Niall et moi avons assisté à notre premier Snowflake Data Cloud Summit en 2022 et avons été bluffés par l'énergie et la dynamique qui entourent la plateforme. Nous savions qu'il fallait nous lancer dans la construction autour de cet écosystème florissant, et SELECT est né.
La semaine dernière, nous sommes retournés à Las Vegas pour notre deuxième summit, et l'évènement a tenu ses promesses. Snowflake a dévoilé plusieurs annonces majeures et présenté une foule de nouvelles fonctionnalités devant une salle comble au Caesar's Palace. Dans cet article, nous décortiquons les dernières innovations, partageons notre point de vue sur chacune et évoquons le seul sujet qu'ils n'ont pas mentionné.
Native Applications Framework (Public Preview)
Sans hésitation, la plus grosse annonce du Summit 2022 a été le Native Applications Framework (Native Apps). Cette année, il est passé en Public Preview.
Imaginez que, chaque fois que vous vouliez télécharger une application sur votre iPhone, vous deviez vous rendre sur un site différent, vous renseigner sur l'offre, puis donner à cette entreprise un accès direct à votre téléphone. C'est ainsi que toutes les entreprises utilisant Snowflake travaillent aujourd'hui avec leurs fournisseurs.

Native Apps vise à apporter au Snowflake Data Cloud une expérience similaire à celle de l'App Store de l'iPhone. Plutôt que de laisser les fournisseurs se connecter à leur data warehouse pour en extraire les données et les restituer dans une application distincte (comme nous le faisons chez SELECT), Native Apps permettra aux fournisseurs d'exécuter leurs applications directement dans le compte Snowflake du client. Plusieurs avantages à la clé :
- Une meilleure sécurité. Les données ne quittent jamais votre warehouse, et personne en dehors de votre entreprise n'y accède. Vous n'aurez pas non plus à gérer d'identifiants ou d'accès séparés à l'application tierce. Native Apps s'appuiera sur les mêmes mécanismes d'authentification et de permissions que le reste de votre compte Snowflake.
- Un Procurement juridique simplifié. La plupart des relations fournisseurs impliquent un nouveau contrat à faire valider par l'équipe juridique interne. Avec Native Apps, les équipes juridiques n'auront à examiner qu'une seule fois les conditions de la marketplace Snowflake, et non pour chaque application installée.
- Votre facture devient bien plus simple, puisque tout est facturé via Snowflake. Snowflake a même annoncé la possibilité, pour les clients, de payer les applications avec la capacité de leur contrat existant, une fonctionnalité appelée capacity drawdown.
Chez SELECT, nous sommes particulièrement enthousiastes face à la promesse de Native Apps : cela nous permettra d'aider encore plus de clients Snowflake à maximiser leur ROI et à débloquer des insights précieux en simplifiant l'onboarding et le Procurement. Cela facilitera aussi le partage de tous les jeux de données uniques sur les coûts et la performance que nous créons.
Snowpark Container Services (Private Preview)
Snowpark Container Services (SCS) a volé la vedette au Summit 2023. Vers la fin de la keynote, Christian Kleinerman a déroulé en direct 10 démonstrations d'applications, avec différents cas d'usage, s'exécutant nativement dans Snowflake grâce à SCS.

Snowpark Container Services vous permettra véritablement d'exécuter n'importe quel workload ou application dans Snowflake. Comment ? Grâce à Docker. En permettant aux utilisateurs de déployer un conteneur Docker directement dans Snowflake via SCS, ces derniers ne seront plus limités par les runtimes et environnements de langage pris en charge par Snowflake.
Snowpark Container Services prendra en charge une grande variété de workloads. Des modèles d'IA complexes peuvent être entraînés et déployés dans SCS, en tirant parti de nouvelles instances GPU. Une tâche planifiée ou une fonction de service peut s'exécuter dans un conteneur Snowpark. Un service longue durée, comme une application web, peut aussi être hébergé directement dans SCS et tourner 24/7 sur Snowflake. Hex a fait la démo de son interface notebooks soignée (une application web React complexe) tournant directement dans un conteneur Snowpark.
