En 2022, Snowflake avait marqué les esprits avec d'importantes annonces autour de son nouveau framework Native Application et des hybrid tables (initialement présentées sous le nom d'Unistore). L'année dernière, l'entreprise a maintenu un niveau d'exigence élevé en dévoilant de nouvelles fonctionnalités comme Snowpark Container Services, ainsi que la prise en charge d'Iceberg.
Ayant assisté aux deux derniers Summits, Niall et moi-même sommes toujours impressionnés par le rythme de développement de Snowflake. Après la clôture du Summit 2024, ce sentiment reste intact.
Entrons dans le vif du sujet.

Récapitulatif des annonces
Si vous manquez de temps, voici la liste complète des annonces accompagnées d'une brève explication.
Data Engineering
- Snowflake va passer Polaris Catalog en open source d'ici 90 jours, ce qui permettra aux clients d'héberger eux-mêmes leurs catalogues Iceberg et offrira une meilleure interopérabilité entre les différents moteurs de calcul.
- Serverless Tasks Flex : jusqu'à 42 % d'économies grâce à plus de souplesse sur le moment d'exécution des tâches (Private Preview).
- Les event-driven tasks passent en public preview : elles déclenchent automatiquement l'exécution d'une task dès qu'un stream Snowflake est mis à jour.
- Low Latency Tasks, désormais en private preview, qui ramènent les intervalles de planification des tâches à 15 secondes.
- Les Iceberg Tables, un format de table open source qui permet de stocker ses données dans le cloud sous forme de fichiers parquet tout en les interrogeant depuis Snowflake, passent en disponibilité générale (GA).
- Les Dynamic Tables passent en GA. Elles offrent une approche déclarative pour créer des transformations incrémentales et des pipelines de données simples à l'aide d'instructions SQL SELECT.
- Data Quality Monitoring : Snowflake propose désormais des métriques système prêtes à l'emploi (comme le nombre de valeurs nulles) ou des métriques personnalisées que les clients peuvent définir et mesurer automatiquement sur leurs tables. Cette fonctionnalité est en public preview et n'est disponible que pour les éditions Enterprise et supérieures de Snowflake.
- Les connecteurs natifs pour Postgres et MySQL arriveront bientôt en public preview. Ils permettront de répliquer facilement des données CDC depuis les bases de données internes vers Snowflake avec une très faible latence, et surtout sans payer un éditeur tiers (comme Fivetran) à chaque ligne chargée.
Outillage pour analystes et développeurs
- Les Snowflake Notebooks passent en public preview et offrent un environnement interactif de bout en bout pour les équipes data et IA.
- Snowflake a annoncé une nouvelle suite de fonctionnalités d'observabilité avec le lancement de Snowflake Trail, qui donne aux développeurs et partenaires davantage d'outils pour surveiller et déboguer leurs pipelines de données.
- Snowpark Container Services (SPCS) passe en GA et permet aux utilisateurs Snowflake d'exécuter en toute sécurité n'importe quel workload dans Snowflake via un conteneur.
- Dans le prolongement, Snowflake a annoncé la prise en charge en public preview de SPCS avec le framework des native apps, permettant aux partenaires de créer et déployer des applications riches.
- Le Copilot de Snowflake sera bientôt en GA. Il permettra aux analystes et aux utilisateurs métier de générer automatiquement des requêtes SQL à partir de texte directement dans l'interface Snowflake.
- L'intégration Git de Snowflake passe en Public Preview. Elle permet de synchroniser des fichiers entre Github/Gitlab/Bitbucket et Snowflake pour une meilleure gestion des versions.
Gouvernance des données et sécurité
- Un nouveau marketplace interne en private preview, qui permettra aux grandes organisations et équipes de partager en privé des jeux de données, applications et notebooks au sein de leur entreprise.
- De nouvelles Table Governance Views en public preview, qui affichent les principaux rôles et utilisateurs accédant à chaque table de votre compte Snowflake.
- Le Trust Center de Snowflake, une interface permettant d'identifier les risques de sécurité et d'obtenir des recommandations pour les résoudre, sera bientôt en GA.
- Universal Search est désormais en GA et permet de rechercher et découvrir rapidement tous ses actifs Snowflake directement depuis l'UI.
- Snowflake a présenté une nouvelle interface de visualisation de Data Lineage dans l'UI, actuellement en private preview, qui permettra de visualiser les dépendances amont et aval pour toutes les tables et vues.
- Les AI-Powered Object Descriptions ont été annoncées : elles ajoutent automatiquement du contexte et des commentaires pertinents aux tables et vues à l'aide de l'IA.
IA et ML d'entreprise
- Snowflake a publié une nouvelle API Snowpark pandas qui permet aux utilisateurs Python d'exécuter leur code pandas sur la compute Snowflake de manière parallélisée, levant les limites classiques de pandas en matière de volumes de données et de performance.
- Document AI sera bientôt en GA. Document AI propose un traitement de documents basé sur des LLM serverless pour extraire des données structurées à partir de documents métier non structurés (PDF, images, Word, etc., comme des factures, contrats ou fiches de tests produits). Plus d'informations ici.
