2022 sorgte Snowflake mit dem neuen Native Application Framework und Hybrid Tables (zunächst als Unistore angekündigt) für die ganz großen Schlagzeilen. Im vergangenen Jahr legte das Team mit weiteren Features wie Snowpark Container Services und der Iceberg-Unterstützung nach.
Da Niall und ich schon bei den letzten beiden Summits dabei waren, beeindruckt uns das Entwicklungstempo bei Snowflake immer wieder aufs Neue. Nach dem Summit 2024 hat sich daran nichts geändert.
Legen wir los.

Zusammenfassung der Ankündigungen
Wenn die Zeit knapp ist, finden Sie hier eine vollständige Übersicht aller Ankündigungen mit kurzer Erläuterung.
Data Engineering
- Snowflake stellt Polaris Catalog innerhalb von 90 Tagen als Open Source bereit. Kunden können damit ihre Iceberg-Kataloge selbst hosten und gewinnen mehr Interoperabilität zwischen verschiedenen Compute-Engines.
- Serverless Tasks Flex spart bis zu 42 %, indem der Ausführungszeitpunkt der Tasks flexibler gewählt werden kann (Private Preview).
- Event-driven Tasks sind jetzt in Public Preview. Damit lässt sich ein Task-Run automatisch auslösen, sobald ein Snowflake Stream aktualisiert wird.
- Low Latency Tasks (Private Preview) ermöglichen kürzere Task-Scheduling-Intervalle – bis hinunter zu 15 Sekunden.
- Iceberg Tables, ein Open-Source-Tabellenformat, mit dem Kunden ihre Daten als Parquet-Dateien im Cloud-Storage ablegen und gleichzeitig aus Snowflake heraus abfragen können, sind jetzt in General Availability (GA).
- Dynamic Tables sind jetzt in GA und bieten einen deklarativen Ansatz für inkrementelle Transformationen und einfache Datenpipelines auf Basis von SQL-SELECT-Statements.
- Data Quality Monitoring: Snowflake liefert nun standardmäßig System-Metriken (z. B. Null-Counts) sowie benutzerdefinierte Metriken, die Kunden selbst festlegen und automatisch auf Tabellen anwenden können. Das Feature ist in Public Preview und nur in den Enterprise- und höheren Editions von Snowflake verfügbar.
- Native Connectors für Postgres und MySQL gehen demnächst in Public Preview. Damit lassen sich CDC-Daten aus internen Unternehmensdatenbanken mit sehr geringer Latenz nach Snowflake replizieren – und vor allem ohne Drittanbieter (wie Fivetran), der pro geladener Zeile abkassiert.
Analyst- & Developer-Tooling
- Snowflake Notebooks sind jetzt in Public Preview und bieten eine durchgängige, interaktive UI-Umgebung für Daten- und KI-Teams.
- Mit Snowflake Trail stellte Snowflake eine neue Suite an Observability-Features vor, mit der Engineers und Partner ihre Datenpipelines besser überwachen und debuggen können.
- Snowpark Container Services (SPCS) sind jetzt in GA. Damit lassen sich beliebige workloads sicher per Container in Snowflake ausführen.
- Im Zuge dessen kündigte Snowflake auch die Public-Preview-Unterstützung von SPCS für das Native Apps Framework an – Partner können damit umfangreiche Anwendungen entwickeln und ausrollen.
- Snowflakes eigener Copilot geht demnächst in GA. Analysten und Business-Anwender können damit direkt im Snowflake-UI per Texteingabe automatisch SQL-Queries generieren lassen.
- Snowflakes Git-Integration ist jetzt in Public Preview und ermöglicht das Synchronisieren von Dateien zwischen GitHub/GitLab/Bitbucket und Snowflake – für bessere Versionskontrolle und Verwaltung.
Data Governance & Security
- Ein neuer interner Marketplace in Private Preview, über den große Organisationen und Teams Datasets, Apps und Notebooks unternehmensintern privat teilen können.
- Neue Table Governance Views in Public Preview zeigen die wichtigsten Rollen und User, die auf eine Tabelle in Ihrem Snowflake-Konto zugreifen.
- Snowflakes Trust Center, eine UI zum Aufspüren von Sicherheitsrisiken inklusive Lösungsempfehlungen, geht bald in GA.
- Universal Search ist jetzt in GA: Nutzer können sämtliche Snowflake-Assets direkt im UI schnell finden und durchsuchen.
- Snowflake zeigte ein neues Interface zur Visualisierung von Data Lineage im UI (Private Preview), mit dem sich Upstream- und Downstream-Abhängigkeiten für alle Tabellen und Views einsehen lassen.
- AI-Powered Object Descriptions wurden angekündigt: Sie ergänzen Tabellen und Views per KI automatisch um relevanten Kontext und Kommentare.
Enterprise AI & ML
- Snowflake hat eine neue Snowpark pandas API veröffentlicht. Python-Nutzer können damit ihren pandas-Code parallelisiert auf Snowflake-Compute ausführen – ohne die typischen pandas-Limitierungen bei Datenvolumen und Performance.
