Niall und ich waren 2022 zum ersten Mal beim Snowflake Data Cloud Summit – und die Energie und Dynamik rund um die Plattform hat uns schlicht umgehauen. Uns war klar: In diesem boomenden Ökosystem müssen wir etwas aufbauen – und so entstand SELECT.
Letzte Woche waren wir für unseren zweiten Summit zurück in Las Vegas, und er hat uns erneut nicht enttäuscht. Snowflake hat im vollbesetzten Saal des Caesar's Palace einige große Neuerungen und eine ganze Fülle weiterer Features vorgestellt. In diesem Beitrag schauen wir uns die jüngsten Innovationen genauer an, ordnen jede einzelne ein und sprechen über die eine Sache, die nicht zur Sprache kam.
Native Applications Framework (Public Preview)
Die mit Abstand größte Ankündigung des Summit 2022 war das Native Applications Framework (Native Apps). Dieses Jahr ist es in die Public Preview übergegangen.
Stellen Sie sich vor, Sie müssten für jede neue App auf dem iPhone eine andere Website besuchen, sich erst über das Angebot informieren und dem Anbieter dann direkten Zugriff auf Ihr Telefon einräumen. Genau so läuft heute die Zusammenarbeit zwischen Snowflake-Kunden und ihren Anbietern.

Native Apps soll ein Erlebnis wie im iPhone App Store in die Snowflake Data Cloud bringen. Statt dass Snowflake-Kunden Anbietern erlauben, sich mit ihrem Data Warehouse zu verbinden und Daten zu extrahieren, um sie in einer separaten Anwendung wieder bereitzustellen (so wie wir es bei SELECT machen), können Anbieter ihre Anwendungen mit Native Apps direkt im Snowflake-Account des Kunden ausführen. Das bringt mehrere Vorteile mit sich:
- Mehr Sicherheit. Daten verlassen Ihr Warehouse nie, und niemand außerhalb Ihres Unternehmens erhält Zugriff darauf. Außerdem entfällt die Verwaltung separater Logins oder Zugänge für die Drittanbieter-Anwendung. Native Apps nutzen dieselbe Authentifizierung und Berechtigungsstruktur wie der Rest Ihres Snowflake-Accounts.
- Einfacheres Procurement aus rechtlicher Sicht. Die meisten Anbieterbeziehungen erfordern einen neuen Vertrag, der von der internen Rechtsabteilung geprüft werden muss. Bei Native Apps muss das Legal Team die Bedingungen des Snowflake Marketplace nur einmal prüfen – und nicht für jede einzelne installierte App.
- Ihre Abrechnung wird deutlich übersichtlicher, weil alles über Snowflake läuft. Snowflake hat sogar angekündigt, dass Kunden Apps über ihr bestehendes Vertragsvolumen bezahlen können – ein Feature namens Capacity Drawdown.
Bei SELECT freuen wir uns enorm auf das Potenzial von Native Apps: Sie versetzen uns in die Lage, noch mehr Snowflake-Kunden dabei zu unterstützen, ihren Snowflake-ROI zu maximieren und wertvolle Erkenntnisse zu gewinnen – mit einem schlankeren Onboarding und Procurement. Auch der Austausch all der einzigartigen Kosten- und Performance-Datasets, die bei uns entstehen, wird damit deutlich einfacher.
Snowpark Container Services (Private Preview)
Snowpark Container Services (SCS) waren der heimliche Star des Summit 2023. Gegen Ende der Keynote führte Christian Kleinerman das Publikum durch 10 Live-Demos von Anwendungen mit unterschiedlichsten Use Cases, die alle nativ in Snowflake über SCS liefen.

Mit Snowpark Container Services lässt sich tatsächlich jeder Workload und jede Anwendung in Snowflake ausführen. Wie das funktioniert? Über Docker. Da sich Docker-Container über SCS direkt in Snowflake deployen lassen, sind Nutzer nicht mehr auf die von Snowflake unterstützten Sprach-Runtimes und Umgebungen beschränkt.
