Qu'est-ce que Terraform ?
Terraform est un outil d'Infrastructure as Code ( IaC — fini les bidouillages dans une interface graphique !) qui permet de gérer la configuration de vos services à l'aide de providers (généralement spécifiques à un service : Snowflake, AWS, dbt Cloud, etc.).
Les providers sont à Terraform ce que les packages sont à Python : des briques d'interfaces réutilisables, pré-packagées et conçues pour un usage précis. Pour filer l'analogie, le Terraform registry jouerait à peu près le rôle de PyPI.
Pourquoi utiliser Terraform pour gérer son infrastructure Snowflake ?
Trois raisons solides justifient d'envisager Terraform pour gérer votre infrastructure Snowflake.
1. Versionner votre configuration
Avec Terraform, la configuration de votre infrastructure est stockée dans un dépôt versionné comme GitHub. Vous bénéficiez ainsi de tous les avantages classiques du code sur GitHub : rollback simplifié, prévisualisation des changements, historique long terme et — cerise sur le gâteau — les précieuses revues de vos collègues avant toute mise en production.
Au-delà de GitHub, Terraform tient à jour son propre état des ressources de votre infrastructure, ce qui aide à prévenir les changements inattendus en présentant un diff à chaque déploiement.
2. Le passage à l'échelle
Terraform favorise la réutilisation des configurations et facilite ainsi la montée en charge de vos déploiements Snowflake. À haut niveau, cela veut dire pouvoir piloter plusieurs comptes Snowflake depuis un seul endroit — un atout majeur. Et la possibilité de créer, mettre à jour ou supprimer des ressources à grande échelle à partir de configurations templatées communes via des loops ou des modules réduit considérablement le temps consacré à ces tâches répétitives.
Terraform aide également à faire passer à l'échelle la collaboration interne et les bonnes pratiques. Il offre un langage commun entre les dépôts, les équipes et même les disciplines — précieux pour toute équipe data aujourd'hui ! Un outillage unifié à l'échelle de l'organisation permet aussi d'éviter de maintenir des pipelines de déploiement sur mesure, dès lors que chacun joue la même partition.
3. Une gestion des dépendances simplifiée
Terraform construit un graphe de dépendances entre vos ressources à partir des objets que vous définissez. Il peut donc vous alerter lorsque vous tentez de supprimer une ressource utilisée en aval, par exemple une table consommée par un stream.
Terraform (ou tout autre IaC) est-il fait pour vous ?
Même dans l'implémentation la plus bancale, un outil IaC a au moins un mérite : il vous force à écrire votre configuration ! Et qui n'apprécie pas une bonne documentation ? Si en plus elle vit dans un système de versioning, on trouvera probablement la trace du pourquoi et du quand de chaque ajout de configuration — autant de contexte précieux.
Revers de la médaille : l'IaC est par nature un cran en deçà de la plateforme avec laquelle vous voulez interagir. Plus vous vous appuyez sur des techniques comme les modules, plus la configuration peut s'éloigner de la réalité du terrain, ce qui peut créer de l'opacité pour ceux qui l'utilisent, voire fragiliser votre stack. Les abstractions doivent donc être pensées avec soin et stratégie.
La configuration de ce service est-elle vraiment critique ? Le jeu en vaut-il la chandelle ? 🍊
Chaque aspect de votre infrastructure comporte ses risques : mauvaise configuration, indisponibilité, etc. Faire basculer vos configurations (existantes ou nouvelles) vers de l'IaC n'est pas gratuit : évaluez d'abord à quel point ce composant est vital pour votre activité.
Avez-vous le temps à investir dans la mise en place et la maintenance ? Snowflake est-il suffisamment central pour le justifier ? Le temps de reprise sur Snowflake entre-t-il en jeu ? Faut-il prévoir la migration de ressources Snowflake existantes vers Terraform ?
Les administrateurs de ce service préfèrent-ils travailler dans le code ?
Parfois, vos administrateurs ne voudront pas (ou ne pourront pas !) passer par du code et un système de versioning à chaque modification ; si les conséquences d'une erreur restent acceptables, ne bridez pas leur flexibilité !
Cela dit, Terraform (ou d'autres IaC) peut aussi offrir un langage commun aux équipes de développement, apporter une certaine cohérence et favoriser la réutilisation (voir les modules Terraform) au sein de votre organisation, en démocratisant l'administration et en allégeant la charge des profils seniors.
