Cos'è Terraform?
Terraform è uno strumento di Infrastructure as Code ( IaC - niente più smanettamenti con le GUI!) che permette di gestire la configurazione dei servizi tramite l'utilizzo di provider (di solito specifici per servizio: Snowflake, AWS, dbt Cloud, ecc.).
I provider stanno a Terraform come i package stanno a Python: insiemi preconfezionati di interfacce riutilizzabili pensati per scopi specifici. Continuando l'analogia, il Terraform registry sarebbe l'equivalente di Pypi.
Perché usare Terraform per gestire l'infrastruttura Snowflake?
Ci sono 3 ottime ragioni per cui dovrebbe valutare l'uso di Terraform per gestire la sua infrastruttura Snowflake.
1. Per versionare la configurazione
Con Terraform la configurazione dell'infrastruttura risiede in un repository sotto controllo di versione come Github. Questo significa ottenere tutti i consueti vantaggi della gestione del codice su Github: rollback semplici, anteprima delle modifiche, cronologia di lungo periodo e le preziosissime review dei colleghi prima di rilasciare qualsiasi modifica.
Github a parte, Terraform mantiene anche uno stato interno delle risorse della sua infrastruttura, contribuendo a proteggerla da modifiche inattese grazie al diff mostrato a ogni deployment.
2. Scalabilità
Terraform consente di riutilizzare le configurazioni, permettendo di scalare con facilità i deployment Snowflake. Al livello più alto significa poter gestire comodamente più account Snowflake da un unico punto: un grande vantaggio di Terraform. Inoltre, la possibilità di creare, aggiornare o rimuovere risorse in modo scalabile con configurazioni template condivise tramite loop o moduli può ridurre drasticamente i tempi di gestione delle attività più estese.
Aiuta anche a far scalare la collaborazione interna e le best practice. Offre un linguaggio comune tra repository, team e persino discipline diverse: una marcia in più per qualsiasi team dati al giorno d'oggi! Avere strumenti condivisi in tutta l'organizzazione riduce anche il tempo speso a mantenere pipeline di deployment su misura, se tutti seguono lo stesso playbook.
3. Un modo più semplice per gestire le dipendenze
Terraform costruisce un grafo delle dipendenze tra le risorse a partire dagli oggetti definiti, il che significa che può segnalarle se sta provando a rimuovere risorse necessarie a valle, come eliminare una tabella usata in uno stream.
Terraform (o un qualsiasi IaC) fa al caso suo?
Anche nelle implementazioni più approssimative, gli strumenti IaC fanno comunque una cosa: la costringono a mettere nero su bianco la configurazione! E a chi non piace un po' di buona documentazione? Se per giunta è anche sotto controllo di versione, è probabile che ci sia almeno un accenno al perché quella configurazione è stata aggiunta o a quando: tutto contesto prezioso.
L'altro lato della medaglia è che l'IaC, per sua natura, aggiunge un livello in più rispetto alla piattaforma con cui si vuole interagire. E più ci si affida a tecniche come i moduli, più la configurazione può allontanarsi, finendo per risultare oscura a chi la deve usare o, peggio, introducendo fragilità nello stack. Le astrazioni vanno quindi adottate con criterio e visione strategica.
La configurazione di questo servizio è davvero così importante? Il gioco vale la candela? 🍊
Ogni aspetto dell'infrastruttura comporta dei rischi, come errori di configurazione e downtime. Portare le configurazioni (esistenti o nuove) su un IaC non è a costo zero, quindi valuti quanto questo componente sia vitale per il business prima di buttarsi.
Può investire il tempo necessario per impostarlo e mantenerlo? Snowflake è abbastanza centrale per il business da giustificarlo? Il recovery time di Snowflake è un fattore rilevante? Deve mettere in conto la migrazione delle risorse Snowflake esistenti su Terraform?
Chi amministra questo servizio preferisce gestirlo via codice?