- Snowflake Feature Store, désormais en public preview, permet de créer, gérer et servir des features ML avec une actualisation continue et automatisée sur des données en batch ou en streaming, via l'UI ou les API Snowpark ML. Plus d'informations ici.
- Snowflake Model Registry passe en GA. Cette solution intégrée permet de gérer, suivre, versionner et partager les modèles d'IA/ML et leurs métadonnées nativement dans Snowflake via l'UI ou les API Snowpark ML. Plus d'informations ici.
- Snowsight AI & ML Studio passe en GA et propose une UI qui permet de créer facilement divers modèles et pipelines ML et IA.
- Cortex Finetuning est désormais en Public Preview. Cette fonctionnalité permet d'entraîner des modèles LLM fondationnels directement depuis l'UI.
- Cortex Analyst, actuellement en private preview, est un service LLM serverless et d'une grande précision qui permet aux utilisateurs métier de poser une question et de recevoir une vraie réponse, et non simplement du SQL. Analyst s'appuiera sur un fichier YAML qui définit notamment le schéma de données, les métriques et les synonymes pour en cadrer la portée et la précision.
- Cortex Search, également en private preview, est un service de recherche hybride (Vector + Keywords) serverless basé sur des LLM. Il extrait les données de manière incrémentale depuis les documents, tables et vues, les découpe automatiquement et les vectorise pour des requêtes rapides (< 200 ms) et une recherche d'une grande précision.
Beaucoup de choses à digérer ! Dans la suite de cet article, je reviens sur la direction prise par Snowflake et j'approfondis quelques-unes des annonces les plus marquantes, en analysant leur impact.
Discours d'ouverture et philosophie de Snowflake
Dans le discours d'ouverture du Summit, Sridhar et Benoit ont commencé par rappeler les principes fondamentaux de la plateforme Snowflake. Ils ont insisté sur le fait que Snowflake est une plateforme unique, construite sur un moteur unique, qui fonctionne, tout simplement. La simplicité prime : pas vingt façons différentes de faire la même chose. Ce point ne m'a pleinement parlé que lorsque j'ai assisté au Databricks Summit la semaine suivante et constaté à quel point leur produit était complexe.
Snowflake ayant récemment rebaptisé sa plateforme de Data Cloud en AI Data Cloud, le discours d'ouverture a largement porté sur la manière dont la plateforme fournit tout ce qu'il faut pour l'IA d'entreprise :
- Les données. Snowflake propose un stockage natif extrêmement performant et prend en charge le format ouvert Iceberg pour les clients qui souhaitent garder le contrôle total de leurs données et les rendre accessibles à d'autres moteurs de calcul (comme Spark ou Trino).
- La compute. Tout le monde connaît les virtual warehouses de Snowflake, principalement utilisés pour les requêtes SQL. En interne, Snowflake désigne cette technologie de virtual warehouse comme un data flow engine. Tous les langages (Java, Python et Scala) sont poussés vers ce moteur, et pas uniquement le SQL. Avec Snowpark Container Services, Snowflake propose désormais une option de compute encore plus flexible, qui permet d'exécuter n'importe quelle application ou workload dans un conteneur sécurisé (en clair : si ça tourne dans Docker, ça tourne dans Snowflake).
- L'IA, le grand sujet du jour. Avec Cortex, les clients Snowflake accèdent à une suite d'outils qui simplifient l'utilisation et la création d'applications d'IA. Snowflake a également évoqué Arctic, une nouvelle famille de LLM conçue en interne et spécifiquement pensée pour les cas d'usage en entreprise.
- La sécurité, la gouvernance et la collaboration. Snowflake est depuis longtemps reconnu pour ses solides garanties de sécurité, sa gouvernance simple et son contrôle d'accès robuste. Même si l'utilisateur lambda n'y pense pas, ces fonctionnalités sont des prérequis incontournables pour toute entreprise.
Polaris Catalog et plus d'interopérabilité dans l'industrie
L'une des annonces les plus commentées est tombée quelques jours avant le Summit, lorsque Snowflake a annoncé qu'il passerait son catalogue Iceberg, Polaris, en open source. La principale raison de son importance : elle va améliorer l'utilisabilité et l'interopérabilité des data lakes Iceberg entre les différentes plateformes cloud.

L'autre raison de l'intérêt suscité, c'est que Databricks a annoncé simultanément l'acquisition de Tabular, une entreprise lancée par les créateurs et les principaux contributeurs au développement d'Iceberg.
Cela signifie clairement que Databricks va offrir un support de premier ordre pour Iceberg dans son produit, et j'imagine que Snowflake suivra à un moment donné en ajoutant la prise en charge de Delta Lake. Même s'il est un peu déstabilisant de savoir qu'une seule entreprise détiendra de fait les deux formats de données open source les plus populaires, je pense qu'au final cela bénéficiera grandement aux clients, car toutes les plateformes data cloud seront contraintes de prendre en charge davantage de formats ouverts.
