Niall y yo asistimos a nuestro primer Snowflake Data Cloud Summit en 2022 y quedamos impactados por la energía y el impulso detrás de la plataforma. Supimos que teníamos que empezar a construir alrededor de ese ecosistema en pleno crecimiento, y así nació SELECT.
La semana pasada volvimos a Las Vegas para nuestro segundo summit, y no nos defraudó. Snowflake presentó varios anuncios importantes y compartió un montón de nuevas funcionalidades ante una sala repleta en el Caesar's Palace. En este artículo profundizamos en las últimas innovaciones, compartimos nuestra opinión sobre cada una y hablamos de lo único que no mencionaron.
Native Applications Framework (Public Preview)
Sin lugar a dudas, el mayor anuncio del Summit 2022 fue el Native Applications Framework (Native Apps). Este año pasó a Public Preview.
Imagina que cada vez que quisieras descargar una app en tu iPhone tuvieras que ir a un sitio web distinto, conocer la propuesta y luego darle a esa empresa acceso directo a tu teléfono. Así es como trabaja hoy con sus proveedores cualquier empresa que use Snowflake.

Native Apps busca llevar una experiencia similar a la del App Store del iPhone al Snowflake Data Cloud. En lugar de que los clientes de Snowflake permitan a los proveedores conectarse a su data warehouse y extraer sus datos para luego devolvérselos en una aplicación aparte ( tal como hacemos nosotros en SELECT), Native Apps permitirá que los proveedores ejecuten sus aplicaciones directamente dentro de la cuenta Snowflake del cliente. Esto trae varios beneficios:
- Mayor seguridad. Los datos nunca salen de tu warehouse y nadie fuera de tu empresa accede a ellos. Tampoco tienes que gestionar logins o accesos separados para la aplicación de terceros. Native Apps aprovecha la misma autenticación y permisos que el resto de tu cuenta Snowflake.
- Procurement legal más simple. La mayoría de las relaciones con proveedores implican un contrato nuevo que el equipo legal interno tiene que revisar. Con Native Apps, los equipos legales solo tendrán que revisar los términos del marketplace de Snowflake una vez, y no para cada app que se instale.
- La factura se vuelve mucho más simple, ya que todo se cobra a través de Snowflake. Snowflake incluso anunció la posibilidad de que los clientes paguen las apps con la capacidad de su contrato actual, una funcionalidad llamada capacity drawdown.
En SELECT estamos enormemente entusiasmados con la promesa de Native Apps, porque nos permitirá ayudar a aún más clientes de Snowflake a maximizar su ROI en Snowflake y aprovechar insights valiosos al simplificar el onboarding y el Procurement. También facilitará compartir los datasets únicos de costos y rendimiento que generamos.
Snowpark Container Services (Private Preview)
Snowpark Container Services (SCS) se robó el show en el Summit 2023. Hacia el final del keynote, Christian Kleinerman recorrió 10 demos en vivo de aplicaciones con distintos casos de uso ejecutándose de forma nativa en Snowflake usando SCS.

Snowpark Container Services te permitirá ejecutar realmente cualquier workload o aplicación en Snowflake. ¿Cómo funciona? Con Docker. Al permitir que los usuarios desplieguen un contenedor Docker directamente en Snowflake con SCS, dejarán de estar limitados por los runtimes y entornos de lenguaje que soporta Snowflake.
Snowpark Container Services soportará una variedad de workloads distintos. Se pueden entrenar y desplegar modelos complejos de IA en SCS, aprovechando las nuevas instancias GPU. Un job programado o una service function puede correr dentro de un contenedor Snowpark. O un servicio de larga duración, como una aplicación web, puede alojarse directamente en SCS y correr en Snowflake 24/7. Hex mostró en demo su elegante UI de notebooks (una compleja aplicación web en React) corriendo directamente dentro de un contenedor Snowpark.
Un servicio corriendo 24/7 en Snowflake suena caro, pero tranquilo: anunciarán nuevos tipos de instancias de cómputo para SCS que harán que estos servicios sean rentables.
Managed Iceberg Tables (Private Preview)
¿Por qué Iceberg?
Muchas empresas ya tienen gran parte de sus datos en almacenamiento en la nube, pero sin cargarlos en Snowflake. ¿No sería genial poder usar Snowflake para consultar y actualizar esos datasets?