Faire tourner un service 24/7 dans Snowflake peut paraître coûteux, mais rassurez-vous : Snowflake annoncera de nouveaux types d'instances de calcul pour SCS afin de rendre ces services rentables.
Managed Iceberg Tables (Private Preview)
Pourquoi Iceberg ?
Beaucoup d'entreprises disposent déjà d'une grande partie de leurs données dans le stockage cloud, sans pour autant les avoir chargées dans Snowflake. Ne serait-il pas formidable de pouvoir utiliser Snowflake pour à la fois interroger et mettre à jour ces jeux de données ?
Apache Iceberg est un format de table ouvert conçu pour les jeux de données analytiques. Ce format constitue une couche d'abstraction au-dessus des fichiers de données physiques (pensez aux fichiers Parquet) et prend en charge les transactions ACID (atomicité, cohérence, isolation, durabilité), l'évolution de schéma, le partitionnement caché, les snapshots de tables, entre autres fonctionnalités. Les moteurs de requêtes ont besoin de savoir quels fichiers composent une table donnée, et c'est précisément ce que fournit Iceberg.
La prise en charge existante d'Iceberg par Snowflake
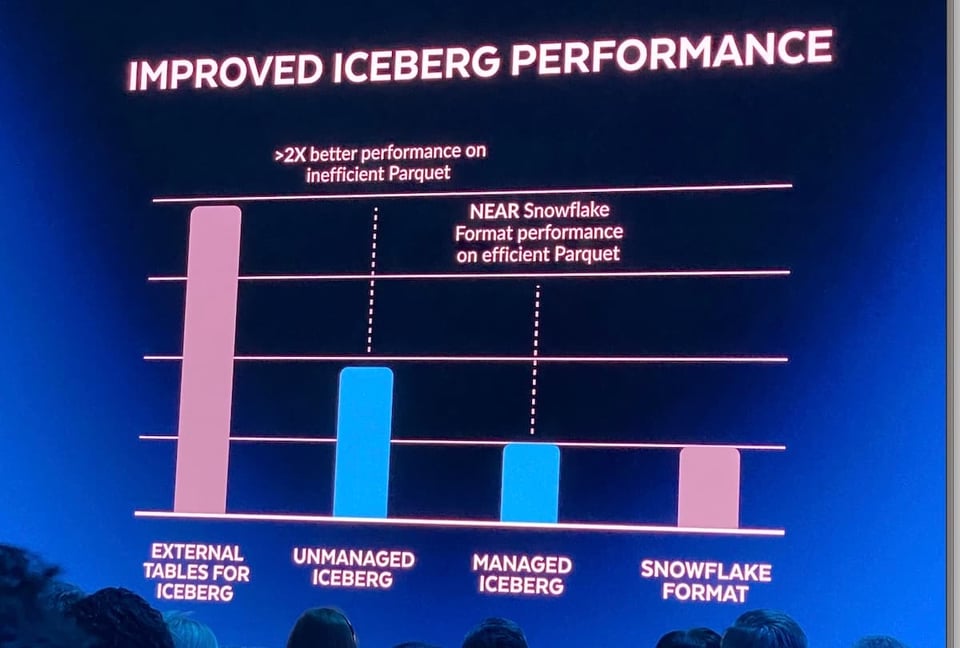
Jusqu'à l'an dernier, la seule option proposée par Snowflake pour interroger des fichiers de data lake était ses tables externes en lecture seule. Les performances de ces requêtes étaient généralement inférieures à celles des tables stockées directement dans Snowflake, pour diverses raisons. Au Summit 2022, Snowflake a annoncé la prise en charge des Iceberg Tables : les clients peuvent gérer le catalogue de leur data lake avec Iceberg et obtenir de bien meilleures performances avec le moteur de requêtes Snowflake grâce aux métadonnées fournies par Iceberg. De plus, cette prise en charge permet de traiter les tables externes (Iceberg) comme des tables Snowflake classiques, avec mises à jour, suppressions et insertions.