A volte gli amministratori non vogliono (o non sono in grado!) di passare ogni volta da codice e version control per apportare una modifica e, se le conseguenze di un errore sono tollerabili, non ostacoli la flessibilità!
Detto questo, Terraform (o altri IaC) può anche offrire un linguaggio comune tra i team di sviluppo, portando coerenza e riutilizzabilità (si vedano i Terraform Modules) nella sua organizzazione, favorendo un approccio più democratico all'amministrazione e alleggerendo il carico che spesso grava sulle figure senior.
Il provider copre le sue esigenze? Esiste un provider?
Non tutto ha un provider disponibile in Terraform, e anche quando esiste, talvolta passa un po' di tempo tra il rilascio di nuove funzionalità e il loro recepimento nel provider. Vale quindi la pena verificare ciò che è disponibile prima di partire con un provider, o prima di intraprendere la strada di costruirne uno proprio.
Come usare Terraform con Snowflake
Che stia sviluppando in locale, in Codespaces o avviando un setup di produzione, i passaggi iniziali sono piuttosto simili. Vediamo quindi alcuni dei concetti di base per usare un qualsiasi provider Terraform.
Il provider Terraform per Snowflake
Consultando il Terraform Registry troverà vari provider e moduli legati a Snowflake, ma quello su cui ci concentreremo è il provider ora mantenuto da Snowflake stessa: lo Snowflake Terraform Registry ufficiale.
Setup iniziale
Per avviare un progetto Terraform per Snowflake:
- Installi Terraform - veda la documentazione, ad esempio tramite Homebrew su Mac OS X:
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
terraform -help
- Crei una nuova directory/repository
mkdir snowflake-terraform-example
cd snowflake-terraform-example
- Crei un file
[versions.tf](http://versions.tf)che conterrà le versioni dei provider Terraform che utilizzerà. Per questo esempio dovrebbe apparire più o meno così:
terraform {
required_version = ">= 1.0.0"
required_providers {
snowflake = {
source = "snowflake-labs/snowflake"
version = "0.84.1"
}
}
}
- Per configurare il provider, crei un file
[providers.tf](http://providers.tf): qui imposterà i provider che utilizza. In fase di test può passare le credenziali direttamente da qui, ma quando il codice viene archiviato in un repository è meglio adottare una soluzione basata su variabili d'ambiente (così da non esporre i suoi segreti!). Un esempio potrebbe essere:
provider "snowflake" {
role = "SYSADMIN"
}
Come fare il deploy di Terraform per Snowflake con Github Actions
Configurare le credenziali
Per interagire con Snowflake via Terraform in Github Actions servono delle credenziali per accedere a Snowflake. Le opzioni sono diverse: Username/Password, Private Key, OAuth, ecc., ma per questo esempio useremo Username/Password. Per le altre modalità di autenticazione consulti la documentazione del provider.
Per memorizzare le credenziali a livello di repository in Github Secrets: Il suo repository > Settings > Secrets and variables > Actions > New repository secret
Con i seguenti valori:
SNOWFLAKE_ACCOUNT- Il suo account identifier, con i dettagli di regione/provider, ad esempioselect_dev-productionoppureselect123.eu-west-1.awsper gli account legacy.SNOWFLAKE_USER- Username di loginSNOWFLAKE_PASSWORD- Password di login
Controlli da eseguire in CI
Quando si effettuano modifiche all'infrastruttura in un repository che contiene Terraform, ci sono alcuni passaggi utili da inserire in CI per agevolare la revisione delle modifiche proposte:
terraform fmt -check- Verifica la formattazione della configurazione Terraform. Una parte del bello di Terraform è proprio la leggibilità, quindi è un passaggio chiave. Il flag-checkfa fallire il job in caso di formattazione errata; senza, il comando aiuta a correggerla (meglio in sviluppo che in CI).terraform validate- Esegue una validazione di base: non chiama servizi remoti ma controlla cose come i nomi degli attributi e simili.terraform plan- Utile anche in sviluppo, confronta l'ultima configurazione Terraform con lo stato remoto del servizio: in pratica calcola quali modifiche stanno per essere applicate (senza applicarle). Questo step è utilissimo in CI, perché mostra esattamente cosa sta per cambiare e dovrebbe essere revisionato prima dell'approvazione.
