O que é Terraform?
Terraform é uma ferramenta de Infraestrutura como Código ( IaC — sem precisar mexer em GUI!) para gerenciar a configuração dos seus serviços por meio de providers (geralmente específicos de cada serviço — Snowflake, AWS, dbt Cloud, etc.).
Os providers estão para o Terraform assim como os pacotes estão para o Python: blocos pré-montados de interfaces reutilizáveis criados para fins específicos. Seguindo a analogia, o Terraform registry seria algo como o Pypi.
Por que usar o Terraform para gerenciar a infraestrutura do Snowflake?
Há 3 motivos bem convincentes para considerar o uso do Terraform no gerenciamento da sua infraestrutura no Snowflake.
1. Para versionar sua configuração
Com o Terraform, a configuração da sua infraestrutura fica armazenada em um repositório com controle de versão, como o Github. Isso traz todos os benefícios de manter código no Github: rollback fácil, prévia das mudanças, histórico de longo prazo e aquelas reviews valiosas dos colegas de time antes de liberar qualquer alteração.
Além do Github, o próprio Terraform mantém o estado dos recursos da sua infraestrutura, ajudando a prevenir mudanças inesperadas ao apresentar um diff em cada deployment.
2. Escala
O Terraform permite reaproveitar configurações, facilitando o escalonamento dos seus deployments no Snowflake. Em alto nível, conseguir gerenciar várias contas Snowflake a partir de um único lugar já é uma grande vantagem. Além disso, criar/atualizar/remover recursos de forma escalável com configurações padronizadas via loops ou módulos reduz bastante o tempo gasto com tarefas amplas.
Ele também ajuda a escalar a colaboração interna e as boas práticas. Oferece uma linguagem comum entre repositórios, times e até disciplinas — algo superútil para qualquer time de dados hoje em dia! Adotar um ferramental único na organização também diminui o tempo gasto mantendo pipelines de deployment sob medida, já que todo mundo segue o mesmo manual.
3. Um jeito mais fácil de gerenciar dependências
O Terraform monta um grafo de dependências entre seus recursos a partir dos objetos que você define, ou seja, ele consegue te alertar quando você tenta remover algo que ainda é necessário em outro lugar, como derrubar uma tabela usada por uma stream.
Será que o Terraform (ou qualquer IaC) é a escolha certa para você?
Mesmo nas implementações mais improvisadas, as ferramentas de IaC sempre fazem uma coisa: obrigam você a deixar sua configuração documentada! Quem não gosta de uma boa documentação, né? E se ela ainda estiver no controle de versão, é bem provável que haja pelo menos alguma menção ao porquê daquela configuração ter sido adicionada ou quando isso aconteceu — todo contexto útil.
O outro lado da moeda é que a IaC, por natureza, fica um passo distante da plataforma com a qual você quer interagir. E quanto mais você abraça técnicas como módulos, mais distante a configuração pode acabar ficando — o que pode gerar obscuridade para quem precisa usá-la ou, pior, introduzir fragilidade na sua stack. Por isso, as abstrações devem ser feitas com critério e estratégia.
A configuração desse serviço é realmente importante? O esforço compensa? 🍊
Todo aspecto da sua infraestrutura tem riscos associados, como configuração incorreta e indisponibilidade. Migrar configurações (existentes ou novas) para IaC exige investimento, então pense o quanto esse componente é vital para o seu negócio antes de mergulhar de cabeça.
Você tem tempo para configurar e manter isso? O Snowflake é central a ponto de justificar o esforço? O tempo de recuperação do Snowflake é um fator? Você precisa considerar a migração dos recursos Snowflake já existentes para o Terraform?
Quem administra esse serviço prefere fazer isso em código?
Às vezes, seus administradores não vão querer (ou não vão conseguir!) passar por código/controle de versão a cada mudança necessária. Se as consequências de errar forem toleráveis, não atrapalhe a flexibilidade!
Dito isso, o Terraform (ou outras IaCs) também oferece uma linguagem comum entre os times de desenvolvimento, agregando consistência e reaproveitamento (veja Terraform Modules) à sua organização, viabilizando uma administração mais democrática e dividindo o que muitas vezes vira um fardo dos profissionais mais sêniores.
O provider cobre as suas necessidades? Será que existe um provider?