Dans le même mouvement, Snowflake a aussi annoncé une extension majeure de son partenariat avec Microsoft Fabric. Au cœur de Fabric se trouve OneLake, qui reposait historiquement sur des fichiers parquet delta-lake. Microsoft prendra désormais en charge Iceberg, et Snowflake s'intégrera à OneLake.
Pour ceux qui se demandent pourquoi un catalogue séparé est nécessaire pour Iceberg, j'ai trouvé ce passage de la documentation Iceberg très éclairant :
On peut voir Iceberg comme un format permettant de gérer les données d'une table unique, mais la bibliothèque Iceberg a besoin d'un moyen de suivre ces tables par leur nom. Les opérations telles que créer, supprimer ou renommer des tables relèvent de la responsabilité d'un catalogue. Les catalogues gèrent un ensemble de tables, généralement regroupées en namespaces. La responsabilité la plus importante d'un catalogue est de suivre les métadonnées actuelles d'une table, qu'il fournit lorsque vous chargez celle-ci.
Le projet Iceberg ne fournissait pas de catalogue en propre ; il a au contraire défini les standards de ce que devaient faire les catalogues et de la façon dont ils pouvaient interagir avec Iceberg. Fidèle à sa philosophie, Snowflake abaisse considérablement la barrière à l'adoption de technologies complexes comme Iceberg en fournissant les pièces manquantes.
Serverless Tasks Flex en Private Preview
Pour celles et ceux qui s'intéressent à l'optimisation des coûts Snowflake, Snowflake a annoncé une nouvelle fonctionnalité prometteuse baptisée Serverless Tasks Flex.
Avec les Serverless Tasks, vous définissez une planification et Snowflake exécute automatiquement votre requête sur les ressources de calcul qu'il gère. Vous ne payez qu'à la seconde, en fonction du temps de calcul réellement consommé.
Avec Serverless Tasks Flex, vous fournissez à la fois une planification et un SLA qui définit le temps d'exécution maximal de votre tâche (autrement dit, l'heure à laquelle elle doit être terminée par rapport à l'heure de démarrage prévue). Snowflake prend ces deux paramètres en entrée et trouve le créneau le moins cher pour exécuter votre tâche tout en garantissant qu'elle se termine dans le SLA imparti (par exemple 3 heures).

Snowpark Container Services dans les Native Apps désormais en Public Preview
Snowflake a annoncé que les développeurs de native apps peuvent maintenant tirer parti de Snowpark Container Services dans leurs applications. Cela ouvre la voie à des UI plus riches (React/JavaScript personnalisé, par exemple) et à des applications plus complexes, créées et exécutées entièrement dans Snowflake.
C'est une annonce majeure pour les partenaires de Snowflake, car elle permettra à des entreprises comme SELECT de proposer leurs produits de manière plus sécurisée et plus fluide.

Snowflake Notebooks en Public Preview
Snowflake a annoncé que sa fonctionnalité Notebooks passe en Public Preview. Les Notebooks permettent de combiner Python, SQL et Markdown pour créer des rapports, des jobs ou réaliser des analyses ponctuelles.
Il est également possible de planifier l'exécution des notebooks sur un virtual warehouse ou un conteneur Snowpark. Snowflake a aussi annoncé l'arrivée du Copilot en ligne pour les notebooks (actuellement en public preview).
Annonces autour de Snowflake Horizon
Snowflake Horizon est la suite de fonctionnalités de Snowflake dédiée à la gouvernance des données, à leur découverte, à la sécurité et à la confidentialité. Plusieurs annonces ont été faites autour d'Horizon :
- Universal Search
- Table Governance Views
- AI-Powered Object Descriptions
- Visualisation du Data Lineage pour les tables et les vues
- Visualisation du ML Lineage
- Trust Center
- Marketplace interne
Je vais m'attarder sur quelques-unes de ces nouveautés qui me semblent les plus significatives pour la majorité des utilisateurs Snowflake.
