Was ist Terraform?
Terraform ist ein Infrastructure-as-Code-Tool ( IaC – kein Geklicke in der GUI!), mit dem Sie Service-Konfigurationen über Provider verwalten (in der Regel servicespezifisch – Snowflake, AWS, dbt Cloud usw.).
Provider sind für Terraform das, was Pakete für Python sind: vorgefertigte, wiederverwendbare Schnittstellen für einen klar umrissenen Zweck. Um in dieser Analogie zu bleiben: Die Terraform Registry entspricht in etwa PyPI.
Warum sollten Sie Ihre Snowflake-Infrastruktur mit Terraform verwalten?
Es gibt drei gute Gründe, Terraform für die Verwaltung Ihrer Snowflake-Infrastruktur in Betracht zu ziehen.
1. Versionskontrolle für Ihre Konfiguration
Mit Terraform liegt Ihre Infrastrukturkonfiguration in einem versionskontrollierten Repository wie GitHub. Damit profitieren Sie von allen Vorteilen, die Code in GitHub bietet: unkomplizierte Rollbacks, Vorschau auf Änderungen, eine langfristige Code-Historie und nicht zuletzt die geschätzten Code-Reviews durch Ihre Teamkollegen, bevor irgendetwas ausgerollt wird.
Davon abgesehen führt Terraform selbst Buch über den Zustand Ihrer Infrastruktur-Ressourcen und schützt vor unerwarteten Änderungen, indem es bei jedem Deployment einen Diff anzeigt.
2. Skalierung
Terraform macht Konfigurationen wiederverwendbar und erleichtert so die Skalierung Ihrer Snowflake-Deployments. Auf höchster Ebene bedeutet das: Mehrere Snowflake-Accounts lassen sich bequem von einer zentralen Stelle aus verwalten – ein großer Pluspunkt. Auch die Möglichkeit, Ressourcen mit gemeinsamen Konfigurationsvorlagen über Loops oder Module skalierbar zu erstellen, zu aktualisieren oder zu entfernen, spart bei großflächigen Aufgaben enorm viel Verwaltungsaufwand.
Außerdem lassen sich interne Zusammenarbeit und Best Practices besser skalieren. Terraform schafft eine gemeinsame Sprache über Repositories, Teams und sogar Fachdisziplinen hinweg – für jedes Datenteam heute Gold wert! Einheitliches Tooling im gesamten Unternehmen reduziert zudem den Pflegeaufwand für individuelle Deployment-Pipelines, wenn alle nach demselben Playbook arbeiten.
3. Abhängigkeiten einfacher verwalten
Terraform erstellt anhand der von Ihnen definierten Objekte einen Abhängigkeitsgraphen Ihrer Ressourcen. Das heißt: Es warnt Sie, wenn Sie versuchen, Ressourcen zu entfernen, die nachgelagert noch gebraucht werden – etwa eine Tabelle, die in einem Stream verwendet wird.
Ist Terraform (oder überhaupt IaC) das Richtige für Sie?
Selbst in der wackeligsten Umsetzung sorgen IaC-Tools immer für eines: dass Sie Ihr Setup schriftlich festhalten! Und wer freut sich nicht über ein bisschen ordentliche Dokumentation? Liegt das Ganze dann auch noch in der Versionskontrolle, ist die Chance groß, dass zumindest irgendwo vermerkt ist, warum oder wann eine Konfiguration ergänzt wurde – alles wertvoller Kontext.
Die Kehrseite: IaC ist von Natur aus eine Abstraktionsebene zwischen Ihnen und der Plattform, mit der Sie arbeiten möchten. Je stärker Sie auf Techniken wie Module setzen, desto weiter rückt Ihre Konfiguration von der Plattform weg. Das kann anderen die Nachvollziehbarkeit erschweren oder, schlimmer noch, Ihren Stack brüchig machen. Abstraktionen sollten daher mit Bedacht und Strategie eingesetzt werden.
Ist die Konfiguration dieses Service wirklich wichtig? Lohnt der Aufwand das Ergebnis? 🍊
Jeder Aspekt Ihrer Infrastruktur birgt Risiken – etwa Fehlkonfigurationen oder Ausfallzeiten. Bestehende oder neue Konfigurationen in IaC zu überführen, ist nicht ohne Investition. Überlegen Sie also zuerst, wie geschäftskritisch diese Komponente ist, bevor Sie loslegen.
