Niall e eu participamos do nosso primeiro Snowflake Data Cloud Summit em 2022 e ficamos impressionados com a energia e o momentum por trás da plataforma. Sabíamos que precisávamos começar a construir em cima desse ecossistema pujante, e foi aí que nasceu o SELECT.
Na semana passada, voltamos a Las Vegas para o nosso segundo summit, e ele não decepcionou. A Snowflake soltou alguns anúncios de peso e apresentou uma porção de novos recursos para uma plateia lotada no Caesar's Palace. Neste post, mergulhamos nas últimas novidades, damos nossa opinião sobre cada uma e falamos sobre a única coisa que ficou de fora.
Native Applications Framework (Public Preview)
Sem dúvida, o maior anúncio do Summit 2022 foi o Native Applications Framework (Native Apps). Neste ano, ele entrou em Public Preview.
Imagine se, toda vez que você quisesse baixar um app no seu iPhone, tivesse que entrar em um site diferente, conhecer a oferta e ainda dar a essa empresa acesso direto ao seu celular. É exatamente assim que toda empresa que usa o Snowflake trabalha com fornecedores hoje.

A proposta do Native Apps é trazer para o Snowflake Data Cloud uma experiência parecida com a da App Store do iPhone. Em vez de os clientes do Snowflake deixarem fornecedores se conectarem ao seu data warehouse e extrair os dados para devolvê-los em uma aplicação separada (exatamente como fazemos no SELECT), o Native Apps vai permitir que os fornecedores rodem suas aplicações direto dentro da conta Snowflake do cliente. Isso traz vários benefícios:
- Mais segurança. Os dados nunca saem do seu warehouse, e ninguém de fora da sua empresa tem acesso a eles. Você também não precisa gerenciar logins ou acessos separados para a aplicação de terceiros. O Native Apps vai aproveitar a mesma autenticação e o mesmo conjunto de permissões do restante da sua conta Snowflake.
- Procurement jurídico mais simples. A maior parte das relações com fornecedores envolve um novo contrato que precisa ser revisado pelo time jurídico interno. Com o Native Apps, o jurídico só precisa revisar os termos do marketplace do Snowflake uma vez, e não a cada app instalado.
- Sua fatura fica muito mais simples, já que tudo é cobrado pelo Snowflake. A Snowflake até anunciou a possibilidade de os clientes pagarem por apps usando a capacidade do contrato existente, um recurso chamado capacity drawdown.
No SELECT, estamos muito animados com a promessa do Native Apps, porque ele vai nos permitir ajudar ainda mais clientes Snowflake a maximizar o ROI da plataforma e a destravar insights valiosos, simplificando o onboarding e o procurement. Também vai facilitar o compartilhamento de todos os datasets exclusivos de custo e performance que criamos.
Snowpark Container Services (Private Preview)
O Snowpark Container Services (SCS) roubou a cena no Summit 2023. Já perto do fim do keynote, Christian Kleinerman conduziu a plateia por 10 demos ao vivo de aplicações com diferentes casos de uso rodando nativamente no Snowflake via SCS.

O Snowpark Container Services vai permitir que você realmente rode qualquer workload ou aplicação dentro do Snowflake. Como isso vai funcionar? Com Docker. Ao permitir que os usuários implantem um container Docker direto no Snowflake via SCS, eles deixam de ficar limitados aos runtimes e ambientes de linguagem suportados pelo Snowflake.
O Snowpark Container Services vai suportar uma variedade de workloads diferentes. Modelos complexos de IA podem ser treinados e implantados no SCS, aproveitando as novas instâncias com GPU. Um job agendado ou uma service function pode ser executado em um container Snowpark. Ou um serviço de longa duração, como uma aplicação web, pode ser hospedado direto no SCS e rodar no Snowflake 24/7. A Hex mostrou sua interface elegante de notebooks (uma aplicação web complexa em React) rodando diretamente em um container Snowpark.
Um serviço rodando 24/7 no Snowflake pode parecer caro, mas pode ficar tranquilo: a empresa vai anunciar novos tipos de instâncias de compute para o SCS para tornar esses serviços viáveis em custo.
Managed Iceberg Tables (Private Preview)
Por que Iceberg?
Muitas empresas já têm boa parte dos seus dados armazenada em cloud storage, mas não carregada no Snowflake. Não seria ótimo poder usar o Snowflake tanto para consultar quanto para atualizar esses datasets?
