Uno dei primi parametri di configurazione a cui gli utenti dbt guardano per capire e migliorare i tempi di esecuzione di un progetto sono i threads. Perché questo parametro ha un impatto così rilevante e quale valore conviene impostare? Lo spieghiamo in questo breve articolo.
Se hai poco tempo, la risposta in sintesi è: imposta i threads su un valore "abbastanza alto da generare queueing". Per un progetto dbt tipico, 16 è il valore che permette di ottenerlo, e puoi verificarlo dalla tab delle query in Snowflake mentre è in corso un'esecuzione.
Cosa controlla il parametro dbt threads?
Premessa sul multi-threading in Python
Alla base, dbt è essenzialmente un processo Python che prende i tuoi file SQL (i "model") e li esegue sul data warehouse che stai utilizzando (cioè Snowflake, nel contesto di questo articolo).
Di default, Python è single threaded: esegue cioè un'operazione alla volta. Con dbt, tutto il "lavoro pesante" di elaborazione dei dati avviene in Snowflake. Di conseguenza, il processo Python di dbt è in gran parte I/O bound: passa la maggior parte del tempo in attesa che Snowflake esegua l'SQL inviato. Per le applicazioni I/O bound, gli sviluppatori Python possono ricorrere al multi-threading per velocizzarle. Il multi-threading consente di avviare più thread, ciascuno in grado di eseguire le proprie operazioni, di fatto permettendo di eseguire i processi in parallelo invece che uno alla volta.
Cosa sono i dbt threads?
dbt espone questa funzionalità tramite un parametro chiamato threads. Questo parametro controlla quanti thread vengono avviati da dbt per eseguire in parallelo le operazioni SQL necessarie al progetto.
In sintesi: il parametro threads controlla il numero massimo di model che, in un dato momento, possono essere inviati a Snowflake per l'esecuzione.
Architettura del Virtual Warehouse di Snowflake e implicazioni sulla concorrenza
Per un breve ripasso sull'architettura di calcolo del virtual warehouse di Snowflake: ogni nodo di un warehouse Snowflake dispone di 8 core/thread per l'elaborazione delle query. Un warehouse X-SMALL ha 1 nodo, quindi 8 core/thread. Un Small ne ha il doppio (2 nodi, 16 core), un Medium il doppio di uno Small (4 nodi e 32 core), e così via.
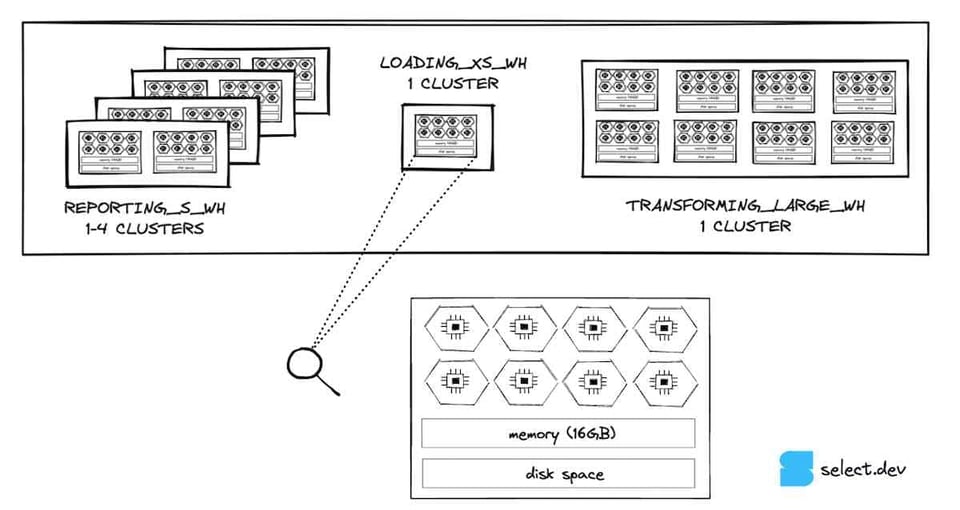
Un warehouse X-SMALL può quindi eseguire fino a 8 query in contemporanea in un dato istante. Man mano che la dimensione del warehouse aumenta, cresce anche il potenziale di concorrenza (cioè il numero di query eseguibili in parallelo).
Quindi, mentre il parametro dbt threads stabilisce quante query vengono inviate a Snowflake in parallelo, è il virtual warehouse di Snowflake a decidere quante query vengono effettivamente elaborate in parallelo. Quando un warehouse non riesce a elaborarne altre, le mette in coda e le elabora automaticamente non appena si libera capacità di calcolo.
Qual è l'impatto dei dbt threads sui tempi di esecuzione?
I progetti dbt sono DAG (Directed Acyclic Graphs), spesso piuttosto ampi e complessi, in cui un model è una dipendenza di diversi altri, e viceversa.
