¿Qué es Terraform?
Terraform es una herramienta de Infraestructura como Código ( IaC: ¡sin pelearse con interfaces gráficas!) que sirve para gestionar la configuración de tus servicios mediante providers (normalmente específicos de cada servicio: Snowflake, AWS, dbt Cloud, etc.).
Los providers son a Terraform lo que los paquetes son a Python: piezas reutilizables y preempaquetadas con interfaces creadas para un propósito específico. Siguiendo con la analogía, el Terraform registry vendría siendo algo así como Pypi.
¿Por qué usar Terraform para gestionar la infraestructura de Snowflake?
Hay 3 razones de peso para plantearte usar Terraform en la gestión de tu infraestructura de Snowflake.
1. Para versionar tu configuración
Con Terraform, la configuración de tu infraestructura se guarda en un repositorio con control de versiones, como Github. Esto significa que obtienes los beneficios habituales de tener código en Github: una forma sencilla de hacer rollback, previsualizar cambios, un historial completo del código y esas valiosísimas revisiones de tus compañeros antes de liberar cualquier cambio.
Más allá de Github, Terraform mantiene su propio estado de los recursos de tu infraestructura, lo que te protege ante cambios inesperados al mostrar un diff en cada despliegue.
2. Escala
Terraform te permite reutilizar la configuración, lo que facilita escalar tus despliegues de Snowflake. A grandes rasgos, poder gestionar varias cuentas de Snowflake desde un único lugar es una de sus grandes ventajas. Además, la capacidad de crear, actualizar o eliminar recursos de forma escalable con configuraciones plantilladas mediante loops o módulos puede reducir muchísimo el tiempo dedicado a esas tareas amplias.
También ayuda a escalar la colaboración interna y las buenas prácticas. Aporta un lenguaje común entre repositorios, equipos e incluso disciplinas, ¡algo súper útil para cualquier equipo de datos hoy en día! Contar con un conjunto de herramientas común en toda la organización también reduce el tiempo de mantenimiento de pipelines de despliegue a medida, si todos se rigen por el mismo manual.
3. Una forma más sencilla de gestionar dependencias
Terraform construye un grafo de dependencias entre tus recursos a partir de los objetos que defines, lo que significa que te puede avisar cuando intentes eliminar recursos de los que dependen otros más adelante, como descartar una tabla que se usa en un stream.
¿Terraform (o cualquier IaC) es lo adecuado para ti?
Incluso en las implementaciones más improvisadas, las herramientas de IaC siempre consiguen una cosa: ¡que dejes tu setup por escrito! ¿A quién no le gusta una buena dosis de documentación? Y si encima está bajo control de versiones, lo más probable es que haya al menos alguna mención de por qué se añadió esa configuración o cuándo se añadió, todo contexto útil.
La otra cara de la moneda es que IaC, por su propia naturaleza, está un paso alejado de la plataforma con la que quieres interactuar, y cuanto más te apoyes en técnicas como los módulos, más alejada quedará tu configuración, lo que puede generar opacidad para quienes intenten usarla o, peor aún, fragilidad en tu stack. Por eso conviene aplicar las abstracciones con criterio y de forma estratégica.
¿La configuración de este servicio es realmente importante? ¿Vale la pena el esfuerzo? 🍊
Cada parte de tu infraestructura conlleva riesgos asociados, como una mala configuración o tiempos de inactividad. Llevar tus configuraciones (existentes o nuevas) a IaC no es gratis en términos de esfuerzo, así que piensa qué tan crítico es este componente para tu negocio antes de lanzarte.
¿Puedes dedicarle el tiempo necesario para configurarlo y mantenerlo? ¿Snowflake es lo bastante central para el negocio como para justificarlo? ¿El tiempo de recuperación de Snowflake es un factor? ¿Tienes que contemplar mover recursos existentes de Snowflake a Terraform?
¿Quienes administran este servicio prefieren hacerlo desde código?
A veces tus administradores no van a querer (¡o no van a poder!) pasar por código y control de versiones cada vez que haya que hacer un cambio, y si las consecuencias de equivocarse son tolerables, ¡no entorpezcas la flexibilidad!