Snowpark Container Services unterstützen eine Vielzahl unterschiedlicher Workloads. Komplexe KI-Modelle lassen sich in SCS trainieren und deployen und können neue GPU-Instanzen nutzen. Ein geplanter Job oder eine Service-Funktion kann in einem Snowpark-Container laufen. Auch ein dauerhaft laufender Service – etwa eine Webanwendung – lässt sich direkt in SCS hosten und rund um die Uhr auf Snowflake betreiben. Hex hat seine elegante Notebooks-UI (eine komplexe React-Webanwendung) live aus einem Snowpark-Container heraus vorgeführt.
Ein Service, der 24/7 in Snowflake läuft, klingt teuer – aber keine Sorge: Snowflake wird neue Compute-Instanztypen für SCS vorstellen, damit solche Services wirtschaftlich bleiben.
Managed Iceberg Tables (Private Preview)
Warum Iceberg?
Viele Unternehmen haben bereits große Datenmengen im Cloud-Speicher liegen, ohne sie in Snowflake zu laden. Wäre es nicht großartig, wenn Sie diese Datensätze mit Snowflake sowohl abfragen als auch aktualisieren könnten?
Apache Iceberg ist ein offenes Tabellenformat für analytische Datensätze. Es bildet eine Abstraktionsschicht über den physischen Datendateien (z. B. Parquet-Dateien) und unterstützt ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability), Schema Evolution, Hidden Partitioning, Table Snapshots und weitere Funktionen. Query Engines müssen wissen, welche Dateien zu einer bestimmten "Tabelle" gehören – genau das liefert Iceberg.
Snowflakes bisherige Unterstützung für Iceberg
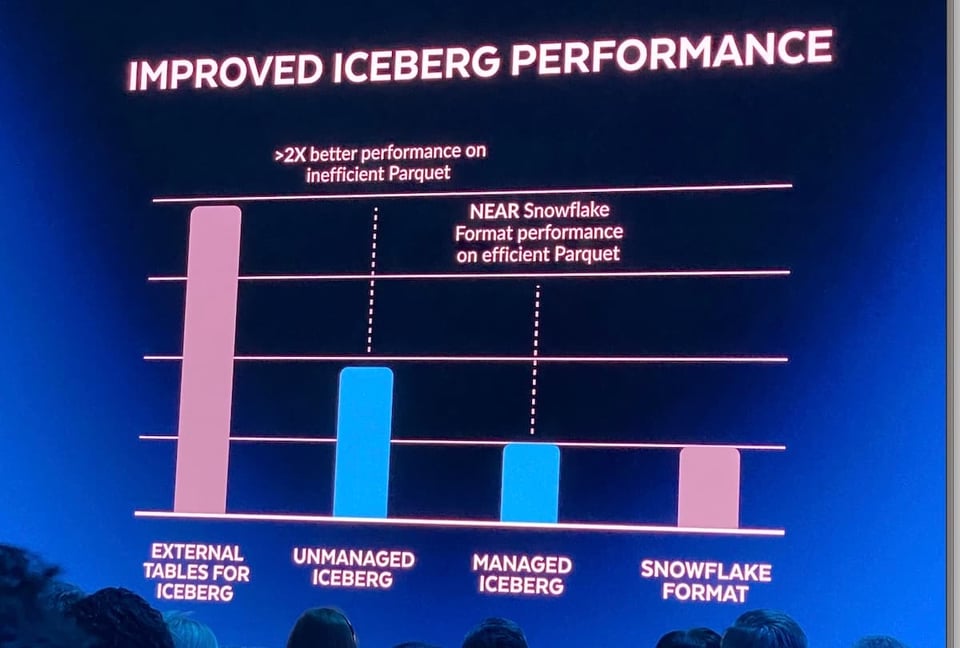
Bis letztes Jahr gab es in Snowflake nur eine Option, um Data-Lake-Dateien abzufragen: die Read-only External Tables. Diese lieferten aus verschiedenen Gründen meist eine schlechtere Performance als direkt in Snowflake gespeicherte Tabellen. Auf dem Summit 2022 kündigte Snowflake die Unterstützung für Iceberg Tables an. Kunden können damit ihren Data-Lake-Katalog mit Iceberg verwalten und dank der von Iceberg bereitgestellten Metadaten eine deutlich bessere Performance über die Snowflake-Query-Engine erzielen. Außerdem lassen sich externe (Iceberg-)Tabellen wie reguläre Snowflake-Tabellen behandeln – inklusive Updates, Deletes und Inserts.