Le provider couvre-t-il vos besoins ? Existe-t-il seulement un provider ?
Tout n'a pas de provider Terraform disponible, et quand c'est le cas, il peut y avoir un délai entre la sortie d'une nouvelle fonctionnalité et son intégration dans le provider. Mieux vaut donc vérifier ce qui existe avant de se lancer avec un provider — ou de partir sur le développement du vôtre.
Comment utiliser Terraform avec Snowflake
Que vous développiez en local, dans Codespaces ou que vous montiez un environnement de production, les étapes initiales restent assez similaires. Voyons quelques concepts de base communs à tout provider Terraform.
Le provider Terraform pour Snowflake
En parcourant le Terraform Registry, vous trouverez plusieurs providers et modules liés à Snowflake. Celui que nous retenons ici est désormais maintenu par Snowflake lui-même : le Snowflake Terraform Registry officiel.
Mise en place
Pour démarrer un projet Terraform pour Snowflake :
- Installez Terraform — voir la documentation, par exemple via Homebrew pour Mac OS X :
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
terraform -help
- Créez un nouveau répertoire ou dépôt
mkdir snowflake-terraform-example
cd snowflake-terraform-example
- Créez un fichier
[versions.tf](http://versions.tf), qui contiendra les versions des providers Terraform que vous utiliserez. Pour cet exemple, il devrait ressembler à ceci :
terraform {
required_version = ">= 1.0.0"
required_providers {
snowflake = {
source = "snowflake-labs/snowflake"
version = "0.84.1"
}
}
}
- Pour configurer votre provider, créez un fichier
[providers.tf](http://providers.tf). C'est ici que vous paramétrerez les providers utilisés. Vous pouvez y renseigner vos identifiants pour des tests rapides, mais privilégiez une solution à base de variables d'environnement dès que le code est stocké dans un dépôt (afin de ne pas exposer vos secrets !). Voici un exemple :
provider "snowflake" {
role = "SYSADMIN"
}
Comment déployer Terraform pour Snowflake avec GitHub Actions
Configurer vos identifiants
Pour interagir avec Snowflake via Terraform dans GitHub Actions, il faudra des identifiants de connexion à Snowflake. Plusieurs options existent : nom d'utilisateur/mot de passe, clés privées, OAuth, etc. Dans cet exemple, nous resterons sur le couple nom d'utilisateur/mot de passe ; pour les autres méthodes d'authentification, reportez-vous à la documentation du provider.
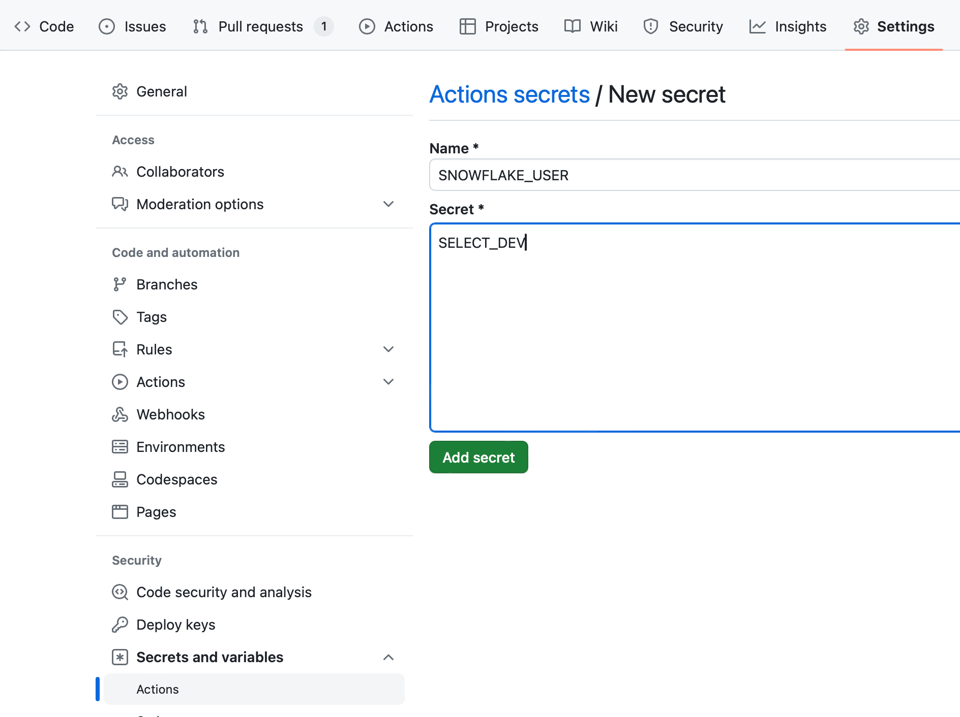