L'annonce Iceberg du Summit 2023
Un défi subsiste avec Iceberg : il faut un système capable d'écrire et de mettre à jour en continu les métadonnées Iceberg dans un catalogue séparé. Pour y répondre, Snowflake a annoncé les managed iceberg tables au Summit 2023. Les utilisateurs peuvent désormais s'appuyer sur les ressources de calcul Snowflake pour gérer les données Iceberg. En plus de lever cette contrainte, ils devraient aussi constater des gains de performance.
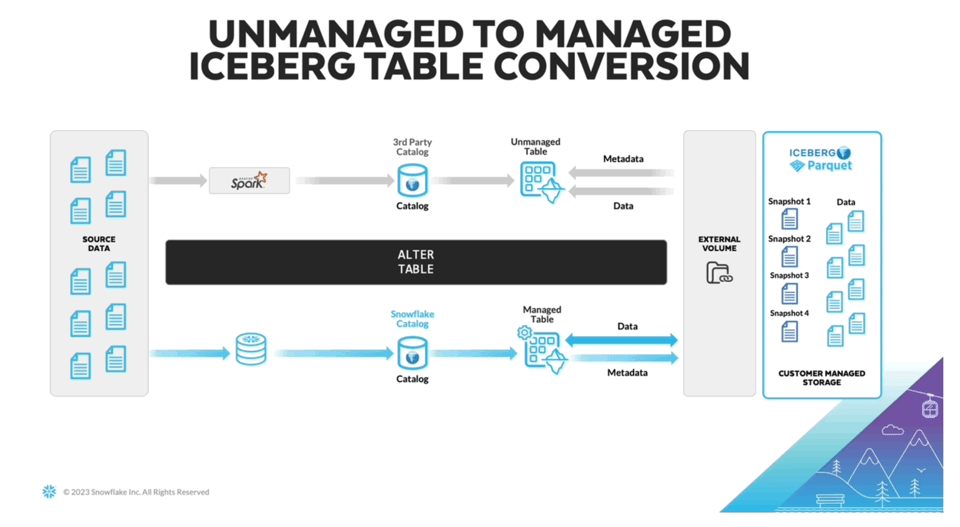
En l'absence de documentation produit, je pense que cette fonctionnalité est actuellement en private preview. L'image ci-dessus provient de James Malone sur LinkedIn. Pour celles et ceux qui découvrent Iceberg, cet article de blog constitue une bonne introduction.
Dynamic Tables (Public Preview)
L'un des principaux postes de coûts liés à la transformation de données que nous observons chez les clients Snowflake, y compris dans notre propre compte, provient de la reconstruction complète des tables à chaque exécution du pipeline. Cette approche est privilégiée parce qu'elle est à la fois plus rapide et plus simple. Construire une table de manière incrémentale est plus subtil, car il faut prendre en compte des facteurs comme l'arrivée tardive de données, le bon high watermark à utiliser pour filtrer chaque jeu de données, etc. Les pipelines peuvent aussi générer des coûts inutiles, car les jobs s'exécutent selon un simple calendrier qui ne tient pas compte du moment où de nouvelles données amont sont disponibles.
Snowflake prend depuis longtemps en charge les Materialized Views (MVs), qui permettent de surmonter une partie de ces défis en ne rafraîchissant la table que lorsque de nouvelles données arrivent en amont. Elles présentent toutefois plusieurs limites, dont une majeure : votre définition de vue SQL ne prend pas en charge diverses opérations courantes telles que les jointures, les unions, les agrégations, les group by ou les fonctions de fenêtre.