Dicho esto, Terraform (u otros IaC) también puede aportar un lenguaje común entre los equipos de desarrollo, sumando consistencia y reutilización (ver Terraform Modules) en tu organización, facilitando un enfoque más democrático de la administración y aliviando lo que muchas veces es una carga para los perfiles senior.
¿El provider cubre tus necesidades? ¿Existe siquiera un provider?
No todo tiene un provider disponible en Terraform, y aun cuando lo haya, a veces hay cierto retraso entre el lanzamiento de una nueva funcionalidad y su llegada al provider, así que conviene verificar qué hay disponible antes de empezar con uno o de meterte en el camino de construir el tuyo.
Cómo usar Terraform con Snowflake
Ya sea que estés desarrollando en local, en Codespaces o arrancando un setup de producción, los pasos iniciales son bastante similares, así que vamos a repasar algunos conceptos base para usar cualquier provider de Terraform.
El Snowflake Terraform Provider
Si revisas el Terraform Registry, encontrarás varios providers y módulos relacionados con Snowflake, pero el que nos interesa es el que ahora mantiene la propia Snowflake: el oficial Snowflake Terraform Registry.
Preparando el entorno
Para arrancar un proyecto de Terraform con Snowflake:
- Instala Terraform; consulta la documentación, por ejemplo vía Homebrew para Mac OS X:
brew tap hashicorp/tap
brew install hashicorp/tap/terraform
terraform -help
- Crea un nuevo directorio/repositorio
mkdir snowflake-terraform-example
cd snowflake-terraform-example
- Crea un archivo
[versions.tf](http://versions.tf), que contendrá las versiones de los Terraform Providers que vas a usar. Para este ejemplo, debería verse algo así:
terraform {
required_version = ">= 1.0.0"
required_providers {
snowflake = {
source = "snowflake-labs/snowflake"
version = "0.84.1"
}
}
}
- Para configurar tu provider, crea un archivo
[providers.tf](http://providers.tf), donde definirás los providers que vayas a usar. Puedes pasar las credenciales aquí mientras pruebas, pero lo mejor es buscar una solución basada en variables de entorno cuando lo guardes en un repositorio (¡así no expones tus secretos por ahí!). Un ejemplo podría verse así:
provider "snowflake" {
role = "SYSADMIN"
}
Cómo desplegar Terraform para Snowflake con Github Actions
Configurando tus credenciales
Para interactuar con Snowflake vía Terraform en Github Actions hacen falta credenciales para iniciar sesión en Snowflake. Hay varias opciones: usuario/contraseña, claves privadas, OAuth, etc., pero en este ejemplo nos quedaremos con usuario/contraseña. Para otras opciones de autenticación, consulta la documentación del provider.
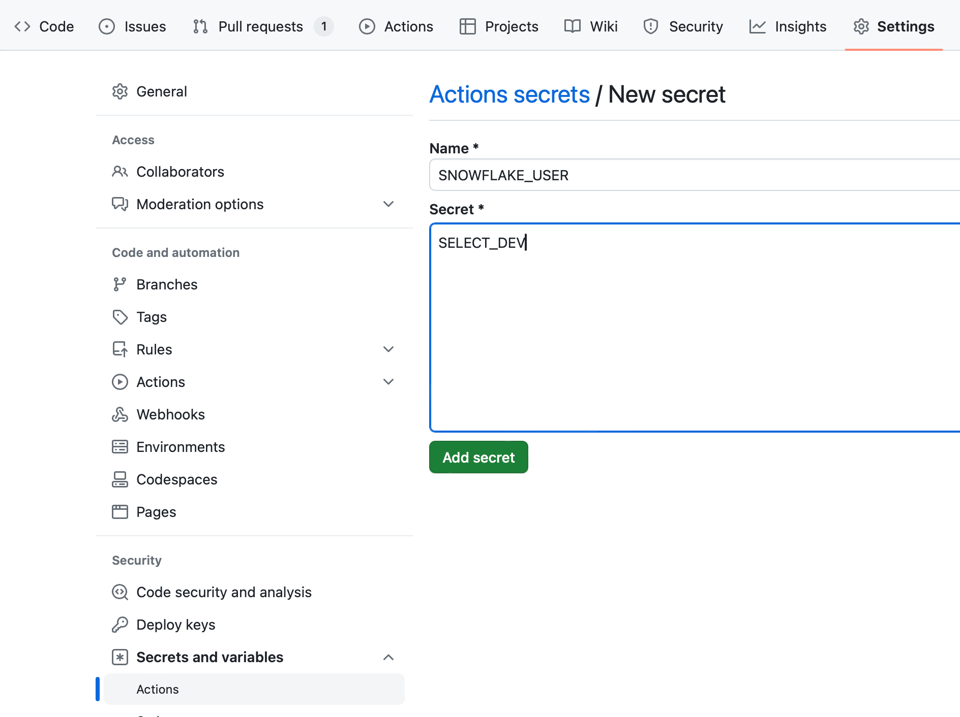
Para guardar tus credenciales a nivel de repositorio en Github Secrets: Tu Repositorio > Settings > Secrets and variables > Actions > New repository secret
Con los siguientes valores:
