Io e Niall abbiamo partecipato al nostro primo Snowflake Data Cloud Summit nel 2022 e siamo rimasti folgorati dall'energia e dallo slancio della piattaforma. Abbiamo capito che era arrivato il momento di costruire qualcosa attorno a questo ecosistema in pieno fermento, ed è così che è nato SELECT.
La settimana scorsa siamo tornati a Las Vegas per il nostro secondo summit e non ci ha delusi. Snowflake ha presentato alcuni grandi annunci e ha svelato una serie di nuove funzionalità davanti a una sala gremita al Caesar's Palace. In questo articolo analizziamo le ultime novità, condividiamo le nostre impressioni su ciascuna e parliamo dell'unica cosa di cui non si è parlato.
Native Applications Framework (Public Preview)
Senza dubbio, l'annuncio più importante del Summit 2022 è stato il Native Applications Framework (Native Apps). Quest'anno è entrato in Public Preview.
Immagini se ogni volta che volesse scaricare un'app sul Suo iPhone dovesse visitare un sito diverso, informarsi sull'offerta e poi concedere a quell'azienda accesso diretto al telefono. Oggi è esattamente così che ogni azienda che utilizza Snowflake si rapporta con i vendor.

L'obiettivo delle Native Apps è portare sullo Snowflake Data Cloud un'esperienza simile a quella dell'App Store di iPhone. Invece di permettere ai vendor di collegarsi al data warehouse del cliente per estrarne i dati e poi rimetterli a disposizione in un'applicazione separata (esattamente come facciamo noi in SELECT), le Native Apps consentiranno ai vendor di eseguire le proprie applicazioni direttamente all'interno dell'account Snowflake del cliente. I vantaggi sono diversi:
- Maggiore sicurezza. I dati non lasciano mai il warehouse e nessuno al di fuori dell'azienda vi ha accesso. Non sarà nemmeno necessario gestire login o accessi separati per l'applicazione di terze parti: le Native Apps sfrutteranno la stessa autenticazione e gli stessi permessi del resto dell'account Snowflake.
- Procurement legale più semplice. La maggior parte dei rapporti con i vendor comporta un nuovo contratto da sottoporre alla revisione del team legale interno. Con le Native Apps, i team legali dovranno revisionare i termini del marketplace di Snowflake una sola volta, e non per ogni app installata.
- La fatturazione diventa molto più snella, perché tutto viene addebitato tramite Snowflake. Snowflake ha persino annunciato la possibilità per i clienti di pagare le app utilizzando la capacità del contratto già in essere, una funzionalità chiamata capacity drawdown.
In SELECT siamo davvero entusiasti del potenziale delle Native Apps: ci permetteranno di aiutare ancora più clienti Snowflake a massimizzare il ROI della piattaforma e a estrarre insight di valore, semplificando onboarding e procurement. Renderanno inoltre molto più immediata la condivisione di tutti i dataset esclusivi su costi e performance che generiamo.
Snowpark Container Services (Private Preview)
Snowpark Container Services (SCS) si è preso la scena al Summit 2023. Verso la fine del keynote, Christian Kleinerman ha guidato il pubblico attraverso 10 demo live di applicazioni con casi d'uso diversi, tutte eseguite in modo nativo in Snowflake tramite SCS.

Snowpark Container Services permetterà davvero di eseguire qualsiasi workload o applicazione in Snowflake. Come? Grazie a Docker. Potendo distribuire un container Docker direttamente in Snowflake tramite SCS, gli utenti non saranno più vincolati ai language runtime e agli ambienti supportati nativamente da Snowflake.
Snowpark Container Services supporterà un'ampia varietà di workload. Modelli di AI complessi potranno essere addestrati e distribuiti in SCS, sfruttando le nuove istanze GPU. Un job pianificato o una service function potrà essere eseguito in un container Snowpark. Oppure un servizio long-running, come un'applicazione web, potrà essere ospitato direttamente in SCS ed eseguito su Snowflake 24/7. Hex ha mostrato la sua elegante UI per i notebook (una complessa applicazione web in React) in esecuzione direttamente in un container Snowpark.
