Uno de los primeros ajustes que revisan los usuarios de dbt cuando quieren entender y mejorar los tiempos de ejecución de un proyecto son los threads. ¿Por qué este parámetro tiene tanto impacto y en qué valor conviene configurarlo? Te lo explicamos todo en este breve post.
Si andas con poco tiempo, la respuesta corta a cuántos threads deberías configurar es: "tantos como sean necesarios para que haya queueing". Para un proyecto típico de dbt, con 16 alcanza, y puedes confirmarlo revisando la pestaña de queries en Snowflake mientras corre una ejecución.
¿Qué controla el parámetro threads de dbt?
Un poco de contexto sobre multi-threading en Python
En esencia, dbt es un proceso de Python que toma tus archivos SQL ("models") y los ejecuta contra el data warehouse que estés usando (en el contexto de este post, Snowflake).
Por defecto, Python es single-threaded, es decir, solo puede realizar una operación a la vez. Con dbt, todo el "trabajo pesado" de procesar tus datos ocurre en Snowflake. Por eso, el proceso de Python de dbt está limitado principalmente por I/O: pasa la mayor parte del tiempo esperando a que Snowflake ejecute el SQL que le envía. Para aplicaciones limitadas por I/O, los desarrolladores de Python pueden recurrir al multi-threading para acelerarlas. El multi-threading te permite levantar varios threads, donde cada uno ejecuta sus propias operaciones, lo que en la práctica te permite correr tus procesos en paralelo en lugar de uno a la vez.
¿Qué son los dbt threads?
dbt expone esta funcionalidad mediante un parámetro llamado threads. Este parámetro controla cuántos threads levanta dbt para ejecutar en paralelo las operaciones SQL necesarias para tu proyecto.
En pocas palabras: el parámetro threads controla la cantidad máxima de models que se envían a Snowflake para su ejecución en un momento dado.
Diseño del Virtual Warehouse de Snowflake e implicaciones de concurrencia
Para un repaso rápido sobre la arquitectura de cómputo del virtual warehouse de Snowflake, cada nodo de un warehouse de Snowflake cuenta con 8 cores/threads disponibles para procesar tu query. Un warehouse X-SMALL tiene 1 nodo y, por lo tanto, 8 cores/threads. Un Small tiene el doble (2 nodos, 16 cores), un Medium el doble de un Small (4 nodos y 32 cores), y así sucesivamente.
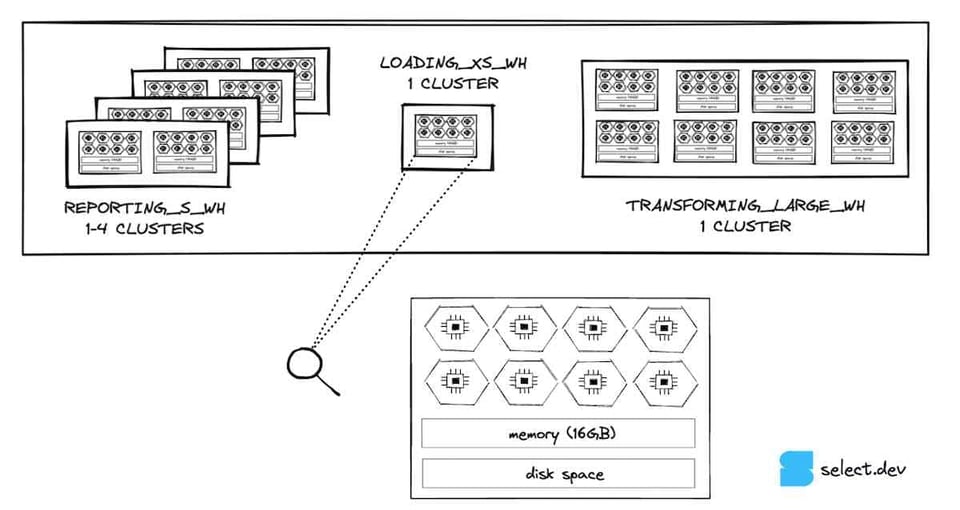
Si consideramos un warehouse X-SMALL, puede ejecutar hasta 8 queries de forma simultánea en un momento dado. A medida que aumenta el tamaño del warehouse, también aumenta el potencial de concurrencia (la cantidad de queries que se pueden ejecutar al mismo tiempo).
Así, mientras el parámetro threads de dbt controla cuántas queries se envían a Snowflake en paralelo, el propio virtual warehouse de Snowflake controla cuántas queries procesa realmente en paralelo. Cuando un warehouse no puede procesar más queries, las pone en cola y las ejecuta automáticamente cuando hay capacidad de cómputo disponible.
¿Qué impacto tienen los dbt threads en el tiempo de ejecución?
Los proyectos de dbt son DAGs (Directed Acyclic Graphs) y suelen ser bastante grandes y complejos, con un model del que dependen varios otros, y viceversa.
