Em 2022, a Snowflake fez grandes anúncios em torno do novo framework de Native Applications e das hybrid tables (anunciadas inicialmente como Unistore). No ano passado, manteve o nível alto ao lançar mais novidades, como o Snowpark Container Services e o suporte ao Iceberg.
Tendo acompanhado os dois últimos summits, eu e o Niall sempre saímos impressionados com o ritmo de desenvolvimento da Snowflake. Depois do Summit 2024, a sensação continua a mesma.
Vamos ao que interessa.

Resumo dos anúncios
Se você está sem tempo, segue a lista completa de tudo o que foi anunciado, com uma breve explicação.
Data Engineering
- A empresa vai abrir o código do Polaris Catalog em 90 dias, permitindo que os clientes hospedem seus próprios catálogos Iceberg e ampliando a interoperabilidade entre diferentes engines de computação.
- Serverless Tasks Flex, que oferece aos clientes uma forma de economizar até 42% ao permitir mais flexibilidade na hora em que as tasks são executadas (Private Preview).
- Event-driven tasks agora em public preview, permitindo disparar automaticamente a execução de uma task sempre que um stream da Snowflake é atualizado.
- Low Latency Tasks, agora em private preview, com intervalos de agendamento de tasks reduzidos a até 15 segundos.
- Iceberg Tables, um formato de tabela open source que permite armazenar os dados em cloud storage como arquivos parquet e ainda assim consultá-los pela Snowflake, agora em General Availability (GA).
- Dynamic Tables agora em GA, com uma abordagem declarativa para criar transformações incrementais e pipelines de dados simples usando comandos SQL SELECT.
- Data Quality Monitoring: a Snowflake passa a oferecer métricas de sistema prontas para uso (como contagem de nulos) ou métricas customizadas que os clientes podem definir e medir automaticamente em tabelas. O recurso está em public preview e disponível apenas nas edições Enterprise ou superiores da Snowflake.
- Conectores nativos para Postgres e MySQL entrarão em public preview em breve. Eles vão permitir replicar com facilidade dados CDC dos bancos internos da empresa para a Snowflake com latência muito baixa e, o mais importante, sem pagar a uma empresa terceira (como a Fivetran) por cada linha carregada.
Ferramentas para analistas e desenvolvedores
- Snowflake Notebooks agora em public preview, com um ambiente de UI interativo e ponta a ponta para times de dados e IA.
- A Snowflake anunciou um novo conjunto de recursos de observabilidade com o lançamento do Snowflake Trail, dando a desenvolvedores e parceiros mais ferramentas para monitorar e depurar seus pipelines de dados.
- Snowpark Container Services (SPCS) agora em GA, permitindo que os usuários da Snowflake executem com segurança qualquer workload na Snowflake por meio de um container.
- Como parte disso, a Snowflake anunciou suporte em public preview para SPCS no framework de native apps, permitindo que parceiros construam e implantem aplicações mais robustas.
- O CoPilot da Snowflake entrará em GA em breve, permitindo que analistas e usuários de negócio gerem automaticamente queries SQL a partir de texto, direto na UI da Snowflake.
- A integração com Git da Snowflake agora em Public Preview, permitindo sincronizar arquivos entre Github/Gitlab/Bitbucket e a Snowflake para um controle de versão e gestão melhores.
Governança e segurança de dados
- Um novo marketplace interno em private preview, que vai permitir a grandes organizações e times compartilhar de forma privada datasets, apps, notebooks e outros recursos dentro da empresa.
- Novas Table Governance Views em public preview, mostrando os principais roles e usuários que acessam cada tabela na sua conta Snowflake.
- O Trust Center da Snowflake, uma interface para identificar riscos de segurança e ver recomendações para resolvê-los, entrará em GA em breve.
- Universal Search agora em GA, permitindo pesquisar e descobrir rapidamente todos os ativos Snowflake direto na UI.
- A Snowflake mostrou uma nova interface de Data Lineage Visualization na UI, atualmente em private preview, que vai permitir ver dependências upstream e downstream de todas as tabelas e views.
- Também foram anunciadas as AI-Powered Object Descriptions, que adicionam automaticamente contexto e comentários relevantes a tabelas e views usando IA.
IA e ML para empresas
- A Snowflake lançou uma nova Snowpark pandas API, que permite a usuários Python executar seu código pandas na computação da Snowflake de forma paralelizada, eliminando as limitações típicas do pandas em volumes de dados e performance.
- O Document AI entrará em GA em breve. Ele oferece processamento de documentos baseado em LLM serverless para extrair dados estruturados de documentos de negócio não estruturados (PDF, Imagens, Word etc., como faturas, contratos, fichas de teste de produto etc.). Saiba mais aqui.