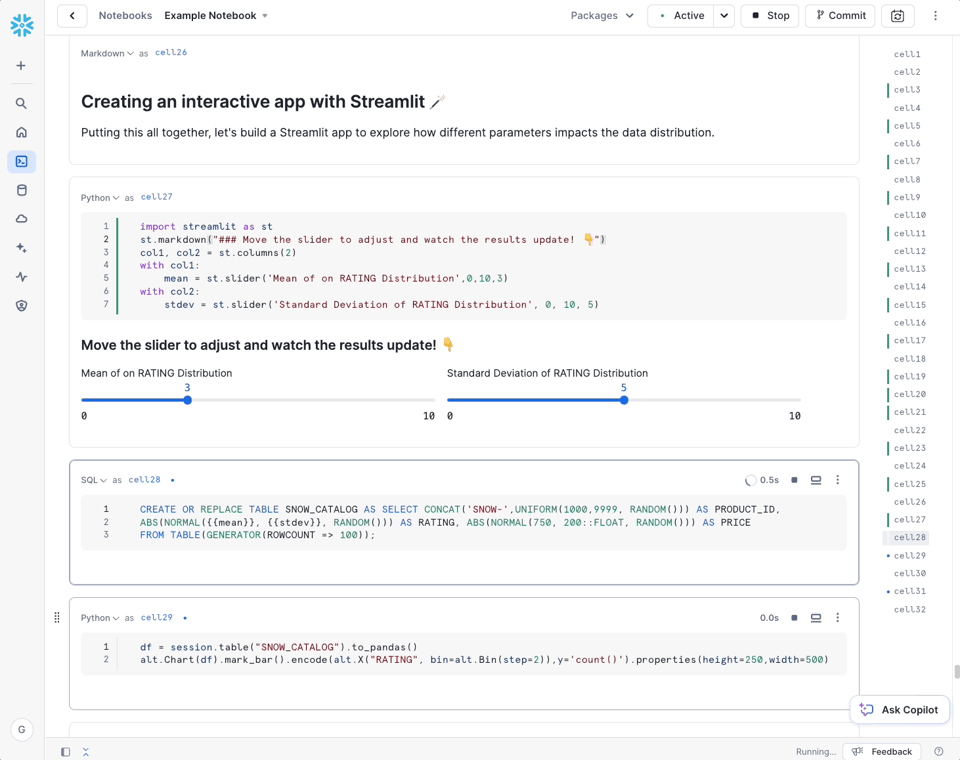
Universal Search en disponibilité générale
Search, accessible depuis l'UI, permet de rechercher dans tout ce que contient Snowflake, depuis vos données internes jusqu'au marketplace. La recherche s'appuie sur la technologie du moteur de recherche Neeva, racheté par Snowflake en 2023.
Voici un exemple tiré de notre compte Snowflake :
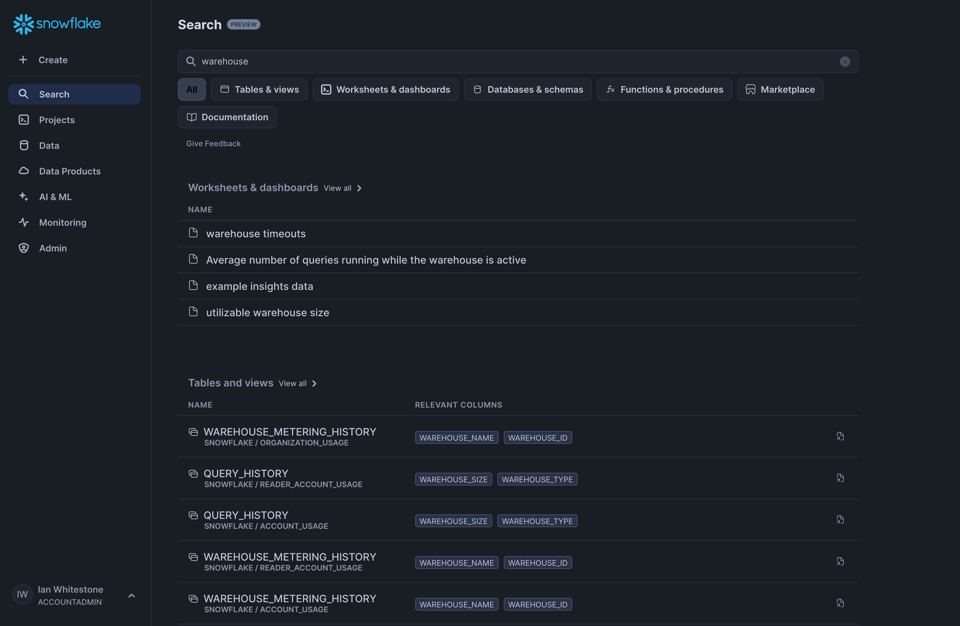
Onglet Table Governance en Public Preview
Sur la page des tables, Snowflake a présenté un nouvel onglet Governance qui regroupe les informations sur les principales requêtes, utilisateurs et rôles accédant à une table. Très utile pour comprendre qui utilise une table, et comment.