Iceberg-Ankündigung Summit 2023
Eine offene Herausforderung beim Einsatz von Iceberg ist, dass man ein System braucht, das die Iceberg-Metadaten kontinuierlich in einem separaten Katalog schreibt und aktualisiert. Genau dafür hat Snowflake auf dem Summit 2023 "Managed Iceberg Tables" angekündigt. Nutzer können nun Snowflake-Compute-Ressourcen einsetzen, um die Iceberg-Daten zu verwalten. Neben dem Wegfall dieses Aufwands sind auch Performance-Verbesserungen zu erwarten.
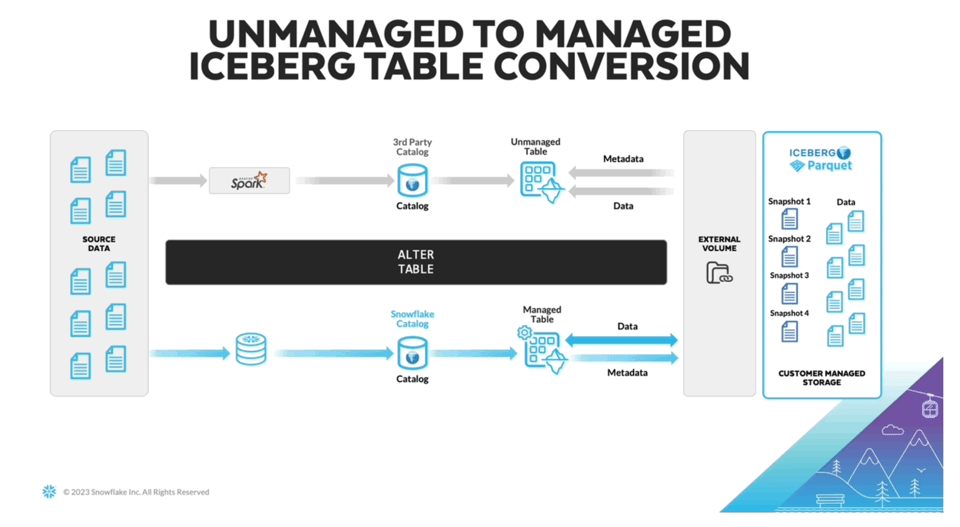
Da es bisher keine Produktdokumentation gibt, gehe ich davon aus, dass sich dieses Feature aktuell in Private Preview befindet. Das obige Bild stammt von James Malone auf LinkedIn. Wer noch ganz neu bei Iceberg ist, findet in diesem Blogpost einen guten Einstieg.
Dynamic Tables (Public Preview)
Einer der größten Kostentreiber bei Datentransformationen, den wir bei Snowflake-Kunden – und auch in unserem eigenen Account – sehen, ist das vollständige Neuaufbauen von Tabellen bei jedem Pipeline-Lauf. Tabellen werden so gebaut, weil es schneller und einfacher ist. Inkrementelles Bauen ist deutlich kniffliger: Man muss Faktoren wie verspätet eintreffende Daten, den korrekten High Watermark für die Filterung jedes Datensatzes und vieles mehr berücksichtigen. Hinzu kommen unnötige Kosten, wenn Pipeline-Jobs nach einem starren Zeitplan laufen, ohne zu prüfen, ob überhaupt neue Upstream-Daten vorliegen.
Snowflake unterstützt seit langem Materialized Views (MVs), die einige dieser Probleme adressieren, indem sie die Tabelle nur dann aktualisieren, wenn neue Upstream-Daten eintreffen. Allerdings haben sie ihre Tücken – der größte Haken: Die SQL-View-Definition unterstützt viele gängige Operationen wie Joins, Unions, Aggregationen, GROUP BYs oder Window Functions nicht.
