Play
Databricks y Snowflake son dos de las plataformas de data cloud más populares del mercado en este momento.
Cada una arrancó resolviendo casos de uso muy distintos: Snowflake como data warehouse SQL y Databricks como servicio gestionado de Apache Spark. ¡Incluso fueron partners en sus inicios!
Hoy ambas son plataformas de data cloud con múltiples facetas que cubren una gran variedad de casos de uso. Y, por lo tanto, compiten de forma directa.
El 28 de febrero de 2024 conversé con Jeff Chou, de Sync Computing. La empresa de Jeff trabaja exclusivamente con clientes de Databricks, mientras que en SELECT trabajamos exclusivamente con clientes de Snowflake.
Por eso nos pareció interesante juntarnos y tener una conversación genuina sobre cada plataforma. Ninguno conocía a fondo la plataforma del otro, pero teníamos muchas ganas de aprender uno del otro.
Fue una conversación honesta y sin guion entre dos personas que trabajan en el día a día con estas herramientas. Sin benchmarks inventados. Sin relleno de marketing.
Hablamos de sus orígenes, de los casos de uso más comunes que vemos en clientes reales, de sus fortalezas y debilidades, y de hacia dónde apuntan ambas.
A continuación armé un resumen de los puntos clave que discutimos.
Los orígenes
Al principio, Databricks y Snowflake arrancaron como partners, cada una enfocada en aspectos distintos de la gestión de datos. Mientras Snowflake se especializaba en data warehousing, Databricks se hizo un nicho con Spark gestionado y rápidamente se expandió hacia workloads de machine learning (ML). Curiosamente, en aquella época se referían clientes entre sí.
Si avanzamos hasta hoy, ambas plataformas han pasado por transformaciones notables. Si miras sus sitios web (captura del 27 de febrero de 2024), Snowflake ahora se presenta como la "data cloud", mientras que Databricks se posiciona como la "data intelligence platform":
A fin de cuentas, ambas son plataformas de data cloud integrales, todo-en-uno, que cubren una gran variedad de casos de uso.
Dicho esto, vale la pena explorar sus orígenes, porque ayudan a entender las fortalezas y debilidades relativas de cada plataforma hoy.
Snowflake se fundó en 2012 por expertos en data warehousing de Oracle y de otra compañía de data warehousing llamada VectorWise. Salió al mercado hace 10 años, en 2014, con su producto principal de data warehousing, al que solían referirse como el "elastic data warehouse" por su arquitectura única, que permite escalar de forma independiente compute y storage.
Poco después del lanzamiento de Snowflake, Databricks lanzó su primer producto, en un espacio totalmente distinto. Databricks fue fundada por los creadores de Apache Spark, todos académicos del área de investigación en computación de alto rendimiento de Berkeley. Su primer producto fue una oferta gestionada de Apache Spark, junto con una interfaz de notebook para ejecutar jobs de forma interactiva en esos clústeres de cómputo.
Snowflake empezó a expandirse con la funcionalidad de data sharing en 2017, seguida en 2019 de un marketplace donde los clientes podían comprarse datasets entre sí.
En una ventana de tiempo similar, Databricks empezó a profundizar en el espacio de ML con el lanzamiento de su oferta gestionada de MLflow en 2019, seguida de MLflow model serving en 2020.
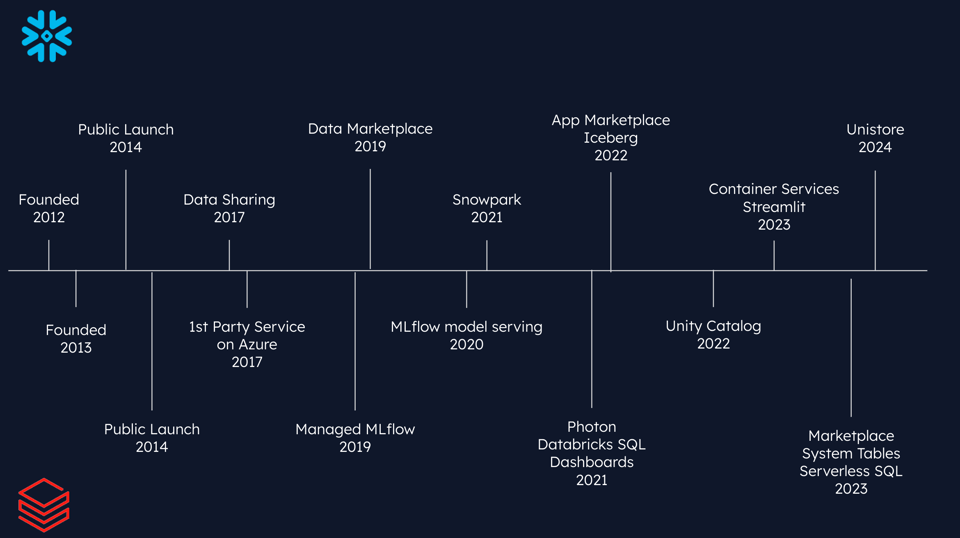
La evolución de cada compañía
Resulta interesante observar cómo cada compañía respondió a las demandas del mercado y lanzó funcionalidades que compiten entre sí.
