Nel 2022 Snowflake aveva fatto annunci importanti sul nuovo framework Native Application e sulle hybrid tables (presentate inizialmente come Unistore). L'anno scorso ha mantenuto l'asticella alta annunciando ulteriori novità come Snowpark Container Services e l'aggiunta del supporto a Iceberg.
Avendo partecipato ai due summit precedenti, io e Niall siamo sempre rimasti colpiti dal ritmo di sviluppo di Snowflake. A Summit 2024 concluso, la sensazione non è cambiata.
Entriamo nel vivo.

Riepilogo degli annunci
Se avete poco tempo, ecco l'elenco completo di tutto ciò che è stato annunciato, con una breve descrizione.
Data Engineering
- Entro 90 giorni verrà rilasciato in open source Polaris Catalog, che permetterà ai clienti di ospitare in autonomia i propri cataloghi Iceberg e garantirà una maggiore interoperabilità tra i vari motori di calcolo.
- Serverless Tasks Flex, che permette ai clienti di risparmiare fino al 42% grazie a una maggiore flessibilità sull'orario di esecuzione dei task (Private Preview).
- Gli event-driven tasks sono ora in public preview e consentono di avviare automaticamente un task ogni volta che uno stream Snowflake viene aggiornato.
- Low Latency Tasks, ora in private preview, che permettono di ridurre gli intervalli di pianificazione dei task fino a 15 secondi.
- Le Iceberg Tables, un formato di tabella open source che permette ai clienti di archiviare i dati nel cloud storage come file parquet potendoli comunque interrogare da Snowflake, sono ora in General Availability (GA).
- Le Dynamic Tables sono ora in GA e offrono un approccio dichiarativo per creare trasformazioni incrementali e semplici data pipeline tramite istruzioni SQL SELECT.
- Data Quality Monitoring: Snowflake mette ora a disposizione metriche di sistema pronte all'uso (come il conteggio dei null) e metriche personalizzate che i clienti possono definire e applicare automaticamente alle tabelle. Questa funzionalità è in public preview e disponibile solo nelle edizioni Enterprise o superiori di Snowflake.
- I connettori nativi per Postgres e MySQL saranno presto in public preview. Permetteranno ai clienti di replicare facilmente dati CDC dai database aziendali interni verso Snowflake con latenza molto bassa e, soprattutto, senza pagare un fornitore terzo (come Fivetran) per ogni riga caricata.
Strumenti per analisti e sviluppatori
- Gli Snowflake Notebooks sono ora in public preview e offrono un ambiente UI interattivo end-to-end per i team data & AI.
- Snowflake ha annunciato una nuova suite di funzionalità di observability con il lancio di Snowflake Trail, che fornisce a sviluppatori e partner ulteriori strumenti per monitorare ed effettuare il debug delle data pipeline.
- Snowpark Container Services (SPCS) è ora in GA e consente agli utenti Snowflake di eseguire in modo sicuro qualsiasi workload all'interno di Snowflake tramite container.
- Nell'ambito di questo annuncio, Snowflake ha presentato il supporto in public preview di SPCS nel framework Native Apps, che consente ai partner di sviluppare e distribuire applicazioni ricche di funzionalità.
- Il Copilot di Snowflake sarà presto in GA e permetterà ad analisti e business user di generare automaticamente query SQL a partire da testo scritto, direttamente nell'interfaccia di Snowflake.
- L'integrazione Git di Snowflake è ora in Public Preview e consente di sincronizzare i file tra Github/Gitlab/Bitbucket e Snowflake per un migliore controllo di versione e una gestione più ordinata.
Data Governance e sicurezza
- Un nuovo marketplace interno in private preview, che permetterà a grandi organizzazioni e team di condividere privatamente dataset, app e notebook all'interno dell'azienda.
- Nuove Table Governance Views in public preview, che mostrano i principali ruoli e utenti che accedono a ciascuna tabella dell'account Snowflake.
- Il Trust Center di Snowflake, un'interfaccia UI per individuare i rischi di sicurezza e ottenere suggerimenti per risolverli, sarà presto in GA.
- Universal Search è ora in GA e consente di cercare e individuare rapidamente tutti gli asset Snowflake direttamente dalla UI.
- Snowflake ha mostrato una nuova interfaccia di Data Lineage Visualization nella UI, attualmente in private preview, che permetterà di visualizzare le dipendenze upstream e downstream per tutte le tabelle e le view.
- Sono state annunciate le AI-Powered Object Descriptions, che aggiungono automaticamente contesto e commenti pertinenti a tabelle e view sfruttando l'AI.
Enterprise AI e ML
- Snowflake ha rilasciato una nuova API Snowpark pandas che permette agli utenti Python di eseguire il proprio codice pandas sul compute di Snowflake in modo parallelizzato, eliminando i tipici limiti di pandas su volumi di dati e performance.
- Document AI sarà presto in GA. Document AI offre un'elaborazione documentale serverless basata su LLM per estrarre dati strutturati da documenti aziendali non strutturati (PDF, immagini, Word ecc., come fatture, contratti, schede tecniche di prodotto e così via). Maggiori informazioni qui.