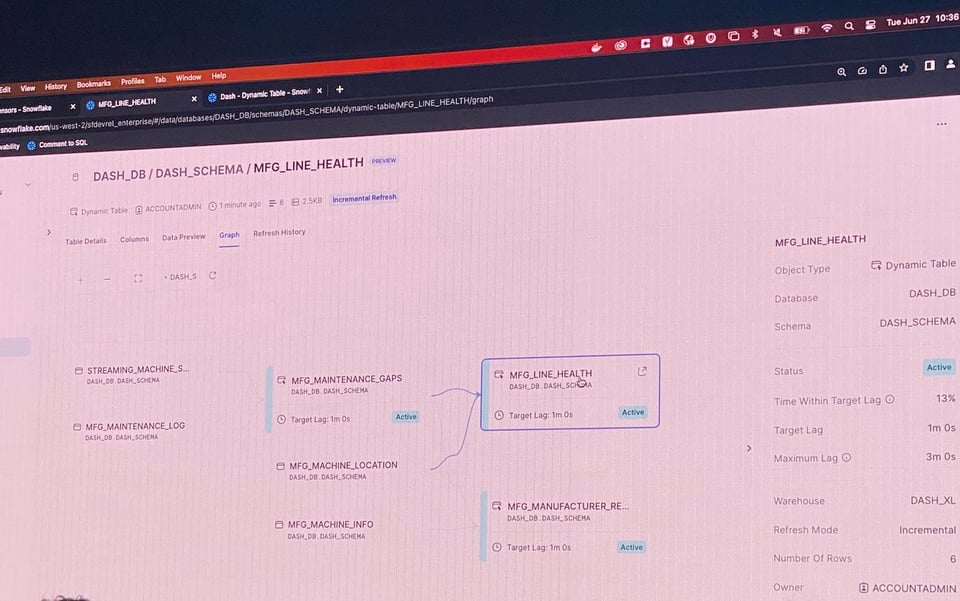
Auf dem diesjährigen Summit hat Snowflake angekündigt, dass Dynamic Tables (DTs) jetzt in Public Preview verfügbar sind. DTs ähneln MVs insofern, als Sie Ihre Tabelle über einen SQL-Ausdruck definieren und Snowflake sich um die Materialisierung kümmert, sobald neue Upstream-Daten eintreffen. DTs bringen darüber hinaus eine ganze Reihe weiterer Vorteile mit:

- Sie unterstützen einen deutlich breiteren SQL-Umfang, darunter Joins, Unions, Aggregationen, Window Functions und mehr.
- Sie verarbeiten neue Daten inkrementell und verschwenden so keine Ressourcen für das wiederholte Berechnen derselben Daten.
- MVs wurden sehr teuer, wenn die Upstream-Tabelle häufig aktualisiert wurde. Bei DTs aktualisiert Snowflake die Tabelle anhand eines von Ihnen definierten Latenzparameters. Das gibt Ihnen mehr Kontrolle darüber, wie oft die Tabellen aktualisiert werden – und damit über die zugehörigen Compute-Kosten.
- Sie bringen erstklassige UI-Unterstützung mit. Nutzer können DTs und ihre Abhängigkeiten leicht visualisieren und die historischen Läufe im Tab
Refresh Historyeinsehen.
Snowpipe Streaming API (Public Preview)
Snowflake hat angekündigt, dass die Snowpipe Streaming API jetzt in Public Preview ist. Snowpipe Streaming ermöglicht es Kunden, Daten direkt aus Apache Kafka oder einer eigenen Java-Anwendung in Snowflake zu laden. Snowpipe Streaming unterstützt Workloads, die Daten mit geringerer Latenz benötigen.