Snowflake desarrolló Snowpark, inicialmente pensado para migrar workloads de Spark, pero que evolucionó hacia una plataforma para workloads de ML basados en Python. También invirtieron fuerte en sumar soporte para Apache Iceberg, de modo que sus clientes puedan gestionar y aprovechar sus data lakes directamente desde Snowflake.
Mientras tanto, Databricks lanzó funcionalidades como Photon y Databricks SQL, ampliando su presencia en el terreno del data warehousing.
Esto se nota especialmente hoy al mirar las interfaces para crear un virtual warehouse en Snowflake y un "SQL warehouse" en Databricks. Se ve que Databricks prácticamente copió el diseño y la configuración de los virtual warehouses de Snowflake:

Aunque no aparecen en la línea de tiempo de arriba, ambas compañías hicieron una buena cantidad de anuncios de funcionalidades relacionadas con AI/LLM a finales de 2023 y principios de 2024. Todavía es temprano en este terreno, pero las dos hicieron grandes adquisiciones y están invirtiendo muy fuerte.
Ventajas de cada plataforma y diferenciadores clave
Es importante entender cómo arrancó cada compañía, porque ayuda a explicar las fortalezas y debilidades relativas de cada plataforma.
Por su origen en data warehousing, Snowflake tiene un producto de data warehouse SQL mucho más sólido y completo. Para la mayoría de las empresas, esta será la funcionalidad más importante y más usada, ya que la mayor parte del valor que se genera a partir de las estrategias de datos viene de un data warehouse bien administrado que cubra los casos de uso centrales de business intelligence.
Muy pocas de las compañías con las que hablo usan Databricks como su "data warehouse". En cambio, recurren a Databricks por sus potentes notebooks de Python y su sólido soporte para workloads de data science. Para empresas con data engineers muy técnicos que prefieren trabajar con Apache Spark y Python, Databricks suele ser la opción preferida para las transformaciones de datos. Una ventaja de Databricks en casos de uso de ETL es la flexibilidad y personalización de Spark. Para workloads analíticos que procesan datasets extremadamente grandes, a veces conviene trabajar con Spark, ya que se pueden ajustar más parámetros y lograr que el job corra más barato. En mi experiencia, esto solo suele tener sentido como consideración para workloads que cuestan decenas de miles de dólares al año, ya que los costos humanos asociados a mantener y programar estos data pipelines suelen superar cualquier ahorro generado del lado del cómputo.
En cuanto a roadmaps futuros y evolución del producto, uno de los diferenciadores clave de Snowflake es su enfoque de plataforma. A finales de 2023, Snowflake lanzó Snowpark Container Services, que permite a los clientes ejecutar aplicaciones containerizadas en Snowflake. Combinado con su marketplace de aplicaciones nativas, queda claro que Snowflake está construyendo para un futuro en el que clientes y partners puedan ejecutar cualquier tipo de aplicación de datos directamente dentro de Snowflake.
En el caso de Databricks, parece que están adoptando un enfoque en el que los clientes obtienen una solución gestionada lista para usar para cada caso de uso. Dos ejemplos claros son su funcionalidad de dashboard y su catálogo de datos. Con Snowflake, la mayoría de los clientes terminan comprando una herramienta externa de BI / dashboarding que se conecta encima de Snowflake. De la misma forma, también compran un producto aparte de catálogo de datos para gestionar y dar seguimiento a todos sus datasets. Databricks claramente intenta eliminar esa necesidad de comprar herramientas separadas. En 2020 compraron una compañía llamada Redash y la convirtieron en una oferta de dashboard sólida y lista para usar. De la misma forma, están invirtiendo fuerte en su Unity Catalog, que apunta a reemplazar a los proveedores externos de catálogos de datos.