- Snowflake Feature Store, ora in public preview, consente di creare, gestire e servire feature ML con aggiornamenti continui e automatizzati su dati batch o streaming, tramite UI o API Snowpark ML. Maggiori informazioni qui.
- Snowflake Model Registry è ora in GA e offre una soluzione integrata per gestire, tracciare, versionare e condividere modelli AI/ML e i relativi metadati nativamente in Snowflake, tramite UI o API Snowpark ML. Maggiori informazioni qui.
- Snowsight AI & ML Studio è ora in GA e offre una UI che permette di creare facilmente diversi modelli e pipeline ML e AI.
- Cortex Finetuning è ora in Public Preview e permette di addestrare modelli Foundational LLM direttamente dalla UI.
- Cortex Analyst, attualmente in private preview, è un servizio LLM serverless e altamente accurato che permette ai business user di porre una domanda e ricevere una vera risposta, non solo testo SQL. Analyst sarà alimentato da un file YAML che definisce elementi come lo schema dei dati, le metriche e i sinonimi per controllarne ambito e accuratezza.
- Cortex Search, anch'esso in private preview, è un servizio di ricerca ibrida (Vector + Keywords) serverless basato su LLM che estrae in modo incrementale dati da documenti, tabelle e view, suddividendoli automaticamente in chunk e vettorializzandoli per query veloci (< 200 ms) e prestazioni di ricerca molto accurate.
Davvero tanta carne al fuoco! Nel resto del post approfondirò ciò che è stato detto sulla direzione di Snowflake e analizzerò nel dettaglio alcuni degli annunci più rilevanti, con il relativo impatto.
Apertura e filosofia di Snowflake
Nell'apertura del keynote del summit, Sridhar e Benoit hanno esordito ribadendo i principi cardine della piattaforma Snowflake. Hanno sottolineato come Snowflake sia un'unica piattaforma costruita su un unico motore, che semplicemente funziona. Le cose sono tenute semplici e non vengono offerti 20 modi diversi per fare la stessa operazione. Questo punto non mi è risuonato appieno finché, la settimana successiva, non ho partecipato al Databricks Summit, scoprendo quanto sia complesso il loro prodotto.
Dopo il recente rebranding da "Data Cloud" a "AI Data Cloud", l'apertura si è concentrata in larga parte su come la piattaforma offra tutto ciò che serve per l'Enterprise AI:
- Dati. Snowflake offre uno storage nativo ad alte prestazioni e supporta il formato aperto Iceberg per i clienti che vogliono mantenere il pieno controllo dei propri dati e renderli accessibili ad altri motori di calcolo (per esempio Spark o Trino).
- Compute. I virtual warehouse di Snowflake, usati soprattutto per le query SQL, sono noti a tutti. Internamente, Snowflake definisce questa tecnologia un "data flow engine". Tutti i linguaggi (Java, Python e Scala) vengono inoltrati a questo motore, non solo SQL. Con Snowpark Container Services, Snowflake propone ora un'opzione di compute ancora più flessibile, che permette di eseguire qualsiasi applicazione o workload in un container sicuro (in altre parole: se gira in Docker, può girare in Snowflake).
- AI, il grande tema del momento. Con Cortex, i clienti Snowflake hanno accesso a una suite di strumenti che semplificano l'uso e lo sviluppo di applicazioni AI. È stato inoltre presentato Arctic, una nuova famiglia di LLM progettata da Snowflake e pensata specificamente per i casi d'uso enterprise.
- Sicurezza, governance e collaborazione. Snowflake è da sempre apprezzata per le solide garanzie di sicurezza, la semplicità della governance e il robusto controllo degli accessi. Anche se non sono aspetti a cui l'utente medio pensa, queste funzionalità sono ormai requisiti imprescindibili per qualsiasi azienda.
Polaris Catalog e più interoperabilità nel settore
Uno degli annunci più discussi è arrivato qualche giorno prima dell'inizio del Summit, quando Snowflake ha annunciato il rilascio in open source del proprio Iceberg Catalog, Polaris. È una notizia rilevante perché contribuirà ad aumentare l'usabilità e a offrire maggiore interoperabilità dei data lake Iceberg tra le diverse piattaforme cloud.

Un altro motivo per cui se n'è parlato tanto è che, in contemporanea, Databricks ha annunciato l'acquisizione di Tabular, l'azienda fondata dai creatori e dalle figure chiave dietro lo sviluppo di Iceberg.
Questo significa chiaramente che Databricks integrerà un supporto di prima classe a Iceberg nel proprio prodotto, e immagino che prima o poi anche Snowflake seguirà l'esempio aggiungendo il supporto a Delta Lake. Anche se è un po' inquietante sapere che una sola azienda "possiederà" di fatto i due formati di dati open source più diffusi, credo che alla fine i clienti ne trarranno enormi benefici, perché tutte le piattaforme dati cloud saranno costrette a supportare un numero maggiore di formati aperti.
Nell'ambito di questo, Snowflake ha anche annunciato un'importante espansione della partnership con Microsoft Fabric. Al centro di Fabric c'è OneLake, storicamente basato su file parquet in formato delta-lake. Ora Microsoft supporterà Iceberg e Snowflake si integrerà con OneLake.