O Apache Iceberg é um formato aberto de tabela projetado para datasets analíticos. Esse formato funciona como uma camada de abstração sobre os arquivos físicos de dados (pense em arquivos Parquet) e suporta transações ACID (atomicidade, consistência, isolamento, durabilidade), evolução de schema, particionamento oculto, snapshots de tabelas, entre outros recursos. Os query engines precisam saber quais arquivos formam uma determinada "tabela", e o Iceberg fornece exatamente isso.
O suporte atual da Snowflake ao Iceberg
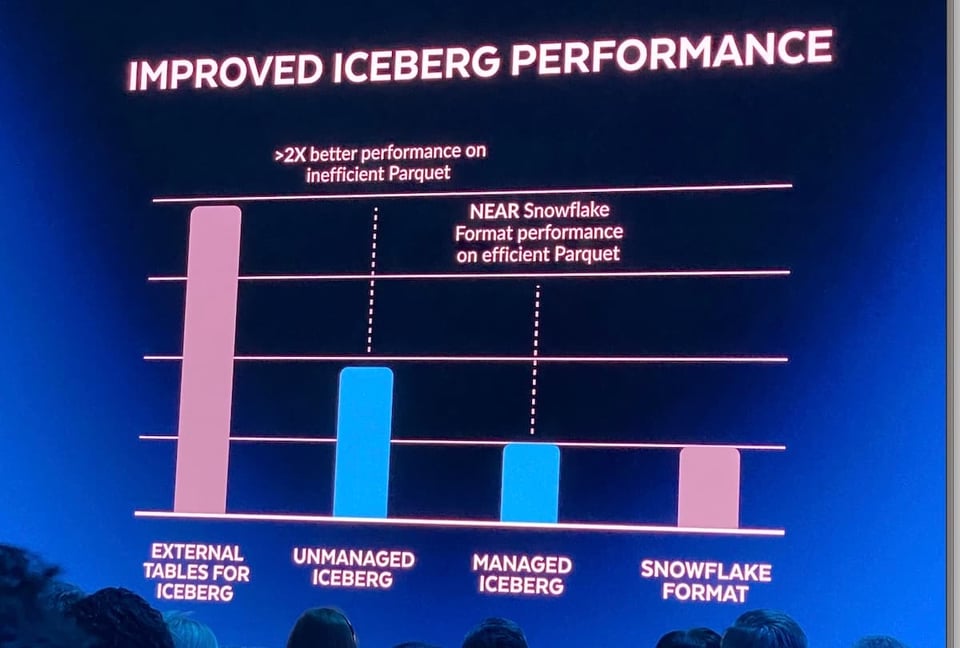
Até o ano passado, a única opção da Snowflake para consultar arquivos em data lake eram as external tables somente leitura. Consultar essas tabelas costumava ter desempenho pior do que o de tabelas armazenadas diretamente no Snowflake, por uma série de fatores. No Summit 2022, a Snowflake anunciou suporte a Iceberg Tables, ou seja, os clientes passaram a poder gerenciar o catálogo do data lake com Iceberg e obter uma performance muito melhor com o query engine do Snowflake graças aos metadados que o Iceberg fornece. Além disso, o suporte ao Iceberg permite que os clientes tratem suas tabelas externas (Iceberg) como tabelas Snowflake comuns, com updates, deletes e inserts.
O anúncio do Iceberg no Summit 2023
Um desafio que ainda existia ao usar Iceberg é precisar de um sistema capaz de gravar e atualizar continuamente os metadados Iceberg em um catálogo separado. Para ajudar a resolver isso, a Snowflake anunciou as "managed iceberg tables" no Summit 2023. Agora os usuários podem aproveitar os recursos de compute do Snowflake para gerenciar os dados Iceberg. Além de tirar esse trabalho das suas costas, os usuários também devem perceber melhorias de performance.