Casos de uso y comparación de funcionalidades clave
Durante el webinar repasamos los casos de uso centrales de una plataforma de data cloud y luego listamos las funcionalidades de Databricks y Snowflake para cada uno. Los principales casos de uso que discutimos fueron:
- Ingesta de datos
- Transformaciones de datos
- Análisis y reporting
- ML/AI
- Data Applications
- Marketplace
- Gobernanza y gestión de datos
Veamos cada uno en más detalle.
Ingesta de datos
Para interactuar con los datos, primero hay que cargarlos o "exponerlos" al sistema subyacente. En Snowflake, esto suele implicar ejecutar un comando COPY INTO para cargar los datos en una tabla que luego puedes consultar con Snowflake. Snowflake también ofrece funcionalidades como Snowpipe para cargar datos de forma automática.
La mayoría de los clientes de Snowflake también suelen usar una solución externa como Fivetran, Stitch o Airbyte para cargar datos desde diversas fuentes (bases de datos de aplicaciones, APIs externas, etc.) hacia Snowflake.
Con Databricks, en cambio, la mayoría de los clientes interactúa con los datos directamente en el cloud storage. Aunque los Volumes gestionados son un concepto similar a las tablas de Snowflake, donde Databricks gestiona la tabla por ti.
Con las inversiones de Snowflake en el soporte para Apache Iceberg, cada vez más clientes dejarán sus datos directamente en el cloud storage e interactuarán con ellos ahí, de forma similar al modelo de Databricks.
| Snowflake | Databricks |
|---|---|
| COPY INTO tradicional | Autoloader |
| Snowpipe | Integraciones nativas (ej. S3) |
| Conectores propios | Volumes |
| Terceros (Fivetran/Stitch/Airbyte) | DBFS |
| No se requiere ingesta si usas Iceberg |
Transformaciones de datos
Una vez que tus datos están expuestos a la plataforma cloud, normalmente vas a querer transformarlos o enriquecerlos de alguna manera. Ambas plataformas ofrecen una variedad de soluciones para hacerlo.
Como Snowflake es un data warehouse basado en SQL, la mayoría de los clientes hace sus transformaciones de datos en SQL puro usando una combinación de tasks, stored procedures o herramientas externas de transformación y orquestación como dbt. Todos los workloads SQL corren en los virtual warehouses de Snowflake.
Del lado de Databricks, la mayoría de los clientes usa Jobs, que te permite enviar un job de Spark a un clúster que corre en instancias de cómputo dentro de tu nube. Con las inversiones recientes de Databricks en su producto serverless de SQL warehouse, cada vez es más común ver transformaciones de datos en SQL puro con herramientas como dbt.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Notebook plots |
| Streamlit | SQL Visualizations |
| Conectores propios | Volumes |
| Terceros (Tableau, Looker, PowerBI, etc.) | Dashboards |
| Terceros (Tableau, Looker, PowerBI, etc.) |
Análisis y reporting
Tanto Databricks como Snowflake ofrecen a sus clientes varias funcionalidades para análisis y reporting. Snowflake te permite crear dashboards ligeros directamente en Snowsight, o bien armar aplicaciones de datos personalizadas con Streamlit.
Databricks tiene un producto de dashboarding muy bien logrado, que algunas empresas usan en reemplazo de una herramienta de BI de terceros.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Notebook plots |
| Streamlit | SQL Visualizations |
| Conectores propios | Volumes |
| Terceros (Tableau, Looker, PowerBI, etc.) | Dashboards |
| Terceros (Tableau, Looker, PowerBI, etc.) |
ML/AI
Como mencionamos antes, ambas compañías están invirtiendo fuerte en capacidades de ML y AI. Por su foco temprano en este tema, Databricks tiene algunas funcionalidades de ML más desarrolladas, como MLflow gestionado y Model Serving.
Con el lanzamiento de Snowpark Container Services, espero que muchos clientes de Snowflake puedan empezar pronto a alojar modelos de ML directamente en Snowflake.
| Snowflake | Databricks |
|---|---|
| Snowpark | MLflow |
| Snowpark Container Services | Model Serving |
| Snowflake Cortex | Soporte sólido para Python |
Data Applications
Un ángulo interesante para comparar Snowflake y Databricks tiene que ver con la creación de "data applications". Reconozco que el término es amplio y queda abierto a interpretación, así que voy a definir una "data application" como un producto o funcionalidad que se usa para servir datos o insights en vivo a clientes externos a la empresa. Es decir, no es una aplicación de uso interno dentro de la compañía.