Per chi si chiede perché serva un catalogo separato per Iceberg, ho trovato utile questo passaggio della documentazione di Iceberg:
Si può pensare a Iceberg come a un formato per gestire i dati di una singola tabella, ma la libreria Iceberg ha bisogno di un modo per tenere traccia di queste tabelle in base al nome. Operazioni come creare, eliminare e rinominare tabelle sono di competenza di un catalogo. I cataloghi gestiscono un insieme di tabelle, di solito raggruppate in namespace. La responsabilità più importante di un catalogo è tracciare i metadati correnti di una tabella, che vengono forniti dal catalogo stesso al momento del caricamento della tabella.
Il progetto Iceberg non ha fornito un catalogo proprio: si è limitato a definire gli standard su cosa i cataloghi dovessero fare e come potessero interagire con Iceberg. Nel tipico stile di Snowflake, l'azienda sta abbassando drasticamente la barriera all'adozione di tecnologie complesse come Iceberg, fornendo i tasselli mancanti.
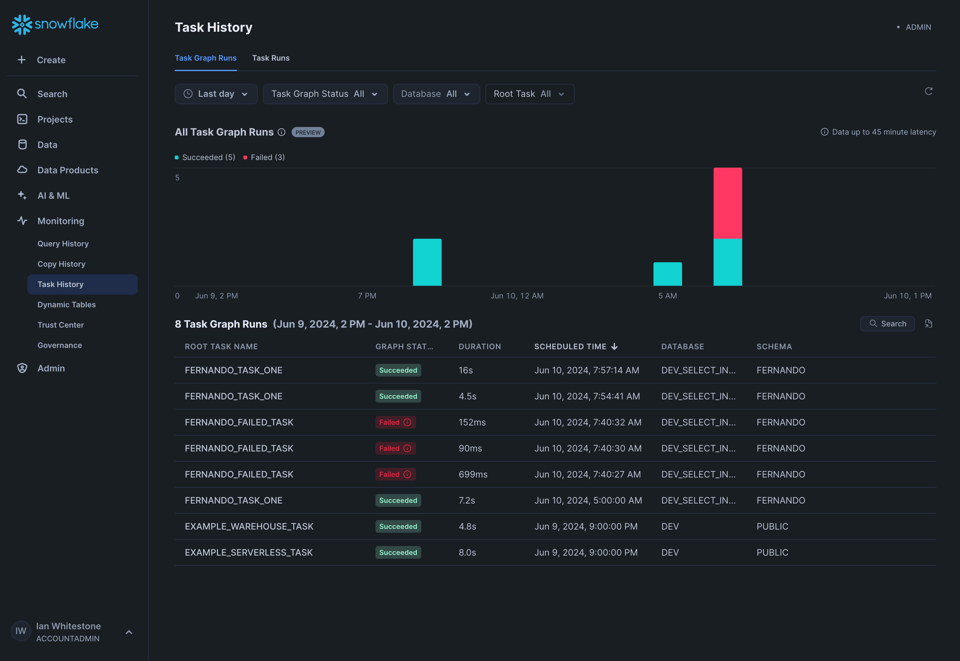
Serverless Tasks Flex in Private Preview
Per chi è interessato all'ottimizzazione dei costi di Snowflake, è stata annunciata una nuova interessante funzionalità chiamata Serverless Tasks Flex.
Con i Serverless Tasks si definisce una pianificazione e Snowflake esegue automaticamente la query sulle risorse di compute che gestisce. Si paga al secondo solo per il tempo di compute effettivamente utilizzato.
Con Serverless Tasks Flex si forniscono sia una pianificazione sia un SLA che definisce il tempo massimo di esecuzione del task (ossia entro quanto deve terminare rispetto all'orario di avvio pianificato). Snowflake utilizzerà questi due parametri per individuare il momento più economico in cui eseguire il task, garantendone comunque il completamento entro lo SLA specificato (per esempio 3 ore).

Snowpark Container Services nelle Native Apps ora in Public Preview
Snowflake ha annunciato che gli sviluppatori di native app possono ora sfruttare Snowpark Container Services nelle proprie applicazioni, permettendo di sviluppare ed eseguire interamente in Snowflake UI più ricche (per esempio React/Javascript personalizzati) e applicazioni complesse.
È un annuncio di grande peso per i partner Snowflake, perché permetterà ad aziende come SELECT di offrire i propri prodotti in modo più sicuro e integrato.