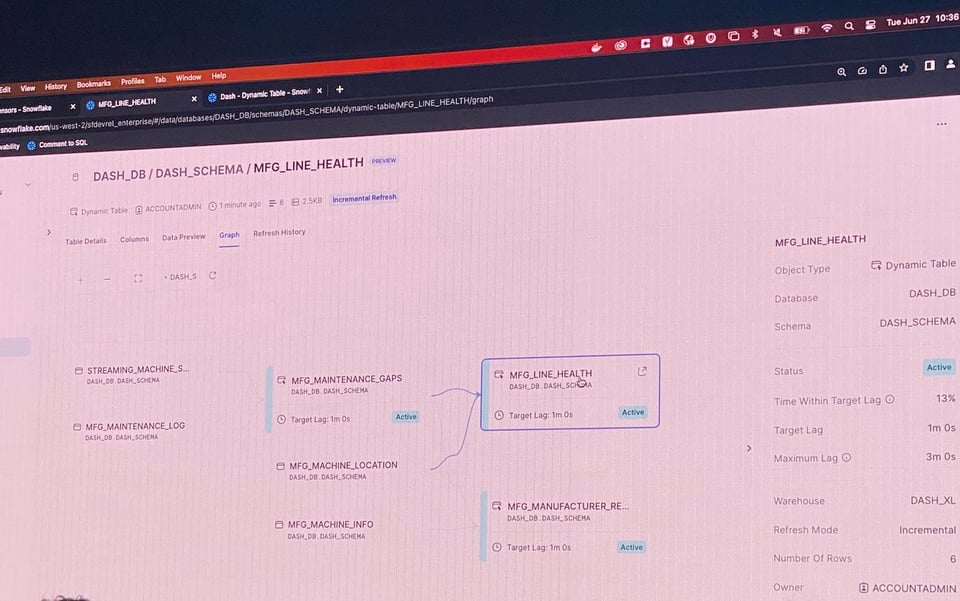
Lors du Summit de cette année, Snowflake a annoncé que les Dynamic Tables (DTs) sont désormais en Public Preview. Les DTs sont similaires aux MVs : vous définissez votre table avec une expression SQL et Snowflake se charge de matérialiser cette expression dès que de nouvelles données arrivent en amont. Les DTs offrent plusieurs autres avantages :

- Elles offrent une prise en charge SQL bien plus étendue : jointures, unions, agrégations, fonctions de fenêtre et bien plus.
- Elles traitent les nouvelles données de manière incrémentale, ce qui évite de gaspiller des ressources à recalculer sans cesse les mêmes données.
- Les MVs devenaient très coûteuses lorsque la table amont était fréquemment mise à jour. Avec les DTs, Snowflake les met à jour selon un paramètre de latence que vous définissez. Cela donne aux utilisateurs davantage de contrôle sur la fréquence de mise à jour, et donc sur les coûts de calcul associés.
- Elles bénéficient d'une prise en charge UI de premier ordre. Les utilisateurs peuvent facilement visualiser les DTs et leurs dépendances, et consulter l'historique des exécutions dans l'onglet
Refresh History.
Snowpipe Streaming API (Public Preview)
Snowflake a annoncé que la Snowpipe Streaming API est désormais en Public Preview. Snowpipe Streaming permet aux clients de charger des données dans Snowflake directement depuis Apache Kafka ou depuis une application Java personnalisée. Snowpipe Streaming facilite la prise en charge des workloads exigeant une plus faible latence.