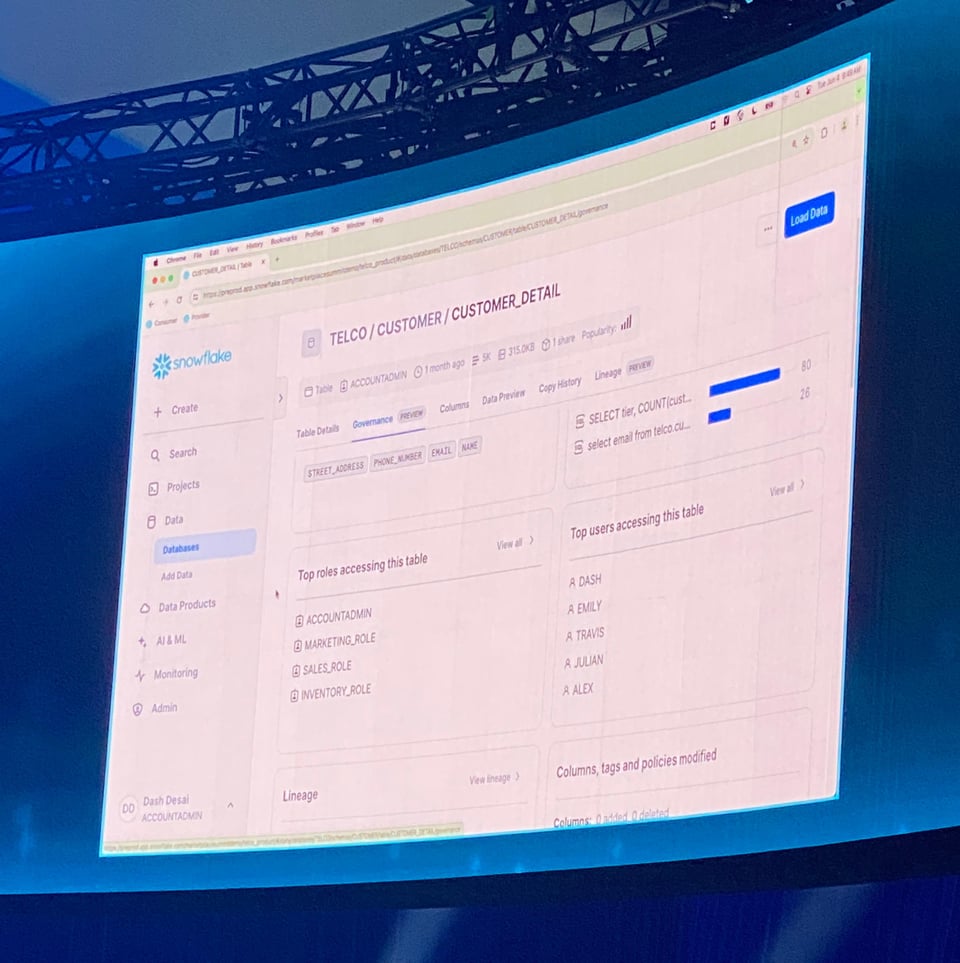
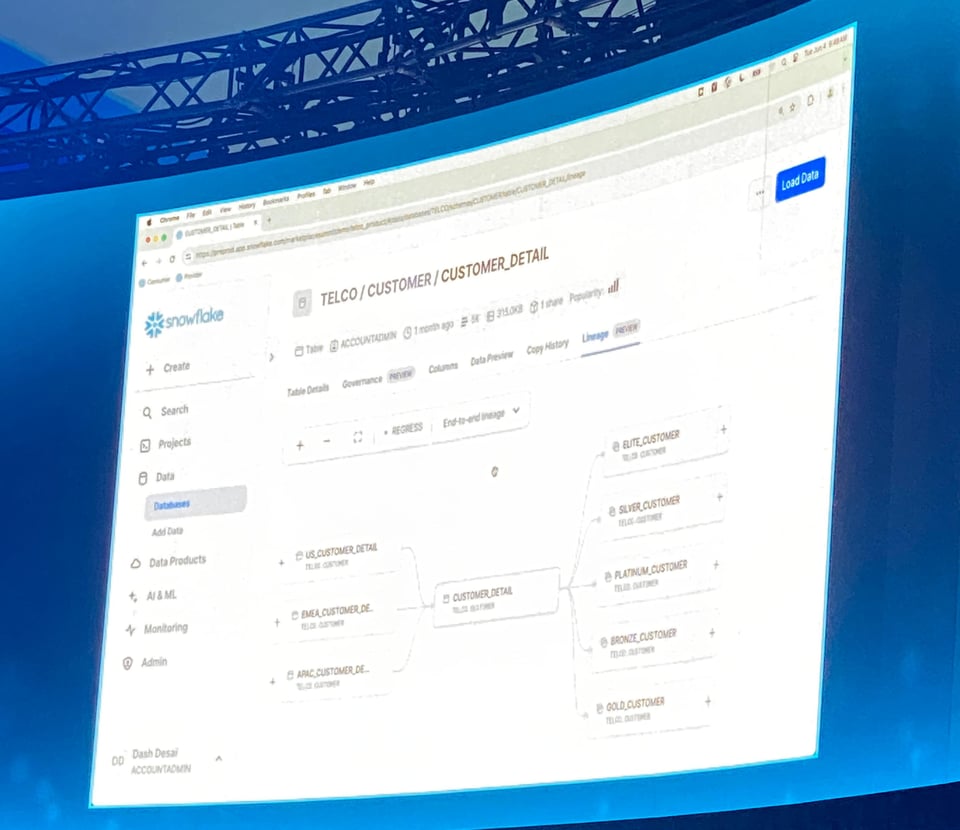
Table Lineage en Private Preview
Snowflake a présenté une nouvelle vue Table Lineage sur la page des tables, qui affiche les dépendances amont et aval pour les vues et les tables.