Un servizio in esecuzione 24/7 su Snowflake può sembrare costoso, ma stia tranquillo: verranno annunciate nuove tipologie di istanze di calcolo per SCS pensate proprio per rendere questi servizi economicamente sostenibili.
Managed Iceberg Tables (Private Preview)
Perché Iceberg?
Molte aziende hanno già grandi quantità di dati nel cloud storage, ma non caricati in Snowflake. Non sarebbe fantastico poter usare Snowflake sia per interrogare sia per aggiornare questi dataset?
Apache Iceberg è un formato di tabella open progettato per i dataset analitici. Si tratta di un livello di astrazione sui file di dati fisici (pensi ai file Parquet) che supporta transazioni ACID (atomicità, consistenza, isolamento, durabilità), evoluzione dello schema, partizionamento nascosto, snapshot delle tabelle e altre funzionalità. I motori di query devono sapere quali file compongono una determinata "tabella", e Iceberg fornisce proprio questa informazione.
Il supporto Iceberg già esistente in Snowflake
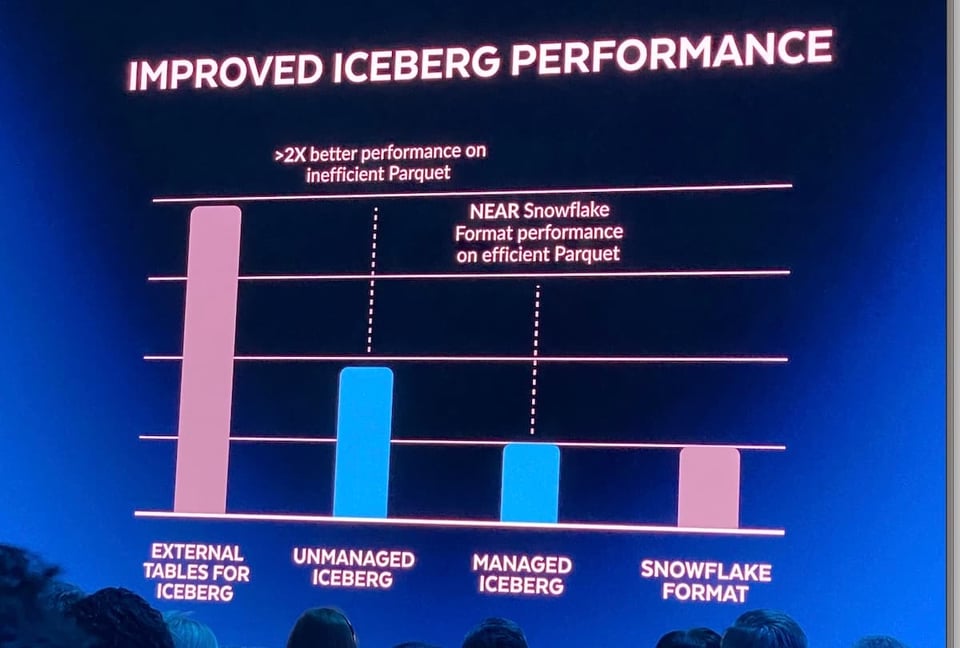
Fino allo scorso anno, l'unica opzione di Snowflake per interrogare i file di un data lake erano le external tables in sola lettura. Le query su queste tabelle avevano in genere performance inferiori rispetto alle tabelle salvate direttamente in Snowflake, per una serie di fattori. Al Summit 2022 Snowflake ha annunciato il supporto per le Iceberg Tables: i clienti possono così gestire il catalogo del proprio data lake con Iceberg e ottenere performance molto migliori grazie al motore di query di Snowflake, sfruttando i metadati forniti da Iceberg. Inoltre, il supporto a Iceberg consente di trattare le tabelle esterne (Iceberg) come normali tabelle Snowflake, con operazioni di update, delete e insert.