Pour stocker vos identifiants au niveau du dépôt dans GitHub Secrets : Votre dépôt > Settings > Secrets and variables > Actions > New repository secret
Avec les valeurs suivantes :
SNOWFLAKE_ACCOUNT— Votre identifiant de compte, avec les détails de région/provider, par exempleselect_dev-productionouselect123.eu-west-1.awspour les comptes legacy.SNOWFLAKE_USER— Nom d'utilisateur de connexionSNOWFLAKE_PASSWORD— Mot de passe de connexion
Vérifications à exécuter en CI
Lorsque vous apportez des changements d'infrastructure dans un dépôt contenant du Terraform, certaines étapes peuvent utilement venir enrichir votre CI pour aider à examiner les modifications proposées :
terraform fmt -check— Vérifie le formatage de votre configuration Terraform. La lisibilité étant l'un des grands atouts de Terraform, c'est une étape clé ; l'option-checkfait échouer la commande en cas de mauvais formatage. Sans elle, la commande corrige automatiquement le formatage (à privilégier en développement plutôt qu'en CI).terraform validate— Effectue une validation de base, sans appeler de services distants, mais contrôle par exemple les noms d'attributs.terraform plan— Également utile en développement, cette commande compare votre dernière configuration Terraform à l'état distant du service ; autrement dit, elle détermine quels changements vont être appliqués (sans les appliquer). Très utile en CI : elle montre exactement ce qui va changer, et doit être passée en revue avant validation.
En combinant tout cela, un exemple de pipeline CI dans GitHub Actions pourrait ressembler à ceci :
name: Terraform Snowflake CI
on:
pull_request:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Déplier le code
Copiez-collez ce qui précède dans un fichier tel que .github/workflows/ci.yml. À la prochaine Pull Request, des vérifications seront exécutées sur votre branche, comme ceci dans GitHub Actions :
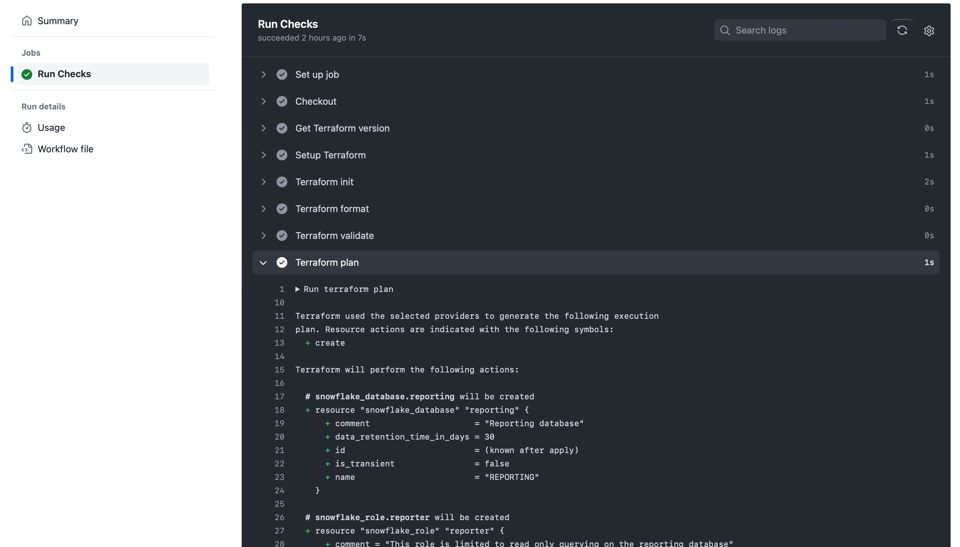
Exemple de pipeline CI sur une Pull Request dans GitHub Actions
( Option supplémentaire) — Si vous pouvez vous offrir plusieurs répliques complètes de votre environnement, vous pouvez aussi ajouter l'étape terraform apply à votre CI. L'intérêt : détecter les erreurs qui ne remontent que côté Snowflake (et non côté provider Terraform) au moment où les changements sont appliqués, permettre une validation manuelle dans Snowflake, et rapprocher le flux de développement de pratiques d'ingénierie plus classiques.