- Document AI geht bald in GA. Document AI bietet serverlose, LLM-basierte Dokumentenverarbeitung zur Extraktion strukturierter Daten aus unstrukturierten Geschäftsdokumenten (PDFs, Bilder, Word-Dateien etc., etwa Rechnungen, Verträge oder Produkt-Datenblätter). Mehr dazu hier.
- Snowflake Feature Store (Public Preview) erlaubt es, ML-Features zu erstellen, zu verwalten und bereitzustellen – mit kontinuierlicher, automatisierter Aktualisierung auf Batch- oder Streaming-Daten via UI oder Snowpark ML APIs. Mehr dazu hier.
- Snowflake Model Registry ist jetzt in GA und bietet eine integrierte Lösung, um KI-/ML-Modelle und ihre Metadaten nativ in Snowflake zu verwalten, zu tracken, zu versionieren und zu teilen – via UI oder Snowpark ML APIs. Mehr dazu hier.
- Snowsight AI & ML Studio ist jetzt in GA und bietet eine UI, mit der sich verschiedenste ML- und KI-Modelle und -Pipelines einfach erstellen lassen.
- Cortex Finetuning ist jetzt in Public Preview. Damit lassen sich Foundational-LLM-Modelle direkt aus dem UI heraus trainieren.
- Cortex Analyst (Private Preview) ist ein serverloser und hochpräziser LLM-Service, mit dem Business-Anwender eine Frage stellen und eine echte Antwort erhalten – nicht nur SQL-Code. Analyst basiert auf einer YAML-Datei, in der Datenschema, Metriken und Synonyme definiert werden, um Umfang und Genauigkeit zu steuern.
- Cortex Search (Private Preview) ist ein serverloser, LLM-basierter hybrider Suchservice (Vector + Keywords). Er extrahiert inkrementell Daten aus Dokumenten, Tabellen und Views, zerlegt sie automatisch in Chunks und vektorisiert sie – für schnelle Abfragen (< 200 ms) und hohe Trefferqualität.
Ganz schön viel auf einmal! Im weiteren Verlauf gehe ich auf die strategische Richtung von Snowflake ein und vertiefe einige der größeren Ankündigungen samt ihrer Auswirkungen.
Eröffnungsworte & Snowflakes Philosophie
Zum Auftakt der Summit-Keynote bekräftigten Sridhar und Benoit die Kernprinzipien der Snowflake-Plattform. Sie betonten, dass Snowflake eine einzige Plattform auf Basis einer einzigen Engine ist – und einfach funktioniert. Snowflake hält die Dinge schlank und bietet eben nicht 20 Wege, dasselbe zu erledigen. Wie wichtig dieser Punkt ist, wurde mir erst eine Woche später beim Databricks Summit klar, als ich sah, wie komplex deren Produkt ausfällt.
Da sich Snowflake kürzlich von der "Data Cloud" zur "AI Data Cloud" umbenannt hat, drehten sich die Eröffnungsworte weitgehend darum, wie die Plattform alles für Enterprise-KI bereitstellt:
- Daten. Snowflake bietet hochperformanten nativen Storage und unterstützt das offene Iceberg-Format für Kunden, die die volle Kontrolle über ihre Daten behalten und sie auch anderen Compute-Engines (z. B. Spark oder Trino) zugänglich machen wollen.
- Compute. Snowflakes Virtual Warehouses kennt jeder – sie kommen vor allem für SQL-Queries zum Einsatz. Intern bezeichnet Snowflake diese Technologie als "Data Flow Engine". Alle Sprachen (Java, Python, Scala) werden auf diese Engine heruntergebrochen, nicht nur SQL. Mit Snowpark Container Services kommt nun eine noch flexiblere Compute-Option dazu: Nutzer können beliebige Anwendungen oder workloads in einem sicheren Container ausführen (Motto: Was in Docker läuft, läuft auch in Snowflake).
- KI – das große Thema des Tages. Mit Cortex haben Snowflake-Kunden Zugriff auf eine ganze Suite an Tools, um KI-Anwendungen unkompliziert zu nutzen und zu bauen. Vorgestellt wurde außerdem Arctic, eine neue LLM-Familie von Snowflake, die gezielt auf Enterprise-Use-Cases zugeschnitten ist.
- Security, Governance und Collaboration. Snowflake ist seit Langem bekannt für starke Sicherheitsgarantien, einfache Governance und ein robustes Access-Control-Modell. Auch wenn der typische Nutzer wenig darüber nachdenkt – für jedes Unternehmen sind diese Features Pflicht.
Polaris Catalog und mehr Interoperabilität in der Branche
Eine der meistdiskutierten Ankündigungen kam bereits Tage vor dem Summit, als Snowflake bekanntgab, ihren Iceberg-Katalog Polaris als Open Source freizugeben. Das ist deshalb so bedeutsam, weil es Nutzbarkeit und Interoperabilität von Iceberg Data Lakes über Cloud-Plattformen hinweg erheblich verbessert.

Ein weiterer Grund für die breite Resonanz: Databricks gab zeitgleich die Übernahme von Tabular bekannt – jenem Unternehmen, das von den Erfindern und wichtigsten Köpfen hinter Iceberg gegründet wurde.