Nem tudo tem provider disponível no Terraform e, mesmo quando tem, às vezes há um atraso entre o lançamento de novas funcionalidades e seu reflexo no provider. Por isso, vale conferir o que está disponível antes de adotar um provider — ou partir para construir o seu.
Como usar o Terraform com o Snowflake
Esteja você desenvolvendo localmente, no Codespaces ou começando uma configuração de produção, os primeiros passos são bem parecidos. Vamos apresentar alguns conceitos básicos para usar qualquer provider do Terraform.
O Snowflake Terraform Provider
Consultando o Terraform Registry, você vai encontrar vários providers e módulos relacionados ao Snowflake, mas o provider em que vamos focar é o que agora está sob manutenção da própria Snowflake: o oficial Snowflake Terraform Registry.
Configuração inicial
Para começar um projeto Terraform com Snowflake:
- Instale o Terraform — veja os docs, por exemplo via Homebrew no Mac OS X:
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
terraform -help
- Crie um novo diretório/repositório
mkdir snowflake-terraform-example
cd snowflake-terraform-example
- Crie um arquivo
[versions.tf](http://versions.tf), que vai conter as versões dos Terraform Providers que você usará. Neste exemplo, ele deve ficar mais ou menos assim:
terraform {
required_version = ">= 1.0.0"
required_providers {
snowflake = {
source = "snowflake-labs/snowflake"
version = "0.84.1"
}
}
}
- Para configurar seu provider, crie um arquivo
[providers.tf](http://providers.tf). É aqui que você configura os providers que vai usar. Dá para passar credenciais aqui durante os testes, mas o ideal é adotar uma solução com variáveis de ambiente quando o arquivo for para o repositório (para não expor seus segredos em lugar nenhum!). Um exemplo poderia ser:
provider "snowflake" {
role = "SYSADMIN"
}
Como fazer deploy do Terraform para Snowflake com Github Actions
Configurando suas credenciais
Para interagir com o Snowflake via Terraform no Github Actions, é preciso ter credenciais de login no Snowflake. Existem algumas opções: usuário/senha, chaves privadas, OAuth, etc. Neste exemplo, vamos usar usuário/senha. Para outras opções de autenticação, consulte a documentação do provider.
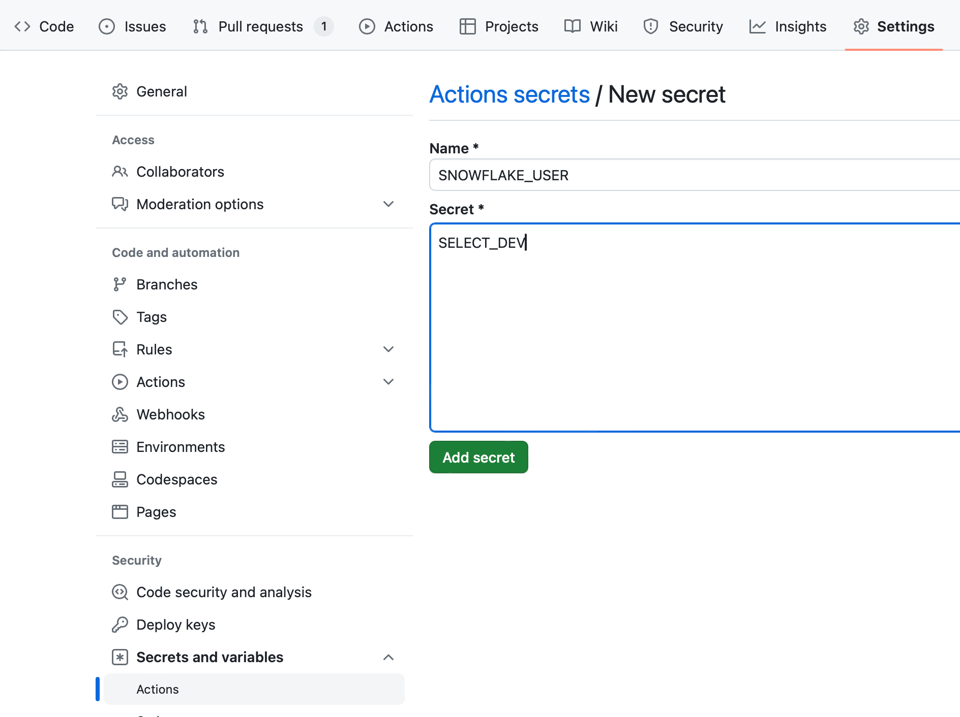
