Uma das primeiras configurações que quem usa dbt costuma olhar para entender e melhorar o tempo de execução do projeto é o número de threads. Por que esse parâmetro tem tanto impacto e qual valor definir? É o que vamos explicar neste post rápido.
Se você está sem tempo, a resposta resumida (TL;DR) para a pergunta sobre como configurar o valor de threads é: "alto o suficiente para garantir queueing". Para um projeto dbt típico, 16 dá conta do recado, e você pode confirmar olhando a aba de queries no Snowflake durante uma execução.
O que o parâmetro dbt threads controla?
Contexto sobre multi-threading em Python
Na essência, o dbt é um processo Python que pega seus arquivos SQL (os "models") e os executa no data warehouse que você estiver usando (no caso deste post, o Snowflake).
Por padrão, o Python é single-threaded, ou seja, executa uma operação por vez. No dbt, todo o "trabalho pesado" de processar os dados acontece no Snowflake. Por isso, o processo Python do dbt é majoritariamente I/O bound: ele passa a maior parte do tempo parado, esperando o Snowflake executar o SQL enviado. Para aplicações I/O bound, quem desenvolve em Python pode recorrer a multi-threading para acelerar a execução. O multi-threading permite criar várias threads, cada uma executando suas próprias operações, o que viabiliza rodar processos em paralelo em vez de um de cada vez.
O que são dbt threads?
O dbt expõe essa funcionalidade por meio de um parâmetro chamado threads. Esse parâmetro controla quantas threads o dbt cria para executar em paralelo as operações SQL necessárias do seu projeto.
Resumindo: o parâmetro threads controla o número máximo de models que serão enviados ao Snowflake para execução em um dado momento.
Arquitetura do Virtual Warehouse do Snowflake e implicações de concorrência
Para uma revisão rápida sobre a arquitetura de compute dos virtual warehouses do Snowflake, cada nó de um warehouse do Snowflake tem 8 cores/threads disponíveis para processar suas queries. Um warehouse X-SMALL tem 1 nó e, portanto, 8 cores/threads. Um Small tem o dobro disso (2 nós, 16 cores), um Medium tem o dobro do Small (4 nós e 32 cores), e assim por diante.
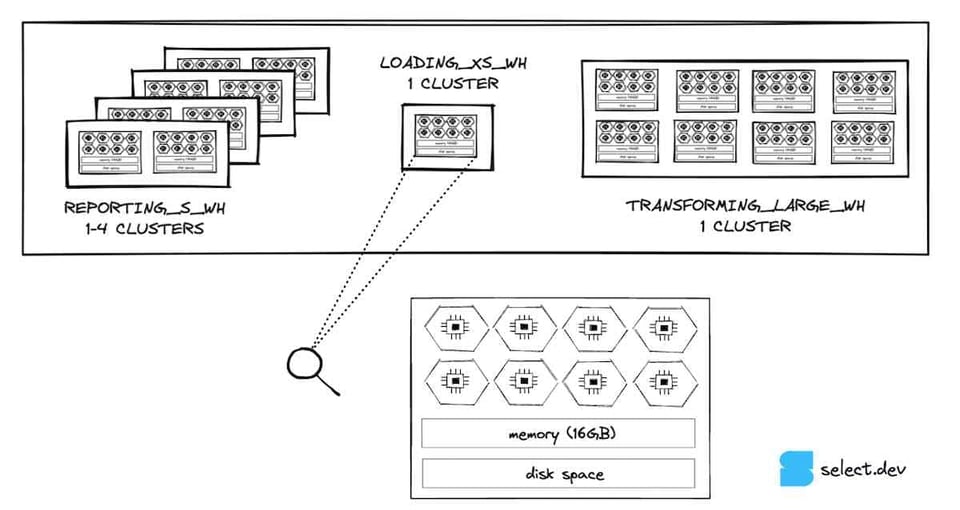
Pegando o exemplo de um warehouse X-SMALL, ele consegue rodar até 8 queries em paralelo a qualquer momento. À medida que o tamanho do warehouse aumenta, o potencial de concorrência (a quantidade de queries que podem rodar ao mesmo tempo) também cresce.
Ou seja, enquanto o parâmetro threads do dbt controla quantas queries são enviadas ao Snowflake em paralelo, é o próprio virtual warehouse do Snowflake que decide quantas queries realmente processa em paralelo. Quando o warehouse não dá conta de mais nenhuma query, ele as coloca em uma fila e processa automaticamente assim que houver capacidade de compute disponível.
Qual é o impacto das dbt threads no tempo de execução?