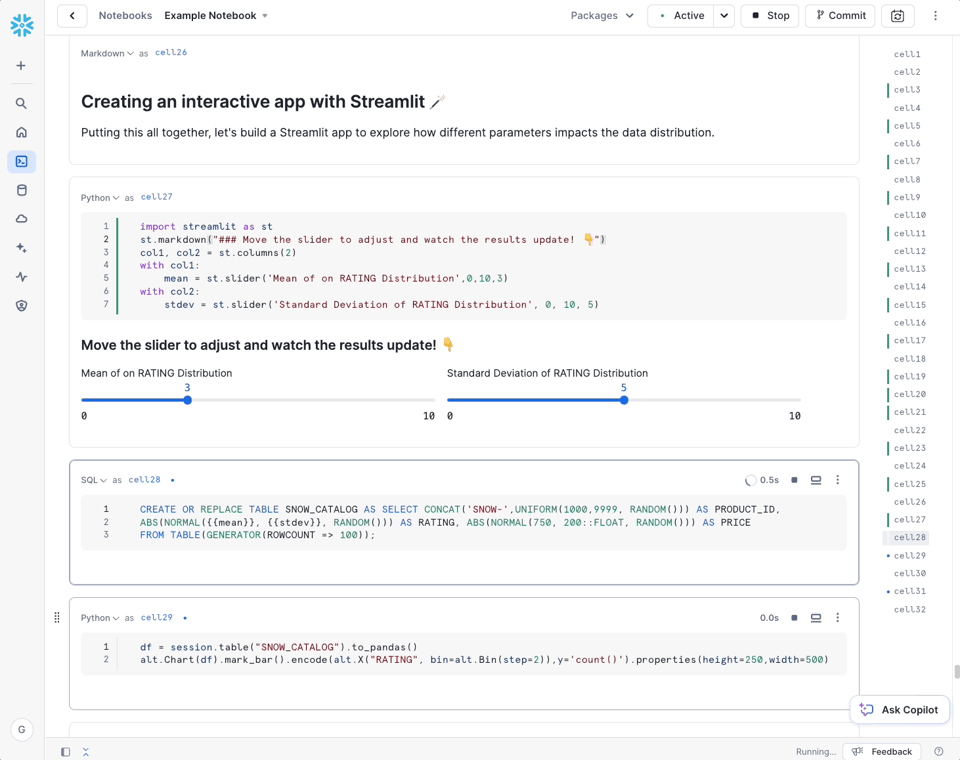
Snowflake Notebooks in Public Preview
Snowflake ha annunciato che la funzionalità Notebooks è ora in Public Preview. I Notebooks permettono di combinare Python, SQL e Markdown per creare report, job o eseguire analisi ad hoc.
È inoltre possibile pianificare l'esecuzione dei notebook su un virtual warehouse o su un container Snowpark. Snowflake ha anche annunciato un Copilot in linea per i notebook (attualmente in public preview).
Annunci di Snowflake Horizon
Snowflake Horizon è la suite di funzionalità Snowflake dedicate a data governance, discoverability, sicurezza e privacy. Sono stati presentati diversi annunci legati a Horizon:
- Universal Search
- Table Governance Views
- AI-Powered Object Descriptions
- Data Lineage Visualization per tabelle e view
- ML Lineage Visualization
- Trust Center
- Marketplace interno
Mi soffermerò su alcune di queste novità che credo saranno più significative per la maggior parte degli utenti Snowflake.
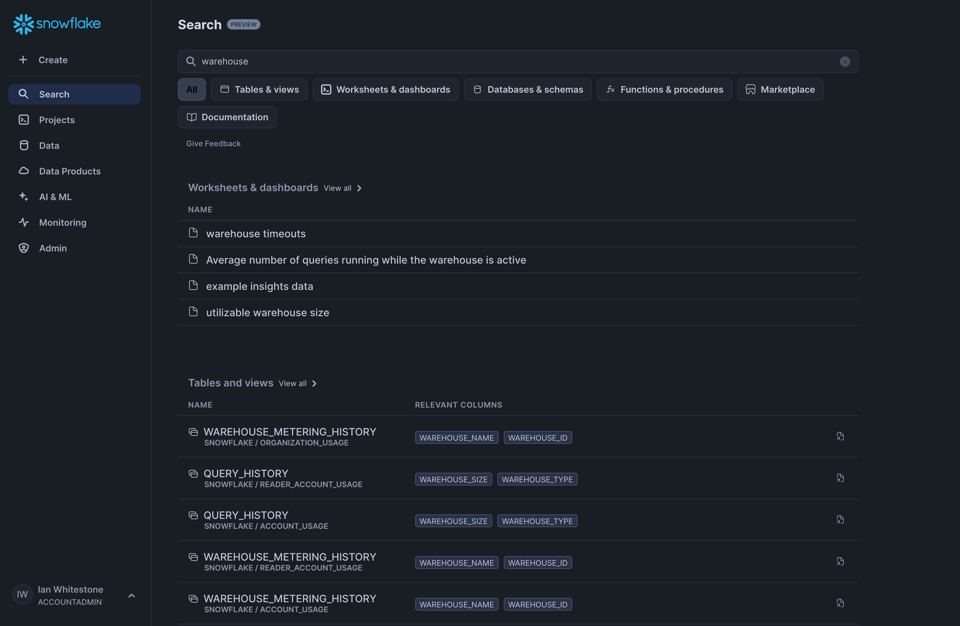
Universal Search ora in General Availability
Search, accessibile dalla UI, permette di cercare tutto ciò che è presente in Snowflake, dai dati interni al marketplace. La ricerca è basata sulla tecnologia del motore di Neeva, acquisita da Snowflake nel 2023.
Ecco un esempio dal nostro account Snowflake:
Tab Table Governance in Public Preview
Nella pagina della tabella, Snowflake ha mostrato un nuovo tab Governance con le informazioni sulle principali query, sugli utenti e sui ruoli che accedono a una tabella. Sarà utile a chi vuole capire chi sta usando una tabella e come.