Para armazenar suas credenciais no nível do repositório nos Github Secrets: Seu Repositório > Settings > Secrets and variables > Actions > New repository secret
Com os seguintes valores:
SNOWFLAKE_ACCOUNT— Seu identificador de conta, com os dados de região/provider, por exemploselect_dev-productionouselect123.eu-west-1.awspara contas legadas.SNOWFLAKE_USER— Nome de usuário para loginSNOWFLAKE_PASSWORD— Senha de login
Verificações para rodar no CI
Ao fazer mudanças de infraestrutura em um repositório com Terraform, vale considerar alguns passos no seu CI para ajudar a revisar as alterações propostas:
terraform fmt -check— Confere a formatação da sua configuração Terraform. Parte da beleza do Terraform é a legibilidade, então este é um passo fundamental. O-checkfaz o comando falhar quando há formatação incorreta; sem ele, o comando vai ajudar a corrigir a formatação (melhor durante o desenvolvimento do que no CI).terraform validate— Roda uma validação básica, sem chamar serviços remotos, mas confere coisas como nomes de atributos, etc.terraform plan— Também útil em desenvolvimento, compara sua configuração Terraform mais recente com o estado remoto do serviço, ou seja, mostra quais mudanças estão prestes a ser aplicadas (sem aplicá-las). Esse passo é superútil no CI, pois exibe exatamente o que vai mudar e deve ser revisado antes da aprovação.
Juntando tudo, um exemplo de pipeline de CI no Github Actions poderia ser algo assim:
name: Terraform Snowflake CI
on:
pull_request:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Expandir código
Copie e cole o trecho acima em um arquivo como .github/workflows/ci.yml. Na próxima vez que você abrir um Pull Request, ele vai rodar as verificações na sua branch, que aparecerão assim no Github Actions:
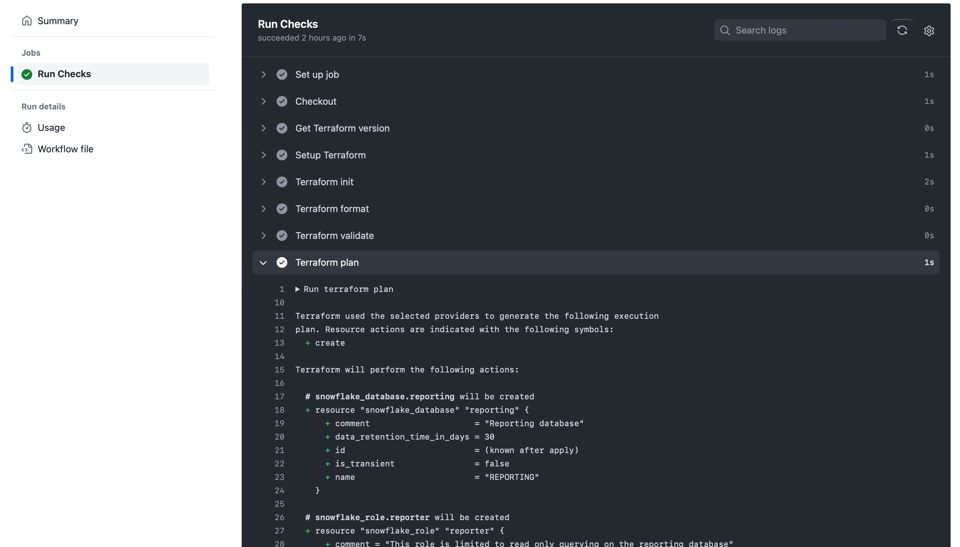
Exemplo de pipeline de CI em um Pull Request no Github Actions
( Extra opcional) — Se você conseguir manter várias réplicas completas do seu ambiente, dá para adicionar o passo terraform apply ao CI. O benefício é capturar erros que só aparecem quando o Snowflake processa as mudanças (e não o Terraform Provider), além de permitir validação manual no Snowflake e aproximar o fluxo de desenvolvimento dos fluxos típicos de engenharia.