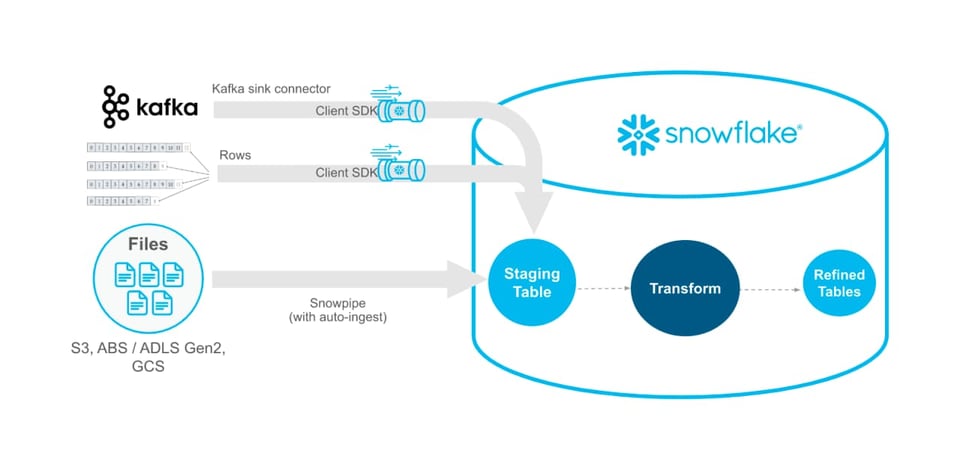
Snowpipe Streaming ist außerdem die kosteneffizienteste Methode, Daten zu laden – sobald die nötige Infrastruktur steht. Alternative Lade-Strategien wie Snowpipe oder manuelle COPY INTO-Statements auf einem selbst verwalteten Warehouse laden jeweils eine Datei aus einem Stage in Snowflake. Da Snowpipe Streaming den teuren Read-Schritt und den Overhead der Dateiverwaltung umgeht, ist es die kostengünstigere Variante.
Eine Flut von KI-Ankündigungen
Angesichts des Hypes um generative KI und LLMs war es kaum überraschend, dass Snowflake eine ganze Reihe kommender KI-Features ankündigte.
Nvidia-Partnerschaft
Am ersten Konferenztag verkündete Snowflake eine neue Partnerschaft mit Nvidia. Gemeinsam mit Nvidia wird Snowflake das LLM-Framework NeMo in Snowflake integrieren. So können Engineers Large Language Models direkt in Snowflake aufbauen – mit den Daten, die sie dort ohnehin schon gespeichert haben.
Snowflake Copilot (TBD)
Snowflake hat ein wirklich cooles "Comment-to-SQL"-Feature vorgeführt, ähnlich wie Github Copilot. Stellen Sie sich vor, Sie schreiben einen Kommentar wie -- show me the count of daily active users over the last 30 days – und Snowflake generiert die Query automatisch, basierend auf (a) Ihren Daten und (b) dem exakten Snowflake-SQL-Dialekt. Snowflake sitzt auf dem größten denkbaren Trainingsdatensatz an Queries; ich erwarte daher, dass dieses Modell alles in den Schatten stellt, was man von anderen Anbietern von der Stange bekommt.
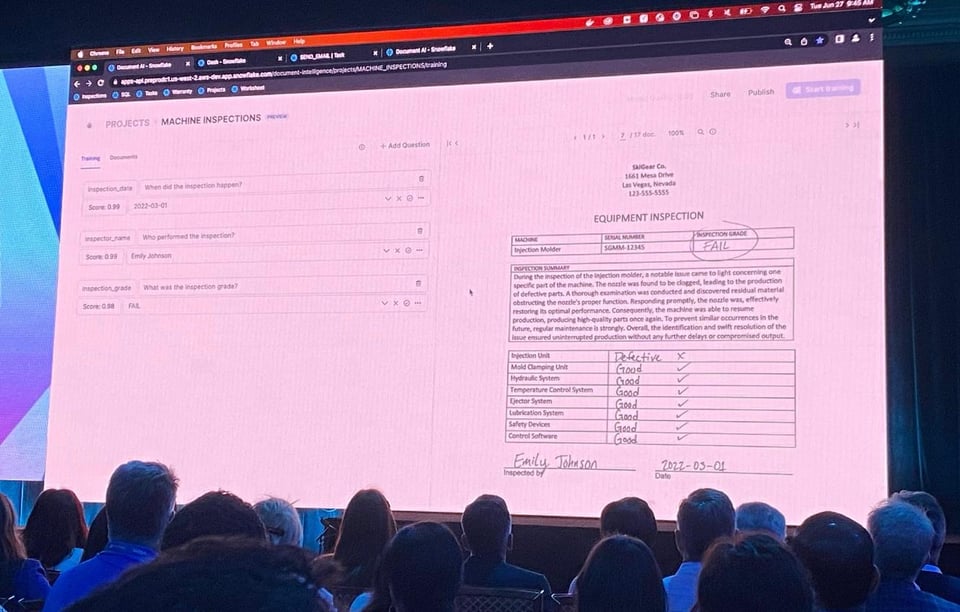
Document AI (Private Preview)
Im April 2022 hat Snowflake das Unternehmen Applica übernommen, das auf die Analyse unstrukturierter Daten spezialisiert war. Auf dem Summit 2023 hat Snowflake mit Document AI ein neues Feature angekündigt, das auf Applicas Technologie aufbaut. Es ist Snowflakes hauseigenes LLM und ermöglicht es Ihnen, Fragen zu Dokumenten zu stellen, die Sie in Snowflake gespeichert haben.
