y a bien un peu de file d'attente sur les requêtes.
Voici un exemple de graphique de timing des modèles dbt avec plus de 16 threads. On voit clairement que Snowflake peut exécuter de nombreuses ressources dbt en parallèle.

Impact sur la mise en file d'attente
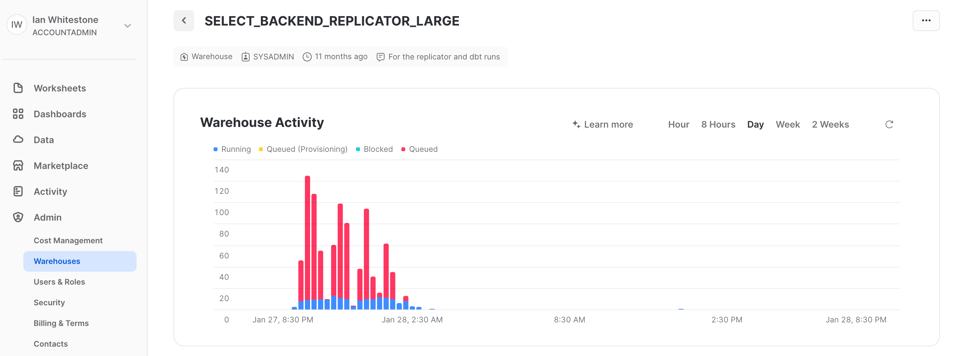
Il existe plusieurs façons de détecter la mise en file d'attente des requêtes. L'une d'elles consiste à utiliser le graphique Warehouse Activity sur la page des warehouses de l'interface Snowsight, qui donne un aperçu rapide de la fréquence de la mise en file d'attente sur le warehouse. Sur cette capture issue de notre projet dbt, on observe une mise en file d'attente continue sur le warehouse dédié à dbt : exactement ce que l'on recherche, puisque cela confirme que le warehouse est exploité à plein. Tant que le temps d'exécution du projet respecte le SLA, la mise en file d'attente n'est pas un problème.
Quels autres facteurs influent sur les temps d'exécution dbt ?
Une fois les threads dbt configurés de sorte que le goulot d'étranglement se situe au niveau du débit de calcul Snowflake, plusieurs autres techniques permettent encore d'améliorer les temps d'exécution. Suivez les liens ci-dessous pour en savoir plus :
- L'incrémentalisation des modèles
- L'optimisation de vos requêtes en identifiant les goulots d'étranglement dans le query profile Snowflake
- La taille du warehouse et la configuration multi-cluster
Niall Woodward·Co-founder & CTO of SELECT
Niall est cofondateur et CTO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Niall était data engineer chez Brooklyn Data Company et dans plusieurs startups. Passionné d'open source, il est aussi mainteneur de SQLFluff et créateur de trois packages dbt : dbt_artifacts, dbt_snowflake_monitoring et dbt_query_tags.
Ian Whitestone·Co-founder & CEO of SELECT
Ian est cofondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à diriger des équipes full stack de data science et d'engineering chez Shopify et Capital One. Chez Shopify, il a piloté l'optimisation de leur data warehouse et le renforcement de l'observabilité des coûts.