A desvantagem é que isso provavelmente vai exigir uma conta Snowflake separada, ou no mínimo um conjunto separado de credenciais para isolar o ambiente de CI do ambiente de Deployment — o que foge do escopo deste artigo.
Mas, para deixar completo, adicionar isso ao ci.yml exigiria apenas um bloco final extra, assim:
- name: Terraform apply
id: terraform-apply
run: terraform apply -auto-approve
Fazendo deploy das suas mudanças
Assumindo que tudo deu certo nos passos acima e todo mundo está satisfeito com as alterações, dá para fazer o deploy via um pipeline de deployment.
terraform apply -auto-approve— Aplica as mudanças à sua infraestrutura. Quando executado via actions, o-auto-approvepermite que o Terraform prossiga sem intervenção do usuário, já que normalmente ele esperaria uma confirmação na linha de comando.
Um passo de deployment bem simples! No Github Actions, ficaria assim, em algum lugar como .github/workflows/deployment.yml:
name: Terraform Snowflake Deployment
on:
push:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Expandir código
Armazenando o Terraform State para o Github Actions
Para guardar um registro de como está a sua infraestrutura, o Terraform cria um arquivo de estado com a lista de todos os recursos e suas configurações atuais (ou que deveriam estar!).
Quando você faz mudanças via Pull Requests e Github, o Github Action precisa acessar o estado atual dos recursos, que é a infraestrutura resultante do terraform apply anterior. Então, como garantir que ele tenha acesso a esse estado vindo de uma execução anterior?
Entram em cena os Terraform Backends (para quem não usa Terraform Cloud), que permitem configurar seu setup do Terraform para armazenar o arquivo de estado em um lugar mais permanente, em vez do armazenamento local.
Para começar essa configuração, adicione um bloco de backend ao seu projeto Terraform, por exemplo, um arquivo [backend.tf](http://backend.tf). Abaixo, um exemplo desse bloco para um backend Amazon S3 (sem configuração de DynamoDB por enquanto).
terraform {
backend "s3" {
bucket = "terraform"
key = "state/snowflake.tfstate"
region = "eu-west-1"
}
}
Simples assim, mas aí vem a parte um pouco mais complicada: incorporar isso ao seu pipeline de deployment. Felizmente, uma vez autenticado na AWS, o Terraform cuida de atualizar o estado remoto para a gente!
Para isso, adicione mais 3 Github Secrets referentes à sua conta AWS:
AWS_ACCESS_KEY_ID— Identificador da chave de acesso da sua conta AWSAWS_SECRET_ACCESS_KEY— Segredo da chave de acessoAWS_REGION— Região da AWS, por exemploeu-west-1
E atualize seu ci.yml/deployment.yml para incluir o passo a seguir (ou uma autenticação parecida) antes de rodar qualquer comando do Terraform.
- name: Authenticate against production account
uses: "aws-actions/configure-aws-credentials@v2"
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
No geral, um pipeline básico para o workflow de Terraform com Snowflake no Github Actions ficaria mais ou menos assim:
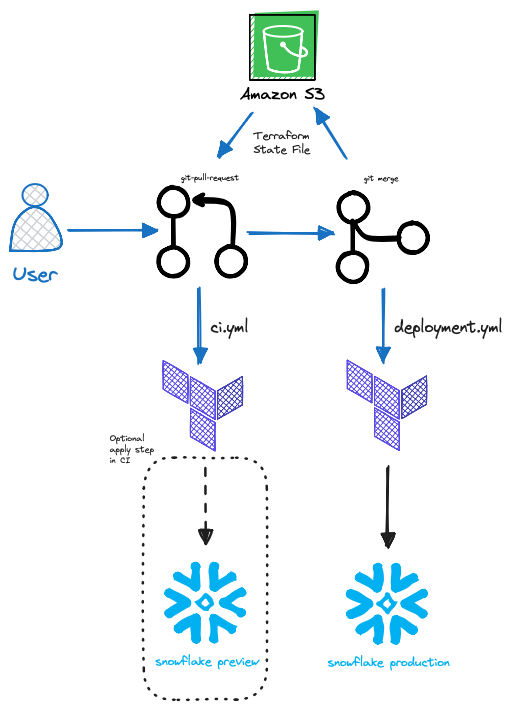
Exemplos de Terraform com Snowflake
Se você está procurando um ponto de partida, alguns exemplos básicos dos principais conceitos do Snowflake ficam mais ou menos assim. Para começar, vamos criar um warehouse (X-small, é claro 😉).