L'inconvénient : il faudra probablement un compte Snowflake distinct, ou au minimum un jeu d'identifiants séparé pour isoler votre environnement CI de votre environnement de déploiement — ce qui dépasse le cadre de cet article.
Pour être complet, ajouter cela à ci.yml ne demanderait qu'un bloc final supplémentaire, comme suit :
- name: Terraform apply
id: terraform-apply
run: terraform apply -auto-approve
Déployer vos changements
En supposant que tout va bien et que chacun valide les changements, nous pouvons les déployer via un pipeline dédié.
terraform apply -auto-approve— Applique les changements à votre infrastructure. Lors d'une exécution via Actions,-auto-approvepermet à Terraform de poursuivre sans intervention de l'utilisateur, alors qu'il attendrait une confirmation en ligne de commande.
Une étape de déploiement vraiment simple, donc ! Voici à quoi cela ressemble dans GitHub Actions, par exemple dans .github/workflows/deployment.yml :
name: Terraform Snowflake Deployment
on:
push:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Déplier le code
Stocker l'état Terraform pour GitHub Actions
Pour garder en mémoire l'état de votre infrastructure, Terraform crée un fichier d'état listant toutes vos ressources et leur configuration actuelle (ou attendue !).
Or, lorsque vous apportez des changements via des Pull Requests sur GitHub, la GitHub Action doit accéder à l'état actuel des ressources, à savoir l'infrastructure issue du précédent terraform apply. Comment garantir cet accès d'une exécution à l'autre ?
C'est là qu'interviennent les Terraform Backends (pour ceux qui n'utilisent pas Terraform Cloud) : ils permettent de configurer Terraform pour stocker son fichier d'état dans un endroit plus pérenne que votre stockage local.
Pour démarrer cette configuration, ajoutez un bloc backend à votre projet Terraform, par exemple dans un fichier [backend.tf](http://backend.tf). Voici un exemple de bloc pour un backend Amazon S3 (sans configuration DynamoDB pour le moment).
terraform {
backend "s3" {
bucket = "terraform"
key = "state/snowflake.tfstate"
region = "eu-west-1"
}
}
Assez simple, mais vient ensuite la partie un peu plus délicate : intégrer cela à votre pipeline de déploiement. Heureusement, une fois authentifié auprès d'AWS, Terraform se chargera de mettre à jour l'état distant à notre place !
Pour cela, ajoutez 3 secrets GitHub supplémentaires pour votre compte AWS :
AWS_ACCESS_KEY_ID— Identifiant de la clé d'accès de votre compte AWSAWS_SECRET_ACCESS_KEY— Clé secrète associéeAWS_REGION— Région AWS, par exempleeu-west-1
Mettez ensuite à jour vos fichiers ci.yml/deployment.yml pour qu'ils contiennent l'étape suivante (ou une authentification équivalente) avant toute commande Terraform.
- name: Authenticate against production account
uses: "aws-actions/configure-aws-credentials@v2"
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
Au final, un pipeline type pour le workflow Terraform Snowflake avec GitHub Actions ressemblerait à ceci :
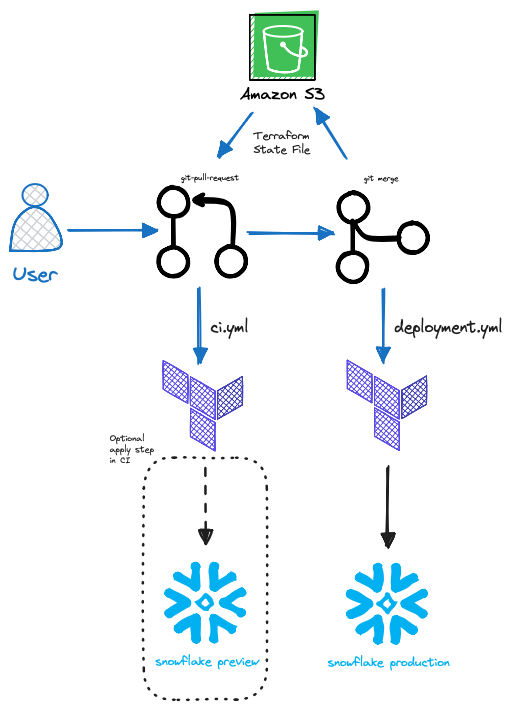
Exemples Terraform pour Snowflake
Si vous cherchez par où commencer, voici quelques exemples basiques autour des concepts fondamentaux de Snowflake. Pour démarrer, créons un warehouse (X-small, évidemment 😉).