Gracias a su data warehouse SQL de alto rendimiento, muchas empresas (como SELECT) construyen sus aplicaciones directamente sobre Snowflake y sirven las consultas de la aplicación directamente desde los virtual warehouses de Snowflake. Puedes ver más ejemplos en el programa Powered By de Snowflake. Con nuevas funcionalidades como Container Services, será posible alojar aplicaciones web completas directamente en Snowflake.
En el caso de Databricks, su principal caso de uso para "data applications externas" vendría de las funcionalidades de model serving que ofrecen, aunque pronto debería ser posible algo similar para servir consultas SQL gracias a las inversiones que están haciendo en sus productos de data warehousing.
| Snowflake | Databricks |
|---|---|
| Servir apps desde Snowflake | Model serving |
| Unistore (HTAP) - hybrid tables | Disparar Jobs al vuelo |
| Data Sharing | Serverless SQL |
| Container Services |
Marketplace
Como cliente, muchas veces vas a querer comprar aplicaciones o datasets adicionales para usar en tu plataforma de data cloud. Snowflake es el claro ganador acá, con un marketplace muy maduro lleno tanto de datasets como de aplicaciones nativas que puedes ejecutar directamente en tu cuenta de Snowflake.
| Snowflake | Databricks |
|---|---|
| Marketplace muy maduro | Marketplace muy maduro |
| Native Apps | Technology partners |
| Cost Management Suite | Mucho menos maduro, menor prioridad |
| Gran foco en partners |
Gobernanza y gestión de datos
Del lado de la gobernanza y la gestión, ambas plataformas ofrecen funcionalidades listas para usar.
Snowflake pone a disposición de todos los clientes cientos de datasets de metadata de forma gratuita en la base de datos account usage de Snowflake. Cuentan con una suite muy avanzada de cost management, que incluye funcionalidades potentes como budgets y resource monitors. Hace poco anunciaron Snowflake Horizon, un nuevo conjunto de capacidades para ayudarte a gobernar tus activos de datos y usuarios.
Databricks tiene una oferta de catálogo de datos muy sólida con su producto Unity Catalog, que ayuda a los clientes a gestionar y entender todos los datos de su entorno. Databricks va bastante más atrás en lo que respecta a cost management, y recién hace poco hizo accesible esta información en system tables (su equivalente a las vistas de account usage de Snowflake).
| Snowflake | Databricks |
|---|---|
| Cientos de datasets de metadata (account usage / information schema) | Unity Catalog |
| Snowflake Horizon | System tables |
| Cost Management Suite | Métricas de cómputo |
| Métricas de cómputo |
Precios y costos
Tanto Databricks como Snowflake ofrecen Precios basados en uso, en los que pagas por lo que consumes. Para conocer más sobre el modelo de precios de Snowflake, puedes leer nuestro post aquí. La información de precios de Databricks está en su sitio web. Algo muy importante a tener en cuenta con los precios de Databricks es que hay dos tipos de cargos:
- Los cargos de overhead/plataforma de Databricks
- Los costos subyacentes de la nube de AWS/Azure/GCP por los servidores que Databricks levanta en esas cuentas
Como en cualquier plataforma cloud basada en uso, los costos pueden dispararse rápidamente si no se gestionan ni se monitorean de forma adecuada.
¿Databricks es más barato que Snowflake?