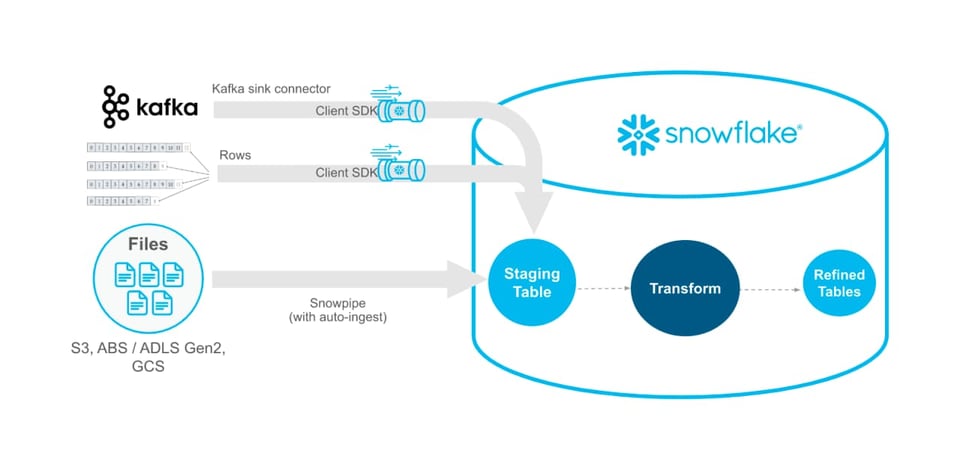
Snowpipe Streaming est aussi la méthode la plus économique pour charger des données, une fois l'infrastructure nécessaire en place. Les autres stratégies de chargement de données, comme Snowpipe ou les instructions manuelles COPY INTO exécutées sur un warehouse autogéré, impliquent toutes deux de charger un fichier depuis un stage vers Snowflake. En évitant l'étape coûteuse de lecture et le surcoût lié à la gestion des fichiers, Snowpipe Streaming devient une option plus rentable.
Une avalanche d'annonces autour de l'IA
Compte tenu de l'attention portée à l'IA générative et aux LLM, il n'est pas surprenant que Snowflake ait annoncé une série de fonctionnalités d'IA à venir.
Partenariat avec Nvidia
Le premier jour de la conférence, Snowflake a annoncé un nouveau partenariat avec Nvidia. Snowflake s'associe à Nvidia pour intégrer NeMo, le framework LLM de Nvidia, à Snowflake. Cela aidera les Engineers à construire des grands modèles de langage directement dans Snowflake, à partir des données qu'ils y ont déjà stockées.
Snowflake Copilot (à venir)
Snowflake a présenté une fonctionnalité très réussie de commentaire vers SQL, à la manière de Github Copilot. Imaginez pouvoir écrire un commentaire du type -- show me the count of daily active users over the last 30 days et voir Snowflake générer automatiquement la requête à partir de sa connaissance (a) de vos données et (b) du dialecte SQL spécifique à Snowflake. Snowflake dispose du plus grand jeu de données d'entraînement de requêtes imaginable, je m'attends donc à ce que ce modèle surpasse tout ce que d'autres entreprises proposent sur étagère.
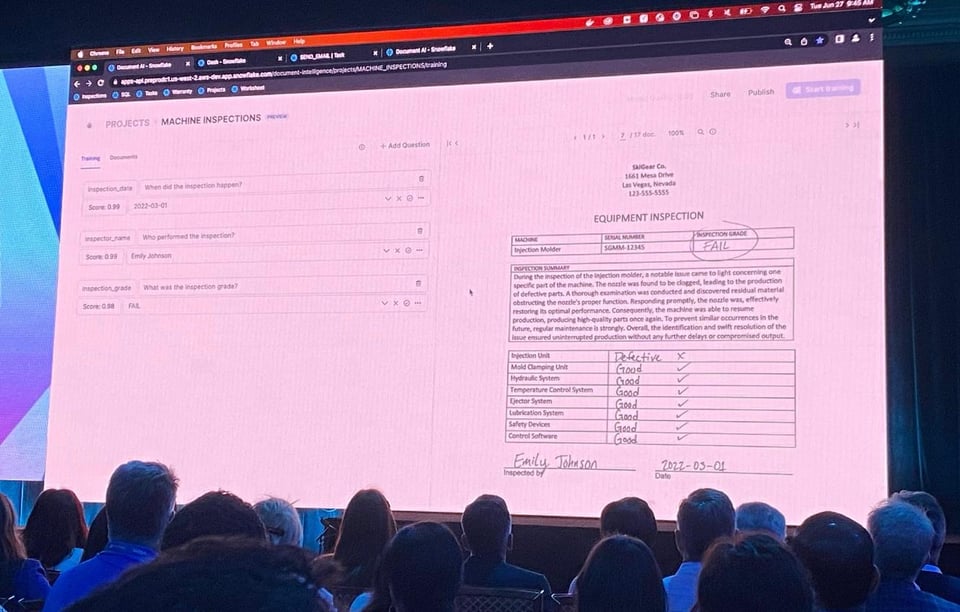
Document AI (Private Preview)
En avril 2022, Snowflake a racheté une société du nom d'Applica, spécialisée dans l'analyse de données non structurées. Au Summit 2023, Snowflake a annoncé une nouvelle fonctionnalité, Document AI, qui s'appuie sur la technologie d'Applica. Il s'agit du premier LLM propriétaire de Snowflake, et il vous permet de poser des questions sur les documents stockés dans Snowflake.