Das bedeutet klar, dass Databricks erstklassige Iceberg-Unterstützung in sein Produkt integrieren wird. Ich rechne damit, dass Snowflake irgendwann nachzieht und Delta Lake unterstützt. Auch wenn ein leicht mulmiges Gefühl bleibt, dass ein einzelnes Unternehmen die beiden populärsten Open-Source-Datenformate faktisch "besitzt", werden die Kunden am Ende deutlich profitieren – denn alle Cloud-Datenplattformen werden gezwungen sein, mehr offene Formate zu unterstützen.
Im Zuge dessen kündigte Snowflake auch eine deutliche Erweiterung der Partnerschaft mit Microsoft Fabric an. Im Kern von Fabric steht OneLake, das bislang auf Delta-Lake-Parquet-Dateien aufsetzte. Künftig wird Microsoft Iceberg unterstützen und Snowflake sich mit OneLake integrieren.
Wer sich fragt, warum es für Iceberg überhaupt einen separaten Katalog braucht – dieser Auszug aus der Iceberg-Dokumentation hilft weiter:
Man kann sich Iceberg als ein Format zur Verwaltung von Daten innerhalb einer einzelnen Tabelle vorstellen. Die Iceberg-Bibliothek braucht jedoch eine Möglichkeit, diese Tabellen über ihren Namen anzusprechen. Aufgaben wie das Anlegen, Löschen und Umbenennen von Tabellen liegen in der Verantwortung eines Katalogs. Kataloge verwalten eine Sammlung von Tabellen, die üblicherweise in Namespaces gruppiert sind. Die wichtigste Aufgabe eines Katalogs besteht darin, die aktuellen Metadaten einer Tabelle nachzuhalten; diese werden vom Katalog bereitgestellt, sobald man eine Tabelle lädt.
Das Iceberg-Projekt selbst stellte keinen Katalog bereit, sondern definierte lediglich die Standards, was Kataloge leisten sollen und wie sie mit Iceberg interagieren. Ganz typisch für Snowflake senkt das Unternehmen nun die Einstiegshürde für komplexe Technologien wie Iceberg drastisch, indem es die fehlenden Puzzleteile liefert.
Serverless Tasks Flex in Private Preview
Für alle, die sich für Snowflake-Kostenoptimierung interessieren, hat Snowflake ein spannendes neues Feature angekündigt: Serverless Tasks Flex.
Bei Serverless Tasks definieren Sie einen Zeitplan, und Snowflake führt Ihre Query automatisch auf von Snowflake verwalteten Compute-Ressourcen aus. Abgerechnet wird sekundengenau nur die tatsächlich genutzte Compute-Zeit.
Bei Serverless Tasks Flex geben Sie sowohl einen Zeitplan als auch ein SLA an, das die maximale Laufzeit Ihres Tasks definiert (also bis wann er – relativ zur geplanten Startzeit – fertig sein muss). Snowflake nimmt diese beiden Vorgaben und findet den günstigsten Ausführungszeitpunkt, ohne das festgelegte SLA (z. B. 3 Stunden) zu reißen.

Snowpark Container Services in Native Apps jetzt in Public Preview
Snowflake kündigte an, dass Entwickler von Native Apps nun Snowpark Container Services in ihren Anwendungen nutzen können. Damit lassen sich anspruchsvollere UIs (z. B. eigenes React/JavaScript) und komplexe Anwendungen vollständig in Snowflake bauen und betreiben.
Für Snowflake-Partner war das eine riesige Ankündigung: Unternehmen wie SELECT können ihre Produkte damit noch sicherer und nahtloser bereitstellen.

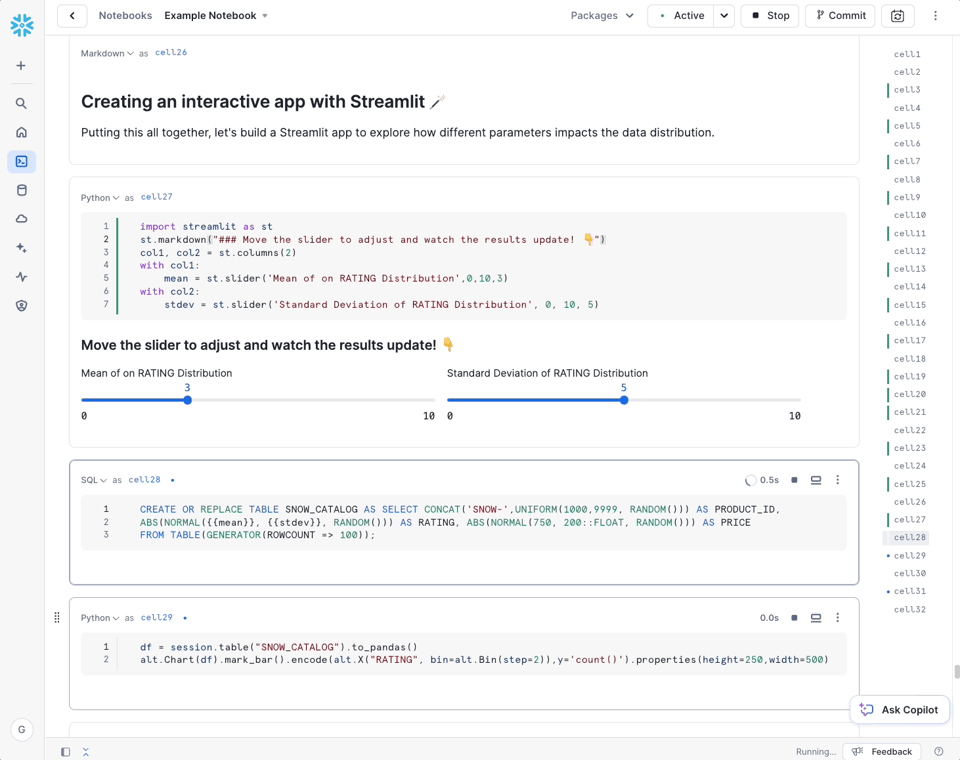
Snowflake Notebooks in Public Preview
Snowflake hat bestätigt, dass das Notebooks-Feature jetzt in Public Preview ist. Notebooks erlauben es, Python, SQL und Markdown zu kombinieren – für Reports, Jobs oder Ad-hoc-Analysen.
