Play
Databricks e Snowflake são duas das plataformas de data cloud mais populares do mercado hoje.
Elas começaram resolvendo casos de uso bem distintos: a Snowflake como data warehouse SQL e a Databricks como serviço gerenciado de Apache Spark. No começo, eram até parceiras!
Hoje, ambas são plataformas de data cloud multifacetadas, que atendem a uma variedade de casos de uso. E, por isso mesmo, viraram concorrentes diretas.
No dia 28 de fevereiro de 2024, tive uma conversa com Jeff Chou, da Sync Computing. A empresa do Jeff trabalha exclusivamente com clientes Databricks, enquanto nós, da SELECT, atendemos só clientes Snowflake.
Justamente por isso, achamos que seria legal sentar e ter uma conversa franca sobre cada plataforma. Nenhum de nós conhecia a fundo a plataforma do outro, mas estávamos animados para aprender um com o outro.
Foi um bate-papo honesto e sem roteiro entre dois profissionais da área. Sem benchmarks furados. Sem papo de marketing.
Falamos sobre as histórias de origem, os casos de uso mais comuns que vemos no dia a dia dos clientes, os pontos fortes e fracos de cada plataforma e para onde elas estão indo.
Abaixo, montei um resumo dos principais pontos que discutimos.
Histórias de origem
No início, Databricks e Snowflake eram parceiras, cada uma focada em aspectos diferentes da gestão de dados. Enquanto a Snowflake se especializou em data warehousing, a Databricks ocupou seu espaço no Spark gerenciado e logo expandiu para workloads de machine learning (ML). Curiosamente, elas costumavam indicar clientes uma para a outra.
Avançando para os dias de hoje, as duas plataformas passaram por transformações marcantes. Se você olhar os sites delas (capturados em 27/02/2024), a Snowflake hoje se posiciona como a "data cloud", enquanto a Databricks se apresenta como a "data intelligence platform":
No fim das contas, as duas são plataformas de data cloud completas, all-in-one, que atendem a uma variedade de casos de uso de dados.
Dito isso, ainda vale a pena explorar a história de origem de cada uma, porque isso ajuda a entender os pontos fortes e fracos de cada plataforma hoje.
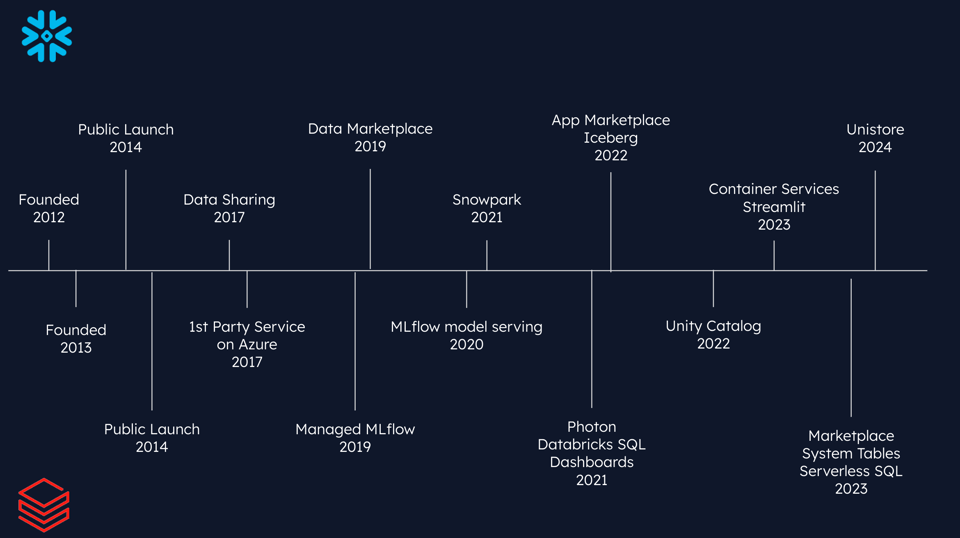
A Snowflake foi fundada em 2012 por especialistas em data warehousing vindos da Oracle e de outra empresa de data warehousing chamada VectorWise. A Snowflake chegou ao mercado há 10 anos, em 2014, com seu principal produto de data warehousing, frequentemente chamado de "elastic data warehouse" por causa de sua arquitetura única, que permitia escalar compute e storage de forma independente.