Apache Iceberg es un formato de tabla abierto diseñado para datasets analíticos. Este formato es una capa de abstracción sobre los archivos físicos de datos (piensa en archivos Parquet) que soporta transacciones ACID (atomicidad, consistencia, aislamiento, durabilidad), evolución de esquemas, particionamiento oculto, snapshots de tablas, entre otras funcionalidades. Los query engines necesitan saber qué archivos componen una determinada "tabla", y eso es justamente lo que provee Iceberg.
El soporte actual de Snowflake para Iceberg
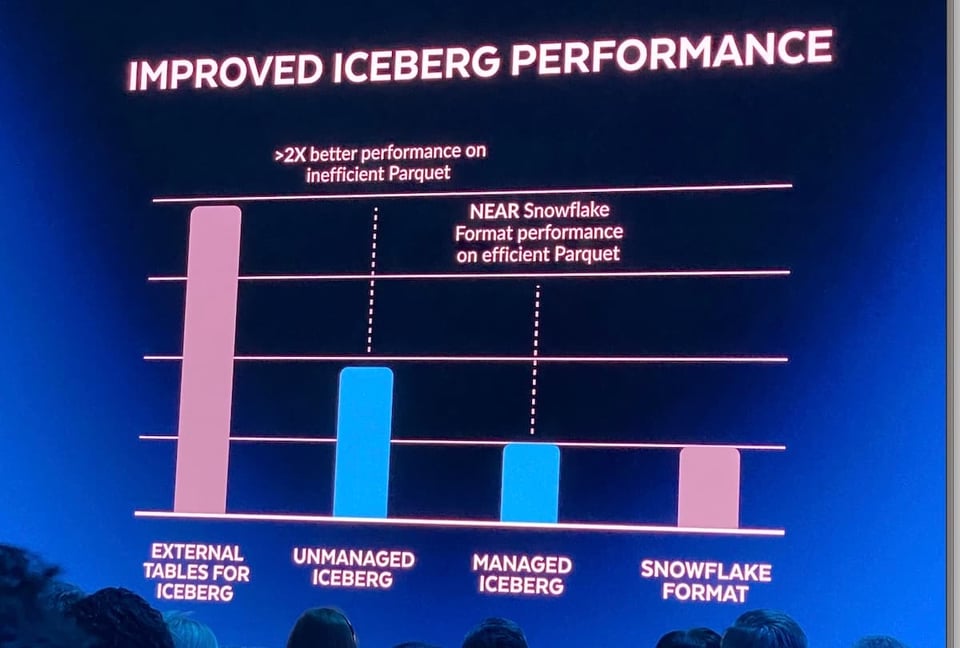
Hasta el año pasado, la única opción de Snowflake para consultar archivos del data lake eran sus external tables de solo lectura. Consultar estas tablas en general tenía peor rendimiento que las tablas almacenadas directamente en Snowflake, por varios factores. En el Summit 2022, Snowflake anunció soporte para Iceberg Tables, lo que significa que los clientes podían administrar su data lake catalog con Iceberg y obtener un rendimiento mucho mejor con el query engine de Snowflake gracias a los metadatos que provee Iceberg. Además, el soporte de Iceberg permite tratar las tablas externas (Iceberg) como tablas normales de Snowflake, con updates, deletes e inserts.
Anuncio de Iceberg en el Summit 2023
Un desafío que persistía al usar Iceberg es que se necesita un sistema que escriba y actualice continuamente los metadatos de Iceberg en un catálogo separado. Para resolver eso, Snowflake anunció las "managed iceberg tables" en el Summit 2023. Ahora los usuarios pueden aprovechar los recursos de cómputo de Snowflake para administrar los datos de Iceberg. Además de quitarse esa carga de encima, también deberían ver mejoras de rendimiento.
