2022年、Snowflakeは新しいNative ApplicationフレームワークとHybrid Tables(発表当初はUnistoreという名称)という大型発表を打ち出しました。昨年もSnowpark Container ServicesやIcebergサポートの追加など、注目の新機能を次々と発表し、高い水準を維持しています。
過去2回のSummitに参加してきたNiallと私は、Snowflakeの開発スピードに毎回圧倒されてきました。Summit 2024を終えた今も、その印象は変わりません。
では、さっそく見ていきましょう。

発表内容まとめ
お時間のない方のために、今回の発表内容を簡単な解説とともに一覧でご紹介します。
データエンジニアリング
- 90日以内にPolaris Catalogをオープンソース化。顧客が自社でIcebergカタログをホストでき、各種コンピュートエンジン間の相互運用性も向上します。
- Serverless Tasks Flex。タスクの実行タイミングに柔軟性を持たせることで、最大42%のコスト削減を実現します(Private Preview)。
- イベント駆動型タスクがPublic Previewに。Snowflake Streamが更新されるたびにタスクを自動実行できます。
- Low Latency TasksがPrivate Previewに。タスクのスケジューリング間隔を最短15秒まで短縮できます。
- Iceberg TablesがGA(一般提供)に。データをクラウドストレージ上のparquetファイルとして保存しつつSnowflakeからクエリできる、オープンソースのテーブルフォーマットです。
- Dynamic TablesがGAに。SQLのSELECT文を使った宣言的なアプローチで、増分変換やシンプルなデータパイプラインを構築できます。
- Data Quality Monitoring:Snowflakeが標準提供するシステムメトリクス(NULL件数など)に加え、顧客が独自に定義してテーブルで自動測定できるカスタムメトリクスにも対応。本機能はPublic Previewで、Enterprise以上のエディションでのみ利用可能です。
- PostgresおよびMySQL向けのネイティブコネクタが間もなくPublic Previewに。社内データベースからSnowflakeへ極めて低レイテンシでCDCデータを簡単にレプリケートでき、何より重要なのは、ロードした行数ごとにFivetranなどのサードパーティに料金を支払う必要がない点です。
アナリスト・開発者向けツール
- Snowflake NotebooksがPublic Previewに。データチームやAIチーム向けに、エンドツーエンドのインタラクティブなUI環境を提供します。
- SnowflakeはSnowflake Trailのローンチとあわせて、新たな可観測性機能群を発表。開発者やパートナーがデータパイプラインを監視・デバッグするためのツールが大幅に拡充されます。
- Snowpark Container Services(SPCS)がGAに。Snowflakeユーザーは、コンテナ経由であらゆるworkloadsをSnowflake上で安全に実行できます。