C'est l'une des fonctionnalités les plus prisées des outils de Data Catalog et d'observabilité. Il est donc remarquable de voir Snowflake la mettre à disposition de tous ses clients.
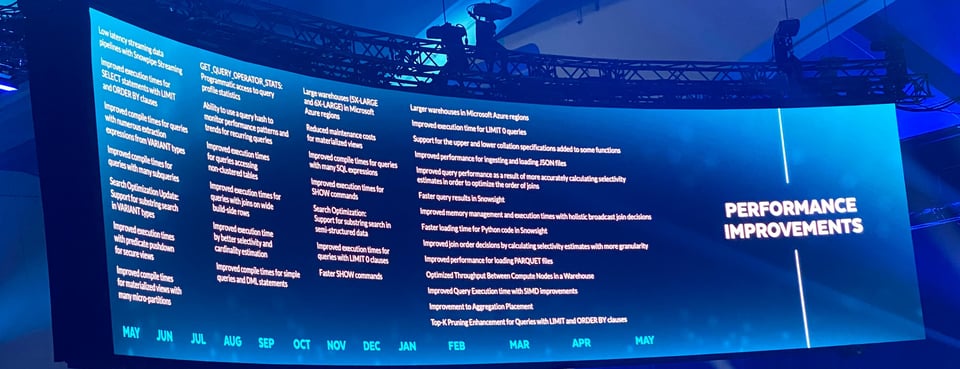
Améliorations de performance
Pour celles et ceux qui s'intéressent à l'optimisation des requêtes, Snowflake a mis en avant un certain nombre d'améliorations de performance déployées au cours des 12 derniers mois. Toutes interviennent en arrière-plan et améliorent silencieusement l'expérience des développeurs et des utilisateurs pour l'ensemble des clients Snowflake.
Connecteurs natifs pour Postgres et MySQL
Fort du succès de ses récents connecteurs natifs — le Snowflake Connector for Kafka et les connecteurs pour applications SaaS comme ServiceNow et Google Analytics —, Snowflake a annoncé que les connecteurs natifs pour Postgres et MySQL arriveront bientôt en public preview. Ils permettront de répliquer facilement des données CDC depuis les bases de données internes vers Snowflake avec une très faible latence, et surtout sans payer un éditeur tiers à chaque ligne chargée.
Il sera intéressant de voir ce que cela implique pour des entreprises comme Fivetran. À vue de nez, plus de la moitié de leurs revenus provient sans doute de la réplication de données Postgres et MySQL. Snowflake a indiqué qu'il développerait à l'avenir d'autres connecteurs pour les principales bases de données : la cannibalisation des revenus ne peut donc aller que dans un sens, à la hausse.
Snowflake Trail en Private Preview
Snowflake continue d'investir en profondeur dans l'observabilité, aussi bien pour les données que pour le développement applicatif.
Cette année au Summit, l'entreprise a annoncé Snowflake Trail, un ensemble de capacités permettant aux développeurs de mieux surveiller, diagnostiquer, déboguer et agir sur les pipelines, les applications, le code utilisateur et la consommation de compute.
Snowflake Trail s'appuie sur les Event Tables et offre automatiquement une meilleure visibilité sur les performances du code Snowpark et l'utilisation des ressources.
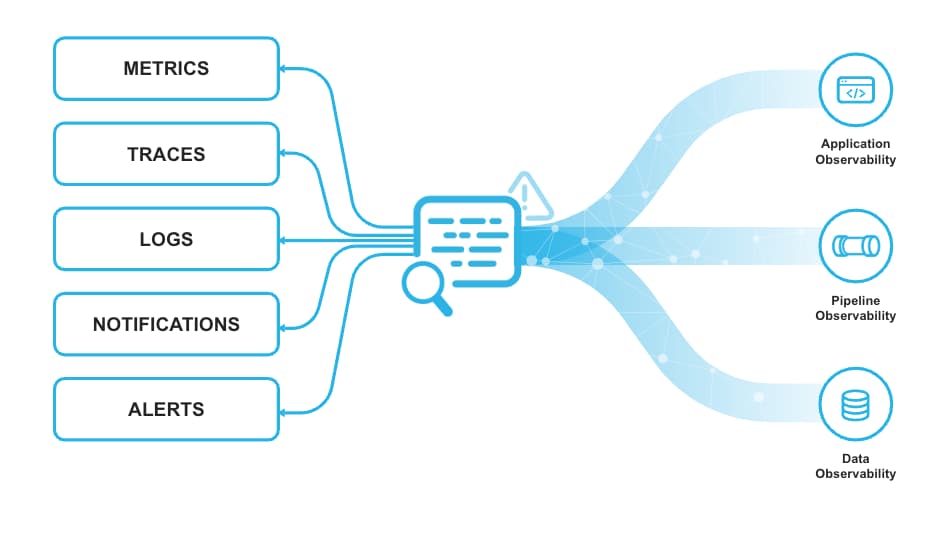
Snowflake Trail est compatible avec la spécification OpenTelemetry, ce qui facilite son intégration avec les technologies partenaires. Une UI de base sera également disponible par-dessus les event tables.