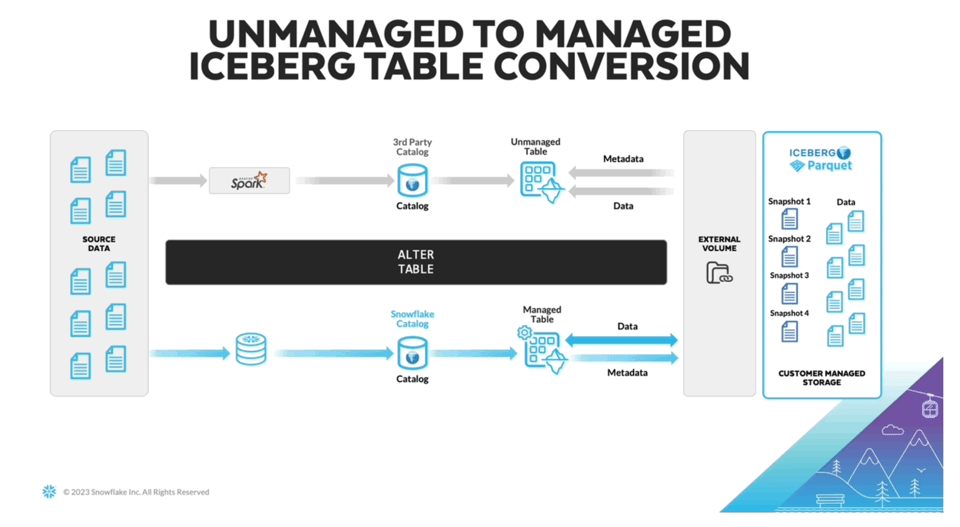
Dado que no hay documentación de producto disponible, creo que esta funcionalidad está actualmente en private preview. La imagen de arriba la tomé de James Malone en LinkedIn. Para quienes recién se acercan a Iceberg, este artículo me pareció una buena introducción.
Dynamic Tables (Public Preview)
Uno de los mayores generadores de costos de transformación de datos que vemos en los clientes de Snowflake, incluida nuestra propia cuenta, viene de reconstruir tablas por completo cada vez que se ejecuta el data pipeline. Las tablas se construyen así porque resulta más rápido y más fácil. Construir una tabla de forma incremental es más complejo, porque hay que considerar factores como datos que llegan tarde, el high watermark correcto al filtrar cada dataset, y más. Los data pipelines también pueden incurrir en costos innecesarios cuando los jobs se ejecutan con un schedule simple que no contempla cuándo se cargan nuevos datos upstream.
Snowflake soporta desde hace tiempo las Materialized Views (MVs), que ayudan con algunos de estos desafíos al refrescar la tabla solo cuando llegan nuevos datos upstream. Sin embargo, tienen varias limitaciones; una importante es que la definición SQL de la view no soporta una variedad de operaciones comunes como joins, unions, agregaciones, group by o window functions.
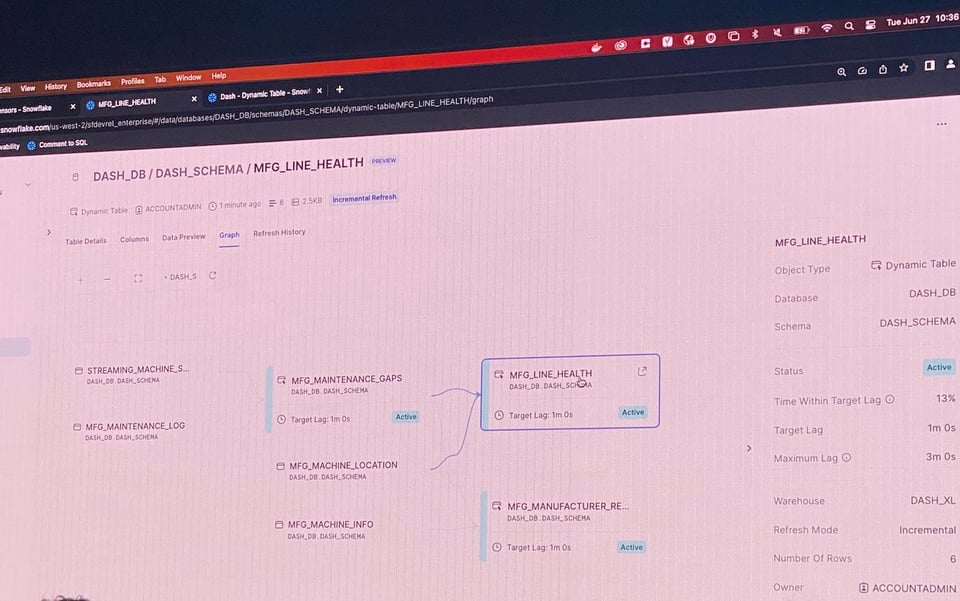
En el Summit de este año, Snowflake anunció que las Dynamic Tables (DTs) ya están en Public Preview. Las DTs son similares a las MVs en que defines tu tabla con una expresión SQL y Snowflake se encarga de materializar esa expresión cuando llegan nuevos datos upstream. Las DTs ofrecen una serie de ventajas adicionales:

- Tienen un soporte de SQL mucho más amplio: joins, unions, agregaciones, window functions, entre otros.