Können Sie die Zeit für Einrichtung und Pflege aufbringen? Ist Snowflake wichtig genug für Ihr Unternehmen, um diesen Aufwand zu rechtfertigen? Spielt die Recovery-Zeit von Snowflake eine Rolle? Müssen Sie auch bestehende Snowflake-Ressourcen nach Terraform migrieren?
Bevorzugen die Administratoren dieses Service die Code-Variante?
Manchmal wollen (oder können!) Ihre Admins nicht bei jeder Änderung den Weg über Code und Versionskontrolle gehen. Solange die Folgen eines Fehltritts überschaubar bleiben, sollten Sie die Flexibilität nicht künstlich beschneiden!
Andererseits: Terraform (oder andere IaCs) kann auch eine gemeinsame Sprache über Entwicklungsteams hinweg schaffen und so für Konsistenz und Wiederverwendbarkeit sorgen (siehe Terraform Module). Das ermöglicht einen demokratisierten Administrationsansatz und entlastet erfahrene Mitarbeitende, denen sonst die ganze Last aufgebürdet würde.
Deckt der Provider Ihre Anforderungen ab? Gibt es überhaupt einen Provider?
Nicht für alles existiert ein Terraform-Provider, und selbst wenn, kann zwischen dem Release einer neuen Funktion und ihrer Abbildung im Provider eine Weile vergehen. Es lohnt sich also, vorab zu prüfen, was verfügbar ist, bevor Sie mit einem Provider starten – oder den Weg gehen, einen eigenen zu entwickeln.
So nutzen Sie Terraform mit Snowflake
Ob Sie lokal entwickeln, in Codespaces arbeiten oder ein Produktions-Setup aufsetzen – die ersten Schritte sind weitgehend gleich. Schauen wir uns also die grundlegenden Konzepte für die Nutzung eines beliebigen Terraform-Providers an.
Der Snowflake Terraform Provider
In der Terraform Registry finden Sie verschiedene Snowflake-bezogene Provider und Module. Wir konzentrieren uns hier auf jenen, der inzwischen von Snowflake selbst gepflegt wird: den offiziellen Snowflake Terraform Provider.
Einrichtung
So starten Sie ein Snowflake-Terraform-Projekt:
- Terraform installieren – siehe Doku, z. B. via Homebrew unter macOS:
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
terraform -help
- Ein neues Verzeichnis bzw. Repository anlegen
mkdir snowflake-terraform-example
cd snowflake-terraform-example
- Eine Datei
[versions.tf](http://versions.tf)anlegen. Sie enthält die Versionen der verwendeten Terraform-Provider. Für dieses Beispiel etwa so:
terraform {
required_version = ">= 1.0.0"
required_providers {
snowflake = {
source = "snowflake-labs/snowflake"
version = "0.84.1"
}
}
}
- Zur Konfiguration Ihres Providers legen Sie eine Datei
[providers.tf](http://providers.tf)an. Hier konfigurieren Sie die verwendeten Provider. Beim Testen können Sie Credentials direkt übergeben – sobald das Ganze ins Repository wandert, sollten Sie aber auf eine Lösung mit Umgebungsvariablen umsteigen (damit Ihre Secrets nirgendwo offen herumliegen!). Ein Beispiel:
provider "snowflake" {
role = "SYSADMIN"
}
So deployen Sie Terraform für Snowflake mit GitHub Actions
Credentials einrichten
Damit Terraform in GitHub Actions mit Snowflake kommunizieren kann, benötigt es Zugangsdaten zur Anmeldung. Dafür gibt es mehrere Optionen: Username/Passwort, Private Keys, OAuth usw. Für dieses Beispiel bleiben wir bei Username/Passwort. Weitere Authentifizierungsoptionen finden Sie in der Provider-Dokumentation.
So legen Sie Ihre Credentials auf Repository-Ebene in GitHub Secrets ab: Ihr Repository > Settings > Secrets and variables > Actions > New repository secret
Mit folgenden Werten:
SNOWFLAKE_ACCOUNT– Ihr Account Identifier inkl. Region/Provider-Details, z. B.select_dev-productionoderselect123.eu-west-1.awsfür ältere Accounts.SNOWFLAKE_USER– Login-UsernameSNOWFLAKE_PASSWORD– Login-Passwort
Checks in der CI
Wenn Sie in einem Repository mit Terraform Infrastrukturänderungen vornehmen, lohnt es sich, einige Prüfschritte in die CI aufzunehmen:
terraform fmt -check– Prüft die Formatierung Ihrer Terraform-Konfiguration. Ein Teil der Stärke von Terraform liegt in der Lesbarkeit, daher ein wichtiger Schritt. Das Flag-checklässt den Befehl bei fehlerhafter Formatierung fehlschlagen; ohne das Flag korrigiert er die Formatierung (das gehört aber eher in die Entwicklung als in die CI).terraform validate– Führt eine grundlegende Validierung durch. Greift nicht auf entfernte Services zu, prüft aber etwa Attributnamen.terraform plan– Auch in der Entwicklung nützlich: Vergleicht Ihre aktuelle Terraform-Konfiguration mit dem Remote-Zustand des Service und ermittelt so, welche Änderungen anstehen (ohne sie anzuwenden). In der CI ist dieser Schritt extrem hilfreich, weil er genau zeigt, was sich gleich ändert – und sollte vor der Freigabe geprüft werden.