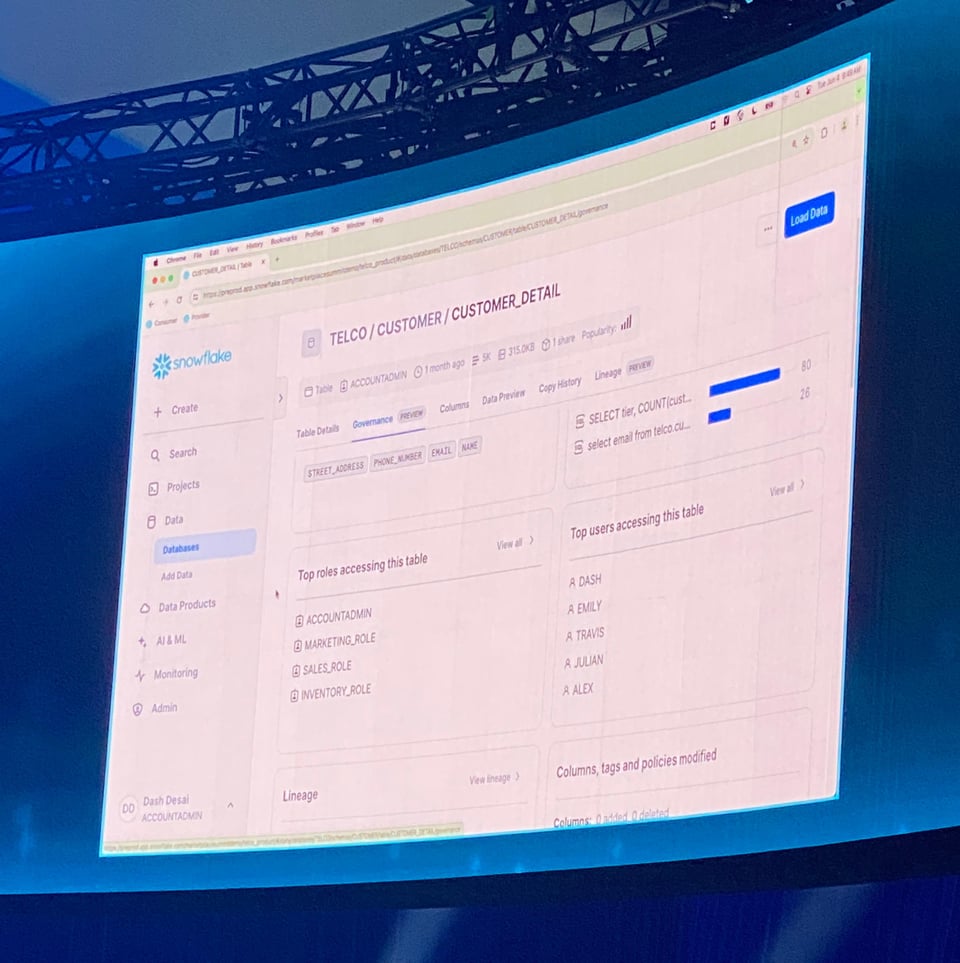
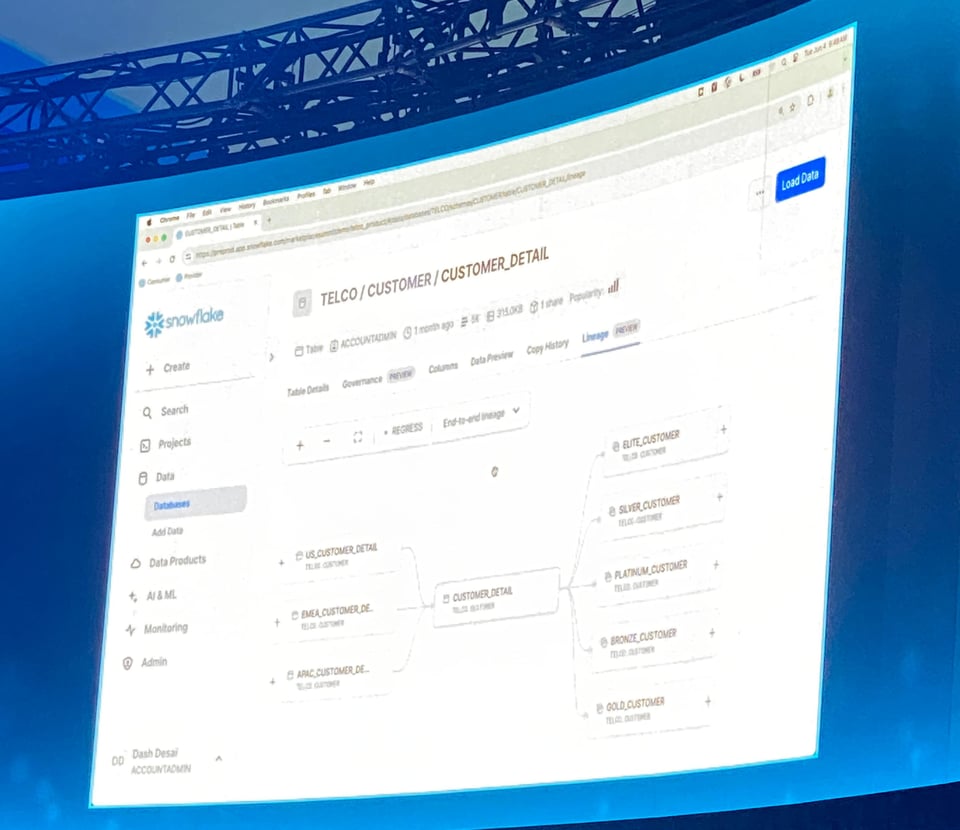
Table Lineage in Private Preview
Snowflake ha mostrato una nuova vista Table Lineage nella pagina della tabella, che evidenzia le dipendenze upstream e downstream di view e tabelle.