Notebooks lassen sich außerdem zeitgesteuert auf einem Virtual Warehouse oder einem Snowpark Container ausführen. Zusätzlich kündigte Snowflake einen Inline-Copilot für Notebooks an (aktuell in Public Preview).
Ankündigungen rund um Snowflake Horizon
Snowflake Horizon ist Snowflakes Feature-Suite rund um Data Governance, Discoverability, Security und Privacy. Zu Horizon gab es eine ganze Reihe an Ankündigungen:
- Universal Search
- Table Governance Views
- AI-Powered Object Descriptions
- Data Lineage Visualization für Tabellen & Views
- ML Lineage Visualization
- Trust Center
- Internal Marketplace
Auf einige davon, die für die meisten Snowflake-Nutzer besonders relevant sein dürften, gehe ich näher ein.
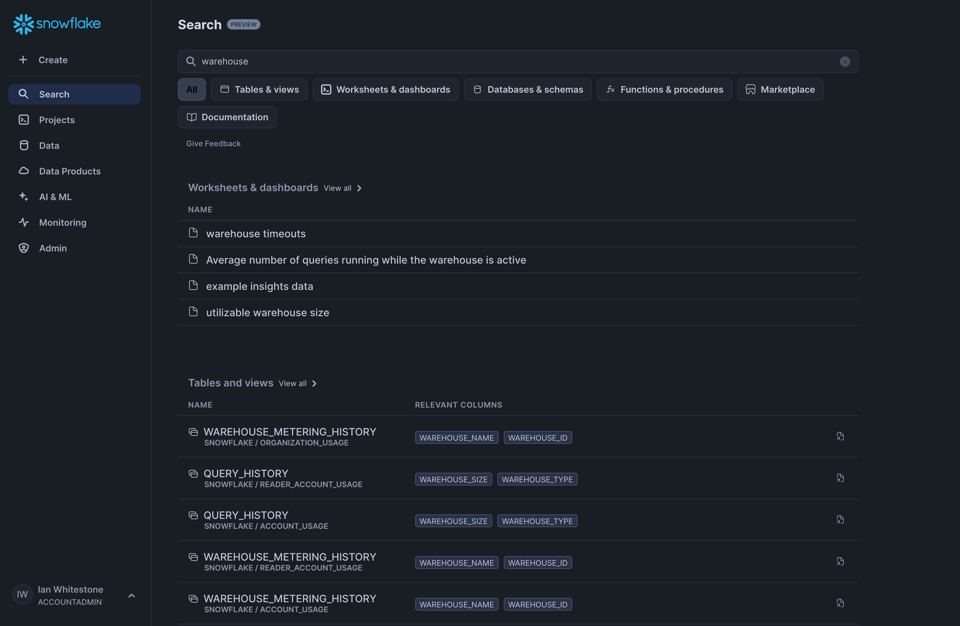
Universal Search ist jetzt Generally Available
Über die Search-Funktion im UI lässt sich alles in Snowflake durchsuchen – von internen Daten bis zum Marketplace. Search basiert auf der Search-Engine-Technologie von Neeva, die Snowflake 2023 übernommen hat.
Hier ein Beispiel aus unserem Snowflake-Konto:
Tab "Table Governance" in Public Preview
Auf der Tabellen-Seite zeigte Snowflake einen neuen Governance-Tab mit Informationen zu den wichtigsten Queries, Usern und Rollen, die auf eine Tabelle zugreifen. Praktisch, wenn man verstehen möchte, wer eine Tabelle wie nutzt.