Snowflake a livré une démo bluffante : des informations étaient extraites automatiquement de documents, et les utilisateurs pouvaient fournir un feedback sur les éléments récupérés afin d'améliorer la précision du modèle. Ils pouvaient ensuite déployer facilement le modèle entraîné et l'exécuter comme une UDF dans une requête SQL.
Diverses mises à jour pour les développeurs
L'équipe Product Management de Snowflake a annoncé une série de mises à jour pour les développeurs. Nous partagerons davantage de détails au fil de leur disponibilité :
- Une nouvelle CLI Snowflake ainsi qu'une REST API Python (en complément du Snowflake Connector for Python existant)
- Le Snowpark Model Registry, qui permet aux data scientists de stocker, publier, découvrir et servir des modèles ML dans Snowflake.
- Plusieurs améliorations de Snowpark : contrôle plus granulaire des packages Python, prise en charge de Python 3.9 et 3.10, accès au réseau externe et UDTFs Python vectorisées.
- Trois fonctions natives basées sur le machine learning pour aider les utilisateurs sur la prévision, la détection d'anomalies et l'exploration des contributions.
- De nouvelles APIs de logging et de tracing, ainsi qu'une synchronisation automatique entre les stages git et Snowflake pour les développeurs qui construisent dans le Native Apps Framework.
- Streamlit serait très proche de la public preview. De nouveaux composants Streamlit pour construire des expériences de chat ont été présentés.
Optimisation et maîtrise des coûts
Contrairement à ce que beaucoup pensent, Snowflake se soucie profondément de l'utilisation efficace de sa plateforme par ses clients. Snowflake sait qu'il faut jouer sur le long terme et aider ses clients à tirer le maximum de valeur de chaque dollar dépensé sur la plateforme.
Budgets (Public Preview)
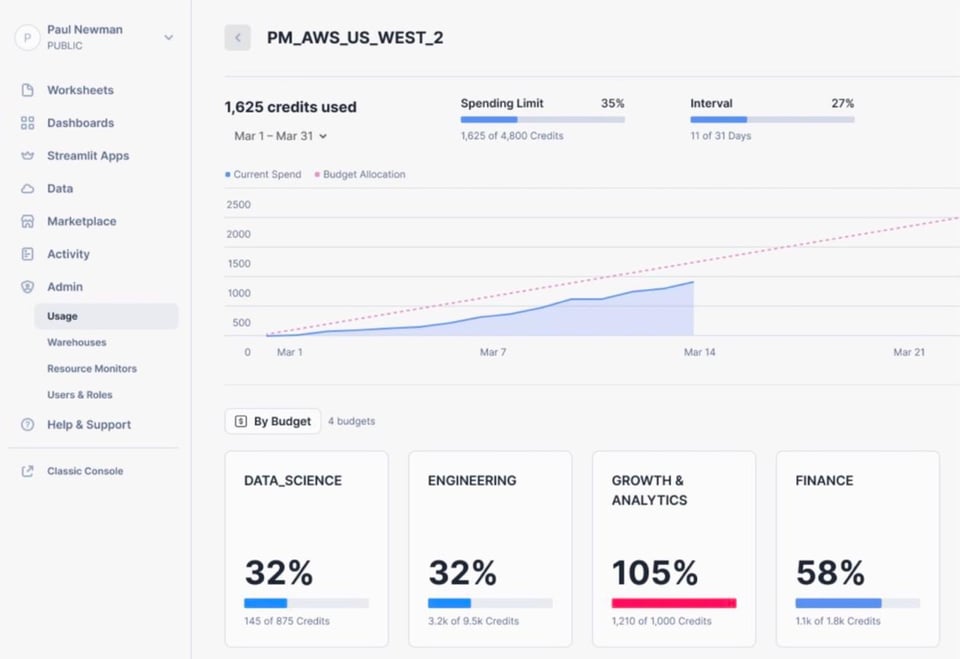
Pour aider ses clients à mieux maîtriser leurs dépenses Snowflake, Snowflake a annoncé que sa fonctionnalité Budgets passe en Public Preview. Avant Budgets, les utilisateurs ne pouvaient définir que des resource monitors, qui permettent de spécifier le nombre de credits qu'un warehouse ou un groupe de warehouses peut consommer. Budgets va plus loin en permettant de regrouper davantage de ressources Snowflake (warehouses, tables, materialized views, Snowpipes, etc.) et d'assigner une limite de credits (budget) à ce groupe de ressources. Comme pour les resource monitors, vous pouvez ensuite être alerté ou suspendre les ressources sous-jacentes pour éviter de nouveaux coûts une fois la limite atteinte.