Un modo efficace per spiegare l'impatto dei threads è ragionare sui due estremi.
Partiamo dal caso in cui sia stato impostato un solo thread: la durata di un'esecuzione su un progetto da 500 model sarà pari alla somma delle durate di ogni singolo model. Servirà molto tempo, e il virtual warehouse (o i warehouse) che eseguono i model resteranno sottoutilizzati per buona parte del processo (puoi approfondire l'argomento dell'utilizzo dei warehouse qui). Il risultato è un progetto molto lento e, di conseguenza, costi elevati del virtual warehouse.
Immaginiamo ora di scegliere un numero di thread molto più alto del numero di model che potrebbero mai essere eseguiti in contemporanea, vista la quantità di model nel DAG e la loro struttura di dipendenze. In questo modo ci assicuriamo che dbt cerchi di eseguire tutte le query potenzialmente idonee in un dato momento. Così facendo, il collo di bottiglia dei tempi di esecuzione del progetto dbt si sposta dal tempo di esecuzione del singolo model (eccetto le dipendenze a nodo singolo) al throughput computazionale del virtual warehouse, massimizzando l'efficienza di utilizzo. Si ottengono due risultati:
- Queueing (cioè tutta la capacità di compute del warehouse è in uso)
- Tempi di esecuzione end-to-end del progetto ridotti al minimo
In questo scenario è probabile che i tempi di esecuzione dei singoli model aumentino, per via della contesa delle risorse, ma ricorda che l'obiettivo è il tempo end-to-end. Per i job batch il queueing è positivo, perché significa che stai sfruttando al meglio il tuo investimento.
Quanti dbt threads usare con Snowflake?
Alla luce di quanto detto, consigliamo di impostare il parametro dbt threads su un valore sufficientemente alto da generare queueing sul warehouse. Un valore di 16 è sufficiente per la maggior parte dei progetti dbt, ma è bene verificare che il virtual warehouse usato da dbt sia completamente saturo, accertandosi che ci sia un po' di queuing delle query.
Ecco un esempio di grafico dei tempi dei model dbt con oltre 16 thread. Si nota come Snowflake sia in grado di gestire l'esecuzione di molte risorse dbt in parallelo.

Impatto sul queuing
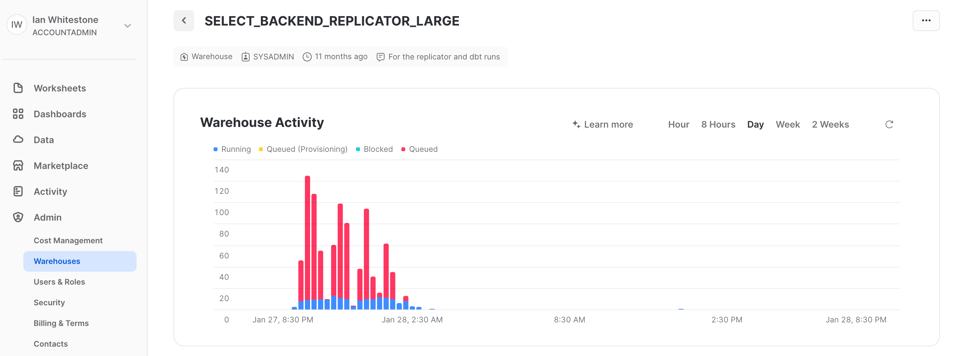
Esistono diversi modi per verificare il queuing delle query. Un metodo consiste nell'utilizzare il grafico Warehouse Activity nella pagina dei warehouse della UI di Snowsight, che offre una panoramica immediata della frequenza con cui si verifica il queueing nel warehouse. In questo screenshot del nostro progetto dbt si vede un queueing costante nel warehouse usato per dbt, ed è esattamente ciò che vogliamo: è la conferma che il warehouse è sfruttato al massimo. Finché il tempo di esecuzione del progetto rientra nello SLA, il queuing non dovrebbe destare preoccupazioni.
Quali altri fattori influenzano i tempi di esecuzione di dbt?
Una volta configurati i dbt threads in modo che il collo di bottiglia sia il throughput computazionale di Snowflake, esistono altre tecniche utili per migliorare i tempi di esecuzione di dbt. Segui i link qui sotto per approfondire:
- Incrementalizzazione dei model
- Ottimizzazione delle query analizzando i colli di bottiglia nel query profile di Snowflake
- Dimensione del warehouse e configurazione multi-cluster
Niall Woodward·Co-founder & CTO di SELECT
Niall è Co-Founder e CTO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT è stato data engineer in Brooklyn Data Company e in diverse startup. Appassionato di open source, è anche maintainer di SQLFluff e autore di tre pacchetti dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder e CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, Ian ha guidato per 6 anni team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha coordinato le attività di ottimizzazione del data warehouse e di miglioramento dell'osservabilità dei costi.