Una pregunta común que mucha gente hace es si Databricks es más barato que Snowflake, impulsada en parte por un fuerte esfuerzo de marketing de Databricks, como se ve abajo en su sitio web:
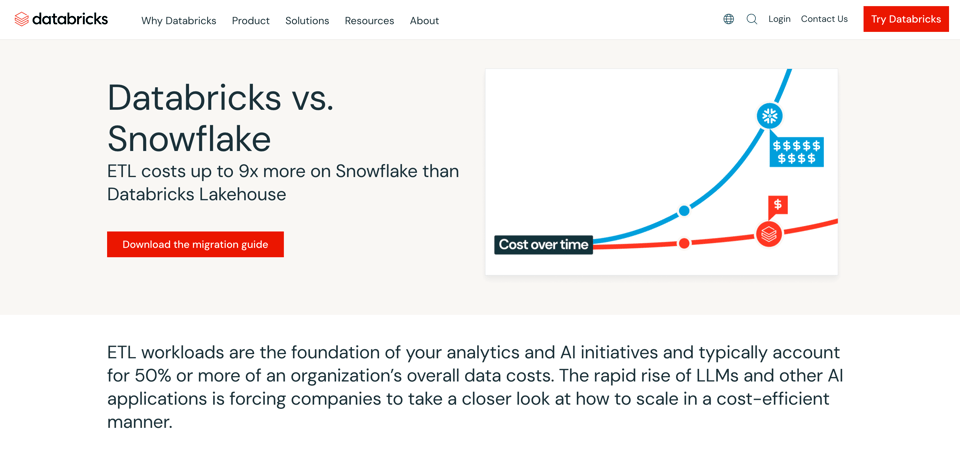
Al evaluar el costo de cualquier proceso o aplicación de datos hay dos factores importantes a considerar:
- Los costos de plataforma. El dinero que le pagas a Databricks/Snowflake/tu proveedor de nube.
- Los costos humanos. El dinero que le pagas a tus empleados para construir y mantener las aplicaciones y procesos que crean.
Databricks sostiene que los workloads de ETL pueden correr mucho más barato que en Snowflake. Esa afirmación parte del hecho de que los jobs de Spark se pueden afinar muchísimo. Hay un montón de parámetros distintos a los que los engineers pueden dedicarles días (o semanas) ajustando y experimentando.
Lo que muchos, incluido el marketing de Databricks, omiten al hacer estas comparaciones son los costos humanos asociados a todo ese trabajo. En ciertos casos puede tener sentido pagarle a los engineers para que experimenten optimizando y afinando un job, pero en la mayoría de los workloads de ETL los costos humanos de overhead terminan haciendo que el costo total sea mayor.
A la hora de tomar decisiones o hacer comparaciones relacionadas con el costo de cada plataforma, asegúrate de considerar el costo total de propiedad que viene de (a) el proveedor de la plataforma y (b) las personas que hacen el trabajo.
Cuota de mercado
Como Databricks es una compañía privada, no revela su número exacto de clientes ni su penetración en cada mercado.
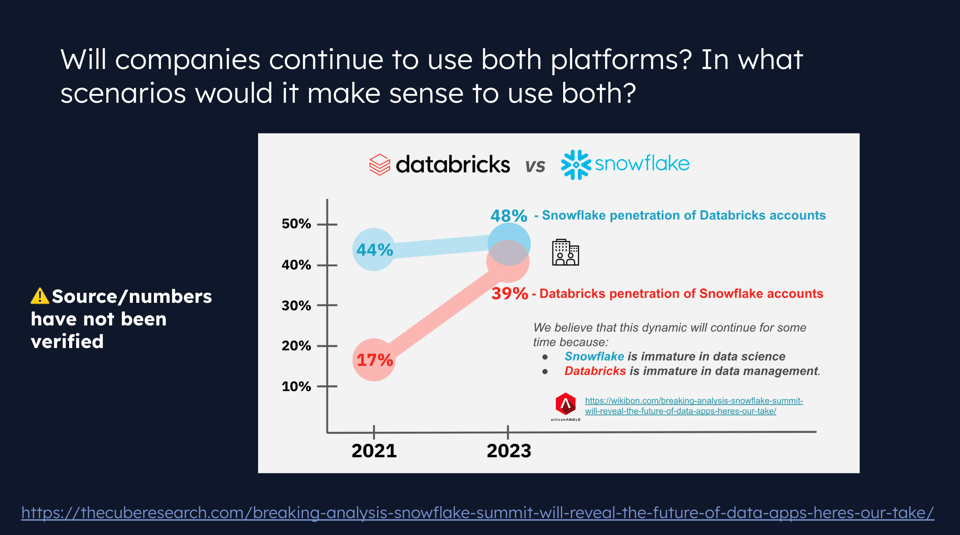
Algo que sí discutimos en el webinar fue cuántos clientes usan ambas plataformas. Las estadísticas de la lámina de abajo no están verificadas, pero sí muestran un solapamiento creciente entre las dos plataformas.
Jeff y yo especulamos que este solapamiento se debe a los enfoques históricamente distintos de cada plataforma, que con el tiempo terminaron convergiendo.
Ian Whitestone·Co-founder y CEO de SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science y engineering en Shopify y Capital One. En Shopify, Ian lideró los esfuerzos para optimizar el data warehouse y aumentar la observabilidad de costos.