Zusammengesetzt könnte eine CI-Pipeline in GitHub Actions etwa so aussehen:
name: Terraform Snowflake CI
on:
pull_request:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Code ausklappen
Kopieren Sie das Obige in eine Datei wie .github/workflows/ci.yml. Beim nächsten Pull Request laufen die Checks dann gegen Ihren Branch und sehen in GitHub Actions etwa so aus:
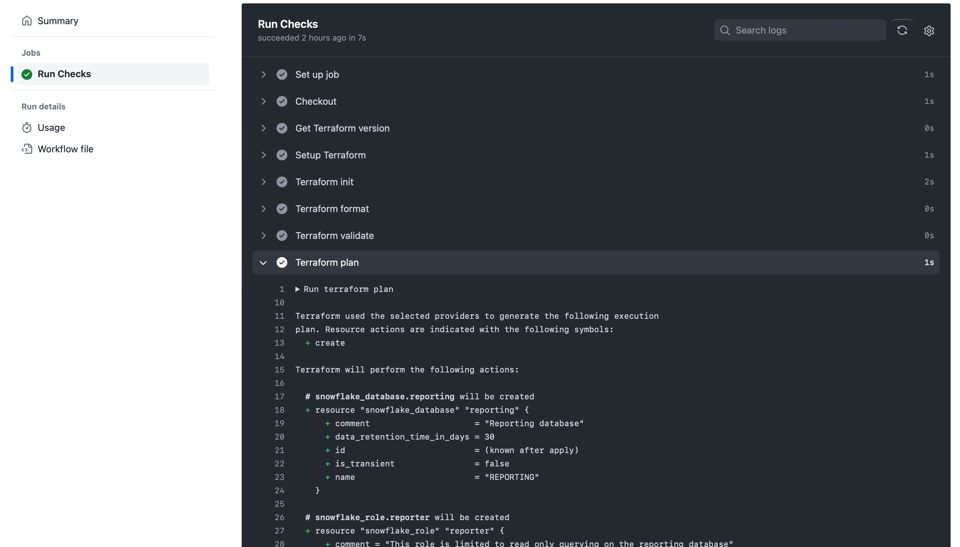
Beispielhafte CI-Pipeline bei einem Pull Request in GitHub Actions
( Optionaler Bonus) – Wenn Sie vollständige Replikate Ihrer Umgebung bereitstellen können, lässt sich auch der Schritt terraform apply in die CI aufnehmen. Der Vorteil: Sie fangen Fehler ab, die erst von Snowflake (nicht vom Terraform-Provider) gemeldet werden, sobald die Änderungen tatsächlich angewendet werden. Außerdem ermöglicht es eine manuelle Validierung direkt in Snowflake und bringt den Entwicklungsfluss näher an gängige Engineering-Workflows heran.
Der Nachteil: Sie brauchen dafür wahrscheinlich einen separaten Snowflake-Account oder zumindest ein separates Credential-Set, um Ihre CI-Umgebung von der Deployment-Umgebung zu trennen – das würde den Rahmen dieses Artikels sprengen.
Der Vollständigkeit halber: Um das in der ci.yml zu ergänzen, fügen Sie einfach folgenden zusätzlichen, abschließenden Block ein:
- name: Terraform apply
id: terraform-apply
run: terraform apply -auto-approve
Änderungen deployen
Wenn nach den vorherigen Schritten alles passt und alle mit den Änderungen einverstanden sind, können wir sie über eine Deployment-Pipeline ausrollen.
terraform apply -auto-approve– Wendet die Änderungen auf Ihre Infrastruktur an. Beim Ausführen über Actions sorgt-auto-approvedafür, dass Terraform ohne Benutzereingriff weiterläuft – auf der Kommandozeile würde sonst eine Bestätigung erwartet.