SNOWFLAKE_ACCOUNT: tu identificador de cuenta, con detalles de región/proveedor, por ejemploselect_dev-productionoselect123.eu-west-1.awspara cuentas legacy.SNOWFLAKE_USER: usuario de inicio de sesiónSNOWFLAKE_PASSWORD: contraseña de inicio de sesión
Validaciones para correr en CI
Cuando hagas cambios de infraestructura en un repositorio con Terraform, hay varios pasos útiles que conviene sumar a tu CI para facilitar la revisión de los cambios propuestos:
terraform fmt -check: revisa el formato de tu configuración de Terraform. Parte de la belleza de Terraform está en su legibilidad, así que es un paso clave. El-checkhace que falle si el formato es incorrecto; sin ese flag, te ayudará a corregirlo (mejor en desarrollo que en CI).terraform validate: hace una validación básica; no llama a servicios remotos, pero revisa cosas como nombres de atributos, etc.terraform plan: también útil en desarrollo. Compara tu configuración de Terraform más reciente con el estado remoto del servicio, es decir, calcula qué cambios están por aplicarse (sin aplicarlos). Este paso es súper útil en CI, ya que muestra exactamente qué va a cambiar y debería revisarse antes de aprobarlo.
Juntando todo, un ejemplo de pipeline de CI en Github Actions podría ser algo así:
name: Terraform Snowflake CI
on:
pull_request:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Expandir código
Copia y pega lo anterior en un archivo como .github/workflows/ci.yml. La próxima vez que abras un Pull Request, se ejecutarán las validaciones contra tu rama, lo que se verá así en Github Actions:
Ejemplo de pipeline de CI en un Pull Request en Github Actions
( Extra opcional): si tienes la posibilidad de mantener múltiples réplicas completas de tu entorno, también podrías añadir el paso terraform apply a tu CI. La ventaja sería detectar errores que solo afloran del lado de Snowflake (y no del Terraform Provider) al aplicar los cambios, además de permitir validación manual en Snowflake y acercar el flujo de desarrollo al de algunas prácticas habituales de ingeniería.
La desventaja es que probablemente requeriría una cuenta de Snowflake separada o, como mínimo, un conjunto de credenciales aparte para separar tu entorno de CI del de Deployment, algo que queda fuera del alcance de este artículo.
Pero, para completar la idea, añadir esto a ci.yml solo requeriría un bloque adicional al final, así:
- name: Terraform apply
id: terraform-apply
run: terraform apply -auto-approve
Desplegando tus cambios
Suponiendo que todo lo anterior va bien y que todos están conformes con los cambios, podemos desplegarlos mediante un pipeline de despliegue.
terraform apply -auto-approve: aplica los cambios a tu infraestructura. Al ejecutarse vía actions,-auto-approvepermite que Terraform siga adelante sin intervención del usuario, ya que de lo contrario esperaría una confirmación como cuando se corre en la línea de comandos.