L'annuncio Iceberg al Summit 2023
Una delle sfide ancora aperte nell'uso di Iceberg è la necessità di un sistema che scriva e aggiorni costantemente i metadati Iceberg in un catalogo separato. Per affrontare questo problema, al Summit 2023 Snowflake ha annunciato le "managed iceberg tables". Ora gli utenti possono sfruttare le risorse di calcolo di Snowflake per gestire i dati Iceberg. Oltre a togliere di mezzo questo onere, dovrebbero notare anche miglioramenti sul fronte delle performance.
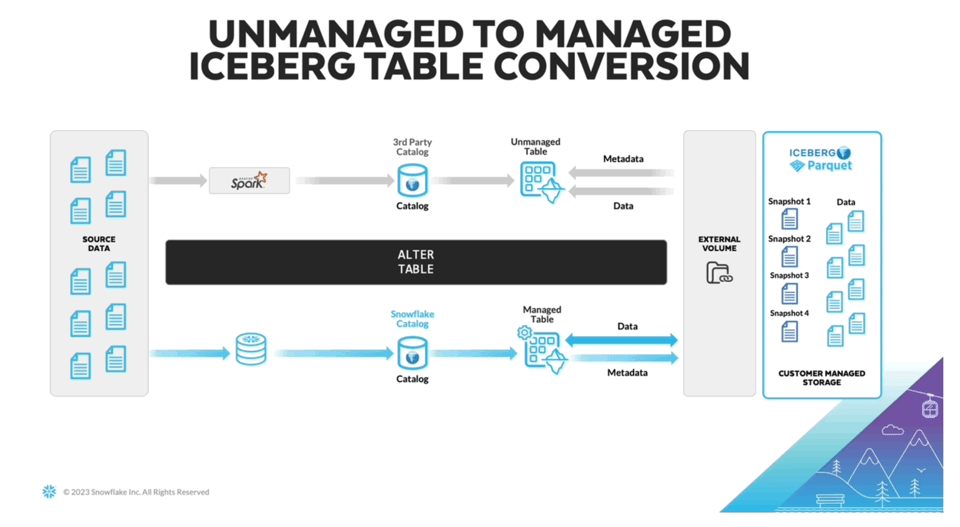
Vista l'assenza di documentazione di prodotto, credo che questa funzionalità sia attualmente in private preview. L'immagine qui sopra è tratta da James Malone su LinkedIn. Per chi si avvicina per la prima volta a Iceberg, ho trovato questo articolo un'ottima introduzione.
Dynamic Tables (Public Preview)
Uno dei principali fattori di costo della trasformazione dei dati che osserviamo nei clienti Snowflake, incluso il nostro stesso account, deriva dalla ricostruzione completa delle tabelle a ogni esecuzione della pipeline. Le tabelle vengono costruite così perché è più semplice e più veloce. Costruirle in modo incrementale è più delicato: bisogna tenere conto di fattori come i dati che arrivano in ritardo, il corretto high watermark da usare nel filtrare ogni dataset e altro ancora. Le pipeline di dati possono inoltre generare costi inutili, perché i job vengono eseguiti su una semplice pianificazione che non tiene conto di quando arrivano effettivamente nuovi dati a monte.
Snowflake supporta da tempo le Materialized Views (MV), che aiutano ad affrontare alcune di queste sfide aggiornando la tabella solo quando arrivano nuovi dati a monte. Hanno però diversi limiti: il più rilevante è che la definizione SQL della view non supporta operazioni comuni come join, union, aggregazioni, group by o window function.