resource "snowflake_warehouse" "reporting_warehouse" {
name = "reporting_wh"
comment = "Warehouse for reporting and BI tools"
warehouse_size = "x-small"
}
Parfait, nous avons de quoi interroger nos données Snowflake, mais nulle part où les stocker pour l'instant. Ajoutons donc une bonne vieille base de données.
resource "snowflake_database" "reporting" {
comment = "Reporting database"
data_retention_time_in_days = 30
name = "REPORTING"
}
Magnifique. Pour finir, créons un rôle Snowflake et attribuons-le à notre utilisateur dédié au reporting.
1
2resource "snowflake_role" "reporter" {
3 name = "REPORTER"
4 comment = "This role is limited to read only querying on the reporting database"
5}
6
7resource "snowflake_role_grants" "reporter" {
8 role_name = snowflake_role.reporter.name
9 roles = [\
\
10 ]
11 users = [\
\
12 snowflake_user.reporting_user.name\
\
13 ]
14}
Ce dernier exemple illustre comment Terraform crée des références entre objets : snowflake_role_grants dépend des ressources snowflake_role et snowflake_user. C'est de cette manière que Terraform détermine l'ordre d'exécution du SQL.
Pour aller plus loin
Pour un exemple fonctionnel de cet article, jetez un œil au dépôt GitHub ci-dessous : un fork et un Codespace, et vous êtes prêt à démarrer !
GtheSheep/terraform-snowflake-example
Pour une mise en pratique de Terraform avec Snowflake, consultez le guide officiel de Snowflake : Terraforming Snowflake.
Les défis liés à Snowflake et Terraform
Comme tout outil, Terraform a ses écueils — et les comportements ou cas d'usage de Snowflake peuvent parfois les accentuer. Passons-en quelques-uns en revue :
Couverture complète des ressources
Le provider Terraform Snowflake est maintenu par une équipe en or, mais il peut parfois mettre un peu de temps à rattraper les toutes dernières fonctionnalités de Snowflake. Et parfois, c'est un choix de conception délibéré de ne pas autoriser certaines opérations via Terraform (cas plus rare). Conséquence : il reste parfois nécessaire de gérer certaines choses directement dans Snowflake.
De plus, certaines ressources ne sont pas entièrement étoffées avec toutes les options offertes par Snowflake, ce qui peut imposer d'exécuter quelques commandes SQL bonus dans Snowflake une fois la ressource déployée.
Par exemple, l'équivalent de GRANT SELECT ON ALL TABLES IN SCHEMA <schema> TO ROLE <role> n'était pas directement disponible dans le provider. Pendant des années, il fallait soit trouver un moyen d'itérer sur les objets du schéma, soit exécuter du SQL supplémentaire — heureusement, le paramètre on_all existe désormais !
Propriété et durée de vie
Au moment de choisir quelles ressources Snowflake gérer via Terraform, pensez à leur durée de vie et à leur propriété.
La durée de vie, c'est notamment le fait de créer puis détruire des ressources rapidement pour du test, des POC, etc. — la question étant de savoir si cela vaut l'effort. Mais cela va plus loin : pensez aux tables transitoires, ou à celles qui sont fréquemment supprimées et recréées indépendamment des déploiements Terraform (dbt, c'est à toi que je pense 👀). Ce type d'activité peut désynchroniser Snowflake et l'état Terraform, et vos déploiements finissent dans le pétrin 🥒.
Côté propriété, déterminez quel process détient réellement ces objets. Terraform pourrait-il servir à délimiter l'environnement dans lequel ces process opèrent ? (Terraformer une base de données dans laquelle dbt peut gérer les schémas 🤷♂️).