- O Snowflake Feature Store, agora em public preview, permite criar, gerenciar e servir features de ML com atualização contínua e automatizada sobre dados em batch ou streaming, via UI ou APIs Snowpark ML. Saiba mais aqui.
- O Snowflake Model Registry agora em GA, com uma solução integrada para gerenciar, rastrear, versionar e compartilhar modelos de IA/ML e seus metadados nativamente na Snowflake, via UI ou APIs Snowpark ML. Saiba mais aqui.
- Snowsight AI & ML Studio agora em GA, com uma UI que permite criar com facilidade diferentes modelos e pipelines de ML e IA.
- Cortex Finetuning agora em Public Preview, permitindo treinar modelos LLM fundacionais direto pela UI.
- O Cortex Analyst, atualmente em private preview, é um serviço LLM serverless e altamente preciso que permite aos usuários de negócio fazer uma pergunta e receber uma resposta de verdade, e não apenas um trecho de SQL. O Analyst será orientado por um arquivo YAML que define elementos como o schema dos dados, as métricas e os sinônimos para controlar escopo e precisão.
- O Cortex Search, também em private preview, é um serviço de busca híbrido (Vetorial + Palavras-chave) baseado em LLM e serverless, que extrai incrementalmente dados de docs, tabelas e views, fragmenta os dados automaticamente e os vetoriza para consultas rápidas (< 200ms) com alta precisão.
Bastante coisa para digerir! No restante do post, vou me aprofundar no que foi discutido sobre a direção da Snowflake e detalhar alguns dos maiores anúncios, junto com seu impacto.
Abertura e filosofia da Snowflake
Na abertura da keynote do summit, Sridhar e Benoit começaram reforçando os princípios centrais da plataforma Snowflake. Eles destacaram como a Snowflake é uma única plataforma construída sobre uma única engine, que simplesmente funciona. A ideia é manter tudo simples, sem oferecer 20 formas diferentes de fazer a mesma coisa. Esse ponto só caiu a ficha de verdade quando participei do Databricks Summit na semana seguinte e vi o quanto o produto deles é complexo.
Como a Snowflake recentemente mudou o posicionamento de "Data Cloud" para "AI Data Cloud", a abertura girou bastante em torno de como a plataforma oferece tudo o que você precisa para IA corporativa:
- Dados. A Snowflake oferece armazenamento nativo de alta performance e tem suporte ao formato aberto Iceberg para clientes que querem manter controle total sobre seus dados e torná-los acessíveis a outras engines de computação (como Spark ou Trino).
- Computação. Todo mundo conhece os virtual warehouses da Snowflake, usados principalmente para queries SQL. Internamente, a Snowflake chama essa tecnologia de virtual warehouse de "data flow engine". Todas as linguagens (Java, Python e Scala) são processadas por essa engine, não só SQL. Com o Snowpark Container Services, a Snowflake agora oferece uma opção de computação ainda mais flexível, que permite rodar qualquer aplicação ou workload em um container seguro (pense assim: se roda no Docker, roda na Snowflake).
- IA, o grande tema do dia. Com o Cortex, os clientes da Snowflake têm acesso a um conjunto de ferramentas que simplifica o uso e a construção de aplicações de IA. Também falaram sobre o Arctic, uma nova família de LLMs desenvolvida pela Snowflake, voltada especificamente para casos de uso corporativos.
- Segurança, governança e colaboração. A Snowflake é conhecida há muito tempo pelas suas fortes garantias de segurança, facilidade de governança e controle de acesso robusto. Embora o usuário comum nem pense nisso, esses recursos e garantias são o mínimo esperado em qualquer empresa.
Polaris Catalog e mais interoperabilidade no setor
Um dos anúncios mais comentados aconteceu dias antes do Summit começar, quando a Snowflake anunciou que abriria o código do seu Iceberg Catalog, o Polaris. Um dos grandes motivos para isso ser relevante é que vai aumentar a usabilidade e a interoperabilidade dos data lakes Iceberg entre as plataformas de nuvem.

Outro motivo de tanto burburinho é que a Databricks anunciou simultaneamente a aquisição da Tabular, empresa fundada pelos criadores e principais responsáveis pelo desenvolvimento do Iceberg.
Isso claramente significa que a Databricks vai oferecer suporte de primeira classe ao Iceberg no seu produto, e imagino que em algum momento a Snowflake vá no mesmo caminho e adicione suporte ao Delta Lake. Embora seja um pouco desconfortável saber que uma única empresa vai praticamente "ser dona" dos dois formatos open source mais populares de dados, acredito que no fim isso vai beneficiar bastante os clientes, já que todas as plataformas de dados em nuvem serão forçadas a oferecer suporte a mais formatos abertos.