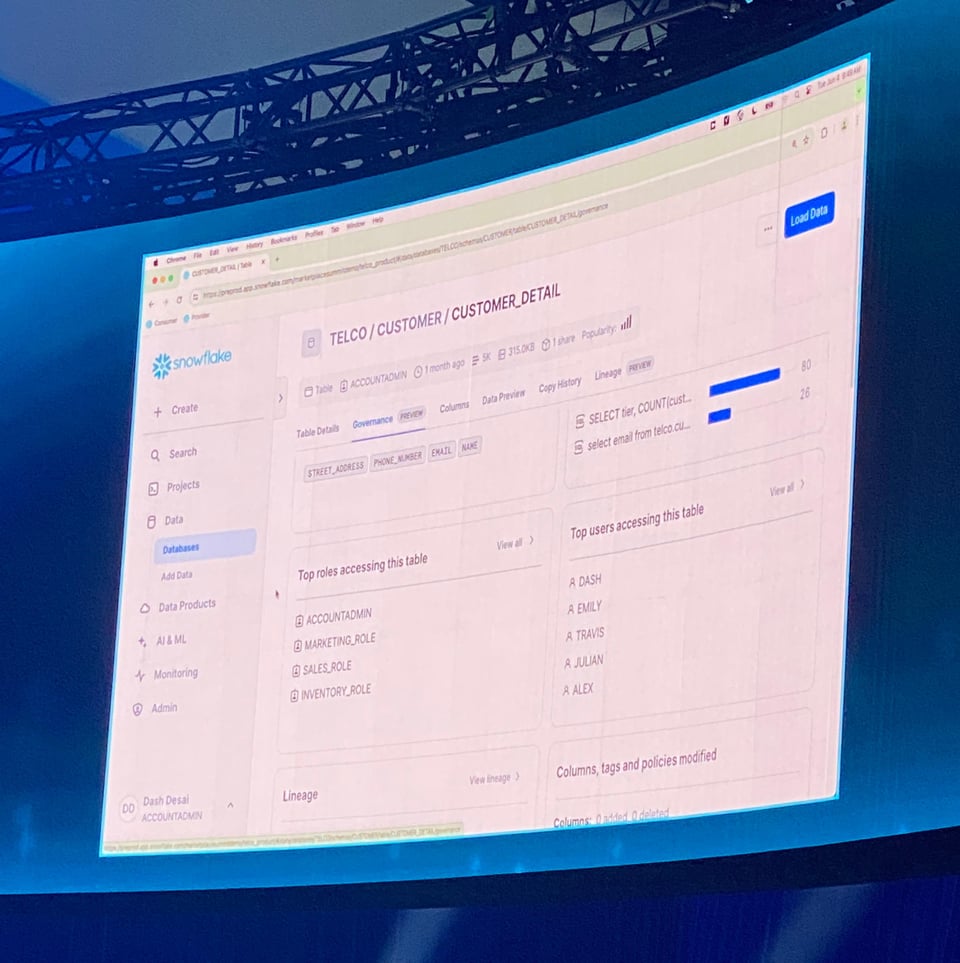
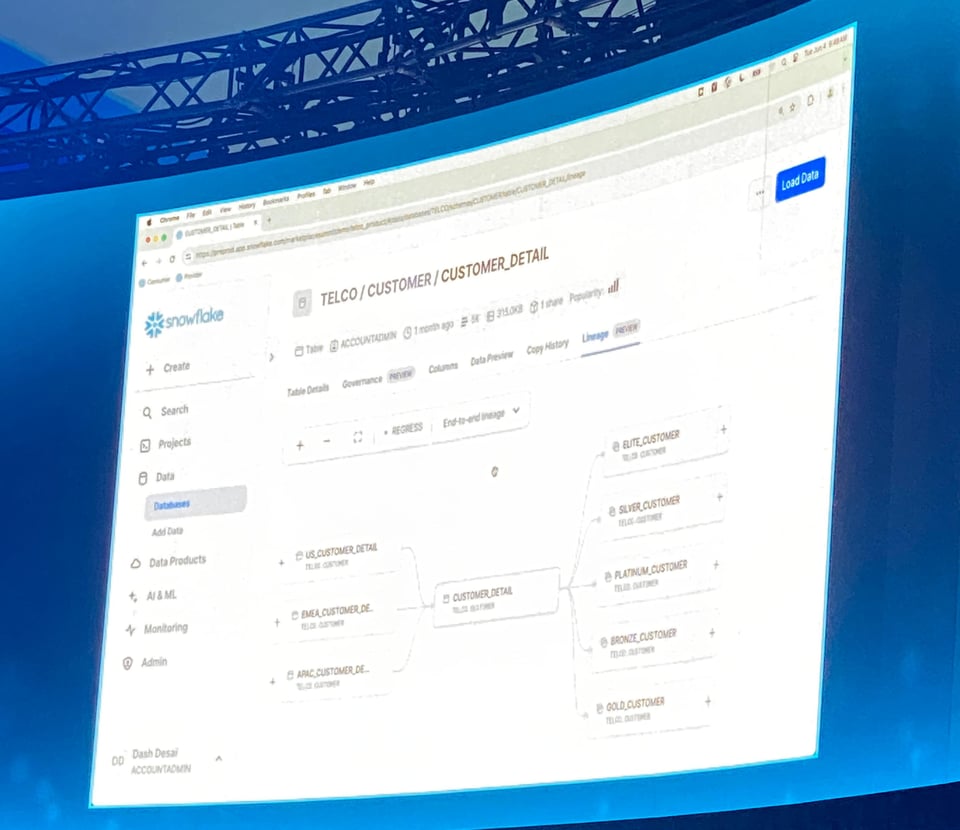
Table Lineage in Private Preview
Snowflake stellte zudem eine neue Table-Lineage-Ansicht auf der Tabellen-Seite vor, die Upstream- und Downstream-Abhängigkeiten für Views und Tabellen zeigt.