¡Así que es un paso de despliegue muy simple! En Github Actions se vería algo así, en un archivo como .github/workflows/deployment.yml:
name: Terraform Snowflake Deployment
on:
push:
branches:
- main
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
jobs:
RunChecks:
name: Run Checks
Expandir código
Almacenando el estado de Terraform para Github Actions
Para llevar un registro de cómo se ve tu infraestructura, Terraform crea un archivo de estado con la lista de todos tus recursos y su configuración tal como están actualmente (¡o como deberían estar!).
Ahora bien, al hacer cambios vía Pull Requests y Github, la Github Action necesitará acceder al estado actual de los recursos, que será el resultado de la infraestructura del paso terraform apply anterior. Entonces, ¿cómo nos aseguramos de que tenga acceso a ese estado desde una acción previa?
Aquí entran los Terraform Backends (para quienes no usan Terraform Cloud), que te permiten configurar tu setup de Terraform para guardar su archivo de estado en un lugar más permanente, en vez de tu almacenamiento local.
Para arrancar con esta configuración, tendrás que añadir un bloque de backend a tu proyecto de Terraform, por ejemplo un archivo [backend.tf](http://backend.tf). Abajo tienes un ejemplo de ese bloque para un backend de Amazon S3 (sin configurar DynamoDB por ahora).
terraform {
backend "s3" {
bucket = "terraform"
key = "state/snowflake.tfstate"
region = "eu-west-1"
}
}
Bastante simple, pero luego viene la parte un poco más enredada: incorporarlo a tu pipeline de despliegue. Por suerte, una vez autenticado en AWS, ¡Terraform se encarga de actualizar el estado remoto por nosotros!
Para lograrlo, añade 3 secretos más en Github para tu cuenta de AWS:
AWS_ACCESS_KEY_ID: identificador de la clave de acceso de tu cuenta de AWSAWS_SECRET_ACCESS_KEY: secreto de la clave de accesoAWS_REGION: región de AWS, por ejemploeu-west-1
Y actualiza tu ci.yml/deployment.yml para que incluya el siguiente paso (o una autenticación similar) antes de ejecutar cualquier comando de Terraform.
- name: Authenticate against production account
uses: "aws-actions/configure-aws-credentials@v2"
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
En conjunto, un pipeline aproximado para el flujo de Terraform + Snowflake en Github Actions se vería más o menos así:
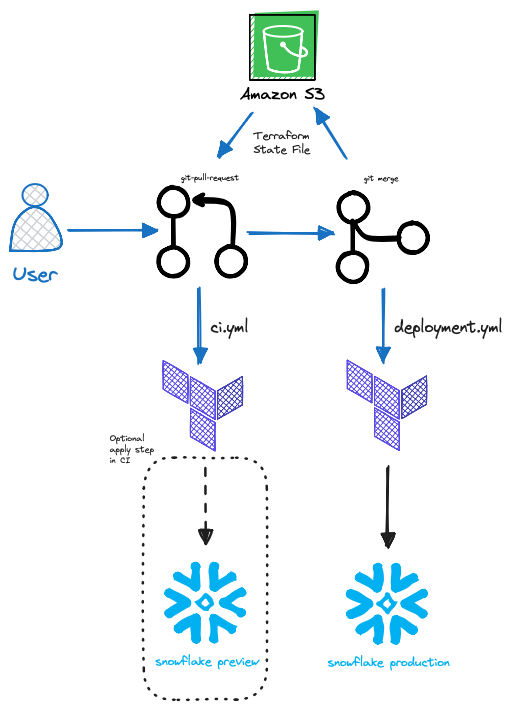
Ejemplos de Terraform para Snowflake
Si estás buscando por dónde empezar, algunos ejemplos básicos de los conceptos centrales de Snowflake se ven más o menos así. Para arrancar, vamos a crear un warehouse (X-small, obviamente 😉).
resource "snowflake_warehouse" "reporting_warehouse" {
name = "reporting_wh"
comment = "Warehouse for reporting and BI tools"
warehouse_size = "x-small"
}
Genial, ya tenemos una forma de consultar nuestros datos en Snowflake, pero hasta ahora no tenemos dónde guardarlos. Así que vamos a añadir una buena base de datos de toda la vida.
resource "snowflake_database" "reporting" {
comment = "Reporting database"
data_retention_time_in_days = 30
name = "REPORTING"
}
Excelente. Y por último, vamos a crear un rol en Snowflake y asignárselo a nuestro usuario de reporting.