Como parte disso, a Snowflake também anunciou uma grande expansão da parceria com o Microsoft Fabric. No coração do Fabric está o OneLake, que historicamente usava arquivos parquet em formato delta-lake. Agora, a Microsoft vai dar suporte ao Iceberg e a Snowflake vai se integrar ao OneLake.
Para quem está curioso sobre por que é preciso um catálogo separado para o Iceberg, achei útil este trecho da documentação do Iceberg:
Você pode pensar no Iceberg como um formato para gerenciar dados em uma única tabela, mas a biblioteca Iceberg precisa de uma forma de rastrear essas tabelas pelo nome. Tarefas como criar, excluir e renomear tabelas são responsabilidade de um catálogo. Catálogos gerenciam uma coleção de tabelas geralmente agrupadas em namespaces. A responsabilidade mais importante de um catálogo é rastrear os metadados atuais de uma tabela, que ele fornece quando você carrega a tabela.
O projeto Iceberg não forneceu um catálogo em si; em vez disso, estabeleceu os padrões do que os catálogos fariam e como poderiam interagir com o Iceberg. Bem ao estilo da Snowflake, eles estão reduzindo drasticamente a barreira para adotar tecnologias complexas como o Iceberg ao fornecer as peças que faltavam.
Serverless Tasks Flex em Private Preview
Para quem se interessa por otimização de custos na Snowflake, foi anunciado um novo recurso bem interessante chamado Serverless Tasks Flex.
Com as Serverless Tasks, você define um agendamento e a Snowflake executa automaticamente sua query em recursos de computação gerenciados por ela. Você paga por segundo apenas pelo tempo de computação efetivamente usado.
Com o Serverless Tasks Flex, você informa um agendamento e também um SLA que define o tempo máximo de execução da sua task (ou seja, em quanto tempo ela precisa terminar a partir do horário agendado). A Snowflake usa essas duas entradas e encontra o momento mais barato para executar sua task, garantindo que ela termine dentro do SLA (por exemplo, 3 horas) que você especificou.

Snowpark Container Services em Native Apps agora em Public Preview
A Snowflake anunciou que desenvolvedores de native apps agora podem usar o Snowpark Container Services em suas aplicações, o que viabiliza UIs mais ricas (por exemplo, React/Javascript customizado) e aplicações complexas construídas e executadas inteiramente na Snowflake.
Esse foi um anúncio enorme para os parceiros da Snowflake, pois vai permitir que empresas como a SELECT ofereçam seus produtos de forma mais segura e fluida.

Snowflake Notebooks em Public Preview
A Snowflake anunciou que sua funcionalidade de Notebooks agora está em Public Preview. Os Notebooks permitem combinar Python, SQL e Markdown para criar relatórios, jobs ou fazer análises ad hoc.
Você também pode agendar notebooks para rodar em um virtual warehouse ou em um container Snowpark. A Snowflake também anunciou que oferecerá CoPilot integrado para notebooks (atualmente em public preview).
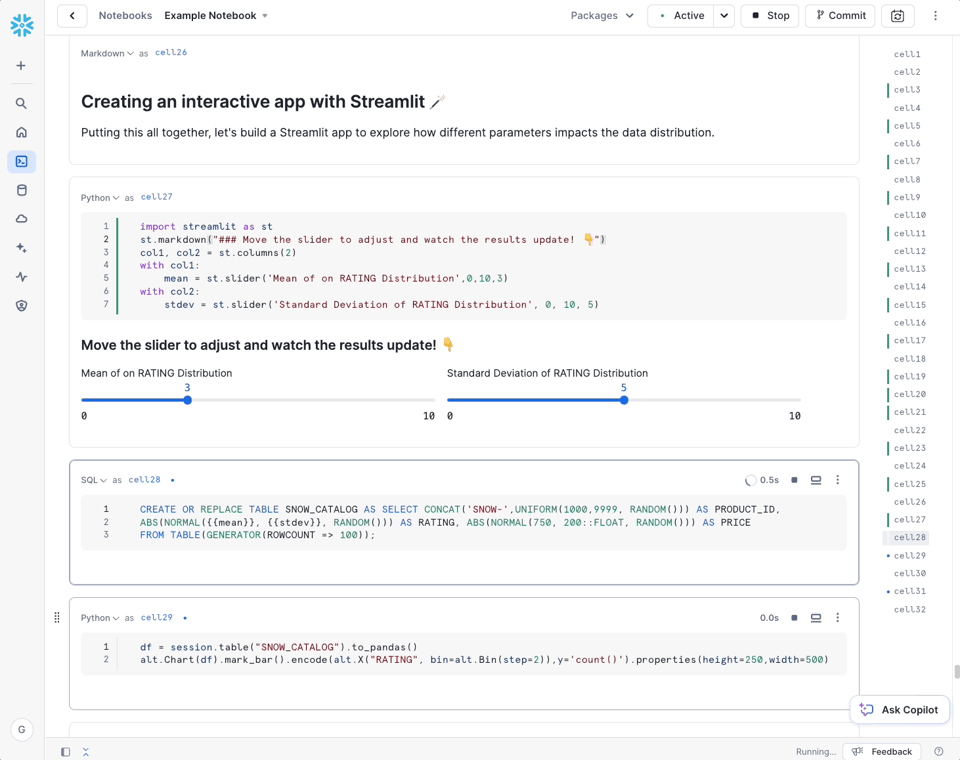
Anúncios do Snowflake Horizon
O Snowflake Horizon é o conjunto de recursos da Snowflake voltado a governança de dados, descoberta, segurança e privacidade. Houve diversos anúncios relacionados ao Horizon:
- Universal Search
- Table Governance Views
- AI-Powered Object Descriptions
- Data Lineage Visualization para Tabelas e Views
- ML Lineage Visualization
- Trust Center
- Internal Marketplace
Vou comentar alguns desses que considero mais relevantes para a maioria dos usuários da Snowflake.