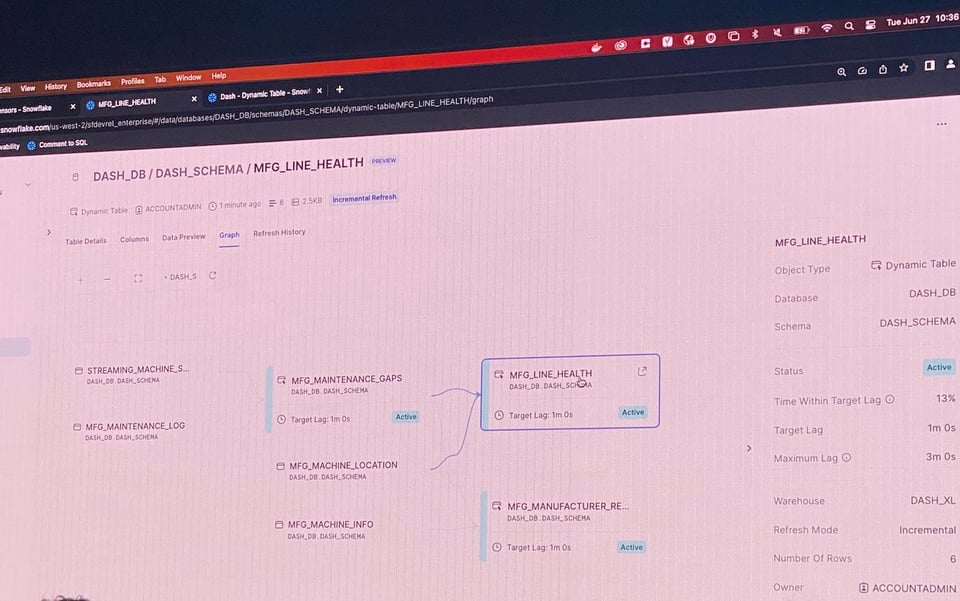
Al Summit di quest'anno, Snowflake ha annunciato che le Dynamic Tables (DT) sono ora in Public Preview. Le DT sono simili alle MV: si definisce la tabella con un'espressione SQL e Snowflake si occupa di materializzarla non appena arrivano nuovi dati a monte. Le DT offrono però una serie di ulteriori vantaggi:

- Hanno un supporto SQL molto più ampio e includono join, union, aggregazioni, window function e altro ancora.
- Elaborano i nuovi dati in modo incrementale, evitando di sprecare risorse ricalcolando ripetutamente gli stessi dati.
- Le MV diventavano molto costose quando la tabella a monte veniva aggiornata di frequente. Con le DT, Snowflake le aggiorna in base a un parametro di latenza definito dall'utente. Questo offre maggior controllo sulla frequenza di aggiornamento delle tabelle e, di conseguenza, sui costi di calcolo associati.
- Sono dotate di un supporto UI di prim'ordine. Gli utenti possono visualizzare facilmente le DT e le loro dipendenze e consultare le esecuzioni storiche nella tab
Refresh History.
Snowpipe Streaming API (Public Preview)
Snowflake ha annunciato che la Snowpipe Streaming API è ora in Public Preview. Snowpipe Streaming consente ai clienti di caricare dati in Snowflake direttamente da Apache Kafka o da un'applicazione Java personalizzata. È pensato per supportare i workloads che richiedono dati a bassa latenza.