Das ist eines der beliebtesten Features in Data-Catalog- und Observability-Tools – umso schöner, dass Snowflake es nun allen Kunden bereitstellt.
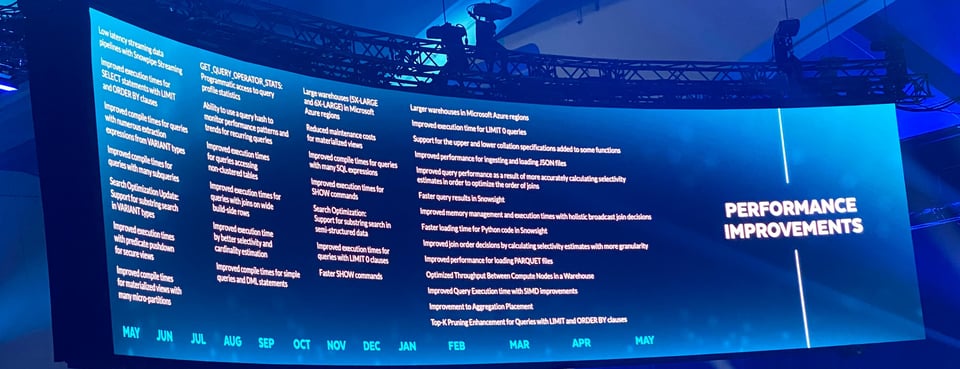
Diverse Performance-Verbesserungen
Für alle, die sich für Query-Optimierung interessieren: Snowflake präsentierte eine ganze Reihe an Performance-Verbesserungen aus den letzten 12 Monaten. All das passiert im Hintergrund und verbessert das Entwickler- und Nutzererlebnis für alle Snowflake-Kunden, ohne dass sie selbst etwas tun müssen.
Native Connectors für Postgres und MySQL
Aufbauend auf dem Erfolg der bisherigen Snowflake-Native-Connectors – Snowflake Connector for Kafka sowie die Connectors für SaaS-Anwendungen wie ServiceNow und Google Analytics – hat Snowflake angekündigt, dass Native Connectors für Postgres und MySQL bald in Public Preview gehen. Damit lassen sich CDC-Daten aus internen Unternehmensdatenbanken mit sehr geringer Latenz nach Snowflake replizieren – und das Wichtigste: ohne pro geladener Zeile an einen Drittanbieter zu zahlen.
Spannend wird, was das für Unternehmen wie Fivetran bedeutet. Ich vermute, dass mehr als die Hälfte ihres Umsatzes aus Postgres- und MySQL-Replikation stammt. Snowflake hat angekündigt, künftig weitere Connectors für andere führende Datenbanken zu bauen – die Umsatzkannibalisierung kann da nur in eine Richtung gehen: nach oben.
Snowflake Trail in Private Preview
Snowflake investiert weiter konsequent in Observability-Features – sowohl für Daten als auch für die Anwendungsentwicklung.
Auf dem diesjährigen Summit wurde Snowflake Trail vorgestellt – eine Sammlung von Snowflake-Funktionen, mit denen Engineers Pipelines, Apps, User-Code und Compute-Auslastung besser überwachen, troubleshooten, debuggen und steuern können.
Snowflake Trail basiert auf Event Tables und verschafft Nutzern automatisch mehr Einblick in die Performance von Snowpark-Code und die Ressourcennutzung.
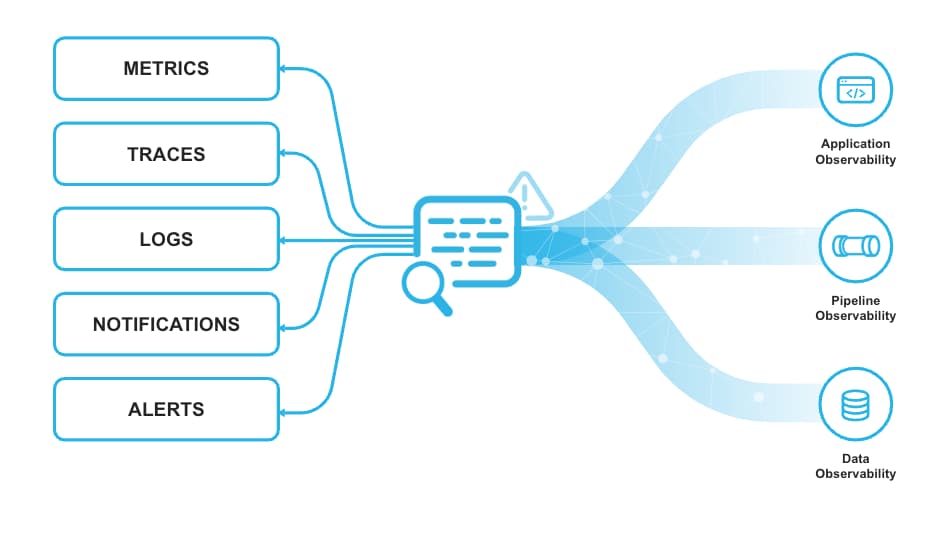
Snowflake Trail ist mit der OpenTelemetry-Spezifikation konform und lässt sich daher problemlos in Partner-Technologien integrieren. Zusätzlich gibt es eine einfache UI auf den Event Tables.