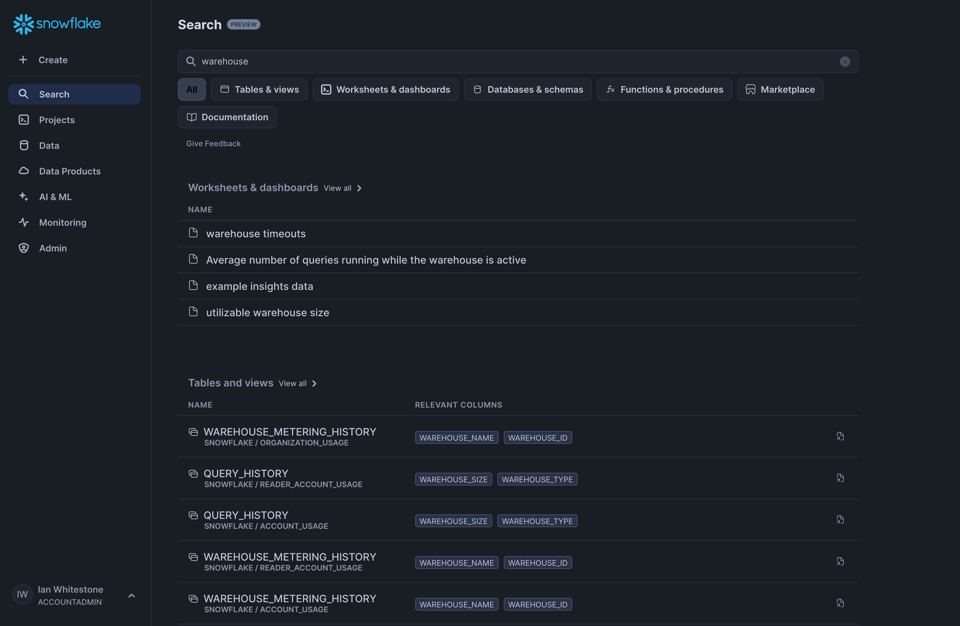
Universal Search agora em General Availability
A busca, acessível pela UI, permite pesquisar tudo na Snowflake, dos seus dados internos ao marketplace. Ela é alimentada pela tecnologia de search engine da Neeva, que a Snowflake adquiriu em 2023.
Veja um exemplo da nossa conta Snowflake:
Aba de Table Governance em Public Preview
Na página da tabela, a Snowflake apresentou uma nova aba de Governance com informações sobre as principais queries, usuários e roles que acessam aquela tabela. Vai ser útil para quem quer entender quem está usando uma tabela e de que forma.