Snowflake zeigte eine sehenswerte Demo, in der Informationen automatisch aus Dokumenten extrahiert wurden. Nutzer konnten den extrahierten Informationen Feedback geben, um die Genauigkeit des Modells zu verbessern. Anschließend ließ sich das trainierte Modell mit wenigen Schritten deployen und als UDF in einer SQL-Query ausführen.
Diverse Developer-Updates
Das Product-Management-Team von Snowflake hat eine ganze Reihe weiterer Developer-Updates angekündigt. Sobald uns mehr Details vorliegen, teilen wir sie:
- Eine neue Snowflake CLI und eine Python-REST-API (als Ergänzung zum bestehenden Snowflake Connector for Python)
- Die Snowpark Model Registry, mit der Data Scientists ML-Modelle in Snowflake speichern, veröffentlichen, finden und bereitstellen können.
- Diverse Snowpark-Verbesserungen, darunter feingranulare Kontrolle über Python-Pakete, Unterstützung für Python 3.9 und 3.10, externer Netzwerkzugriff und vektorisierte Python-UDTFs.
- Drei native, ML-gestützte Funktionen für Forecasting, Anomaly Detection und Contribution Explorer.
- Neue Logging- und Tracing-APIs sowie automatische Synchronisation zwischen Git und Snowflake-Stages, um Entwickler beim Bauen im Native Apps Framework zu unterstützen.
- Streamlit ist angeblich "ganz kurz" vor der Public Preview. Vorgestellt wurden neue Streamlit-Komponenten zum Bauen von Chat-Erlebnissen.
Kostenoptimierung und Kontrolle
Anders als viele meinen, liegt Snowflake sehr daran, dass Kunden die Plattform effektiv nutzen. Snowflake weiß: Hier zählt das lange Spiel – und es geht darum, Kunden zu helfen, das Maximum aus jedem Dollar herauszuholen, den sie in Snowflake investieren.
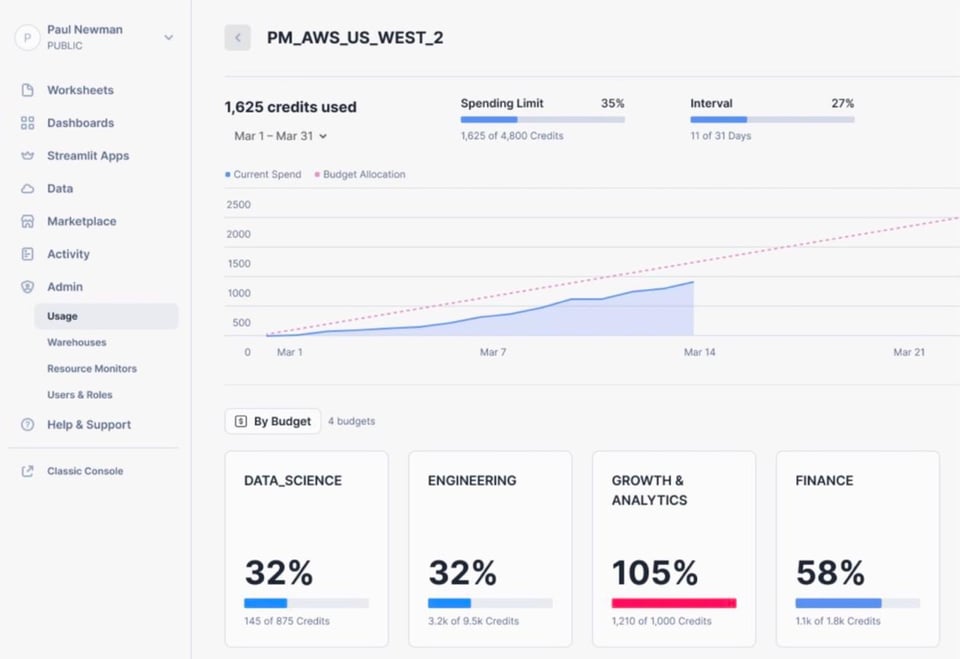
Budgets (Public Preview)
Damit Kunden ihre Snowflake-Ausgaben besser steuern können, hat Snowflake angekündigt, dass das Budgets-Feature in die Public Preview geht. Bisher konnten Nutzer nur Resource Monitors einrichten, mit denen sich die Anzahl der Credits festlegen lässt, die ein Warehouse oder eine Gruppe von Warehouses verbrauchen darf. Budgets gehen einen Schritt weiter: Sie erlauben es, mehrere Snowflake-Ressourcen (Warehouses, Tabellen, Materialized Views, Snowpipes usw.) zu gruppieren und dieser Ressourcengruppe ein Credit-Limit (Budget) zuzuweisen. Ähnlich wie bei Resource Monitors lassen sich dann Benachrichtigungen auslösen oder die zugrunde liegenden Ressourcen aussetzen, sobald das Credit-Limit erreicht ist – um weitere Kosten zu verhindern.