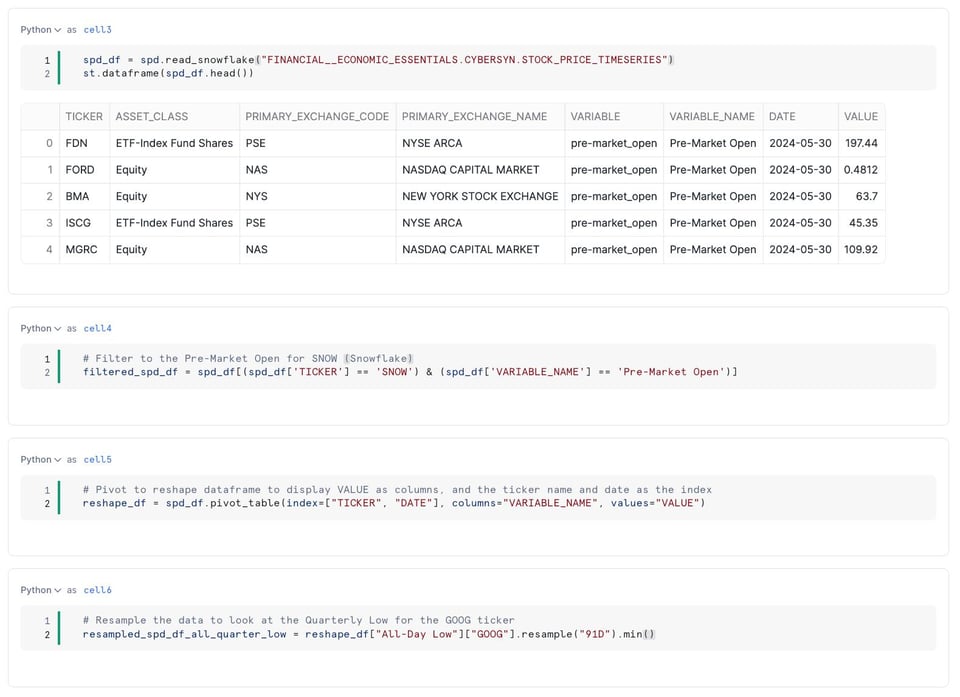
API Snowpark pandas
Fin 2023, Snowflake a racheté Ponder pour renforcer ses capacités Python.
Dans la foulée de cette acquisition, Snowflake a lancé une nouvelle API Snowpark pandas qui permet aux utilisateurs Python d'exécuter leur code pandas sur la compute Snowflake de façon parallélisée, levant les limites classiques de pandas en matière de volumes de données et de performance.
On peut désormais écrire du code pandas classique et le voir s'exécuter automatiquement, en coulisses, sous forme de SQL Snowflake — avec de bien meilleures performances et la capacité de traiter des jeux de données plus volumineux que la mémoire disponible.
En coulisses, le mécanisme prend votre code pandas, le traduit en requêtes SQL et restitue le résultat sous forme d'objets Python natifs. Très ingénieux !
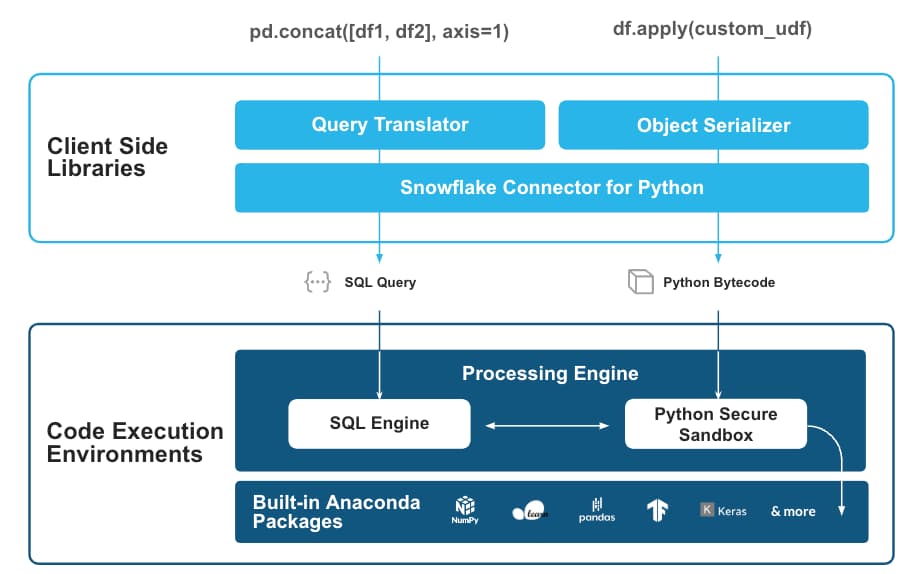
Images issues de l'annonce Snowflake : https://www.snowflake.com/blog/snowpark-pandas-api-run-at-scale/
Snowflake Cortex
Snowflake Cortex est la suite d'outils et de fonctionnalités IA de Snowflake. Cortex donne accès à une grande variété de LLM, dont ceux de Mistral, Reka, Meta, Google et Snowflake Arctic.