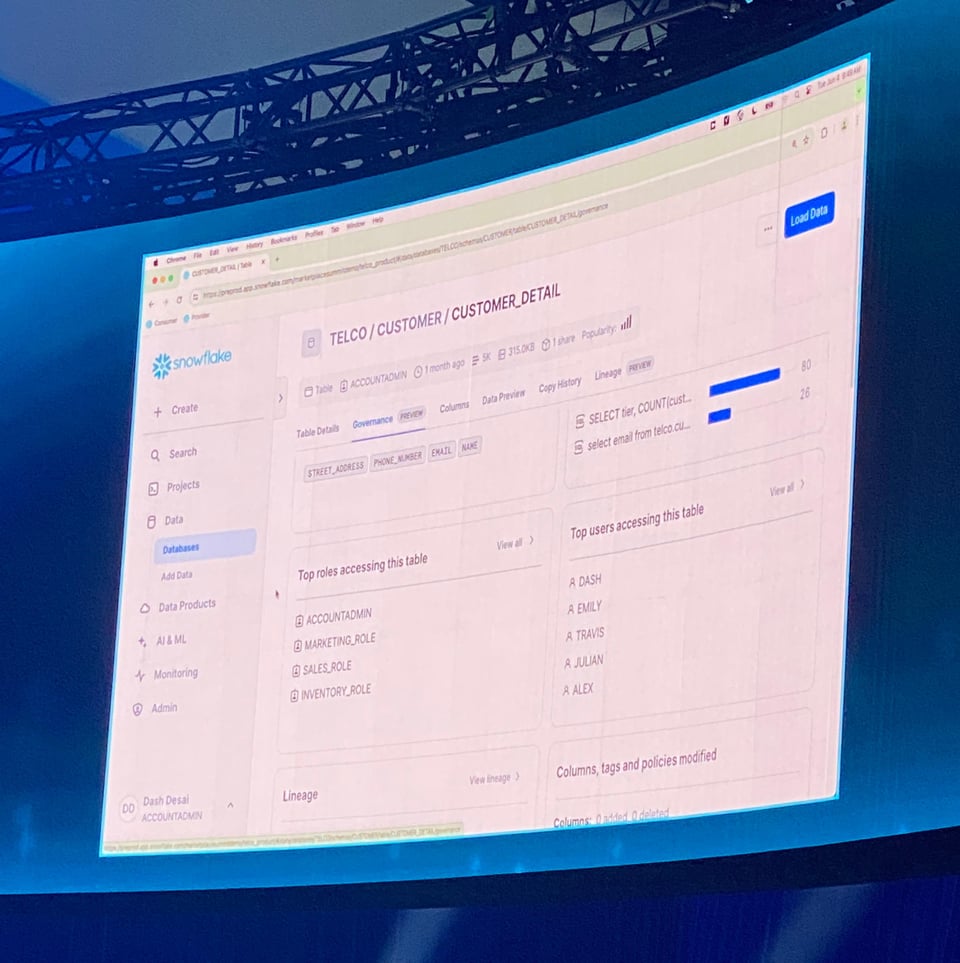
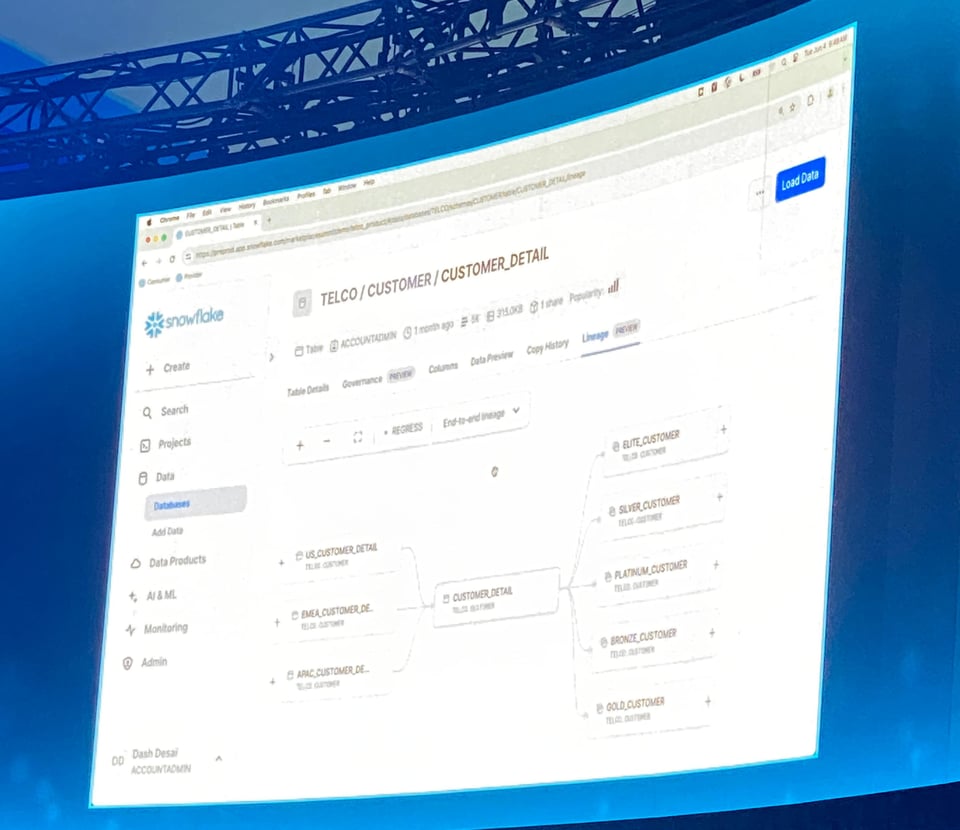
Table Lineage em Private Preview
A Snowflake mostrou uma nova visualização de Table Lineage na página da tabela, exibindo as dependências upstream e downstream de Views e Tabelas.