Danke an Sonny für die Details und das Bild unten.
Warehouse Utilization (Private Preview)
Eine der größten Herausforderungen für Snowflake-Kunden ist die Frage, ob ihre Warehouses richtig dimensioniert sind. Snowflake hat dafür eine neue Warehouse-Utilization-Metrik in Private Preview angekündigt. Mehr Details liegen uns noch nicht vor – wir freuen uns aber darauf, das Feature in der Public Preview unter die Lupe zu nehmen.
Performance-Verbesserungen
Snowflake hat eine Reihe von Performance-Verbesserungen an der Query Engine angekündigt sowie einen neuen Snowflake Performance Index (SPI), mit dem diese Fortschritte öffentlich gemessen und nachverfolgt werden. Snowflake-typisch werden alle Verbesserungen automatisch wirksam – Nutzer müssen nichts tun, um sie zu aktivieren.

Der, dessen Name nicht genannt werden darf
Engineers und Data Practitioners sind es gewohnt, mit Daten zu arbeiten, die über verschiedene Datenbanken verteilt liegen. Das ist seit der zweiten Datenbank in den 70ern Realität – und der Grund, warum rund um Datenbewegung eine milliardenschwere Industrie entstanden ist (hust Fivetran).
Wünschenswert ist das natürlich nicht. Wäre es nicht großartig, wenn man einfach eine einzige Datenbank für alles nutzen könnte? Auf dem Summit 2022 hat Snowflake Unistore angekündigt – einen neuen Workload-Typ, der sowohl transaktionale als auch analytische Queries unterstützt. Ein unglaublich ambitioniertes Vorhaben, denn es handelt sich um ein notorisch schwieriges Engineering-Problem.
Leider fielen auf dem Summit 2023 weder das Wort Unistore noch ein Hinweis auf die Hybrid Tables, die das Ganze unter der Haube antreiben. Wir vermuten, dass das Engineering-Team noch an den Feinheiten dieses komplexen Features arbeitet, bevor es in die Public Preview geht.
Update: Mehrere Leute haben sich gemeldet und mir mitgeteilt, dass es in einer dedizierten Session sehr wohl einen Talk zu Unistore gab – sorry, dass ich das übersehen habe! (Den Titel behalte ich trotzdem bei, weil er einfach hervorragender Clickbait ist! 😉)
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder & CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT hat Ian 6 Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One geleitet. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Kostentransparenz.