- これに伴い、SPCSがNative Apps Frameworkに対応(Public Preview)。パートナーがリッチなアプリケーションを構築・デプロイできるようになります。
- Snowflake独自のCopilotが間もなくGAに。アナリストやビジネスユーザーが、Snowflake UI上で自然言語からSQLクエリを自動生成できます。
- SnowflakeのGit統合がPublic Previewに。GitHub/GitLab/BitbucketとSnowflakeの間でファイルを同期でき、バージョン管理が容易になります。
データガバナンス・セキュリティ
- 新たな社内向けマーケットプレイス(Private Preview)。大規模な組織やチームが、データセット、アプリ、ノートブックなどを社内限定で共有できます。
- 新たなTable Governance Views(Public Preview)。Snowflakeアカウント内の各テーブルにアクセスしている上位のロールとユーザーを表示します。
- SnowflakeのTrust Centerが間もなくGAに。セキュリティリスクを検出し、解消に向けた推奨事項を提示するUIです。
- Universal SearchがGAに。Snowflake上のすべてのアセットを、UIから素早く検索・発見できます。
- UI上の新たなData Lineage Visualization(現在Private Preview)を披露。すべてのテーブルとビューについて、上流・下流の依存関係を確認できます。
- AIによるオブジェクト記述機能を発表。テーブルやビューに関連するコンテキストやコメントをAIが自動付与します。
エンタープライズAI・ML
- 新たなSnowpark pandas APIをリリース。PythonユーザーはpandasコードをSnowflakeコンピュート上で並列実行でき、データ量やパフォーマンスにまつわるpandas特有の制約から解放されます。
- Document AIが間もなくGAに。サーバーレスのLLMベースのドキュメント処理機能で、非構造化ビジネス文書(PDF、画像、Wordなど。請求書、契約書、製品試験成績書など)から構造化データを抽出できます。詳しくはこちら。
- Snowflake Feature StoreがPublic Previewに。UIまたはSnowpark ML APIから、バッチ・ストリーミングデータに対してMLフィーチャーを継続的かつ自動的にリフレッシュしながら、作成・管理・提供できます。詳しくはこちら。
- Snowflake Model RegistryがGAに。UIまたはSnowpark ML APIを介して、AI/MLモデルとそのメタデータをSnowflakeネイティブに管理・追跡・バージョニング・共有できる統合ソリューションです。詳しくはこちら。
- Snowsight AI & ML StudioがGAに。さまざまなMLおよびAIモデル・パイプラインを手軽に作成できるUIを提供します。
- Cortex FinetuningがPublic Previewに。基盤LLMモデルをUIから直接ファインチューニングできます。