Essa é uma das funcionalidades mais populares oferecidas por ferramentas de Data Catalog e Observabilidade, então é ótimo ver a Snowflake disponibilizando isso para todos os clientes.
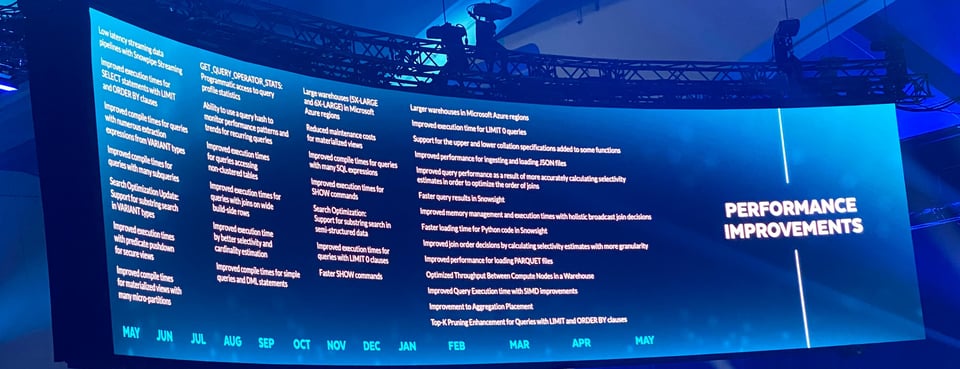
Diversas melhorias de performance
Para quem se interessa por otimização de queries, a Snowflake destacou uma série de melhorias de performance lançadas nos últimos 12 meses. Todas elas acontecem nos bastidores e melhoram silenciosamente a experiência de desenvolvedores e usuários de todos os clientes da Snowflake.
Conectores nativos para Postgres e MySQL
Com base no sucesso dos seus conectores nativos recentes — o Snowflake Connector for Kafka e os conectores para aplicações SaaS, como ServiceNow e Google Analytics —, a Snowflake anunciou que os conectores nativos para Postgres e MySQL entrarão em public preview em breve. Isso vai permitir aos clientes replicar com facilidade dados CDC dos bancos internos da empresa para a Snowflake com latência muito baixa e, o mais importante, sem pagar a uma empresa terceira por cada linha carregada.
Vai ser interessante ver o que isso significa para empresas como a Fivetran. Se eu fosse chutar, mais da metade da receita deles provavelmente vem de replicação de dados de Postgres e MySQL. A Snowflake já afirmou que vai construir mais conectores no futuro para outros bancos de dados líderes, então a canibalização de receita só tende a aumentar.
Snowflake Trail em Private Preview
A Snowflake segue ampliando os investimentos em recursos de observabilidade, tanto para dados quanto para desenvolvimento de aplicações.
Este ano, no Summit, anunciaram o Snowflake Trail, um conjunto de funcionalidades da Snowflake para que os desenvolvedores monitorem, investiguem, depurem e ajam sobre pipelines, apps, código de usuário e uso de computação.
O Snowflake Trail é alimentado pelas Event Tables e ajuda os usuários a ganharem automaticamente mais visibilidade sobre a performance do código Snowpark e o uso de recursos.
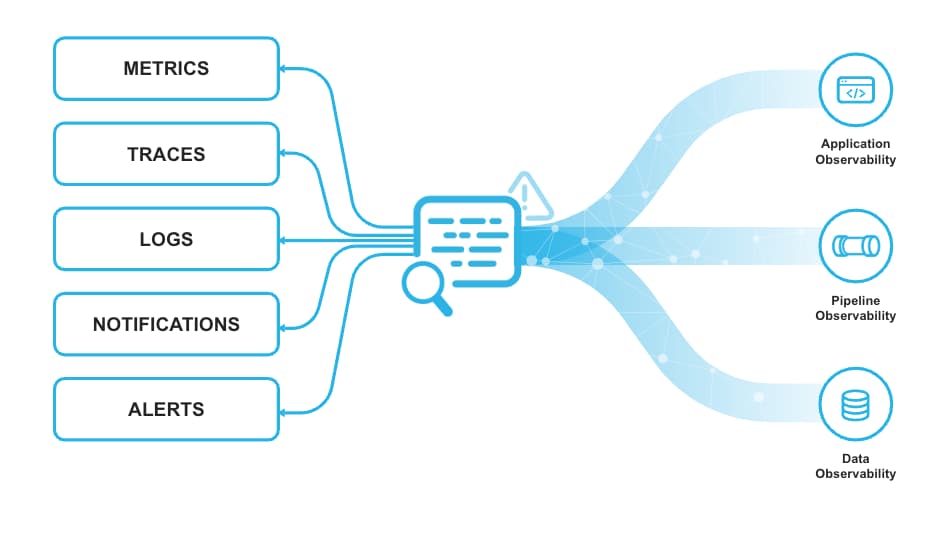
O Snowflake Trail é compatível com a especificação OpenTelemetry, então pode ser facilmente integrado a tecnologias parceiras. Eles também terão uma UI básica sobre as event tables.