Una manera que nos resulta útil para explicar el impacto de los threads es imaginar los dos extremos.
Si partimos del supuesto de que solo se configuró un único thread, la duración total de un proyecto con 500 models será la suma de las duraciones individuales de cada model. Eso va a tomar mucho tiempo, y el virtual warehouse (o los warehouses) que ejecute los models pasará buena parte de ese tiempo subutilizado (puedes leer más sobre la utilización de warehouses aquí). El resultado: un proyecto muy lento y, en consecuencia, costos altos de virtual warehouse.
Ahora imaginemos qué pasaría si elegimos un número de threads muy superior al número de models que podrían ejecutarse simultáneamente, considerando la cantidad de models en el DAG y su estructura de dependencias. Al hacerlo, nos aseguramos de que dbt intente ejecutar todas las queries que estén en condiciones de correr en cualquier momento dado. Esto traslada el cuello de botella del tiempo de ejecución del proyecto desde la duración de cada model (salvo en dependencias de un solo nodo) hacia la capacidad computacional del virtual warehouse, con lo que se maximiza la eficiencia de utilización. Con esto se logran dos cosas:
- Queueing (lo que significa que se está usando todo el cómputo disponible del warehouse)
- Tiempos de ejecución end-to-end del proyecto minimizados
En este escenario, es probable que los tiempos individuales de cada model aumenten por la contención de recursos, pero recuerda que el objetivo aquí es el tiempo de ejecución end-to-end. Para jobs en batch, el queueing es algo positivo, porque significa que estás obteniendo el mejor retorno por tu dinero.
¿Cuántos dbt threads deberías usar en Snowflake?
Con base en lo anterior, recomendamos configurar el parámetro threads de dbt en un valor lo suficientemente alto como para que haya queueing en tu warehouse. Un valor de 16 lo logra en la mayoría de los proyectos de dbt, pero conviene validar que el virtual warehouse que usas para dbt esté completamente saturado, comprobando que exista algo de queueing de queries.
Aquí tienes un ejemplo de un dbt model timing chart con más de 16 threads. Se puede ver que Snowflake es capaz de ejecutar muchos recursos de dbt en paralelo.

Impacto en el queueing
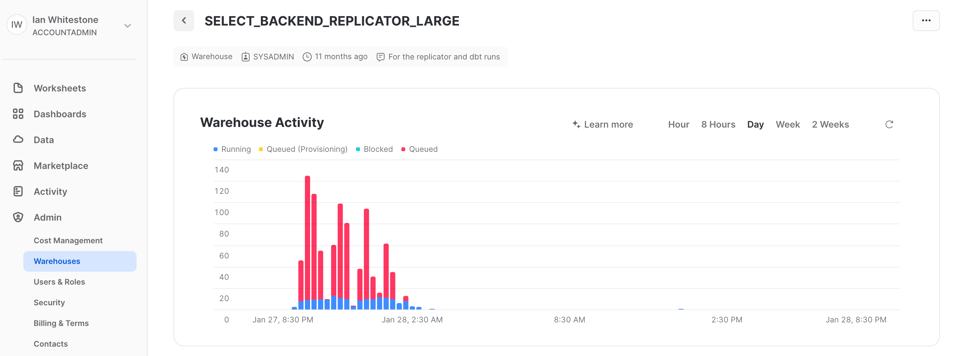
Hay varias formas de verificar el queueing de queries. Un método es usar el gráfico de Warehouse Activity en la página de warehouses de la UI de Snowsight, que te da una vista rápida de qué tan seguido hay queueing en el warehouse. En esta captura de nuestro proyecto de dbt se ve queueing constante en el warehouse que usamos para dbt, que es justo lo que queremos, ya que nos confirma que se está aprovechando al máximo. Mientras el tiempo de ejecución de tu proyecto esté dentro del SLA, el queueing no debería preocuparte.
¿Qué otros factores afectan los tiempos de ejecución de dbt?
Una vez configurados los dbt threads para que el cuello de botella sea la capacidad computacional de Snowflake, existen otras técnicas para mejorar los tiempos de ejecución de dbt. Sigue los enlaces de abajo para aprender más:
- Incrementalización de models
- Optimizar tus queries identificando los cuellos de botella en el query profile de Snowflake
- Tamaño del warehouse y configuración multi-cluster
Niall Woodward·Co-founder & CTO of SELECT
Niall es Co-Founder y CTO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Niall fue data engineer en Brooklyn Data Company y en varias startups. Como entusiasta del open-source, también es maintainer de SQLFluff y creador de tres paquetes de dbt: dbt_artifacts, dbt_snowflake_monitoring y dbt_query_tags.
Ian Whitestone·Co-founder & CEO of SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, Ian lideró los esfuerzos para optimizar su data warehouse y aumentar la observabilidad de costos.