- Cortex Analyst(現在Private Preview)はサーバーレスかつ高精度なLLMサービス。ビジネスユーザーが質問すると、SQL文ではなく実際の回答を返します。データスキーマ、メトリクス、シノニムなどを定義するYAMLファイルによって、対象範囲と精度を制御する仕組みです。
- Cortex Search(同じくPrivate Preview)はサーバーレスのLLMベースのハイブリッド検索サービス(ベクトル+キーワード)。ドキュメント、テーブル、ビューからデータを増分的に抽出し、自動でチャンク分割・ベクトル化することで、200ms未満の高速クエリと高精度な検索を実現します。
かなりのボリュームですね。ここから先は、Snowflakeの方向性について語られた内容と、主要な発表のいくつかについて、その影響も含めて掘り下げていきます。
オープニングとSnowflakeの哲学
Summitキーノートの冒頭、SridharとBenoitはSnowflakeプラットフォームの中核となる原則を改めて打ち出しました。Snowflakeは「一つのエンジンの上に構築された一つのプラットフォーム」であり、そして何より「ただ動く」こと。シンプルさを保ち、同じことを20通りのやり方で実現させるような作りにはしない、というメッセージです。この点は、翌週Databricks Summitに参加して同社製品の複雑さを目の当たりにするまで、正直あまりピンと来ていませんでした。
Snowflakeは最近、「Data Cloud」から「AI Data Cloud」へとリブランドしましたが、オープニングの大半は、エンタープライズAIに必要なものをすべて提供するプラットフォームである、というメッセージに割かれていました。
- データ。Snowflakeは高性能なネイティブストレージを提供する一方、データを自社で完全にコントロールしたい、あるいは他のコンピュートエンジン(SparkやTrinoなど)からもアクセスしたい顧客のために、オープンなIcebergフォーマットもサポートしています。
- コンピュート。SQLクエリで主に使われるSnowflakeのvirtual warehousesはおなじみでしょう。Snowflakeでは社内的に、このvirtual warehouseの技術を「データフローエンジン」と呼んでいます。SQLだけでなく、すべての言語(Java、Python、Scala)がこのエンジンにプッシュダウンされます。さらにSnowpark Container Servicesによって、より柔軟なコンピュートの選択肢も提供されており、ユーザーは任意のアプリケーションやworkloadsをセキュアなコンテナで実行できます(Dockerで動くものなら、Snowflakeでも動く、と考えてください)。
- AI、本日の最大のテーマです。Cortexにより、Snowflake顧客はAIアプリケーションの利用・構築を簡単にする一連のツールを使えるようになります。さらに、エンタープライズのユースケース向けにSnowflakeが設計した新たなLLMファミリー「Arctic」についても触れられました。
- セキュリティ、ガバナンス、コラボレーション。Snowflakeは長年、堅牢なセキュリティ保証、扱いやすいガバナンス、強力なアクセス制御で知られてきました。一般的なユーザーが日常的に意識する部分ではないかもしれませんが、これらの機能や保証はあらゆる企業にとって不可欠な土台です。