1
2resource "snowflake_role" "reporter" {
3 name = "REPORTER"
4 comment = "This role is limited to read only querying on the reporting database"
5}
6
7resource "snowflake_role_grants" "reporter" {
8 role_name = snowflake_role.reporter.name
9 roles = [\
\
10 ]
11 users = [\
\
12 snowflake_user.reporting_user.name\
\
13 ]
14}
Este último ejemplo muestra cómo Terraform crea referencias entre objetos: snowflake_role_grants depende de los recursos snowflake_role y snowflake_user, y así es como Terraform determina el orden en el que ejecutar el SQL.
Más ejemplos
Para ver un ejemplo funcional de este artículo, échale un vistazo al repositorio de Github de abajo. ¡Hacerle fork y crear un Codespace es una forma rápida de empezar!
GtheSheep/terraform-snowflake-example
Para un setup práctico de Terraform con Snowflake, revisa la propia guía de Snowflake para empezar: Terraforming Snowflake.
Retos con Snowflake y Terraform
Como toda herramienta, Terraform no está libre de tropiezos, y a veces los comportamientos o casos de uso de Snowflake pueden incluso amplificarlos. Veamos algunos:
Cobertura completa de recursos
Aunque hay un equipazo manteniendo el Snowflake Terraform provider, a veces puede tardar un poco en ponerse al día con lo último que saca Snowflake o, en algunos casos, es una decisión de diseño no permitir explícitamente algo vía Terraform (situación más rara). Eso puede implicar que aún haya cosas que gestionar directamente en Snowflake.
Encima, algunos recursos no vienen completamente equipados con todas las opciones que ofrece Snowflake, lo que puede obligarte a ejecutar algunos comandos SQL "de propina" en Snowflake después de desplegar el recurso.
Por ejemplo, el equivalente de GRANT SELECT ON ALL TABLES IN SCHEMA <schema> TO ROLE <role> no estuvo disponible directamente en el provider durante años; tocaba buscar la manera de iterar sobre los objetos del schema o ejecutar SQL extra. ¡Por suerte ahora existe el parámetro on_all!
Propiedad y ciclo de vida
Al decidir qué recursos de Snowflake gestionar vía Terraform, ten en cuenta su ciclo de vida y su propiedad.
El ciclo de vida puede referirse a simplemente montar y desmontar cosas para pruebas, POCs, etc., y si eso vale el esfuerzo, pero va más allá. Piensa en tablas transitorias o en aquellas que se eliminan y recrean con frecuencia de forma independiente a cuándo Terraform pueda desplegar cosas (dbt, te estoy mirando a ti 👀). Este tipo de actividad puede dejar a Snowflake muy desincronizado con el estado de Terraform, y acabarás con tus despliegues hechos un lío 🥒.
En cuanto a la propiedad, decide qué proceso es realmente dueño de esos objetos. ¿Podrías usar Terraform para acotar el entorno en el que operan esos procesos? (Hacer Terraform de una base de datos en la que dbt gestione el schema 🤷♂️).
A modo de ejemplo, supongamos que tenemos una herramienta de carga de datos en bruto, Airbyte, y una herramienta de transformación, dbt:
- Airbyte generalmente toma un target schema en el que cargar los datos. A partir de ahí, le permitimos ser dueño y gestionar las tablas dentro de ese schema de Snowflake, añadiendo columnas y tablas según lo necesite (asumimos que por defecto seleccionamos todos los recursos disponibles desde el origen). En este caso no querríamos gestionar las tablas con Terraform, porque Airbyte las desactualizaría rápidamente, pero sí podríamos gestionar el schema con Terraform, tanto su creación como el control de acceso, ya que eso es inmutable desde el punto de vista de Airbyte.