- Procesan los nuevos datos de forma incremental, así que no desperdician recursos recalculando los mismos datos una y otra vez.
- Las MVs se volvían muy caras cuando la tabla upstream se actualizaba con frecuencia. Con las DTs, Snowflake las actualiza con base en un parámetro de latencia que tú defines. Esto te da más control sobre la frecuencia con la que se actualizan esas tablas y, por consiguiente, sobre los costos de cómputo asociados.
- Cuentan con soporte de UI de primera. Los usuarios pueden visualizar fácilmente las DTs y sus dependencias, y ver el historial de ejecuciones en la pestaña
Refresh History.
Snowpipe Streaming API (Public Preview)
Snowflake anunció que la Snowpipe Streaming API ya está en Public Preview. Snowpipe Streaming permite a los clientes cargar datos en Snowflake directamente desde Apache Kafka o desde una aplicación Java personalizada. Snowpipe Streaming ayuda a soportar workloads que requieren datos con menor latencia.
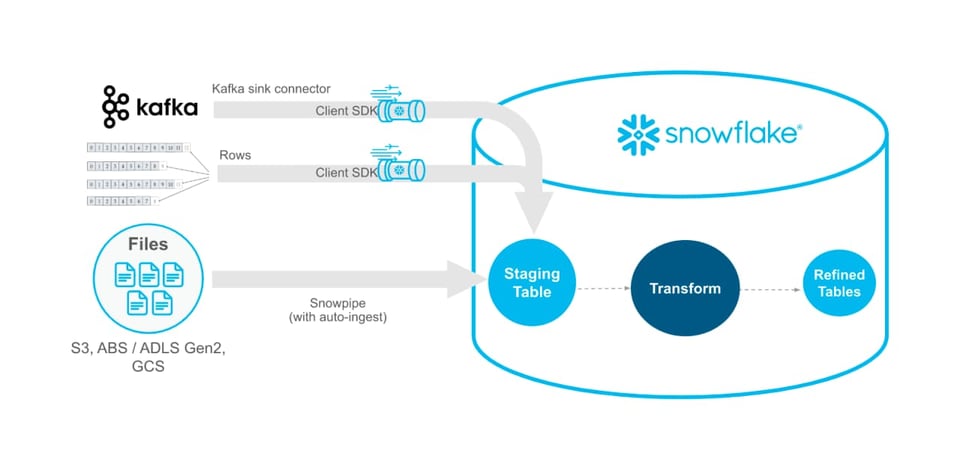
Snowpipe Streaming es además la forma más rentable de cargar datos, una vez que tienes la infraestructura necesaria. Las estrategias alternativas de data loading, como Snowpipe o las sentencias COPY INTO ejecutadas manualmente en un warehouse autogestionado, implican cargar un archivo desde un stage hacia Snowflake. Al evitar el costoso paso de lectura y la sobrecarga de gestión de archivos, Snowpipe Streaming se convierte en una opción más eficiente en costos.
Un montón de anuncios de IA
Con todo el ruido alrededor de la IA generativa y los LLMs, no sorprendió que Snowflake anunciara una serie de funcionalidades de IA por venir.
Alianza con Nvidia
El primer día de la conferencia, Snowflake anunció una nueva alianza con Nvidia. Snowflake se aliará con Nvidia para integrar NeMo, el framework de LLM de Nvidia, dentro de Snowflake. Esto les permitirá a los Engineers construir large language models directamente en Snowflake, usando los datos que ya tienen almacenados allí.
Snowflake Copilot (TBD)
Snowflake mostró en demo una funcionalidad muy interesante de "comentario a SQL", muy al estilo de Github Copilot. Imagina poder escribir un comentario como -- muéstrame el conteo de usuarios activos diarios de los últimos 30 días y que Snowflake genere automáticamente la query usando su conocimiento de (a) tus datos y (b) el dialecto SQL exacto de Snowflake. Snowflake está sentado sobre el mayor dataset de entrenamiento de queries posible, así que espero que este modelo supere a cualquier alternativa lista para usar de otras empresas.