resource "snowflake_warehouse" "reporting_warehouse" {
name = "reporting_wh"
comment = "Warehouse for reporting and BI tools"
warehouse_size = "x-small"
}
Show, já temos como consultar os dados no Snowflake — mas, até aqui, nenhum lugar para armazená-los. Então vamos adicionar um bom e velho banco de dados.
resource "snowflake_database" "reporting" {
comment = "Reporting database"
data_retention_time_in_days = 30
name = "REPORTING"
}
Coisa linda. E, para fechar, vamos criar uma role no Snowflake e concedê-la ao nosso usuário de reporting.
1
2resource "snowflake_role" "reporter" {
3 name = "REPORTER"
4 comment = "This role is limited to read only querying on the reporting database"
5}
6
7resource "snowflake_role_grants" "reporter" {
8 role_name = snowflake_role.reporter.name
9 roles = [\
\
10 ]
11 users = [\
\
12 snowflake_user.reporting_user.name\
\
13 ]
14}
Esse último exemplo mostra como o Terraform cria referências entre objetos: o snowflake_role_grants depende dos recursos snowflake_role e snowflake_user. É assim que o Terraform determina a ordem em que vai executar o SQL.
Mais exemplos
Para um exemplo funcional deste artigo, dê uma olhada no repositório do Github abaixo. Fazer um fork e criar um Codespace é uma forma rápida de começar!
GtheSheep/terraform-snowflake-example
Para uma configuração prática do Terraform com Snowflake, confira o guia oficial da própria Snowflake sobre como começar: Terraforming Snowflake.
Desafios com Snowflake e Terraform
Como toda ferramenta, o Terraform tem suas armadilhas e, às vezes, os comportamentos ou casos de uso do Snowflake até intensificam isso. Vamos passar por alguns:
Cobertura completa de recursos
Apesar de haver um pessoal incrível mantendo o Snowflake Terraform Provider, às vezes pode demorar um pouco para colocá-lo em dia com as funcionalidades mais novas do Snowflake. Em outros casos, é uma decisão de design não permitir explicitamente que algo seja feito via Terraform (situação mais rara). Isso significa que ainda pode haver necessidade de fazer parte do gerenciamento direto no Snowflake.
Além disso, alguns recursos não estão totalmente refinados com todas as opções que o Snowflake oferece, o que pode exigir rodar alguns comandos SQL "bônus" no Snowflake depois que o recurso for implantado.
Como exemplo, o equivalente a GRANT SELECT ON ALL TABLES IN SCHEMA <schema> TO ROLE <role> não estava diretamente disponível no provider. Durante anos, era preciso achar uma forma de iterar sobre os objetos do schema ou rodar SQL extra. Felizmente, agora existe o parâmetro on_all!
Propriedade e ciclo de vida
Ao decidir quais recursos do Snowflake gerenciar via Terraform, leve em conta o ciclo de vida e a propriedade de cada um.
Ciclo de vida pode significar simplesmente subir e derrubar coisas para testes, POCs, etc., e avaliar se vale o esforço. Mas vai além: pense em tabelas transitórias, ou em tabelas que são frequentemente derrubadas e recriadas em momentos independentes dos deployments do Terraform (dbt, é com você 👀). Esse tipo de atividade faz o Snowflake ficar bem dessincronizado do estado do Terraform, e seus deployments acabam numa sinuca de bico 🥒.
Quanto à propriedade, decida qual processo é, de fato, dono desses objetos. O Terraform poderia ser usado para delimitar o ambiente em que esses processos vão operar? (Por exemplo: Terraform cria um database no qual o dbt fica livre para gerenciar os schemas 🤷♂️).