Polaris Catalogと業界全体の相互運用性向上
今回最も話題を呼んだ発表の一つは、Summit開幕の数日前に飛び出した、SnowflakeがIcebergカタログのPolarisをオープンソース化するというニュースでした。これが重要な理由の一つは、クラウドプラットフォームをまたいだIcebergデータレイクの使い勝手と相互運用性が大きく高まる点にあります。

もう一つ大きな話題となった背景には、ほぼ同時にDatabricksがTabularの買収を発表したことがあります。Tabularは、Icebergの開発を主導した創設者およびキーパーソンたちが立ち上げた企業です。
これは明らかに、DatabricksがIcebergをファーストクラスでサポートしていくことを意味します。そしてSnowflake側もいずれDelta Lakeのサポートを追加し、追随していくと予想されます。最も人気のあるオープンソースのデータフォーマット2つを、事実上一社が「所有」するという構図には少々落ち着かないものを感じますが、結果的にはすべてのクラウドデータプラットフォームがよりオープンなデータフォーマットへの対応を迫られることになり、顧客にとって大きなメリットになるはずです。
これに関連して、SnowflakeはMicrosoft Fabricとのパートナーシップの大幅な拡大も発表しました。Fabricの中核にあるOneLakeは、これまでDelta LakeベースのparquetファイルでしたMicrosoftがIcebergをサポートするようになり、SnowflakeはOneLakeと統合される予定です。
Icebergになぜ別途カタログが必要なのか気になる方は、Icebergのドキュメントにある以下の一節が参考になります。
Icebergは単一テーブルのデータを管理するためのフォーマットと捉えてかまいませんが、Icebergライブラリにはそうしたテーブルを名前で追跡する仕組みが必要です。テーブルの作成・削除・リネームといった操作はカタログの責務であり、カタログは通常ネームスペースにまとめられた一連のテーブルを管理します。カタログの最も重要な役割は、テーブルの現在のメタデータを追跡することで、これはテーブルをロードする際にカタログから提供されます。
Icebergプロジェクトはカタログ自体を提供せず、カタログが果たすべき役割や、Icebergとどのように連携するかという標準だけを定めてきました。いかにもSnowflakeらしく、欠けていたピースを自ら提供することで、Icebergのような複雑な技術の導入ハードルを一気に下げに来ているわけです。
Serverless Tasks FlexがPrivate Previewに
Snowflakeのコスト最適化に関心がある方には朗報です。Snowflakeは、Serverless Tasks Flexという興味深い新機能を発表しました。
Serverless Tasksでは、スケジュールを定義すれば、Snowflakeが管理するコンピュートリソース上でクエリが自動的に実行されます。料金は実際に使用したコンピュート時間に対して、秒単位で課金されます。