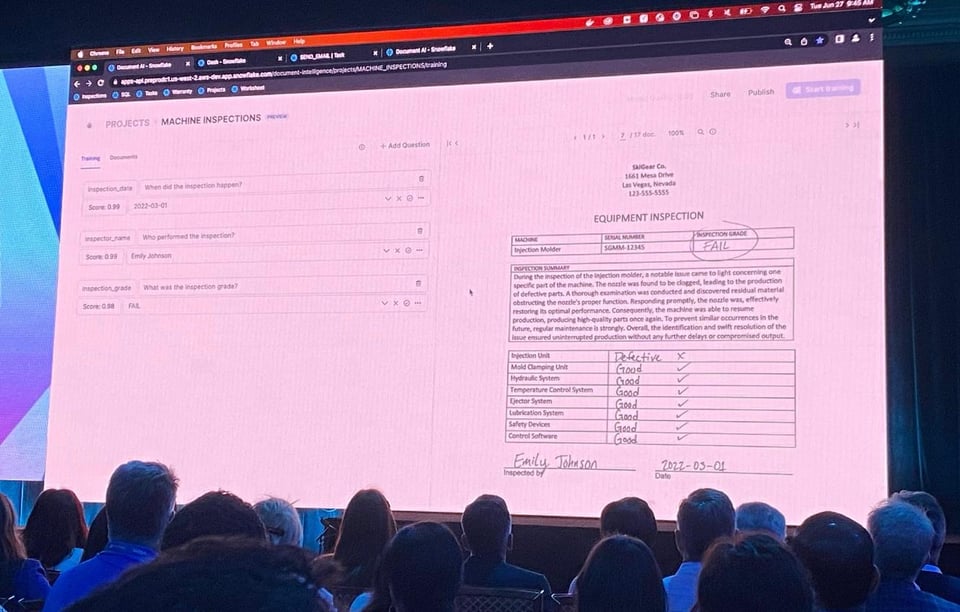
Document AI (Private Preview)
En abril de 2022, Snowflake adquirió una empresa llamada Applica, especializada en analizar datos no estructurados. En el Summit 2023, Snowflake anunció una nueva funcionalidad llamada Document AI que aprovecha la tecnología de Applica. Es el primer LLM propio de Snowflake y te permite hacer preguntas sobre documentos que tienes almacenados en Snowflake.
Snowflake mostró una demo muy interesante en la que se extraía información automáticamente de documentos, y los usuarios podían dar feedback sobre la información recuperada para mejorar la precisión del modelo. Luego, los usuarios podían desplegar fácilmente el modelo entrenado y ejecutarlo como una UDF dentro de una query SQL.
Varias actualizaciones para developers
El equipo de product management de Snowflake anunció una serie de actualizaciones para developers. Compartiremos más detalles a medida que los recibamos:
- Una nueva Snowflake CLI y una rest API de Python (para complementar el Snowflake Connector for Python existente).
- El Snowpark Model Registry, que permite a los data scientists almacenar, publicar, descubrir y servir modelos de ML en Snowflake.
- Varias mejoras en Snowpark, incluyendo un control más granular de paquetes de Python, soporte para Python 3.9 y 3.10, acceso a red externa y UDTFs de Python vectorizadas.
- Tres funciones nativas potenciadas por machine learning que ayudarán a los usuarios con forecasting, detección de anomalías y exploración de contribuciones.
- Nuevas APIs de logging y tracing, y sincronización automática entre git y los stages de Snowflake para apoyar a los developers que construyen sobre el Native Apps Framework.
- Streamlit aparentemente está "muy cerca" del public preview. Mostraron nuevos componentes de Streamlit para crear experiencias de chat.
Optimización y control de costos
Contrario a lo que mucha gente piensa, a Snowflake le importa profundamente que sus clientes usen Snowflake de manera efectiva. Snowflake entiende que tiene que jugar a largo plazo y ayudar a los clientes a obtener el mayor valor de cada dólar que gastan en Snowflake.