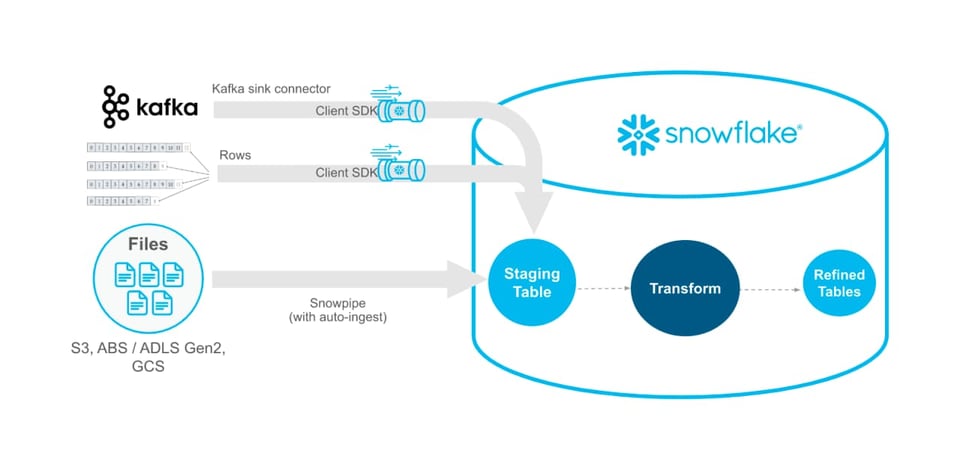
Snowpipe Streaming è anche il modo più conveniente per caricare dati, una volta predisposta l'infrastruttura necessaria. Altre strategie di data loading come Snowpipe o le istruzioni manuali COPY INTO eseguite su un warehouse autogestito prevedono il caricamento di un file da uno stage a Snowflake. Eliminando il costoso passaggio di lettura e l'overhead di gestione dei file, Snowpipe Streaming diventa un'opzione decisamente più economica.
Una raffica di annunci sull'AI
Visto tutto il clamore intorno all'AI generativa e agli LLM, non sorprende che Snowflake abbia annunciato una serie di nuove funzionalità AI in arrivo.
Partnership con Nvidia
Il primo giorno della conferenza, Snowflake ha annunciato una nuova partnership con Nvidia. Snowflake collaborerà con Nvidia per integrare NeMo, il framework LLM di Nvidia, all'interno di Snowflake. In questo modo gli Engineers potranno costruire large language model direttamente in Snowflake, utilizzando i dati che vi sono già archiviati.
Snowflake Copilot (TBD)
Snowflake ha mostrato una funzionalità molto interessante di "da commento a SQL", sulla falsariga di Github Copilot. Immagini di poter scrivere un commento come -- show me the count of daily active users over the last 30 days e che Snowflake generi automaticamente la query, sfruttando la conoscenza (a) dei Suoi dati e (b) dell'esatto dialetto SQL di Snowflake. Snowflake dispone del più grande dataset di addestramento di query immaginabile, quindi mi aspetto che questo modello superi qualsiasi soluzione preconfezionata offerta da altre aziende.
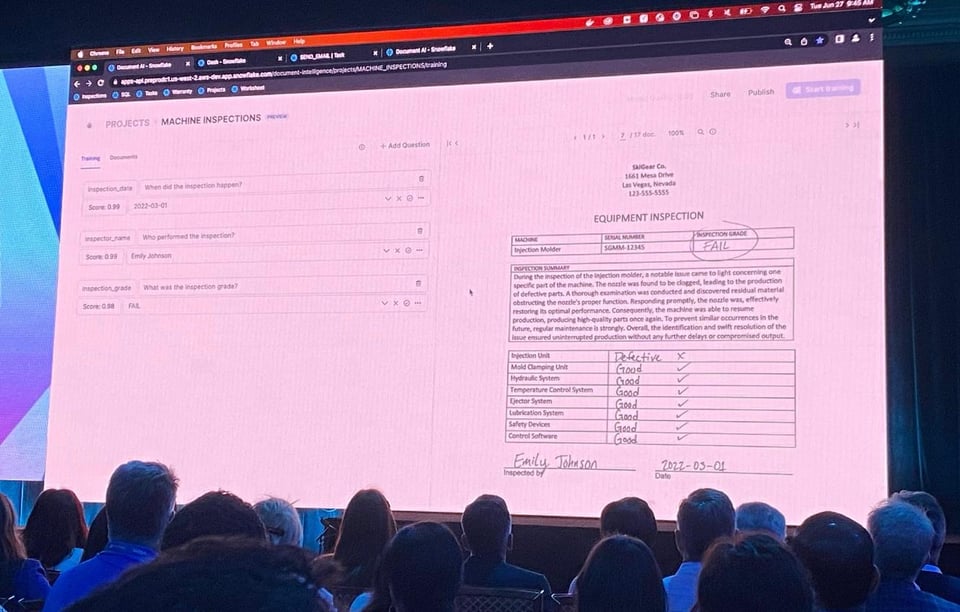
Document AI (Private Preview)
Ad aprile 2022, Snowflake ha acquisito Applica, società specializzata nell'analisi di dati non strutturati. Al Summit 2023, Snowflake ha annunciato una nuova funzionalità chiamata Document AI, che sfrutta proprio la tecnologia di Applica. È il primo LLM proprietario di Snowflake e permette di porre domande sui documenti archiviati in Snowflake.