Snowpark Pandas API
No fim de 2023, a Snowflake adquiriu a Ponder para reforçar suas capacidades em Python.
Como resultado dessa aquisição, a Snowflake lançou uma nova Snowpark pandas API, que permite a usuários Python executar seu código pandas na computação da Snowflake de forma paralelizada, eliminando as limitações típicas do pandas em volumes de dados e performance.
Agora dá para escrever código pandas normal e tê-lo executado automaticamente, por baixo dos panos, como SQL da Snowflake, com performance bem melhor e capacidade de lidar com datasets maiores que a memória disponível.
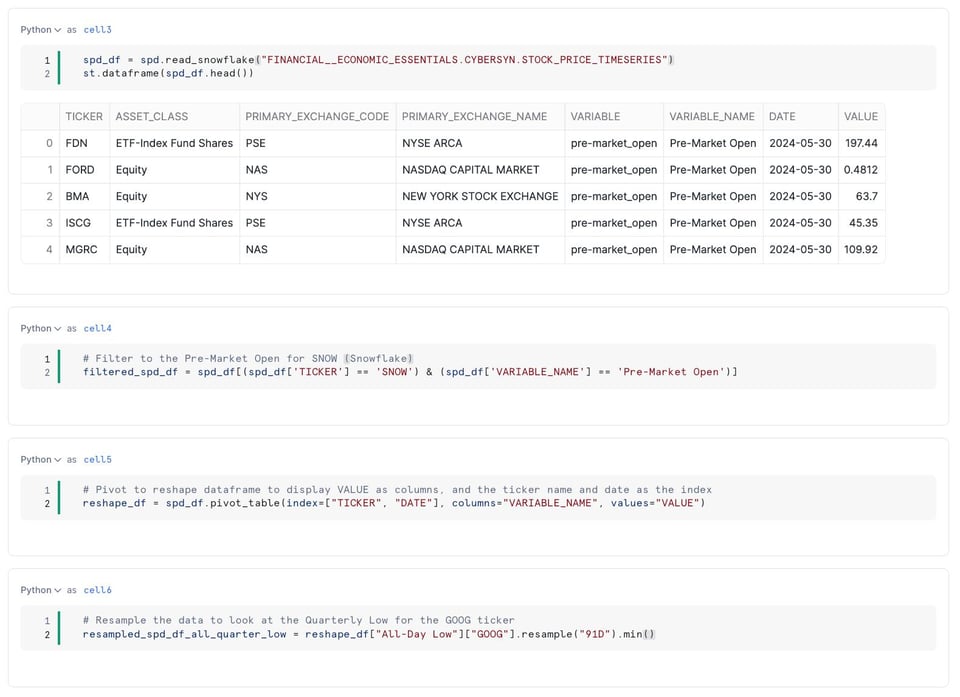
Nos bastidores, isso funciona pegando seu código pandas e traduzindo-o em queries SQL, cujos resultados voltam como objetos Python nativos. Muito legal!
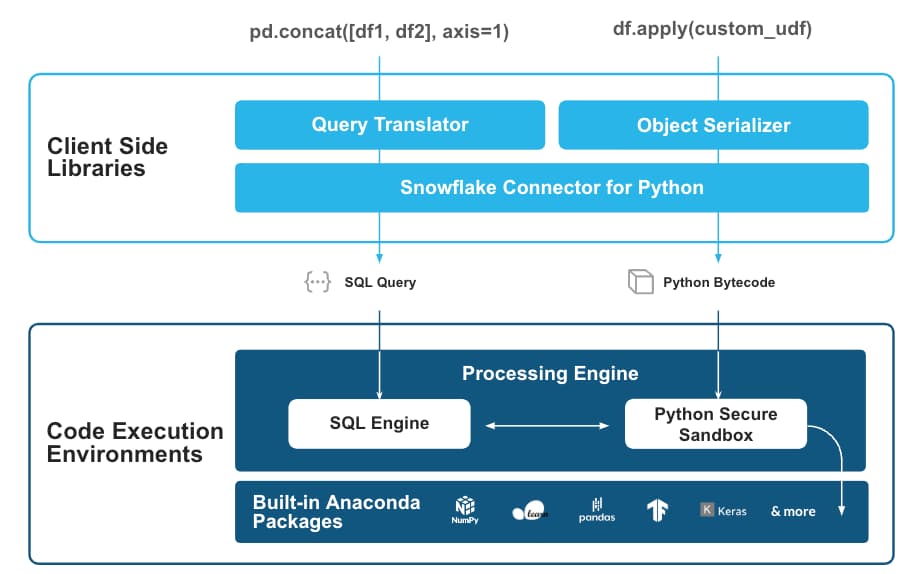
Imagens do anúncio da Snowflake: https://www.snowflake.com/blog/snowpark-pandas-api-run-at-scale/
Snowflake Cortex
O Snowflake Cortex é o conjunto de ferramentas e recursos de IA da Snowflake. O Cortex dá acesso a vários LLMs diferentes, incluindo os da Mistral, Reka, Meta, Google e o Snowflake Arctic.