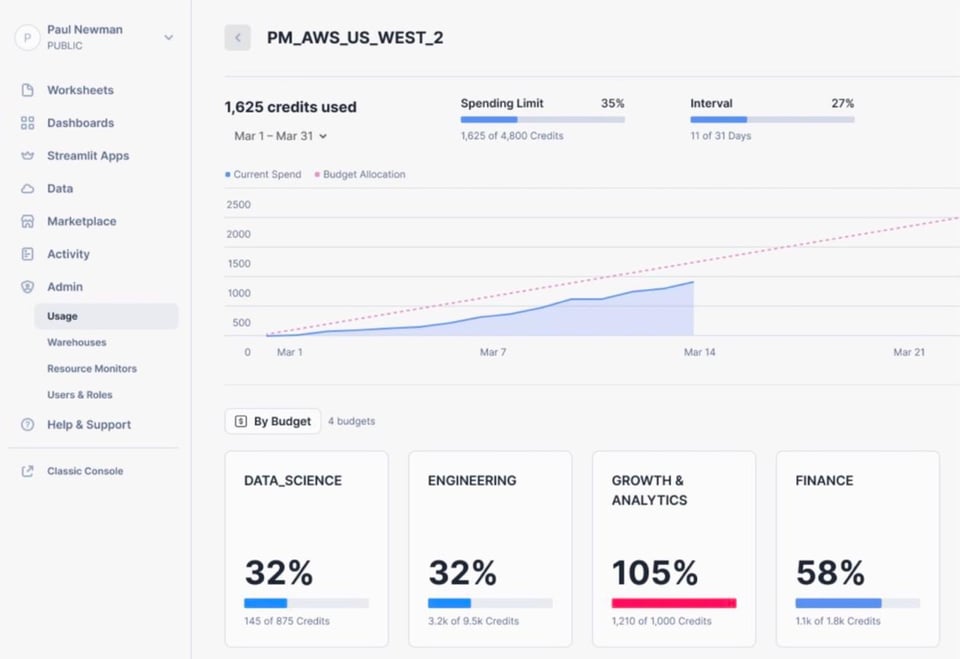
Budgets (Public Preview)
Para ayudar a los clientes a controlar mejor su gasto en Snowflake, Snowflake anunció que su funcionalidad de Budgets entrará en Public Preview. Antes de Budgets, los usuarios solo podían configurar resource monitors, que permiten especificar la cantidad de créditos que puede consumir un warehouse o un grupo de warehouses. Budgets va más allá: te permite agrupar más recursos de Snowflake (warehouses, tablas, materialized views, Snowpipes, etc.) y asignarle un límite de créditos (budget) a ese grupo de recursos. Al igual que con los resource monitors, puedes recibir alertas o suspender los recursos subyacentes para evitar más cargos una vez alcanzado el límite de créditos.
Gracias a Sonny por compartir los detalles y la imagen de abajo.
Warehouse Utilization (Private Preview)
Uno de los mayores desafíos para los clientes de Snowflake es saber si sus warehouses están dimensionados correctamente. Para ayudar con esto, Snowflake anunció una nueva métrica de utilización de warehouse en Private Preview. No tenemos más detalles aún, pero nos entusiasma explorarla cuando esté disponible en Public Preview.
Mejoras de rendimiento
Snowflake anunció varias mejoras de rendimiento en su query engine y un nuevo Snowflake Performance Index (SPI) que usarán para medir y dar seguimiento públicamente a las mejoras que están haciendo. Al puro estilo Snowflake, todas estas mejoras se aplican automáticamente y no requieren que los usuarios hagan nada para activarlas.

Aquel del que no se debe hablar
Los Engineers y los profesionales de datos están acostumbrados a trabajar con datos almacenados en bases de datos distintas. Es parte de nuestra realidad desde que se creó la segunda base de datos allá en los 70s, y por eso existe una industria multimillonaria construida alrededor del movimiento de datos ( cof Fivetran).
Esto no es para nada deseable. ¿No sería genial poder usar una sola base de datos para todo? En el Summit 2022, Snowflake anunció Unistore, un nuevo tipo de workload que soporta queries transaccionales y analíticas. Era un esfuerzo increíblemente ambicioso, porque se trata de un problema de ingeniería notoriamente difícil.
Lamentablemente, en el Summit 2023 no hubo mención de Unistore ni de las hybrid tables que lo sostienen por debajo. Suponemos que es porque el equipo de ingeniería sigue afinando los detalles de esta compleja funcionalidad antes de abrirla al Public Preview.
Actualización: varias personas me escribieron para avisarme que sí hubo una charla sobre Unistore en una sesión dedicada, ¡así que disculpas por habérmela perdido! (Dicho esto, mantengo el título tal cual porque ¡es un clickbait excelente! 😉)
Ian Whitestone·Co-fundador y CEO de SELECT
Ian es Co-fundador y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian dedicó 6 años a liderar equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify, Ian lideró los esfuerzos por optimizar su data warehouse y aumentar la observabilidad de costos.