È una delle funzionalità più richieste tra quelle offerte dagli strumenti di Data Catalog e Observability, quindi è ottimo vedere Snowflake renderla disponibile a tutti i clienti.
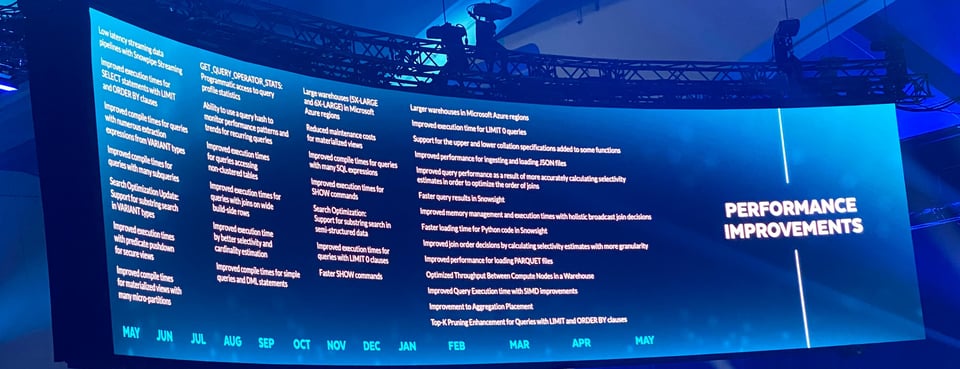
Vari miglioramenti delle performance
Per chi è interessato all'ottimizzazione delle query, Snowflake ha messo in evidenza una serie di miglioramenti delle performance rilasciati negli ultimi 12 mesi. Avvengono tutti dietro le quinte e migliorano silenziosamente l'esperienza di sviluppatori e utenti per tutti i clienti Snowflake.
Connettori nativi per Postgres e MySQL
Sulla scia del successo dei recenti connettori nativi — lo Snowflake Connector for Kafka e i connettori per applicazioni SaaS come ServiceNow e Google Analytics — Snowflake ha annunciato che i connettori nativi per Postgres e MySQL saranno presto in public preview. Permetteranno ai clienti di replicare facilmente dati CDC dai database aziendali interni verso Snowflake con latenza molto bassa e, soprattutto, senza pagare un fornitore terzo per ogni riga caricata.
Sarà interessante capire cosa significherà per aziende come Fivetran. A mio parere, probabilmente oltre la metà del loro fatturato deriva dalla replica di dati Postgres e MySQL. Snowflake ha dichiarato che in futuro svilupperà altri connettori per i principali database, quindi la cannibalizzazione dei ricavi può andare in una sola direzione: in aumento.
Snowflake Trail in Private Preview
Snowflake continua a investire in profondità nelle funzionalità di observability, sia per i dati sia per lo sviluppo applicativo.
Quest'anno al Summit è stato annunciato Snowflake Trail, un insieme di funzionalità che permette agli sviluppatori di monitorare meglio pipeline, app, codice utente e utilizzo del compute, individuarne i problemi, fare debug e intervenire di conseguenza.
Snowflake Trail si basa sulle Event Tables e aiuta gli utenti a ottenere automaticamente una migliore visibilità sulle performance del codice Snowpark e sull'utilizzo delle risorse.
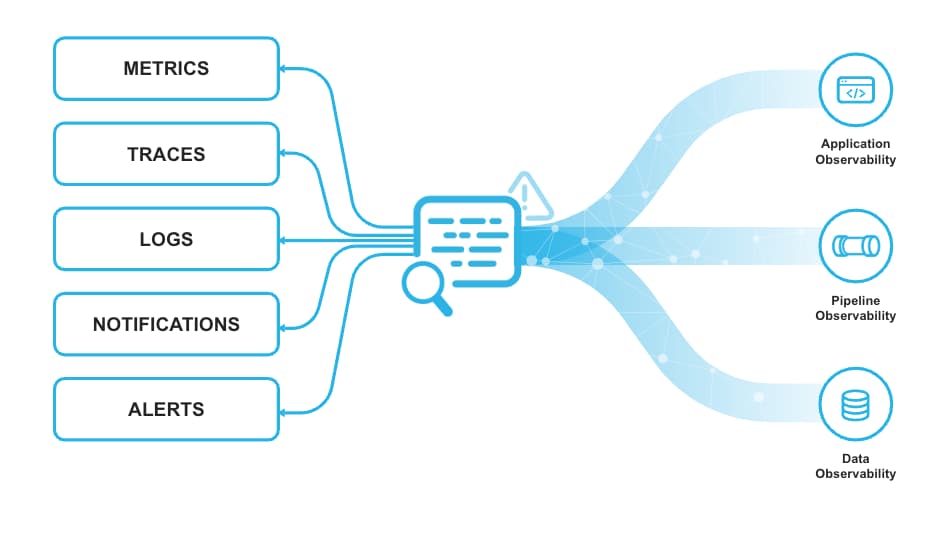
Snowflake Trail è conforme alla specifica OpenTelemetry e può quindi essere integrato facilmente con tecnologie partner. Disporrà inoltre di una UI di base sopra le event table.