Mettendo tutto insieme, un esempio di pipeline CI in Github Actions potrebbe essere il seguente:
name: Terraform Snowflake CI
on:
pull_request:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Espandi codice
Copi e incolli quanto sopra in un file come .github/workflows/ci.yml: alla prossima Pull Request verranno eseguiti dei controlli sul suo branch, che appariranno così in Github Actions:
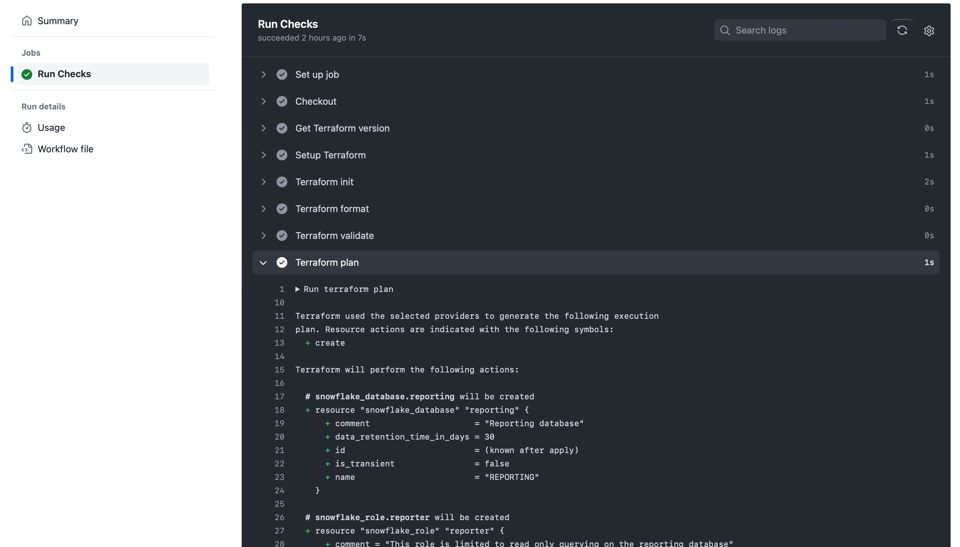
Esempio di pipeline CI su una Pull Request in Github Actions
( Extra opzionale) - Se ha la possibilità di gestire più repliche complete del suo ambiente, può anche aggiungere il passaggio terraform apply alla CI. I vantaggi sarebbero intercettare gli errori che vengono sollevati solo da Snowflake e non dal provider Terraform al momento dell'applicazione delle modifiche, oltre a consentire una validazione manuale in Snowflake e ad avvicinare il flusso di sviluppo a quello tipico dell'engineering.
Lo svantaggio è che probabilmente richiederebbe un account Snowflake separato, o quantomeno un set di credenziali distinto, per scollegare l'ambiente di CI da quello di Deployment: un tema che esula dallo scopo di questo articolo.
Ma, per completezza, aggiungere questo a ci.yml richiederebbe semplicemente un ulteriore blocco finale come questo:
- name: Terraform apply
id: terraform-apply
run: terraform apply -auto-approve
Deploy delle modifiche
Supponendo che tutto sia a posto e che le modifiche soddisfino tutti, possiamo distribuirle tramite una pipeline di deployment.
terraform apply -auto-approve- Applica le modifiche all'infrastruttura. Quando viene eseguito tramite actions,-auto-approvepermette a Terraform di proseguire senza intervento dell'utente, dato che da linea di comando si aspetterebbe una conferma.
Quindi uno step di deployment davvero semplice! In Github Actions, in un file come .github/workflows/deployment.yml, apparirebbe così:
name: Terraform Snowflake Deployment
on:
push:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Espandi codice
Conservare lo stato di Terraform per Github Actions
Per tenere memoria della struttura della sua infrastruttura, Terraform crea un file di stato con l'elenco di tutte le risorse e la loro configurazione attuale (o quella che dovrebbero avere!).