Snowpark pandas API
Ende 2023 hat Snowflake Ponder übernommen, um die Python-Fähigkeiten der Plattform zu stärken.
Aus dieser Übernahme ist die neue Snowpark pandas API hervorgegangen, mit der Python-Nutzer ihren pandas-Code parallelisiert auf Snowflake-Compute ausführen können – ohne die typischen pandas-Limitierungen bei Datenvolumen und Performance.
Nutzer können jetzt ganz normalen pandas-Code schreiben, der unter der Haube automatisch als Snowflake-SQL ausgeführt wird. Das Ergebnis: deutlich bessere Performance und die Möglichkeit, Datasets zu verarbeiten, die größer als der Arbeitsspeicher sind.
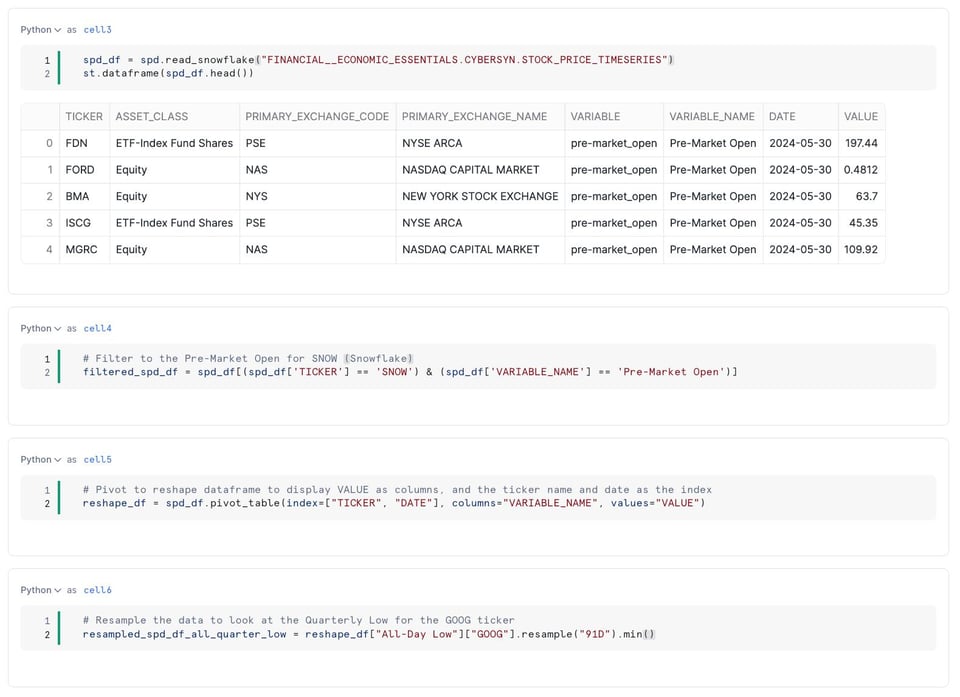
Im Hintergrund wird der pandas-Code in SQL-Queries übersetzt, deren Ergebnisse anschließend als native Python-Objekte zurückgeliefert werden. Wirklich elegant gelöst!
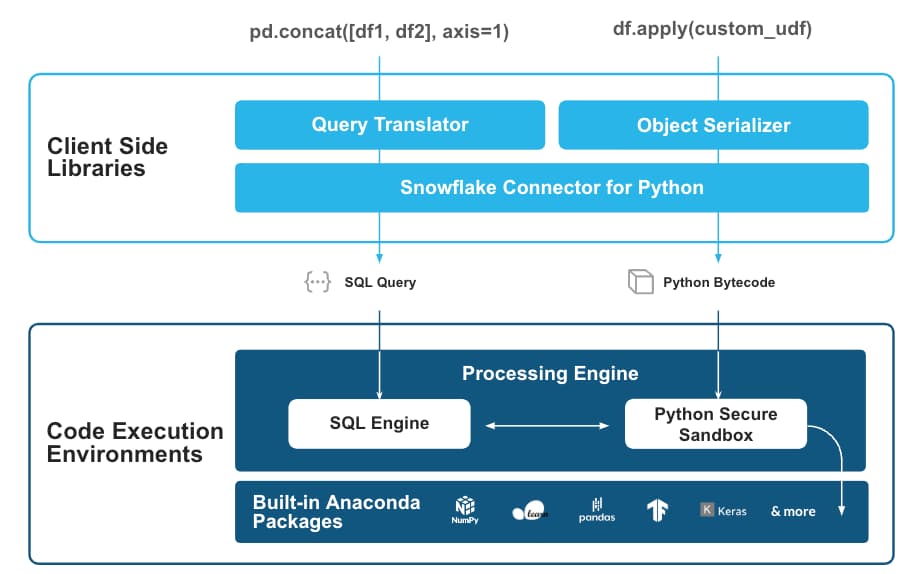
Bilder aus der Snowflake-Ankündigung: https://www.snowflake.com/blog/snowpark-pandas-api-run-at-scale/
Snowflake Cortex
Snowflake Cortex ist Snowflakes Suite an KI-Tools und -Features. Cortex gibt Ihnen Zugriff auf eine Vielzahl unterschiedlicher LLMs – darunter Modelle von Mistral, Reka, Meta, Google und Snowflake Arctic.