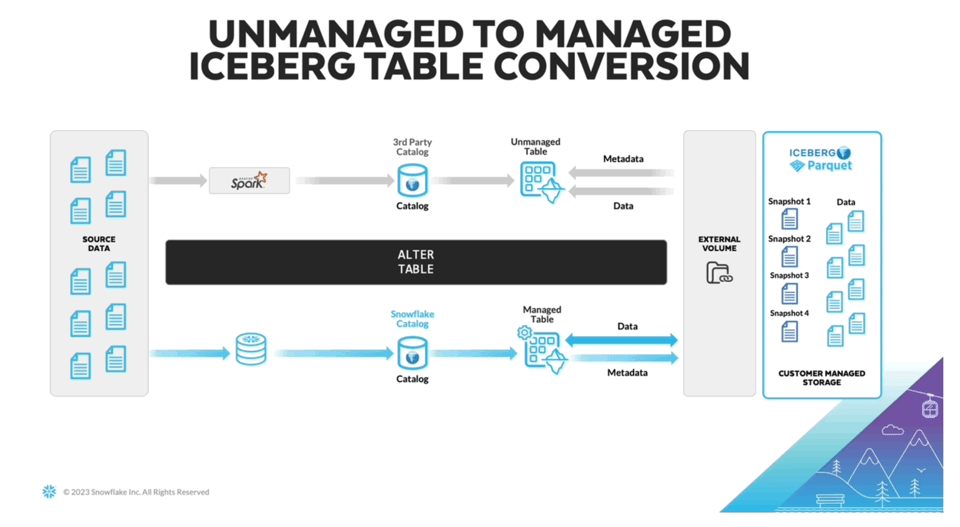
Pela ausência de documentação do produto, acredito que esse recurso esteja atualmente em private preview. A imagem acima veio do James Malone no LinkedIn. Para quem está começando com Iceberg, achei este post uma ótima introdução.
Dynamic Tables (Public Preview)
Um dos maiores geradores de custo de transformação de dados que vemos nos clientes do Snowflake, incluindo a nossa própria conta, é a reconstrução completa das tabelas a cada execução do pipeline. As tabelas são construídas assim porque é mais rápido e mais fácil. Construir uma tabela de forma incremental tem mais nuances, já que é preciso considerar fatores como dados que chegam atrasados, qual high watermark usar ao filtrar cada dataset, entre outros. Pipelines de dados também podem gerar custos desnecessários por causa de jobs rodando em uma agenda fixa, sem levar em conta quando os novos dados upstream são populados.
A Snowflake já suporta há tempos as Materialized Views (MVs), que ajudam com alguns desses desafios atualizando a tabela apenas quando novos dados chegam upstream. Mas elas têm várias armadilhas; uma das principais é que a definição da view em SQL não suporta diversas operações comuns, como joins, unions, agregações, group bys ou window functions.
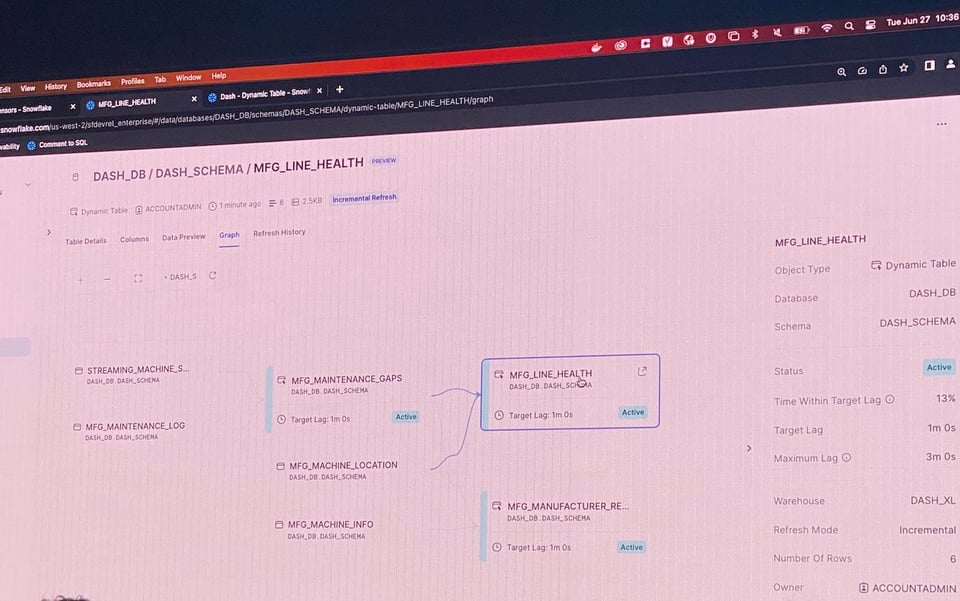
No Summit deste ano, a Snowflake anunciou que as Dynamic Tables (DTs) agora estão em Public Preview. As DTs são parecidas com as MVs no sentido de que você define a tabela com uma expressão SQL e o Snowflake cuida de materializar essa expressão sempre que houver novos dados upstream. As DTs trazem uma série de outras vantagens:

- Têm um suporte a SQL muito mais amplo, incluindo joins, unions, agregações, window functions e muito mais.