Quando si effettuano modifiche tramite Pull Request e Github, la Github Action dovrà accedere allo stato corrente delle risorse, cioè all'infrastruttura risultante dal precedente terraform apply. Come garantirne quindi l'accesso a partire da un'esecuzione precedente?
Entrano in gioco i Terraform Backends (per chi non usa Terraform Cloud): permettono di configurare Terraform per archiviare il file di stato in un luogo più stabile rispetto alla memoria locale.
Per iniziare deve aggiungere un blocco backend al suo progetto Terraform, ad esempio un file [backend.tf](http://backend.tf). Qui sotto un esempio per un backend Amazon S3 (per ora senza configurazione DynamoDB).
terraform {
backend "s3" {
bucket = "terraform"
key = "state/snowflake.tfstate"
region = "eu-west-1"
}
}
Abbastanza semplice, ma poi viene la parte un po' più ostica: integrare il tutto nella pipeline di deployment. Per fortuna, una volta autenticato su AWS, Terraform si occuperà di aggiornare lo stato remoto al posto suo!
Per farlo, aggiunga altri 3 Github Secrets per il suo account AWS:
AWS_ACCESS_KEY_ID- Identificatore della chiave di accesso del suo account AWSAWS_SECRET_ACCESS_KEY- Secret della chiave di accessoAWS_REGION- Regione AWS, ad esempioeu-west-1
E aggiorni il suo ci.yml/deployment.yml aggiungendo il seguente step (o un'autenticazione analoga) prima di eseguire qualsiasi comando Terraform.
- name: Authenticate against production account
uses: "aws-actions/configure-aws-credentials@v2"
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
Nel complesso, una pipeline indicativa per il workflow Terraform Snowflake in Github Actions avrebbe questo aspetto:
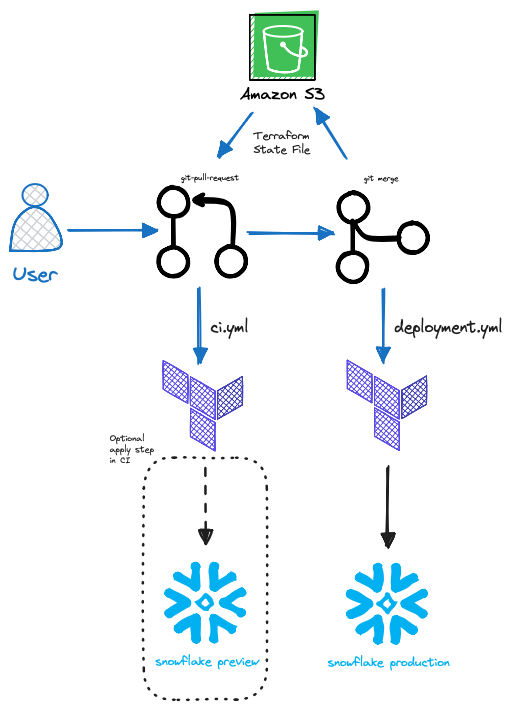
Esempi di Terraform per Snowflake
Se cerca un punto di partenza, ecco alcuni esempi di base dei concetti chiave di Snowflake. Per cominciare, creiamo un warehouse (X-small, ovviamente 😉).
resource "snowflake_warehouse" "reporting_warehouse" {
name = "reporting_wh"
comment = "Warehouse for reporting and BI tools"
warehouse_size = "x-small"
}
Ottimo: ora abbiamo un modo per interrogare i dati Snowflake, ma finora manca un posto dove archiviarli. Aggiungiamo allora un buon vecchio database.
resource "snowflake_database" "reporting" {
comment = "Reporting database"
data_retention_time_in_days = 30
name = "REPORTING"
}
Perfetto. E infine creiamo un ruolo Snowflake e lo assegniamo al nostro utente per il reporting.