Ein sehr einfacher Deployment-Schritt also! In GitHub Actions sähe das z. B. unter .github/workflows/deployment.yml so aus:
name: Terraform Snowflake Deployment
on:
push:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Code ausklappen
Terraform-State für GitHub Actions speichern
Damit Terraform sich "merkt", wie Ihre Infrastruktur aussieht, erstellt es eine State-Datei mit einer Liste aller Ressourcen und ihrer aktuellen (bzw. gewünschten!) Konfiguration.
Wenn Sie nun Änderungen über Pull Requests und GitHub vornehmen, muss die GitHub Action auf den aktuellen Zustand der Ressourcen zugreifen können – also auf die resultierende Infrastruktur des vorherigen terraform apply-Schritts. Wie stellen wir sicher, dass sie darauf Zugriff hat?
Hier kommen Terraform Backends ins Spiel (für alle, die nicht Terraform Cloud nutzen). Damit konfigurieren Sie Ihr Terraform-Setup so, dass die State-Datei an einem dauerhafteren Ort als Ihrem lokalen Speicher liegt.
Dazu fügen Sie Ihrem Terraform-Projekt einen Backend-Block hinzu, z. B. in einer Datei [backend.tf](http://backend.tf). Unten sehen Sie ein Beispiel für ein Amazon-S3-Backend (vorerst ohne DynamoDB-Setup):
terraform {
backend "s3" {
bucket = "terraform"
key = "state/snowflake.tfstate"
region = "eu-west-1"
}
}
So weit, so einfach – jetzt kommt der etwas kniffligere Teil: die Integration in Ihre Deployment-Pipeline. Zum Glück übernimmt Terraform, sobald es bei AWS authentifiziert ist, das Aktualisieren des Remote-States für uns!
Dazu fügen Sie drei weitere GitHub Secrets für Ihren AWS-Account hinzu:
AWS_ACCESS_KEY_ID– Access Key Identifier Ihres AWS-AccountsAWS_SECRET_ACCESS_KEY– Access Key SecretAWS_REGION– AWS-Region, z. B.eu-west-1
Und ergänzen Sie Ihre ci.yml bzw. deployment.yml um folgenden Schritt (oder eine vergleichbare Authentifizierung), bevor Terraform-Befehle ausgeführt werden.
- name: Authenticate against production account
uses: "aws-actions/configure-aws-credentials@v2"
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
Alles in allem würde eine grobe Pipeline für den Terraform-Snowflake-Workflow mit GitHub Actions etwa so aussehen:
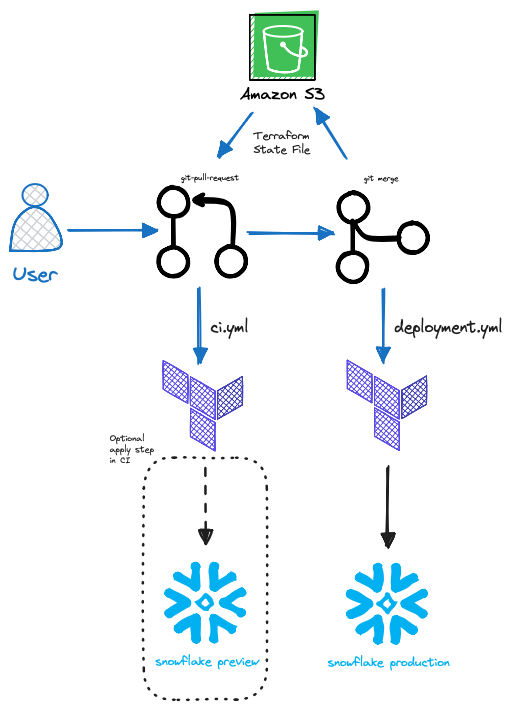
Snowflake-Terraform-Beispiele
Falls Sie einen Einstieg suchen: Hier finden Sie ein paar grundlegende Beispiele für die zentralen Snowflake-Konzepte. Legen wir zunächst ein Warehouse an (X-Small, versteht sich 😉).
resource "snowflake_warehouse" "reporting_warehouse" {
name = "reporting_wh"
comment = "Warehouse for reporting and BI tools"
warehouse_size = "x-small"
}
Super, wir können unsere Snowflake-Daten jetzt abfragen – aber noch nirgendwo speichern. Legen wir also eine gute alte Datenbank an.
resource "snowflake_database" "reporting" {
comment = "Reporting database"
data_retention_time_in_days = 30
name = "REPORTING"
}
Wunderbar. Zum Abschluss richten wir noch eine Snowflake-Rolle ein und weisen sie unserem Reporting-User zu.