- dbt podría luego transformar los datos hacia múltiples schemas de Snowflake, creándolos y construyendo tablas en cada uno. Aquí no tendría sentido siquiera gestionar los schemas con Terraform, porque dbt tiene plena propiedad sobre ellos e incluso podría encargarse del control de acceso por ti, pero la base de datos es el área en la que dbt opera, así que podríamos aprovisionarla vía Terraform.
Ambos procesos corren totalmente al margen de tu pipeline de Terraform, así que el estado o bien no se enteraría de los cambios hechos por estos otros procesos y generaría mucho ruido en tu terraform plan, o peor, ¡sobrescribiría los cambios hechos por Airbyte/dbt!
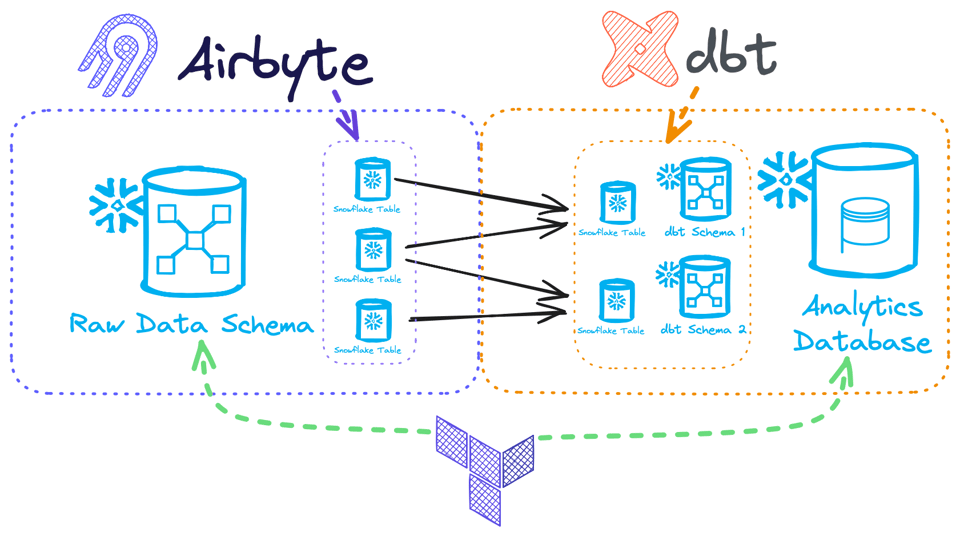
Gestionar varios repositorios
Cuando hay recursos que se necesitan o se tocan desde varios lugares, la cosa se puede poner peliaguda.
Como ya mencionamos, es clave dejar claro dónde reside la propiedad de los recursos de Snowflake, ya que definiciones en conflicto pueden hacer que distintos despliegues sobrescriban la configuración de otros, por ejemplo si 2 repos otorgan USAGE sobre una base de datos a roles distintos (algo bastante mitigado hoy en día con el parámetro enable_multiple_grants).
Las dependencias se pueden manejar con módulos de Terraform, leyendo cosas desde data sources, etc., pero para evitar que esa flexibilidad se desborde, define un plan sólido sobre cómo vas a estructurar la gestión de recursos: por ejemplo, un repo central que gestione roles/usuarios/grants/warehouses de Snowflake, etc., todos los elementos realmente core de una cuenta, y luego dejar que otros aprovisionen sus propias bases de datos/tasks/procedures según lo necesiten.
Gary James·Senior Analytics Engineer en Beauty Pie
Gary es Senior Analytics Engineer en Beauty Pie, una empresa de maquillaje y cuidado de la piel. Con más de una década de experiencia bajo cualquier cargo relacionado con 'data' que se te ocurra, es un gran fan de todo lo que tenga que ver con data/engineering. Gary es un contribuidor muy activo en distintos proyectos open source del data stack. Creó el provider de Terraform para dbt cloud y contribuye a otros proyectos del ecosistema como dbt, elementary data, lightdash y Meltano.