Snowflake ha presentato una demo brillante in cui le informazioni venivano estratte automaticamente dai documenti e gli utenti potevano fornire feedback sui risultati per migliorare l'accuratezza del modello. Una volta addestrato, il modello può essere distribuito facilmente ed eseguito come UDF all'interno di una query SQL.
Vari aggiornamenti per gli sviluppatori
Il team di product management di Snowflake ha annunciato una raffica di aggiornamenti dedicati agli sviluppatori. Condivideremo maggiori dettagli man mano che li riceveremo:
- Una nuova Snowflake CLI e una REST API in Python (che affiancheranno l'esistente Snowflake Connector for Python).
- Lo Snowpark Model Registry, che consente ai data scientist di archiviare, pubblicare, scoprire e distribuire modelli ML in Snowflake.
- Diversi miglioramenti a Snowpark, tra cui un controllo più granulare dei pacchetti Python, il supporto a Python 3.9 e 3.10, l'accesso a reti esterne e le UDTF Python vettorializzate.
- Tre funzioni native basate sul machine learning, pensate per supportare gli utenti con forecasting, anomaly detection e contribution explorer.
- Nuove API di logging e tracing e sincronizzazione automatica tra git e gli stage di Snowflake, a supporto degli sviluppatori che lavorano sul Native Apps Framework.
- Streamlit sarebbe "molto vicino" alla public preview. Sono stati mostrati nuovi componenti Streamlit per costruire esperienze di chat.
Ottimizzazione e controllo dei costi
Contrariamente a quanto si pensa, Snowflake tiene molto a che i propri clienti utilizzino la piattaforma in modo efficace. L'azienda è consapevole di dover giocare sul lungo periodo, aiutando i clienti a ottenere il massimo valore da ogni dollaro speso su Snowflake.
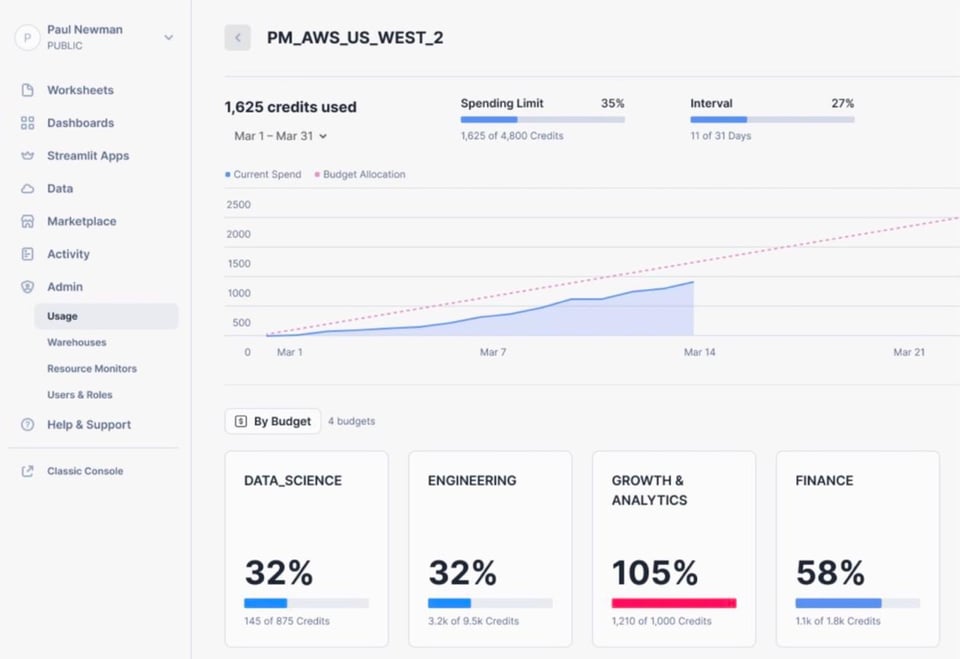
Budgets (Public Preview)
Per aiutare i clienti a tenere meglio sotto controllo la spesa su Snowflake, l'azienda ha annunciato che la funzionalità Budgets passerà in Public Preview. Fino a oggi gli utenti potevano impostare solo i resource monitor, che consentono di specificare il numero di crediti che un warehouse o un gruppo di warehouse può consumare. I Budgets vanno oltre: permettono di raggruppare più risorse Snowflake (warehouse, tabelle, materialized view, Snowpipe, ecc.) e di assegnare un limite di crediti (budget) a quel gruppo. Analogamente ai resource monitor, è possibile ricevere notifiche o sospendere le risorse sottostanti per evitare ulteriori addebiti una volta raggiunto il limite di crediti.