Serverless Tasks Flexでは、スケジュールに加えて、タスクの最大実行時間を定めるSLA(スケジュールされた開始時刻からどれくらいで完了させる必要があるか)も指定します。Snowflakeはこの2つの入力をもとに、指定されたSLA(例:3時間)内に確実に完了する形で、最も安く実行できるタイミングを見つけ出します。

Native AppsでSnowpark Container ServicesがPublic Previewに
Snowflakeは、ネイティブアプリ開発者がアプリケーション内でSnowpark Container Servicesを活用できるようになったと発表しました。これにより、よりリッチなUI(独自のReact/JavaScriptなど)や複雑なアプリケーションを、丸ごとSnowflake上で構築・実行できます。
これはSnowflakeパートナーにとって極めて大きな発表でした。SELECTのような企業が、よりセキュアでシームレスな形で製品を提供できるようになります。

Snowflake NotebooksがPublic Previewに
SnowflakeはNotebooks機能がPublic Previewになったと発表しました。NotebooksではPython、SQL、Markdownを組み合わせて、レポート作成、ジョブの実行、アドホック分析などが行えます。
ノートブックはvirtual warehouseやSnowparkコンテナ上でスケジュール実行することも可能です。あわせて、ノートブック向けのインラインCopilot(現在Public Preview)も発表されました。
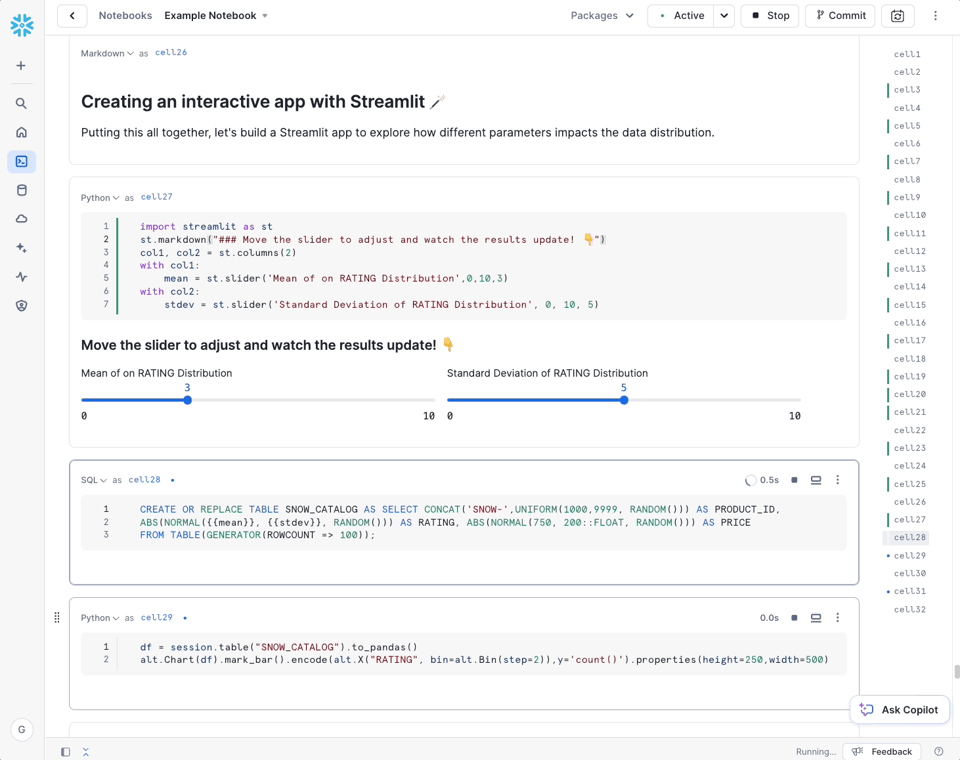
Snowflake Horizon関連の発表
Snowflake Horizonは、データガバナンス、ディスカバリ、セキュリティ、プライバシーに関連する機能群です。Horizonまわりではさまざまな発表がありました。
- Universal Search
- Table Governance Views
- AIによるオブジェクト記述
- テーブル・ビューのData Lineage Visualization
- ML Lineage Visualization
- Trust Center
- 社内向けマーケットプレイス
このなかから、多くのSnowflakeユーザーにとって特に重要だと思われるものをいくつか取り上げます。
Universal SearchがGAに
UIから利用できるSearchでは、社内データからマーケットプレイスに至るまで、Snowflake上のあらゆるものを横断的に検索できます。Searchは、Snowflakeが2023年に買収したNeevaの検索エンジン技術を基盤としています。
当社のSnowflakeアカウントでの例がこちらです。
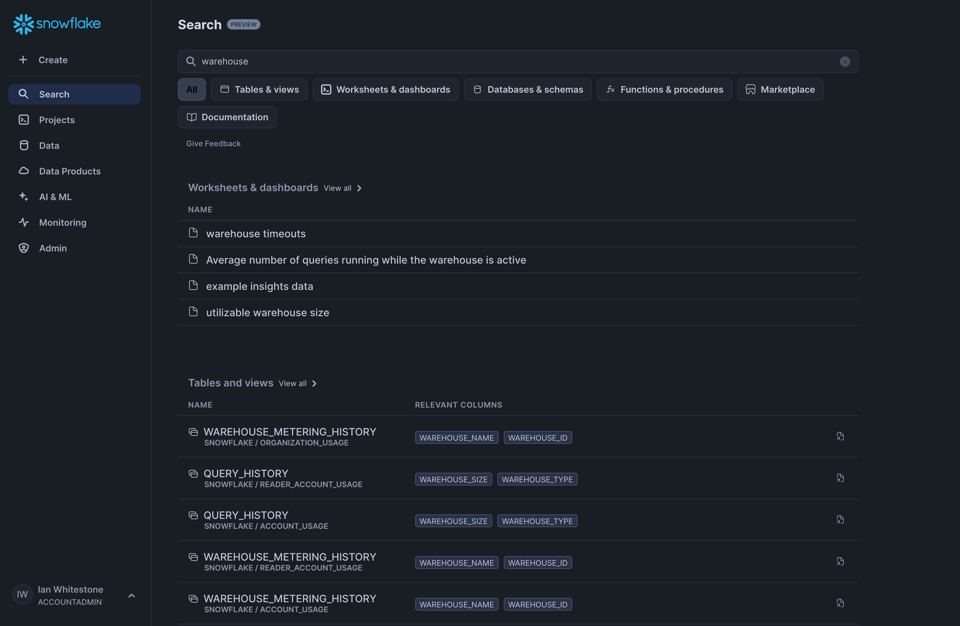
Table Governance TabがPublic Previewに
Snowflakeは、テーブルページ上に新たなGovernanceタブを披露しました。そのテーブルにアクセスしている上位のクエリ、ユーザー、ロールに関する情報がまとまっており、誰がどのようにテーブルを使っているかを把握したいユーザーにとって便利な機能です。
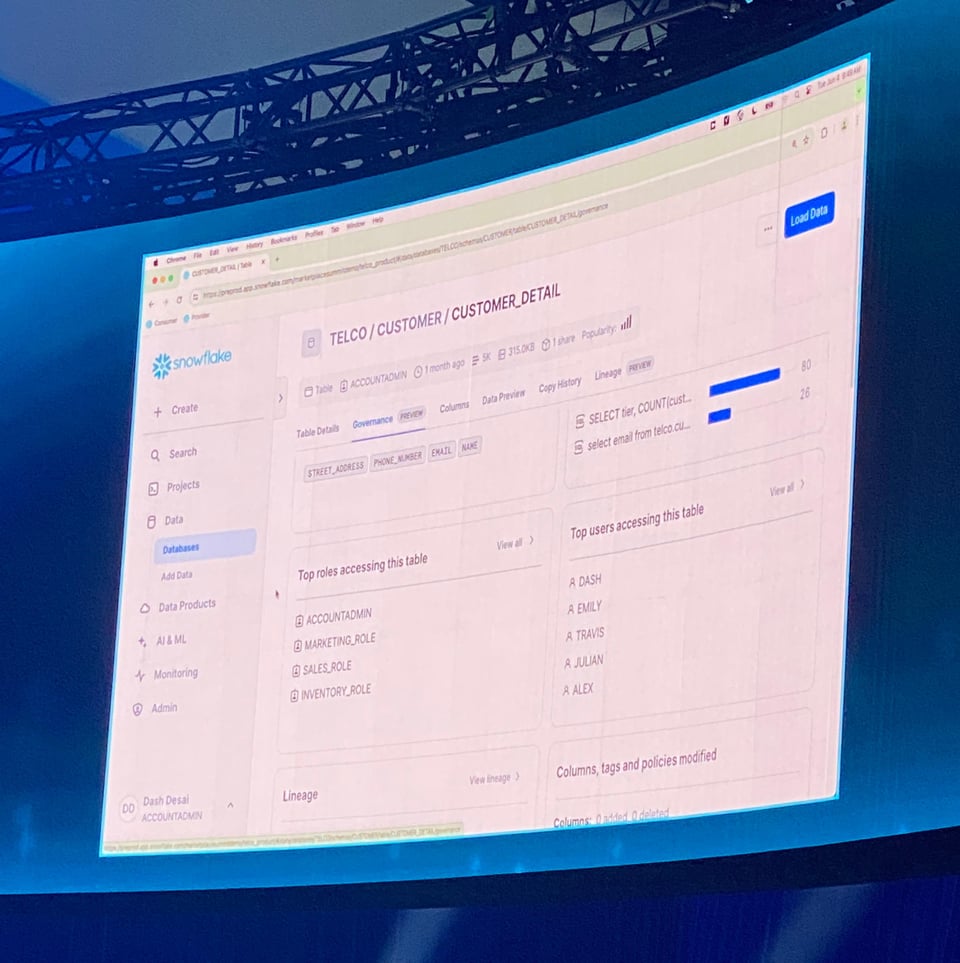
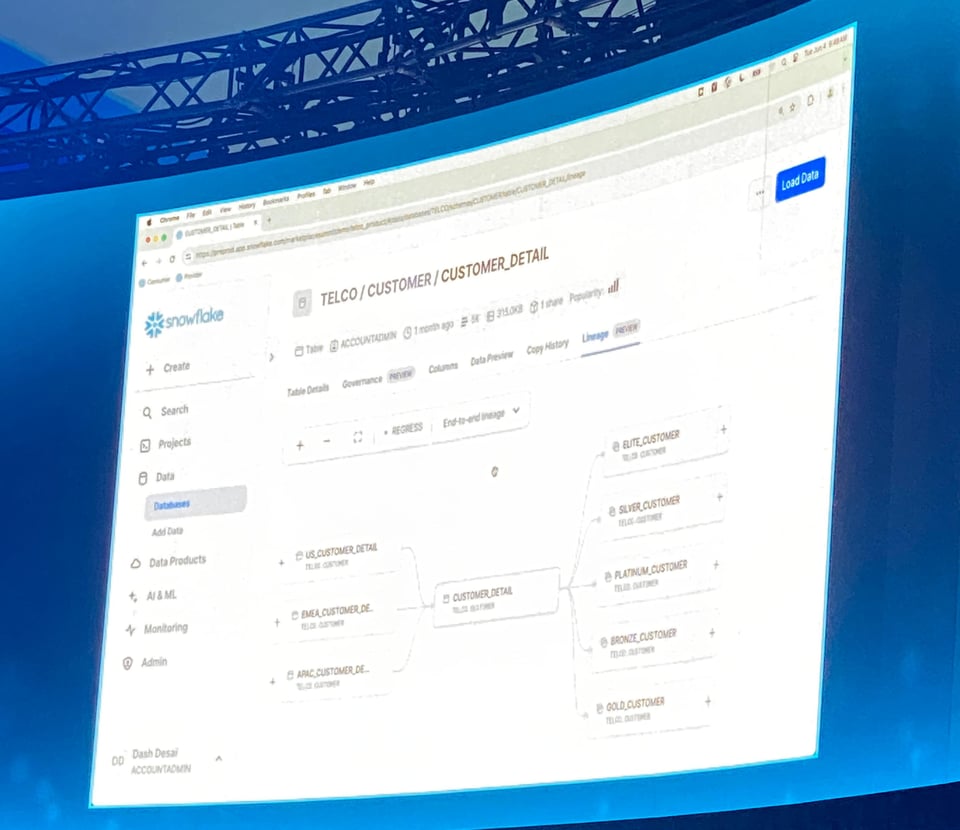