No Summit, a Snowflake anunciou 3 novos recursos como parte do conjunto Cortex.
Cortex Finetuning (Public Preview)
O Cortex Finetuning agora está em Public Preview, permitindo treinar modelos LLM fundacionais direto pela UI.
A maioria dos LLMs prontos não atende bem à maior parte das empresas, porque não conhecem seus dados ou sistemas internos. Com o fine-tuning, as empresas conseguem treinar modelos mais relevantes para seus casos de uso internos.
Cortex Analyst (Private Preview)
O Cortex Analyst, atualmente em private preview, é um serviço LLM serverless e altamente preciso que permite aos usuários de negócio fazer uma pergunta e receber uma resposta de verdade, não apenas um trecho de SQL.
Esse é um dos principais casos de uso de IA que todo mundo está discutindo no setor. Se você equipa um LLM com todo o conhecimento semântico e os metadados do seu data warehouse e dá a ele a capacidade de executar queries SQL e interpretar os resultados, surge algo de muito valor.
O Cortex Analyst será orientado por um arquivo YAML que define elementos como o schema dos dados, as métricas e os sinônimos para controlar escopo e precisão. Estamos bem animados para ver como esse recurso vai evoluir. Dada a complexidade de construir um sistema desses e as implicações de negócio em respostas incorretas, acredito que vai demorar um pouco até que ele lide com volumes significativos de perguntas reais do negócio.
Cortex Search (Private Preview)
O Cortex Search, também em private preview, é um serviço de busca híbrido (Vetorial + Palavras-chave) baseado em LLM e serverless, que extrai incrementalmente dados de docs, tabelas e views, fragmenta os dados automaticamente e os vetoriza para consultas rápidas (< 200ms) com alta precisão.
Durante a keynote do Summit, chamaram uma pessoa aleatória da plateia ao palco. Ela só tinha entrado na Snowflake umas poucas vezes e conseguiu colocar um serviço funcionando em menos de 5 minutos, só clicando pela UI.
Durante a demo, selecionaram um stage pré-carregado com vários PDFs de exemplo e, em poucos minutos, apareceu uma interface de chat onde dava para fazer perguntas, e o LLM respondia com base direta no conteúdo desses PDFs.
Dark Mode!!
Para encerrar a keynote, a Snowflake anunciou que um dos recursos mais pedidos, o Dark Mode, agora estava disponível para todos os clientes. Você pode assistir ao vídeo aqui.
Estou usando desde então e estou bem satisfeito com o visual!
Considerações finais
Embora não tenha havido nenhum anúncio fundacional de plataforma tão grande quanto Native Apps ou Snowpark Container Services dos anos anteriores, o Summit 2024 deixou algumas coisas claras:
- O ritmo em que novos recursos são lançados e disponibilizados em GA acelerou bastante. Mesmo sem nenhum anúncio individual tão impactante quanto a Snowflake lançar uma app store ou uma forma fundacional nova de executar workloads (Snowpark Container Services), a sensação é a de que recebemos muito mais coisa no geral.
- A Snowflake está entregando aos clientes mais funcionalidades prontas de fábrica e reduzindo a necessidade de buscar outras ferramentas de terceiros que costumam ser exigidas para operar um data warehouse. A empresa aprofundou seus investimentos em qualidade e governança de dados, todos os clientes em breve terão data lineage (o recurso mais popular dos data catalogs), há um excelente novo recurso de Notebooks e está prestes a lançar conectores nativos e gratuitos para Postgres e MySQL (tchau, Fivetran?).
- IA e ML são a área de foco número um da Snowflake. Isso também tem ficado cada vez mais claro nas calls com investidores, já que o mercado espera que esses novos workloads (junto com o Snowpark) representem uma parcela significativa da receita nos próximos 5 anos. Hoje, a maior parte da receita da Snowflake (eu chutaria mais de 90%) vem de workloads tradicionais de data warehousing e business intelligence. Foram demonstradas muitas funcionalidades impressionantes no Summit. Se elas entregarem o que foi mostrado no palco, não há dúvida de que terão um impacto enorme em muitas organizações em termos de acelerar a adoção de IA.
Ian Whitestone·Co-fundador e CEO da SELECT
Ian é Co-fundador e CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.