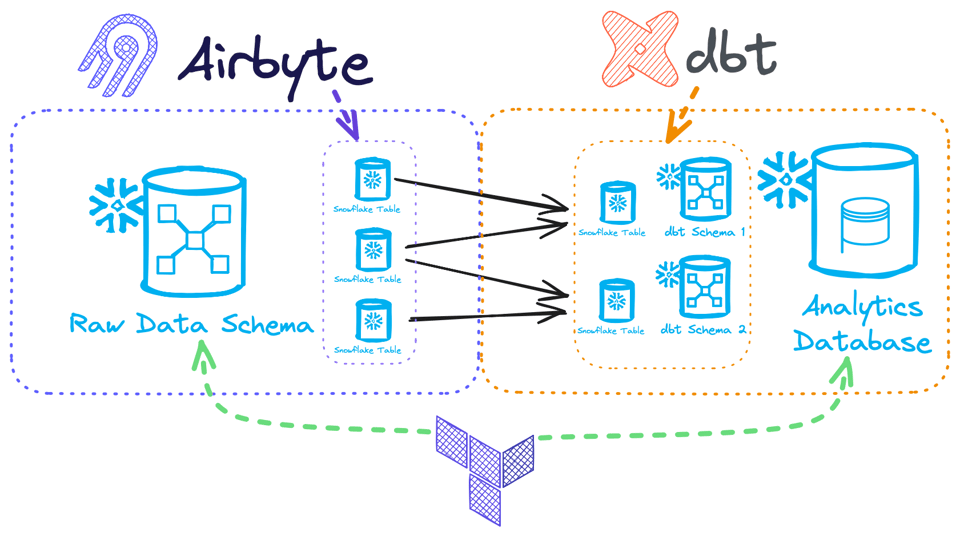
Par exemple, supposons que nous ayons un outil de chargement de données brutes, Airbyte, et un outil de transformation, dbt :
- Airbyte prend généralement un schéma cible dans lequel charger les données ; ensuite, on lui laisse la propriété et la gestion des tables au sein de ce schéma Snowflake, en ajoutant colonnes et tables au besoin (en supposant qu'on sélectionne par défaut toutes les ressources disponibles depuis la source). Dans ce cas, on ne souhaitera pas gérer les tables avec Terraform, car elles seraient vite obsolètes à cause de l'activité d'Airbyte. En revanche, on peut gérer le schéma avec Terraform — sa création comme son contrôle d'accès — puisque celui-ci est immuable du point de vue d'Airbyte.
- dbt pourrait ensuite transformer les données vers plusieurs schémas Snowflake, en les créant et en y construisant des tables. Ici, gérer les schémas avec Terraform n'aurait même pas de sens : dbt en a la pleine propriété et peut même gérer le contrôle d'accès pour vous. La base de données, en revanche, est le périmètre dans lequel dbt est autorisé à opérer : on peut donc la provisionner via Terraform.
Ces deux processus s'exécutent entièrement indépendamment de votre pipeline Terraform : soit l'état ne connaît pas les changements faits par ces autres processus et génère beaucoup de bruit dans votre terraform plan, soit, pire encore, il écrase les changements opérés par Airbyte/dbt !
Gérer plusieurs dépôts
Lorsque des ressources sont sollicitées et/ou manipulées depuis plusieurs endroits, les choses peuvent vite se compliquer.
Comme indiqué plus haut, il est essentiel de bien fixer le lieu de la propriété des ressources Snowflake : des définitions contradictoires peuvent amener différents déploiements à écraser les configurations les uns des autres, par exemple si deux dépôts accordent USAGE sur une même base à des rôles différents (situation aujourd'hui en partie atténuée par le paramètre enable_multiple_grants).
Les dépendances peuvent être gérées via les modules Terraform, la lecture depuis des data sources, etc. Mais pour éviter que cette flexibilité ne déborde, élaborez un plan clair de structuration de la gestion des ressources : par exemple, un dépôt central qui gère les rôles, utilisateurs, grants, warehouses Snowflake — tous les éléments vraiment fondamentaux d'un compte — puis laisser les autres équipes provisionner leurs propres bases, tâches et procédures selon leurs besoins.
Gary James·Senior Analytics Engineer chez Beauty Pie
Gary est Senior Analytics Engineer chez Beauty Pie, une entreprise de maquillage et de soins. Avec plus de dix ans d'expérience sous tous les intitulés data imaginables, c'est un grand passionné de tout ce qui touche à la data et à l'engineering. Gary est un contributeur très actif à de nombreux projets open source de la data stack. Il est l'auteur du provider Terraform pour dbt Cloud et contribue à d'autres projets de l'écosystème comme dbt, Elementary Data, Lightdash et Meltano.