- Processam novos dados de forma incremental, ou seja, não desperdiçam recursos recomputando os mesmos dados várias vezes.
- As MVs ficavam bem caras quando a tabela upstream era atualizada com frequência. Com as DTs, o Snowflake atualiza com base em um parâmetro de latência definido por você. Isso dá ao usuário mais controle sobre a frequência das atualizações e, consequentemente, sobre os custos de compute associados.
- Têm suporte de primeira classe na UI. Os usuários conseguem visualizar facilmente as DTs e suas dependências, além de ver o histórico de execuções na aba
Refresh History.
Snowpipe Streaming API (Public Preview)
A Snowflake anunciou que a Snowpipe Streaming API agora está em Public Preview. O Snowpipe Streaming permite que os clientes carreguem dados no Snowflake direto do Apache Kafka ou de uma aplicação Java customizada. Ele ajuda a suportar workloads que precisam de dados com menor latência.
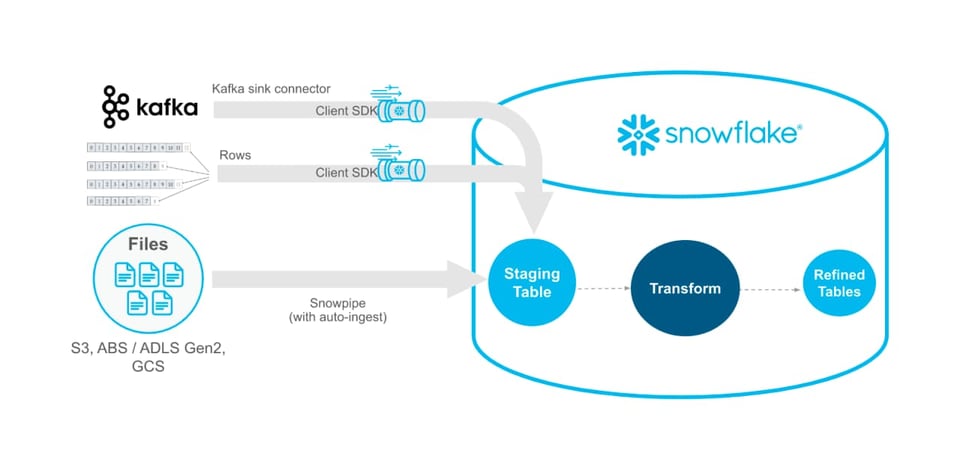
O Snowpipe Streaming também é a forma mais econômica de carregar dados, depois que você tem a infraestrutura necessária no lugar. Estratégias alternativas de data loading, como o Snowpipe ou comandos manuais COPY INTO rodando em um warehouse autogerenciado, envolvem carregar um arquivo de um stage para o Snowflake. Ao evitar essa etapa cara de leitura e o overhead de gestão de arquivos, o Snowpipe Streaming acaba sendo uma opção mais eficiente em custo.
Uma série de anúncios sobre IA
Com toda a conversa em torno de IA generativa e LLMs, não foi surpresa a Snowflake anunciar uma enxurrada de novos recursos de IA.
Parceria com a Nvidia
No primeiro dia da conferência, a Snowflake anunciou uma nova parceria com a Nvidia. A Snowflake vai se unir à Nvidia para integrar o NeMo, framework de LLM da Nvidia, ao Snowflake. Isso vai ajudar engenheiros a construir large language models direto dentro do Snowflake, usando os dados que já têm armazenados lá.
Snowflake Copilot (a definir)
A Snowflake mostrou um recurso muito legal de "comentário para SQL", parecido com o Github Copilot. Imagine poder escrever um comentário como -- mostre a contagem de usuários ativos diários nos últimos 30 dias e ter o Snowflake gerando automaticamente a query usando o conhecimento (a) dos seus dados e (b) do dialeto SQL específico do Snowflake. A Snowflake está sentada sobre o maior dataset de treinamento de queries possível, então espero que esse modelo seja melhor do que qualquer coisa pronta oferecida por outras empresas.