Table LineageがPrivate Previewに
Snowflakeは、テーブルページ上に新たなTable Lineageビューも披露しました。ビューやテーブルについて、上流・下流の依存関係を確認できます。
これはData Catalogや可観測性ツールが提供する機能のなかでも特に人気の高い機能の一つで、Snowflakeがこれをすべての顧客に提供してくれるのは非常にありがたいことです。
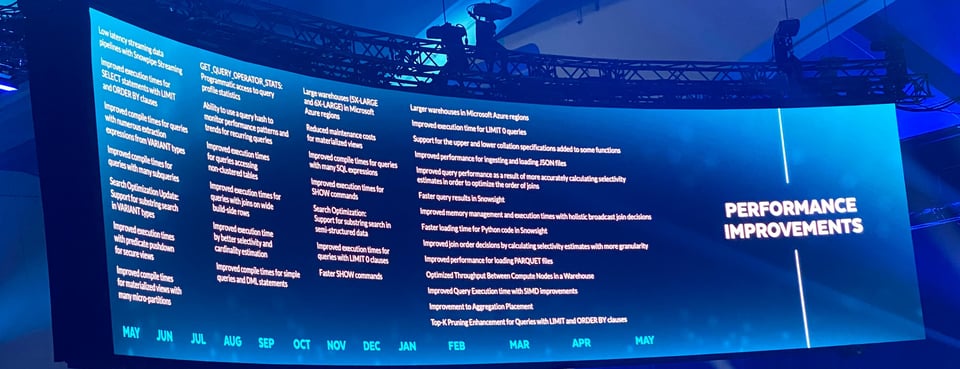
各種パフォーマンス改善
クエリ最適化に関心のある方に向けて、Snowflakeは過去12か月間にリリースしてきた数々のパフォーマンス改善を紹介しました。いずれも舞台裏で動作し、すべてのSnowflake顧客の開発者体験・ユーザー体験を静かに底上げしてくれるものです。
PostgresおよびMySQL向けのネイティブコネクタ
近年リリースされたSnowflakeネイティブコネクタ — Snowflake Connector for Kafkaや、ServiceNow、Google AnalyticsなどSaaS向けコネクタ — の好調を受けて、SnowflakeはPostgresおよびMySQL向けのネイティブコネクタが間もなくPublic Previewに入ると発表しました。これにより顧客は、社内データベースからSnowflakeへ極めて低いレイテンシでCDCデータを簡単にレプリケートでき、そして何より、ロードした行数ごとにサードパーティに料金を支払う必要がなくなります。
これがFivetranのような企業にとって何を意味するのか、注目すべきところです。あくまで推測ですが、同社の売上の半分以上はおそらくPostgresとMySQLのデータレプリケーションが占めているのではないでしょうか。Snowflakeは今後、他の主要データベース向けにもコネクタを開発していく方針を示しており、収益の侵食は今後増えていく一方でしょう。
Snowflake TrailがPrivate Previewに
Snowflakeは、データとアプリケーション開発の両面で、可観測性機能への投資をさらに深めています。
今年のSummitでは、Snowflake Trailを発表しました。開発者がパイプライン、アプリ、ユーザーコード、コンピュート使用状況について、より深く監視・トラブルシューティング・デバッグし、アクションを取れるようにするためのSnowflake機能群です。
Snowflake TrailはEvent Tablesを基盤としており、Snowparkコードのパフォーマンスやリソース使用状況の可視性を自動的に高めてくれます。
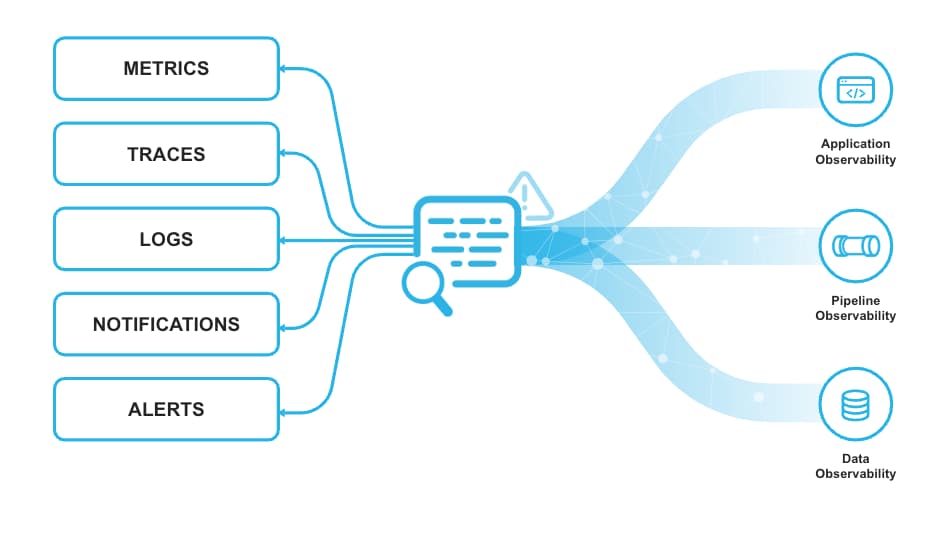
Snowflake TrailはOpenTelemetry仕様に準拠しており、パートナー製品とも容易に統合できます。Event Tablesの上に乗るシンプルなUIも提供される予定です。
Snowpark Pandas API
2023年後半、SnowflakeはPonderを買収し、Python関連の機能を強化しました。