Merci à Sonny pour le partage des détails et de l'image ci-dessous.
Warehouse Utilization (Private Preview)
L'un des plus grands défis pour les clients Snowflake est de savoir si leurs warehouses sont correctement dimensionnés. Pour les aider, Snowflake a annoncé une nouvelle métrique d'utilisation des warehouses en Private Preview. Nous n'avons pas plus de détails à ce stade, mais nous sommes impatients de l'explorer dès qu'elle sera en Public Preview.
Améliorations de performance
Snowflake a annoncé une série d'améliorations de performance pour son moteur de requêtes ainsi qu'un nouveau Snowflake Performance Index (SPI) qui servira à mesurer et suivre publiquement les progrès réalisés. Fidèle à sa philosophie, Snowflake applique automatiquement toutes ces améliorations : les utilisateurs n'ont aucune action à entreprendre pour en bénéficier.

Celui dont on ne doit pas prononcer le nom
Les Engineers et praticiens de la donnée ont l'habitude de travailler avec des données réparties dans différentes bases. C'est la réalité depuis la création de la deuxième base de données dans les années 70, et c'est ce qui explique l'existence d'une industrie de plusieurs milliards de dollars autour du déplacement de données (toux Fivetran).
Cette situation n'a rien de souhaitable. Ne serait-il pas formidable de pouvoir utiliser une seule base de données pour tout ? Au Summit 2022, Snowflake a annoncé Unistore, un nouveau type de workload prenant en charge à la fois les requêtes transactionnelles et analytiques. Le projet était extrêmement ambitieux, car il s'agit d'un problème d'ingénierie notoirement complexe.
Malheureusement, ni Unistore ni les hybrid tables qui le motorisent n'ont été mentionnés au Summit 2023. Nous supposons que l'équipe d'ingénierie peaufine encore cette fonctionnalité complexe avant de l'ouvrir en Public Preview.
Mise à jour : plusieurs personnes m'ont signalé qu'une session dédiée à Unistore avait bien eu lieu, désolé pour cet oubli ! (Cela dit, je garde le titre tel quel : c'est un excellent clickbait ! 😉)
Ian Whitestone · Co-fondateur et CEO de SELECT
Ian est co-fondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à diriger des équipes full stack data science et engineering chez Shopify et Capital One. Chez Shopify, Ian a piloté les efforts d'optimisation du data warehouse et d'amélioration de la visibilité sur les coûts.