1
2resource "snowflake_role" "reporter" {
3 name = "REPORTER"
4 comment = "This role is limited to read only querying on the reporting database"
5}
6
7resource "snowflake_role_grants" "reporter" {
8 role_name = snowflake_role.reporter.name
9 roles = [\
\
10 ]
11 users = [\
\
12 snowflake_user.reporting_user.name\
\
13 ]
14}
Das letzte Beispiel zeigt, wie Terraform Referenzen zwischen Objekten herstellt: snowflake_role_grants hängt von snowflake_role und snowflake_user ab – daran erkennt Terraform die Reihenfolge, in der das SQL ausgeführt werden muss.
Weitere Beispiele
Ein lauffähiges Beispiel zu diesem Artikel finden Sie im folgenden GitHub-Repository. Forken und einen Codespace anlegen ist der schnellste Weg, um loszulegen!
GtheSheep/terraform-snowflake-example
Für ein praxisnahes Setup von Terraform mit Snowflake empfehlen wir den offiziellen Einstiegsleitfaden von Snowflake: Terraforming Snowflake.
Herausforderungen mit Snowflake und Terraform
Wie jedes Tooling hat auch Terraform seine Tücken – und manchmal verschärfen die Eigenheiten oder Anwendungsfälle von Snowflake diese sogar. Schauen wir uns ein paar davon an:
Vollständige Ressourcenabdeckung
Auch wenn ein starkes Team den Snowflake-Terraform-Provider pflegt, kann es manchmal etwas dauern, bis er mit den neuesten Snowflake-Funktionen Schritt hält. Gelegentlich ist es auch eine bewusste Design-Entscheidung, etwas nicht über Terraform zuzulassen (eher selten). Das bedeutet: Ein Teil der Verwaltung muss möglicherweise weiterhin direkt in Snowflake erfolgen.
Hinzu kommt: Manche Ressourcen sind nicht mit allen Schikanen ausgestattet, die Snowflake bietet. Das kann dazu führen, dass Sie nach dem Deployment noch ein paar "Bonus"-SQL-Befehle in Snowflake absetzen müssen.
Ein Beispiel: Das Äquivalent zu GRANT SELECT ON ALL TABLES IN SCHEMA <schema> TO ROLE <role> war im Provider lange nicht direkt verfügbar. Jahrelang musste man entweder einen Weg finden, über die Objekte im Schema zu iterieren, oder zusätzliches SQL ausführen. Inzwischen gibt es zum Glück den Parameter on_all!
Ownership und Lebensdauer
Wenn Sie entscheiden, welche Snowflake-Ressourcen Sie via Terraform verwalten möchten, denken Sie an deren Lebensdauer und Ownership.
Lebensdauer kann zum einen heißen: schnell mal etwas hochziehen und wieder abreißen für Tests, POCs usw. – und die Frage, ob sich der Aufwand lohnt. Aber es geht weiter: Denken Sie an transiente Tabellen oder solche, die unabhängig von Terraform-Deployments häufig gelöscht und neu erstellt werden (dbt, ich schaue dich an 👀). Solche Aktivitäten können dazu führen, dass Snowflake und der Terraform-State stark auseinanderdriften – und Ihre Deployments im Schlamassel landen 🥒.
Bei der Ownership gilt: Entscheiden Sie, welcher Prozess die jeweiligen Objekte tatsächlich besitzt. Könnte Terraform genutzt werden, um die Umgebung abzustecken, in der diese Prozesse operieren? (Etwa: eine Datenbank via Terraform anlegen, deren Schema dbt verwaltet 🤷♂️.)