Auf dem Summit kündigte Snowflake drei neue Features als Teil der Cortex-Suite an.
Cortex Finetuning (Public Preview)
Cortex Finetuning ist jetzt in Public Preview. Damit lassen sich Foundational-LLM-Modelle direkt aus dem UI heraus trainieren.
Die meisten Standard-LLMs sind für Unternehmen kaum brauchbar, weil sie weder die internen Daten noch die Systeme kennen. Mit Finetuning können Unternehmen Modelle trainieren, die für ihre internen Use-Cases deutlich relevanter sind.
Cortex Analyst (Private Preview)
Cortex Analyst (Private Preview) ist ein serverloser und hochpräziser LLM-Service, mit dem Business-Anwender eine Frage stellen und eine echte Antwort erhalten – nicht nur SQL-Code.
Das ist einer der derzeit am meisten diskutierten KI-Use-Cases in der Branche. Wenn man einem LLM das gesamte semantische Wissen und die Metadaten des Data Warehouse zur Verfügung stellt und es zusätzlich SQL-Queries ausführen und die Ergebnisse interpretieren lässt, hat man etwas extrem Wertvolles in der Hand.
Cortex Analyst basiert auf einer YAML-Datei, in der Datenschema, Metriken und Synonyme definiert werden, um Umfang und Genauigkeit zu steuern. Wir sind sehr gespannt, wie sich dieses Feature entwickelt. Angesichts der Komplexität eines solchen Systems und der geschäftlichen Tragweite der Antworten dürfte es aber noch eine Weile dauern, bis es nennenswerte Volumina an echten Business-Anfragen beantwortet.
Cortex Search (Private Preview)
Cortex Search (ebenfalls in Private Preview) ist ein serverloser, LLM-basierter hybrider Suchservice (Vector + Keywords). Er extrahiert inkrementell Daten aus Dokumenten, Tabellen und Views, zerlegt sie automatisch in Chunks und vektorisiert sie – für schnelle Abfragen (< 200 ms) und hohe Trefferqualität.
Während der Summit-Keynote holte man spontan eine Person aus dem Publikum auf die Bühne. Sie hatte sich bis dahin nur wenige Male in Snowflake eingeloggt – und brachte in unter 5 Minuten allein per Klick im UI einen funktionierenden Service zum Laufen.
In der Demo wurde eine Stage ausgewählt, die mit einigen Beispiel-PDFs vorbefüllt war. Wenige Minuten später erschien ein Chat-Interface, in dem Fragen gestellt werden konnten – und das LLM antwortete direkt auf Basis der PDF-Inhalte.
Dark Mode!!
Zum Abschluss der Keynote verkündete Snowflake, dass eines der meistgewünschten Features – Dark Mode – nun für alle Kunden verfügbar ist. Das Video gibt es hier.
Ich nutze ihn seitdem und bin von Look & Feel ziemlich begeistert!
Abschließende Gedanken
Auch wenn es keine fundamentalen Plattform-Ankündigungen in der Größenordnung der vergangenen Jahre – etwa Native Apps oder Snowpark Container Services – gab, hat der Summit 2024 ein paar Dinge sehr deutlich gemacht:
- Das Tempo, in dem neue Features veröffentlicht und allgemein verfügbar gemacht werden, hat sich spürbar beschleunigt. Auch wenn keine einzelne Ankündigung so groß war wie damals der Snowflake App Store oder eine grundlegend neue Art, workloads auszuführen (Snowpark Container Services), gab es insgesamt deutlich mehr in der Breite.
- Snowflake stattet seine Kunden mit immer mehr Funktionalität ab Werk aus und reduziert den Bedarf an zusätzlichen Drittanbieter-Tools, die man typischerweise für den Betrieb eines Data Warehouse braucht. Es wird stärker in Data Quality und Data Governance investiert, alle Kunden bekommen bald Data Lineage (das beliebteste Feature von Data Catalogs), es gibt ein hervorragendes neues Notebooks-Feature und in Kürze kostenfreie Native Connectors für Postgres und MySQL (Tschüss, Fivetran?).
- KI und ML sind der absolute Fokus für Snowflake. Das wird auch in den Investor-Calls immer deutlicher – der Markt erwartet, dass diese neuen workloads (zusammen mit Snowpark) in den nächsten 5 Jahren einen relevanten Umsatzanteil ausmachen. Aktuell stammt der Großteil von Snowflakes Umsatz (ich schätze über 90 %) aus klassischen Data-Warehousing- und BI-workloads. Auf dem Summit wurden viele beeindruckende Features gezeigt. Wenn sie halten, was sie auf der Bühne versprochen haben, werden sie ohne Zweifel in vielen Organisationen die KI-Adoption maßgeblich beschleunigen.
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder und CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT leitete Ian sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und den Ausbau der Kostentransparenz.