Grazie a Sonny per aver condiviso dettagli e immagine qui sotto.
Warehouse Utilization (Private Preview)
Una delle sfide più grandi per i clienti Snowflake è capire se i propri warehouse sono dimensionati correttamente. Per aiutarli, Snowflake ha annunciato in Private Preview una nuova metrica di utilizzo dei warehouse. Non abbiamo ulteriori dettagli al momento, ma non vediamo l'ora di esplorarla non appena sarà disponibile in Public Preview.
Miglioramenti delle performance
Snowflake ha annunciato numerosi miglioramenti delle performance del proprio motore di query e un nuovo Snowflake Performance Index (SPI) con cui misurerà e traccerà pubblicamente i progressi compiuti. Nel più puro stile Snowflake, tutti questi miglioramenti vengono applicati automaticamente e non richiedono alcuna azione da parte degli utenti per essere abilitati.

Colui che non deve essere nominato
Engineers e data practitioner sono abituati a lavorare con dati distribuiti su database diversi. È una costante della nostra realtà fin da quando, negli anni '70, fu creato il secondo database, ed è il motivo per cui è nata un'industria multimiliardaria attorno al movimento dei dati (ehm Fivetran).
Non si tratta affatto di una situazione ideale. Non sarebbe fantastico poter usare un solo database per tutto? Al Summit 2022, Snowflake aveva annunciato Unistore, un nuovo tipo di workload che supporta query sia transazionali sia analitiche. Un'iniziativa estremamente ambiziosa, perché è notoriamente uno dei problemi ingegneristici più ostici.
Purtroppo, al Summit 2023 non c'è stata alcuna menzione di Unistore né delle hybrid tables che lo alimentano sotto il cofano. Ipotizziamo che ciò sia dovuto al fatto che il team di ingegneria stia ancora rifinendo questa complessa funzionalità prima di aprirla alla Public Preview.
Aggiornamento: diverse persone mi hanno scritto per segnalarmi che in realtà c'è stata una sessione dedicata a Unistore, quindi mi scuso per la dimenticanza! (Detto questo, mantengo il titolo così com'è perché è un clickbait perfetto! 😉)
Ian Whitestone · Co-founder & CEO di SELECT
Ian è Co-founder e CEO di SELECT, piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, Ian ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify, ha guidato il lavoro di ottimizzazione del data warehouse e di potenziamento dell'osservabilità dei costi.