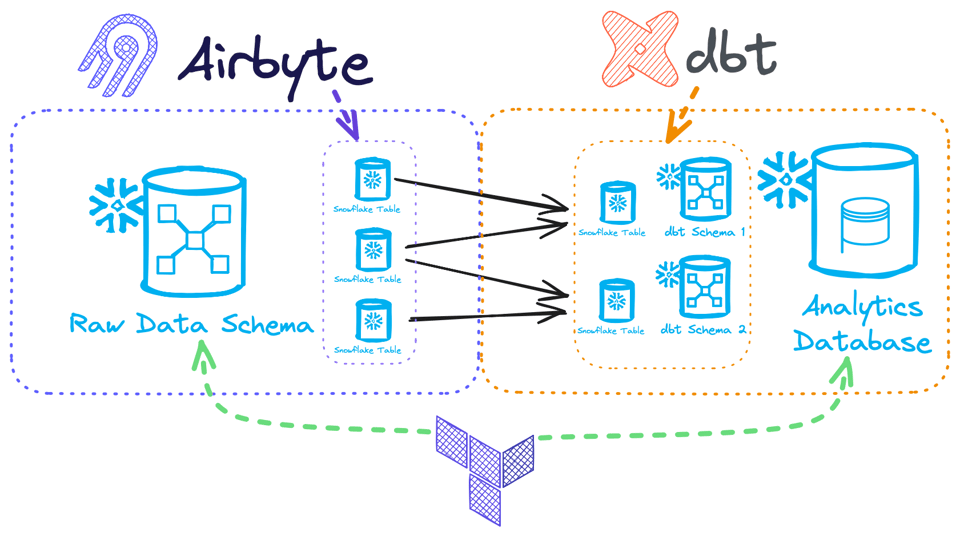
Beispiel: Angenommen, wir haben ein Tool zum Laden von Rohdaten – Airbyte – und ein Transformationstool – dbt:
- Airbyte erhält in der Regel ein Zielschema, in das die Daten geladen werden. Danach lassen wir es die Tabellen innerhalb dieses Snowflake-Schemas besitzen und verwalten, also nach Bedarf Spalten und Tabellen anlegen (gehen wir davon aus, dass standardmäßig alle verfügbaren Ressourcen aus der Quelle ausgewählt werden). In diesem Fall wollen wir die Tabellen nicht mit Terraform verwalten – sie wären durch Airbytes Aktivität schnell veraltet. Wohl aber können wir das Schema mit Terraform verwalten: sowohl die Erstellung als auch die Zugriffssteuerung, denn aus Airbytes Sicht ist es unveränderlich.
- dbt könnte die Daten anschließend in mehrere Snowflake-Schemata transformieren, diese selbst erstellen und darin Tabellen aufbauen. Hier wäre es nicht sinnvoll, auch nur die Schemata mit Terraform zu verwalten, da dbt die volle Ownership hat und sogar die Zugriffssteuerung übernehmen könnte. Aber: Die Datenbank ist der Bereich, in dem dbt operieren darf – die könnten wir also via Terraform bereitstellen.
Beide Prozesse laufen völlig unabhängig von Ihrer Terraform-Pipeline. Der State würde also entweder gar nichts von den Änderungen der anderen Prozesse mitbekommen und in Ihrem terraform plan jede Menge Rauschen erzeugen – oder, schlimmer, die Änderungen von Airbyte/dbt überschreiben!
Mehrere Repositories verwalten
Wenn Ressourcen aus mehreren Quellen benötigt oder bearbeitet werden, kann es etwas knifflig werden.
Wie oben erwähnt, ist es entscheidend, die Ownership von Snowflake-Ressourcen klar zu klären. Widersprüchliche Definitionen können dazu führen, dass unterschiedliche Deployments einander die Konfigurationen überschreiben – etwa wenn zwei Repos USAGE auf einer Datenbank an unterschiedliche Rollen vergeben (heute teilweise entschärft durch den Parameter enable_multiple_grants).
Abhängigkeiten lassen sich über Terraform-Module, das Auslesen aus Data Sources usw. verwalten. Damit diese Flexibilität nicht aus dem Ruder läuft, sollten Sie einen soliden Plan für die Struktur Ihres Ressourcenmanagements entwickeln. Beispielsweise: Ein zentrales Repo verwaltet Snowflake-Rollen, -User, -Grants, -Warehouses usw. – also die wirklich zentralen Elemente eines Accounts – und andere Teams können bei Bedarf eigene Datenbanken, Tasks oder Procedures bereitstellen.
Gary James · Senior Analytics Engineer bei Beauty Pie
Gary ist Senior Analytics Engineer bei Beauty Pie, einem Make-up- und Hautpflegeunternehmen. Mit über einem Jahrzehnt Erfahrung in jeder erdenklichen "Daten"-Rolle ist er ein großer Fan von allem rund um Data und Engineering. Gary trägt sehr aktiv zu einer Vielzahl von Open-Source-Projekten im Data-Stack bei. Er hat den dbt-cloud-Terraform-Provider entwickelt und arbeitet an weiteren Projekten im Ökosystem mit, darunter dbt, Elementary Data, Lightdash und Meltano.