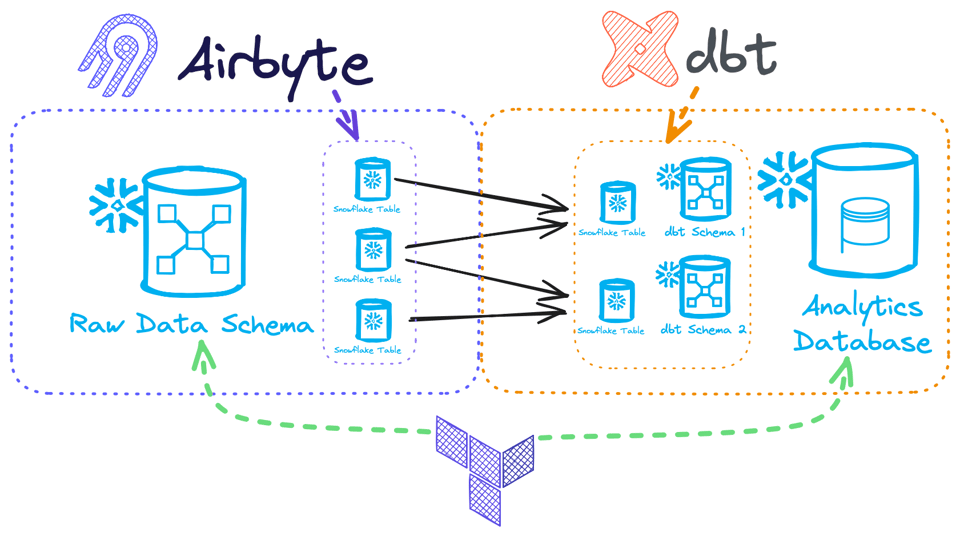
Como exemplo, vamos supor que temos uma ferramenta de carga de dados brutos, o Airbyte, e uma ferramenta de transformação, o dbt:
- O Airbyte geralmente recebe um schema de destino para carregar os dados. A partir daí, deixamos ele ser dono e gerenciar as tabelas dentro daquele schema do Snowflake, adicionando colunas e tabelas conforme precisar (supondo que, por padrão, selecionamos todos os recursos disponíveis na origem). Nesse caso, não vamos querer gerenciar as tabelas com o Terraform, porque elas rapidamente ficariam desatualizadas pela atividade do Airbyte. Mas podemos gerenciar o schema com Terraform — tanto a criação quanto o controle de acesso — já que isso é imutável da perspectiva do Airbyte.
- O dbt poderia, então, transformar os dados em vários schemas do Snowflake, criando-os e montando tabelas em cada um. Aqui, não faria sentido nem gerenciar os schemas com Terraform, já que o dbt tem total propriedade sobre eles e até pode cuidar do controle de acesso. Mas o database é o espaço em que o dbt pode operar, então dá para provisioná-lo via Terraform.
Esses dois processos rodam totalmente independentes do seu pipeline do Terraform, então o estado ou desconheceria as mudanças feitas por eles, gerando muito ruído no seu terraform plan, ou pior, sobrescreveria as alterações feitas pelo Airbyte/dbt!
Gerenciando vários repositórios
Quando os recursos são necessários e/ou acessados a partir de vários lugares, as coisas podem ficar um pouco complicadas.
Como já dissemos, é fundamental deixar claro onde está a propriedade dos recursos do Snowflake, porque definições conflitantes podem fazer com que deployments diferentes sobrescrevam as configurações uns dos outros. Por exemplo, dois repos concedendo USAGE em um database para roles diferentes (problema parcialmente mitigado hoje pelo parâmetro enable_multiple_grants).
Dependências podem ser gerenciadas via módulos do Terraform, lendo informações de data sources, e por aí vai. Mas, para evitar que essa flexibilidade saia do controle, monte um plano sólido de como vai estruturar o gerenciamento dos recursos. Por exemplo: um repo central cuidando de roles/users/grants/warehouses/etc. do Snowflake — todos os elementos realmente centrais de uma conta — e permitir que os outros provisionem seus próprios databases/tasks/procedures conforme a necessidade.
Gary James·Senior Analytics Engineer at Beauty Pie
Gary é Senior Analytics Engineer na Beauty Pie, uma empresa de maquiagem e skincare. Com mais de uma década de experiência em praticamente qualquer cargo com a palavra 'dados' que você possa imaginar, ele é fã de tudo que envolve dados/engenharia. Gary é um contribuidor muito ativo em diversos projetos open source da stack de dados. Ele criou o Terraform provider do dbt cloud e contribui com outros projetos do ecossistema, como dbt, elementary data, lightdash e Meltano.