API Snowpark pandas
A fine 2023 Snowflake ha acquisito Ponder per rafforzare le proprie capacità Python.
Come risultato di questa acquisizione, Snowflake ha rilasciato una nuova API Snowpark pandas che permette agli utenti Python di eseguire il proprio codice pandas sul compute di Snowflake in modo parallelizzato, eliminando i tipici limiti di pandas su volumi di dati e performance.
Gli utenti possono ora scrivere normale codice pandas e farlo eseguire automaticamente, dietro le quinte, come SQL Snowflake, ottenendo performance molto migliori e la capacità di gestire dataset più grandi della memoria disponibile.
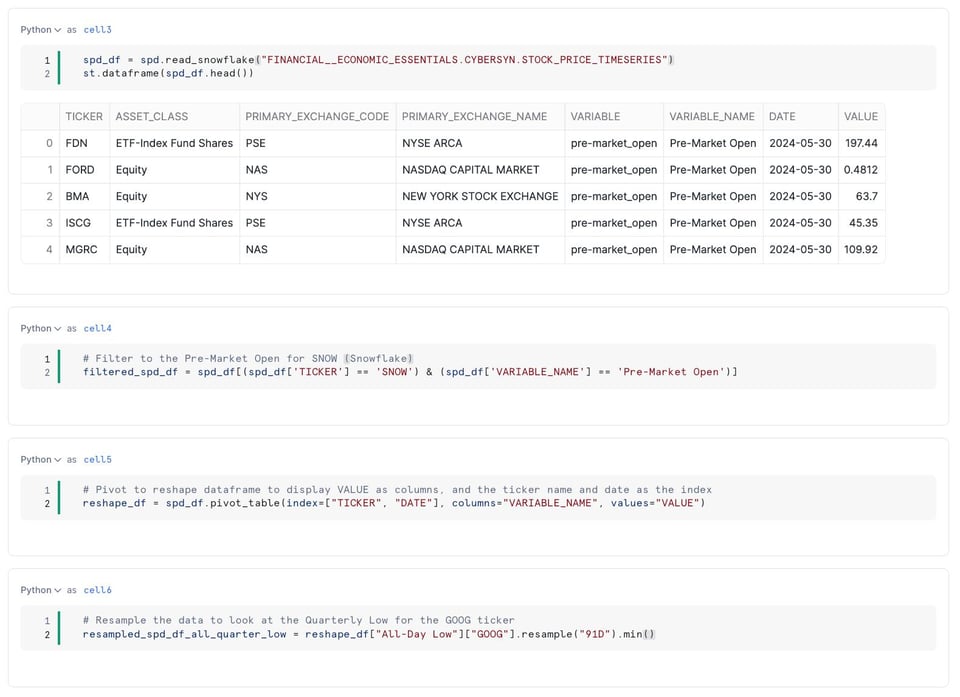
Sotto il cofano, il codice pandas viene tradotto in query SQL i cui risultati vengono poi restituiti come oggetti Python nativi. Davvero notevole!
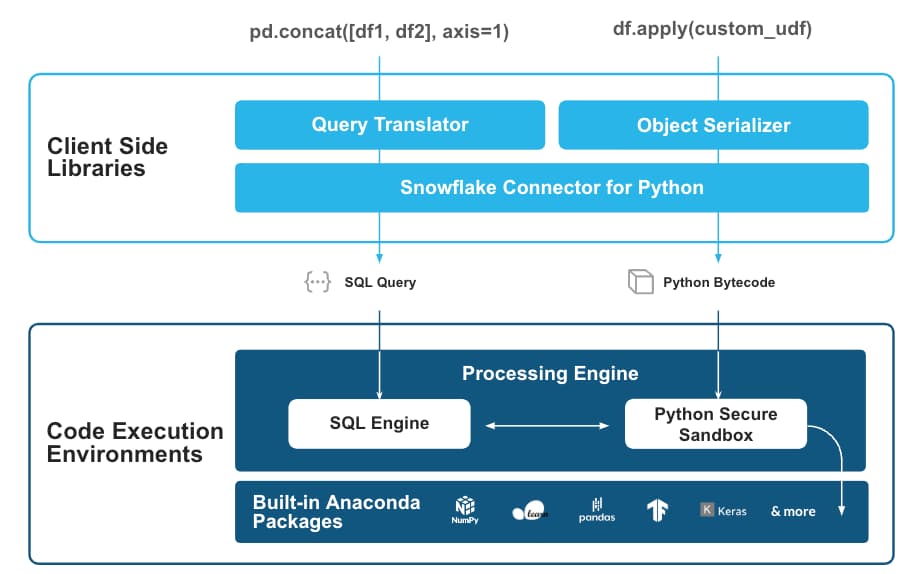
Immagini tratte dall'annuncio di Snowflake: https://www.snowflake.com/blog/snowpark-pandas-api-run-at-scale/
Snowflake Cortex
Snowflake Cortex è la suite di strumenti e funzionalità AI di Snowflake. Cortex offre l'accesso a diversi LLM, tra cui quelli di Mistral, Reka, Meta, Google e Snowflake Arctic.