1
2resource "snowflake_role" "reporter" {
3 name = "REPORTER"
4 comment = "This role is limited to read only querying on the reporting database"
5}
6
7resource "snowflake_role_grants" "reporter" {
8 role_name = snowflake_role.reporter.name
9 roles = [\
\
10 ]
11 users = [\
\
12 snowflake_user.reporting_user.name\
\
13 ]
14}
L'ultimo esempio mostra come Terraform crei riferimenti tra gli oggetti: snowflake_role_grants dipende dalle risorse snowflake_role e snowflake_user, ed è così che Terraform determina l'ordine di esecuzione dell'SQL.
Altri esempi
Per un esempio funzionante di questo articolo dia un'occhiata al repository Github qui sotto: farne un fork e creare un Codespace è un modo rapido per iniziare!
GtheSheep/terraform-snowflake-example
Per una configurazione pratica di Terraform per Snowflake, dia un'occhiata alla guida ufficiale di Snowflake: Terraforming Snowflake.
Sfide con Snowflake e Terraform
Come ogni strumento, Terraform ha le sue insidie, e talvolta i comportamenti o i casi d'uso di Snowflake possono persino accentuarle. Vediamone alcune:
Copertura completa delle risorse
Anche se c'è un ottimo team che mantiene il provider Terraform di Snowflake, a volte può volerci un po' di tempo per allinearsi alle ultime novità di Snowflake; in altri casi è una scelta progettuale non consentire esplicitamente che qualcosa venga fatto tramite Terraform (situazione più rara). Questo può significare che resta comunque la necessità di gestire qualcosa direttamente in Snowflake.
A questo si aggiunge il fatto che alcune risorse non sono completamente rifinite con tutti gli optional che Snowflake mette a disposizione, il che può richiedere l'esecuzione di qualche comando SQL "bonus" in Snowflake dopo che la risorsa è stata distribuita.
Ad esempio, l'equivalente di GRANT SELECT ON ALL TABLES IN SCHEMA <schema> TO ROLE <role> non era direttamente disponibile nel provider: per anni richiedeva o di iterare sugli oggetti dello schema o di eseguire SQL aggiuntivo. Per fortuna ora esiste il parametro on_all!
Ownership e ciclo di vita
Quando decide quali risorse Snowflake gestire tramite Terraform, consideri il loro ciclo di vita e la loro ownership.
Il ciclo di vita può riferirsi al semplice creare e distruggere risorse al volo per test, POC, ecc., e al fatto che valga o meno la pena farlo, ma il discorso va oltre: pensi alle tabelle transient o a quelle che vengono frequentemente eliminate e ricreate indipendentemente dai deployment di Terraform (dbt, sto guardando te 👀). Questo tipo di attività può portare Snowflake a finire molto fuori sincrono rispetto allo stato di Terraform, e i deployment si ritroveranno in un bel pasticcio 🥒.
Per quanto riguarda l'ownership, decida quale processo sia il vero proprietario di quegli oggetti: si potrebbe usare Terraform per delimitare l'ambiente in cui questi processi devono operare? (Usare Terraform per un database in cui dbt può gestire lo schema 🤷♂️).
Come esempio, supponiamo di avere uno strumento di caricamento dati grezzi, Airbyte, e uno di trasformazione, dbt:
- Airbyte di norma riceve uno schema di destinazione in cui caricare i dati e, da quel momento in poi, gli permettiamo di possedere e gestire le tabelle all'interno di quello schema Snowflake, aggiungendo colonne e tabelle a seconda delle necessità (ipotizziamo di selezionare per default tutte le risorse disponibili dalla sorgente). In questo caso non vorremmo gestire le tabelle con Terraform, perché verrebbero rapidamente disallineate dall'attività di Airbyte, ma potremmo gestire lo schema con Terraform, sia per la creazione sia per il controllo degli accessi, dato che è immutabile dal punto di vista di Airbyte.