この買収を受けて、Snowflakeは新たなSnowpark pandas APIをリリースしました。PythonユーザーはpandasコードをSnowflakeコンピュート上で並列実行でき、データ量やパフォーマンスにまつわるpandas特有の制約を解消できます。
ユーザーは通常のpandasコードを書くだけで、その処理が裏側で自動的にSnowflake SQLとして実行されます。これにより、パフォーマンスが大幅に向上するとともに、メモリに収まらない大規模データセットも扱えるようになります。
仕組みとしては、pandasコードをSQLクエリに変換して実行し、その結果をネイティブのPythonオブジェクトとして返すというものです。とても面白い設計ですね。
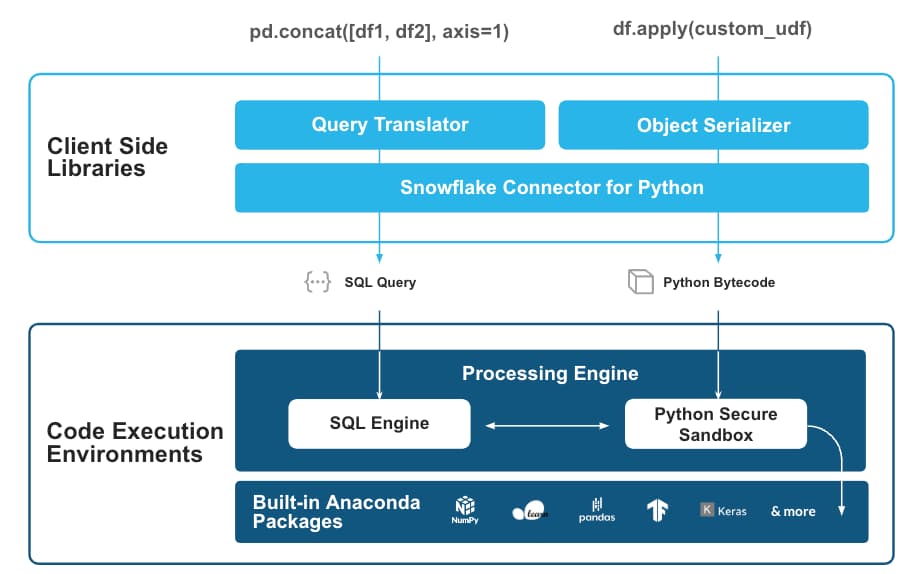
画像はSnowflakeの発表より引用:https://www.snowflake.com/blog/snowpark-pandas-api-run-at-scale/
Snowflake Cortex
Snowflake Cortexは、SnowflakeのAI関連ツールと機能を束ねたスイートです。Cortexを通じて、Mistral、Reka、Meta、Google、そしてSnowflake Arcticなど、多様なLLMを利用できます。
SummitでSnowflakeは、Cortexスイートの一部として3つの新機能を発表しました。
Cortex Finetuning(Public Preview)
Cortex FinetuningがPublic Previewに。基盤LLMモデルをUIから直接ファインチューニングできます。
既製のLLMの多くは、企業の社内データやシステムについてまったく知らないため、そのままではほとんどの企業の業務には適しません。ファインチューニングを使えば、企業ごとの社内ユースケースにより適合したモデルを学習させることができます。
Cortex Analyst(Private Preview)
現在Private PreviewのCortex Analystは、サーバーレスで高精度なLLMサービスです。ビジネスユーザーが質問をすると、SQL文ではなく実際の答えが返ってきます。
これは、業界の多くの人が口を揃えてAIの代表的なユースケースとして挙げているものです。データウェアハウスのセマンティックな知識とメタデータをLLMに与え、さらにSQLクエリを直接実行して結果を解釈する力を与えてやれば、極めて価値の高いものができあがります。
Cortex Analystは、データスキーマ、メトリクス、シノニムなどを定義したYAMLファイルで対象範囲と精度を制御します。この機能が今後どのように進化していくか、非常に楽しみです。とはいえ、こうしたシステムを構築する難しさと、回答が業務に与えるインパクトの大きさを考えると、ビジネスからの実データに対する問い合わせを意味のある規模で捌けるようになるまでには、まだしばらく時間がかかるでしょう。
Cortex Search(Private Preview)
こちらもPrivate PreviewのCortex Searchは、サーバーレスのLLMベースのハイブリッド検索サービス(ベクトル+キーワード)です。ドキュメント、テーブル、ビューからデータを増分的に抽出し、自動でチャンク分割・ベクトル化することで、200ms未満の高速クエリと高精度な検索を実現します。