Al Summit, Snowflake ha annunciato 3 nuove funzionalità nell'ambito della suite Cortex.
Cortex Finetuning (Public Preview)
Cortex Finetuning è ora in Public Preview e permette di addestrare modelli Foundational LLM direttamente dalla UI.
La maggior parte degli LLM pronti all'uso non è adatta all'utilizzo in azienda, dato che non conosce dati o sistemi interni. Con il fine-tuning, le aziende possono addestrare modelli più pertinenti per i propri casi d'uso interni.
Cortex Analyst (Private Preview)
Cortex Analyst, attualmente in private preview, è un servizio LLM serverless e altamente accurato che permette ai business user di porre una domanda e ricevere una vera risposta, non solo testo SQL.
È uno dei principali casi d'uso dell'AI di cui si parla nel settore. Fornendo a un LLM tutta la conoscenza semantica e i metadati del proprio data warehouse, oltre alla capacità di eseguire direttamente query SQL e interpretarne i risultati, si ottiene qualcosa di estremamente prezioso.
Cortex Analyst sarà alimentato da un file YAML che definisce elementi come lo schema dei dati, le metriche e i sinonimi per controllarne ambito e accuratezza. Siamo molto curiosi di vedere come evolverà questa funzionalità. Vista la complessità di costruire un sistema simile e le implicazioni business legate alle risposte ottenute, mi aspetto che ci vorrà del tempo prima che gestisca volumi significativi di vere richieste dati dal business.
Cortex Search (Private Preview)
Cortex Search, anch'esso in private preview, è un servizio di ricerca ibrida (Vector + Keywords) serverless basato su LLM che estrae in modo incrementale dati da documenti, tabelle e view, suddividendoli automaticamente in chunk e vettorializzandoli per query veloci (< 200 ms) e prestazioni di ricerca molto accurate.
Durante il keynote del Summit è stato fatto salire sul palco un membro del pubblico scelto a caso. La persona si era collegata a Snowflake solo poche volte ed è riuscita a ottenere un servizio funzionante in meno di 5 minuti, semplicemente cliccando nella UI.
Durante la demo ha selezionato uno stage precaricato con alcuni PDF di esempio e, in pochi minuti, le è stata presentata un'interfaccia di chat in cui poteva porre domande e ricevere dall'LLM risposte basate direttamente sul contenuto di quei PDF.
Dark Mode!!
A chiusura del keynote, Snowflake ha annunciato che una delle funzionalità più richieste, la Dark Mode, è ora disponibile per tutti i clienti. Potete guardare il video qui.
Da allora la uso sempre e sono molto soddisfatto del look and feel!
Considerazioni finali
Anche se non ci sono stati annunci di piattaforma rivoluzionari quanto quelli degli anni passati come Native Apps o Snowpark Container Services, il Summit 2024 ha messo in chiaro alcuni punti:
- Il ritmo con cui le nuove funzionalità vengono rilasciate e portate in general availability è accelerato in modo significativo. Anche se non abbiamo visto un singolo annuncio rivoluzionario paragonabile per portata al lancio dell'app store di Snowflake o a un modo nuovo e fondamentale di eseguire i workloads (Snowpark Container Services), si è avuta la sensazione di aver ricevuto molto di più, su tutti i fronti.
- Snowflake sta offrendo ai propri clienti più funzionalità pronte all'uso, riducendo la necessità di acquistare strumenti di terze parti tipicamente richiesti per gestire un data warehouse. L'azienda ha rafforzato gli investimenti in data quality e data governance, tutti i clienti avranno presto la data lineage (la funzionalità più richiesta dei data catalog), c'è una nuova ed eccellente funzionalità Notebooks e stanno per uscire connettori nativi gratuiti per Postgres e MySQL (addio Fivetran?).
- AI e ML sono l'area di principale focus per Snowflake. Lo si è capito sempre più chiaramente anche dalle call con gli investitori, dato che il mercato si aspetta che questi nuovi workloads (insieme a Snowpark) costituiscano una quota significativa del fatturato nei prossimi 5 anni. Oggi la gran parte dei ricavi di Snowflake (a mio giudizio oltre il 90%) deriva dai tradizionali workloads di data warehousing e business intelligence. Al Summit sono state mostrate molte funzionalità interessanti. Se manterranno quanto visto sul palco, non c'è dubbio che avranno un impatto enorme su molte organizzazioni, accelerando l'adozione dell'AI.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è co-founder e CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, Ian ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify, Ian ha coordinato gli interventi per ottimizzare il data warehouse e aumentare l'observability sui costi.