- dbt potrebbe poi trasformare i dati in più schemi Snowflake, creandoli e popolandoli di tabelle. Qui non avrebbe senso gestire nemmeno gli schemi con Terraform, perché dbt ne ha piena ownership e potrebbe persino occuparsi del controllo degli accessi, ma il database è l'ambito in cui dbt è autorizzato a operare, quindi potremmo provisionarlo tramite Terraform.
Entrambi i processi girano in modo del tutto indipendente dalla sua pipeline Terraform, quindi lo stato o non sarebbe a conoscenza delle modifiche apportate da questi altri processi e genererebbe molto rumore nel suo terraform plan, oppure, peggio, sovrascriverebbe le modifiche fatte da Airbyte/dbt!
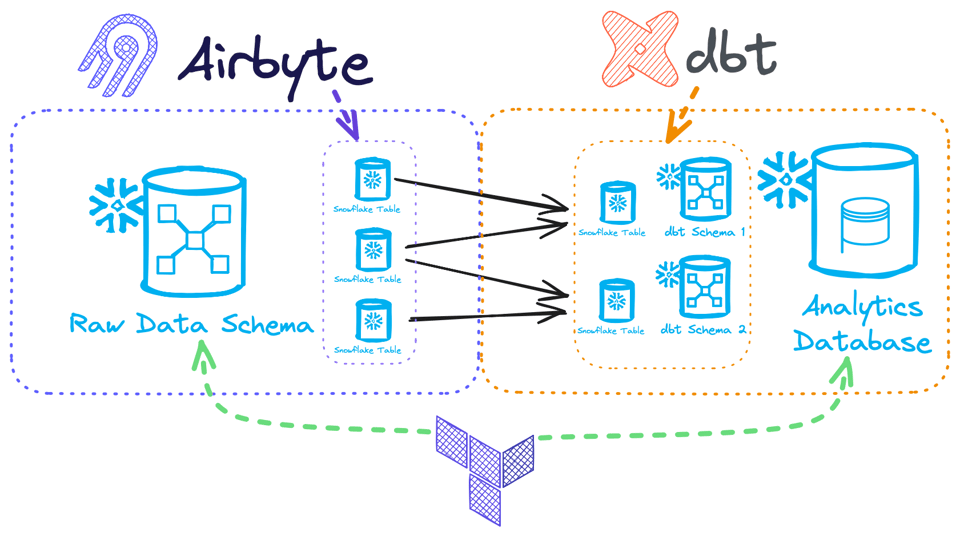
Gestire più repository
Quando le risorse sono richieste e/o utilizzate da più punti, le cose possono complicarsi un po'.
Come accennato sopra, è fondamentale stabilire con chiarezza dove risiede l'ownership delle risorse Snowflake, perché definizioni in conflitto possono far sì che deployment diversi sovrascrivano reciprocamente le configurazioni: ad esempio se 2 repository concedono USAGE su un database a ruoli diversi (problema oggi in parte mitigato dal parametro enable_multiple_grants).
Le dipendenze possono essere gestite tramite moduli Terraform, leggendo dati dai data source e così via, ma per evitare che questa flessibilità sfugga di mano, definisca un piano solido su come strutturare la gestione delle risorse. Ad esempio: un repository centrale che gestisce ruoli, utenti, grant, warehouse Snowflake e tutti gli elementi davvero centrali di un account, lasciando poi che altri provisionino i propri database, task e procedure secondo necessità.
Gary James·Senior Analytics Engineer presso Beauty Pie
Gary è Senior Analytics Engineer presso Beauty Pie, azienda di makeup e skincare. Con oltre un decennio di esperienza in praticamente qualsiasi ruolo "data" si possa immaginare, è un grande appassionato di tutto ciò che riguarda dati ed engineering. Gary è un contributor molto attivo a diversi progetti open source dello stack dati. Ha creato il provider Terraform per dbt cloud e contribuisce ad altri progetti dell'ecosistema come dbt, elementary data, lightdash e Meltano.