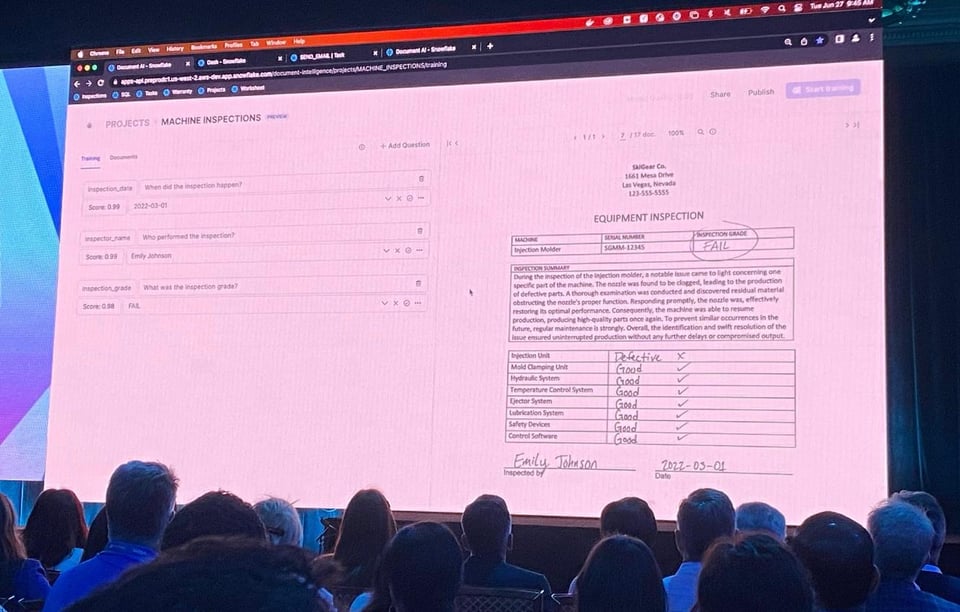
Document AI (Private Preview)
Em abril de 2022, a Snowflake adquiriu uma empresa chamada Applica, especializada em analisar dados não estruturados. No Summit 2023, a Snowflake anunciou um novo recurso chamado Document AI, que aproveita a tecnologia da Applica. Esse é o LLM proprietário da Snowflake e permite que você faça perguntas sobre documentos armazenados no Snowflake.
A Snowflake mostrou uma demo bem bacana em que as informações eram extraídas automaticamente dos documentos, e os usuários podiam dar feedback sobre o que foi recuperado para melhorar a acurácia do modelo. Em seguida, dava para implantar facilmente o modelo treinado e executá-lo como uma UDF em uma query SQL.
Diversas novidades para desenvolvedores
O time de product management da Snowflake anunciou uma série de novidades variadas para desenvolvedores. Vamos compartilhar mais detalhes à medida que tivermos acesso:
- Uma nova CLI do Snowflake e uma REST API em Python (para complementar o já existente Snowflake Connector for Python)
- O Snowpark Model Registry, que permite que cientistas de dados armazenem, publiquem, descubram e sirvam modelos de ML no Snowflake.
- Diversas melhorias no Snowpark, incluindo controle mais granular sobre pacotes Python, suporte a Python 3.9 e 3.10, acesso a rede externa e UDTFs Python vetorizadas.
- Três funções nativas baseadas em machine learning que vão ajudar os usuários com forecasting, detecção de anomalias e contribution explorer.
- Novas APIs de logging e tracing, além de sincronização automática entre git e stages do Snowflake para apoiar desenvolvedores que constroem no Native Apps Framework.
- O Streamlit, aparentemente, está "muito perto" do public preview. Foram apresentados novos componentes do Streamlit para construir experiências de chat.
Otimização e controle de custos
Ao contrário do que muita gente pensa, a Snowflake se importa profundamente em garantir que seus clientes usem a plataforma de forma eficaz. A Snowflake sabe que precisa jogar o jogo longo e ajudar os clientes a tirar o máximo de valor de cada dólar investido na plataforma.