Au Summit, Snowflake a annoncé 3 nouvelles fonctionnalités dans la suite Cortex.
Cortex Finetuning (Public Preview)
Cortex Finetuning est désormais en Public Preview et permet d'entraîner directement depuis l'UI des modèles LLM fondationnels.
La plupart des LLM prêts à l'emploi ne conviennent pas tels quels à la majorité des entreprises, faute de connaissance de leurs données ou systèmes internes. Le fine-tuning permet d'entraîner des modèles plus pertinents pour ses propres cas d'usage.
Cortex Analyst (Private Preview)
Cortex Analyst, actuellement en private preview, est un service LLM serverless et d'une grande précision qui permet aux utilisateurs métier de poser une question et de recevoir une vraie réponse, et non simplement du SQL.
C'est l'un des principaux cas d'usage de l'IA discutés dans l'industrie. Si vous donnez à un LLM toute la connaissance sémantique et les métadonnées de votre data warehouse, ainsi que la capacité d'exécuter directement des requêtes SQL et d'en interpréter les résultats, vous obtenez quelque chose de très précieux.
Cortex Analyst s'appuiera sur un fichier YAML qui définit notamment le schéma de données, les métriques et les synonymes pour en cadrer la portée et la précision. Nous sommes impatients de voir comment cette fonctionnalité va évoluer. Vu la complexité de la construction d'un tel système et les enjeux métiers liés à la justesse des réponses, je m'attends à ce qu'il faille un certain temps avant qu'il ne traite des volumes significatifs de questions métier réelles.
Cortex Search (Private Preview)
Cortex Search, également en private preview, est un service de recherche hybride (Vector + Keywords) serverless basé sur des LLM. Il extrait les données de manière incrémentale depuis les documents, tables et vues, les découpe automatiquement et les vectorise pour offrir des requêtes rapides (< 200 ms) et une recherche d'une grande précision.
Pendant la keynote du Summit, les présentateurs ont fait monter sur scène un membre du public choisi au hasard. La personne ne s'était connectée à Snowflake qu'une poignée de fois, et a réussi à mettre en place un service fonctionnel en moins de 5 minutes, simplement en cliquant dans l'UI.
Lors de la démo, elle a sélectionné un stage préchargé avec plusieurs PDF d'exemple, puis s'est retrouvée en quelques minutes face à une interface de chat où elle pouvait poser des questions et obtenir des réponses du LLM, directement basées sur le contenu de ces PDF.
Dark Mode !!
Pour clôturer la keynote, Snowflake a annoncé que l'une des fonctionnalités les plus demandées, le Dark Mode, était désormais disponible pour tous les clients. La vidéo est à voir ici.
Je l'utilise depuis, et j'apprécie beaucoup son rendu !
Pour conclure
Même s'il n'y a pas eu d'annonce plateforme aussi structurante que celles des années précédentes (Native Apps ou Snowpark Container Services), le Summit 2024 a mis en évidence plusieurs points :
- Le rythme auquel les nouvelles fonctionnalités sont publiées et passent en disponibilité générale s'est nettement accéléré. Même si aucune annonce isolée n'a eu l'ampleur du lancement d'un app store ou d'une toute nouvelle manière d'exécuter des workloads (Snowpark Container Services), on a eu le sentiment d'en recevoir beaucoup plus, sur tous les fronts.
- Snowflake offre à ses clients davantage de fonctionnalités intégrées et réduit le besoin de recourir à des outils tiers habituellement nécessaires pour exploiter un data warehouse. La qualité et la gouvernance des données ont été renforcées, tous les clients auront bientôt accès au data lineage (la fonctionnalité phare des data catalogs), ils disposent d'une nouvelle fonctionnalité Notebooks très convaincante et s'apprêtent à publier des connecteurs natifs gratuits pour Postgres et MySQL (adieu Fivetran ?).
- L'IA et le ML sont la priorité absolue de Snowflake. Cela transparaît de plus en plus clairement dans les annonces aux investisseurs, le marché s'attendant à ce que ces nouveaux workloads (avec Snowpark) représentent une part significative du chiffre d'affaires dans les 5 prochaines années. Aujourd'hui, l'essentiel des revenus de Snowflake (à mon estimation, plus de 90 %) provient des workloads classiques de data warehousing et de business intelligence. Beaucoup de fonctionnalités impressionnantes ont été démontrées au Summit. Si elles tiennent les promesses montrées sur scène, elles auront sans aucun doute un impact considérable dans de nombreuses organisations en accélérant l'adoption de l'IA.
Ian Whitestone·Co-fondateur et CEO de SELECT
Ian est co-fondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à diriger des équipes data science et engineering full stack chez Shopify et Capital One. Chez Shopify, Ian a piloté les travaux d'optimisation du data warehouse et le renforcement de l'observabilité des coûts.