Summitのキーノートでは、観客のなかからランダムに選んだ一人をステージに招きました。その方はSnowflakeにこれまで数回しかログインしたことがありませんでしたが、UIをクリックしていくだけで、5分とかからずに動作するサービスを作り上げてしまいました。
デモでは、サンプルPDFがあらかじめ読み込まれたステージを選択し、わずか数分でチャットインターフェースが立ち上がり、質問を投げかけると、LLMがそれらのPDFの内容に基づいて回答する、という流れが披露されました。
ダークモード!!
キーノートの締めくくりに、Snowflakeは要望の特に多かった機能の一つであるダークモードを、すべての顧客向けに提供開始したと発表しました。動画はこちらからご覧いただけます。
それ以来ずっと使っていますが、見た目も使い心地もかなり気に入っています!
まとめ
Native AppsやSnowpark Container Servicesのような、過去のSummitで見られた基盤プラットフォームレベルの大型発表こそありませんでしたが、Summit 2024からはいくつかのことがはっきりと見えてきました。
- 新機能のリリースとGA化のペースが、これまでに比べて格段に上がっています。Snowflakeによるアプリストアの立ち上げや、workloadsの実行方法を根本から変える(Snowpark Container Servicesのような)単独の超大型発表こそ今回はありませんでしたが、全体として見ればはるかに多くのものが届けられた印象です。
- Snowflakeは、これまでサードパーティ製ツールに頼ることが多かったデータウェアハウス運用の機能を、より多く標準で提供するようになっています。データ品質とデータガバナンスへの投資がさらに深まり、すべての顧客が間もなくdata lineage(データカタログで最も人気のある機能)を使えるようになり、強力な新Notebooks機能も登場し、PostgresとMySQL向けの無料ネイティブコネクタも間もなくリリース予定です(Fivetran、さようなら?)。
- AIとMLは、Snowflakeにとって最重要のフォーカス領域です。これは投資家向け説明会でもますます明確になっており、市場はこれらの新しいworkloads(Snowparkとあわせて)が今後5年で売上の意味のある割合を占めることを期待しています。現時点では、Snowflakeの売上の大半(おそらく90%以上)は、従来型のデータウェアハウスとBIのworkloadsから生まれていると見ています。Summitでは数多くの印象的な機能のデモが披露されました。もしそれらがステージ上で見せたとおりの実力を発揮するなら、多くの組織でAI導入を加速させ、大きなインパクトを生むことは間違いないでしょう。
Ian Whitestone·Co-founder & CEO of SELECT
Ianは、Snowflakeのコスト管理・最適化を行うSaaSプラットフォームSELECTの共同創業者兼CEOです。SELECT創業以前は、ShopifyとCapital Oneにてフルスタックのデータサイエンス・エンジニアリングチームを6年間にわたって率いていました。Shopifyではデータウェアハウスの最適化とコスト可視化向上に向けた取り組みを主導しています。