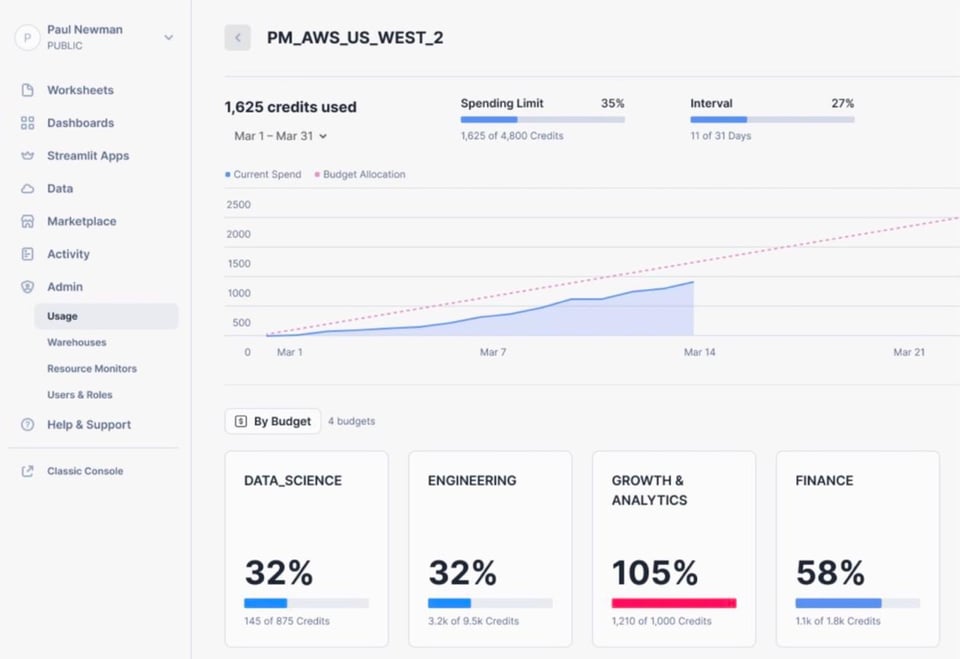
Budgets (Public Preview)
Para ajudar os clientes a controlar melhor seus gastos com Snowflake, a empresa anunciou que o recurso Budgets vai entrar em Public Preview. Antes do Budgets, os usuários só conseguiam configurar resource monitors, que permitem definir a quantidade de créditos que um warehouse ou grupo de warehouses pode consumir. Os Budgets vão além: dá para agrupar mais recursos do Snowflake (warehouses, tabelas, materialized views, Snowpipes etc.) e atribuir um limite de créditos (budget) a esse grupo de recursos. Assim como nos resource monitors, é possível receber alertas ou suspender os recursos subjacentes para evitar cobranças adicionais assim que o limite de créditos for atingido.
Agradecimentos ao Sonny por compartilhar os detalhes e a imagem abaixo.
Warehouse Utilization (Private Preview)
Um dos maiores desafios dos clientes Snowflake é saber se seus warehouses estão dimensionados corretamente. Para ajudar nisso, a Snowflake anunciou uma nova métrica de utilização de warehouse em Private Preview. Não temos mais detalhes sobre essa novidade, mas estamos animados para explorá-la assim que estiver disponível em Public Preview.
Melhorias de performance
A Snowflake anunciou diversas melhorias de performance no seu query engine e um novo Snowflake Performance Index (SPI) que vai ser usado para medir e acompanhar publicamente os ganhos. No melhor estilo Snowflake, todas essas melhorias são aplicadas automaticamente e não exigem nenhuma ação dos usuários para serem ativadas.

Aquele que não deve ser nomeado
Engenheiros e profissionais de dados estão acostumados a trabalhar com dados armazenados em bancos de dados diferentes. Essa é a nossa realidade desde que o segundo banco de dados foi criado, lá nos anos 70, e é justamente por isso que existe uma indústria de bilhões de dólares construída em torno da movimentação de dados (cof cof Fivetran).
De forma alguma isso é desejável. Não seria ótimo poder usar um único banco de dados para tudo? No Summit 2022, a Snowflake anunciou o Unistore, um novo tipo de workload que suporta consultas no estilo transacional e analítico. Foi uma empreitada incrivelmente ambiciosa, já que esse é um problema de engenharia notoriamente difícil.
Infelizmente, não houve nenhuma menção ao Unistore nem às hybrid tables que o sustentam por baixo dos panos no Summit 2023. Presumimos que isso aconteceu porque o time de engenharia ainda está acertando os últimos detalhes desse recurso complexo antes de liberá-lo para o Public Preview.
Atualização: várias pessoas entraram em contato e me avisaram que houve sim uma palestra sobre o Unistore em uma sessão dedicada, então desculpem por ter deixado isso passar! (Mesmo assim, vou manter o título como está, porque é um ótimo clickbait! 😉)
Ian Whitestone·Cofundador e CEO do SELECT
Ian é cofundador e CEO do SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar o SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.