Projetos dbt são DAGs (Directed Acyclic Graphs) e, em geral, são bem grandes e complexos, com um model servindo de dependência para vários outros, e vice-versa.
Uma forma que achamos útil para explicar o impacto das threads é imaginar os dois extremos.
Se começarmos supondo que só uma thread foi configurada, então a duração da execução de um projeto com 500 models será a soma das durações individuais de cada model. Isso vai levar muito tempo, e o virtual warehouse (ou warehouses) que está rodando os models vai passar boa parte desse tempo subutilizado (você pode ler mais sobre utilização de warehouse aqui). O resultado é um projeto bem lento e custos de virtual warehouse proporcionalmente altos.
Agora imagine o que aconteceria se escolhêssemos um número de threads muito maior do que o número de models que conseguiriam rodar simultaneamente, dadas a quantidade de models no DAG e sua estrutura de dependências. Com isso, garantimos que o dbt vai tentar executar todas as queries elegíveis para rodar a qualquer momento. Essa estratégia desloca o gargalo do tempo de execução do projeto dbt: ele sai do tempo individual de cada model (com exceção das dependências de nó único) e passa a ser o throughput computacional do virtual warehouse, maximizando a eficiência de utilização. Isso traz duas coisas:
- Queueing (ou seja, todo o compute disponível do warehouse está sendo usado)
- Tempos de execução end-to-end do projeto minimizados
Nesse cenário, é provável que os tempos individuais dos models aumentem por causa da disputa por recursos, mas lembre que o objetivo aqui é o tempo end-to-end. Para jobs em batch, queueing é algo bom, porque significa que você está tirando o máximo do seu investimento.
Quantas dbt threads você deve usar no Snowflake?
Com base na discussão acima, recomendamos configurar o parâmetro dbt threads em um valor alto o suficiente para garantir queueing no seu warehouse. Um valor de 16 atende a maioria dos projetos dbt, mas vale validar se o virtual warehouse usado pelo dbt está totalmente saturado, confirmando que há algum queuing de queries.
Veja um exemplo de gráfico de timing de models do dbt com mais de 16 threads. Dá para perceber que o Snowflake consegue rodar muitos recursos do dbt em paralelo.

Impacto no queuing
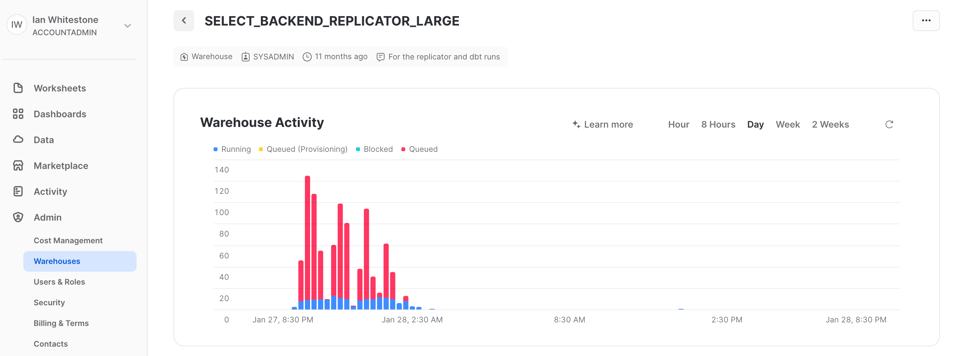
Existem várias formas de verificar o queuing de queries. Uma delas é usar o gráfico Warehouse Activity na página de warehouses na interface do Snowsight, que dá um panorama rápido da frequência de queueing no warehouse. Na captura de tela abaixo, tirada do nosso projeto dbt, há queueing consistente no warehouse que usamos para o dbt, e é exatamente isso que queremos, porque indica que o warehouse está sendo totalmente aproveitado. Desde que o tempo de execução do seu projeto esteja dentro do SLA, o queuing não deve ser motivo de preocupação.
Que outros fatores afetam os tempos de execução do dbt?
Depois de configurar as dbt threads para que o gargalo seja o throughput computacional do Snowflake, há outras técnicas que ajudam a melhorar os tempos de execução do dbt. Acesse os links abaixo para saber mais:
- Incrementalização de models
- Otimização das suas queries entendendo os gargalos no query profile do Snowflake
- Tamanho de warehouse e configuração multi-cluster
Niall Woodward·Co-founder & CTO da SELECT
Niall é Co-Founder & CTO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Niall foi engenheiro de dados na Brooklyn Data Company e em várias startups. Entusiasta de open-source, também é mantenedor do SQLFluff e criador de três pacotes dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.
Ian Whitestone·Co-founder & CEO da SELECT
Ian é Co-founder & CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times de full stack data science e engenharia na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.