Pouco depois do lançamento da Snowflake, a Databricks lançou seu primeiro produto, em uma área completamente diferente. A Databricks foi fundada pelos criadores do Apache Spark, todos pesquisadores acadêmicos da área de computação de alto desempenho em Berkeley. O primeiro produto deles foi uma versão gerenciada do Apache Spark, junto com uma interface de notebooks para rodar jobs de forma interativa nesses clusters de computação.
A Snowflake começou a se expandir lançando a funcionalidade de compartilhamento de dados em 2017, seguida por um marketplace, em 2019, onde os clientes podiam comprar datasets uns dos outros.
Em um período parecido, a Databricks foi se aprofundando na área de ML, lançando sua oferta gerenciada de MLFlow em 2019, seguida pelo MLFlow model serving em 2020.
Evolução das empresas
Uma coisa interessante de observar é como cada empresa respondeu às demandas do mercado e lançou funcionalidades que competem entre si.
A Snowflake desenvolveu o Snowpark, voltado inicialmente para migrar workloads de Spark, mas que evoluiu para uma plataforma para workloads de ML em Python. Eles também investiram pesado em adicionar suporte ao Apache Iceberg, para que seus clientes possam gerenciar e usar seus data lakes direto da Snowflake.
Enquanto isso, a Databricks lançou recursos como Photon e Databricks SQL, ampliando sua atuação na área de data warehousing.
Isso fica especialmente evidente hoje quando você olha as interfaces para criar um virtual warehouse na Snowflake e um "SQL warehouse" na Databricks. Dá para ver que a Databricks praticamente copiou o design e as configurações dos virtual warehouses da Snowflake:

Embora não apareça no slide da timeline acima, as duas empresas anunciaram uma série de recursos ligados a AI/LLM no fim de 2023 e começo de 2024. Ainda estamos no começo nessa área, mas as duas fizeram grandes aquisições no espaço e estão investindo muito pesado.
Vantagens de cada plataforma e principais diferenciais
É importante entender como cada empresa começou, porque isso ajuda a explicar os pontos fortes e fracos de cada plataforma.
Por ter começado em data warehousing, a Snowflake tem um produto de data warehousing SQL muito mais robusto e completo. Para a maioria das empresas, esse vai ser o recurso mais importante e mais usado, já que a maior parte do valor gerado por estratégias de dados vem de um data warehouse bem gerenciado, capaz de atender aos principais casos de uso de business intelligence.
Pouquíssimas empresas com quem converso usam a Databricks como seu "data warehouse". Em vez disso, recorrem à Databricks pelos notebooks Python poderosos e pelo forte suporte a workloads de ciência de dados. Para empresas com data engineers muito técnicos, que preferem trabalhar com Apache Spark e Python, a Databricks costuma ser a escolha preferida para transformações de dados. Uma vantagem da Databricks para casos de uso de ETL é a flexibilidade e a customização do Spark. Para workloads analíticos que processam datasets enormes, trabalhar com Spark às vezes pode ser melhor, já que dá para ajustar mais parâmetros e fazer o job rodar mais barato. Na minha experiência, isso normalmente só faz sentido como consideração para workloads que custam dezenas de milhares de dólares por ano, já que o custo humano associado a manter e programar esses pipelines de dados muitas vezes supera qualquer economia gerada do lado do compute.
Em termos de roadmap futuro e evolução de produto, um dos principais diferenciais da Snowflake é o foco em plataforma. No fim de 2023, a Snowflake lançou o Snowpark Container Services, que permite aos clientes rodar aplicações containerizadas dentro da Snowflake. Quando combinado com o marketplace de aplicações nativas, fica claro que a Snowflake está construindo para um futuro em que clientes e parceiros possam rodar qualquer tipo de aplicação de dados diretamente na Snowflake.
Já a Databricks parece estar adotando uma abordagem em que o cliente recebe uma solução gerenciada pronta para cada caso de uso. Dois exemplos claros disso são a funcionalidade de dashboard e o data catalog. Na Snowflake, a maioria dos clientes vai contratar uma ferramenta externa de BI / dashboarding que roda em cima da Snowflake. Da mesma forma, também vão comprar um produto separado de data catalog para gerenciar e acompanhar todos os seus datasets. A Databricks claramente está tentando eliminar a necessidade de o cliente comprar ferramentas separadas. Compraram uma empresa chamada Redash em 2020 e transformaram isso em uma oferta forte de dashboard, pronta para usar. Da mesma forma, estão investindo pesado no Unity Catalog, que pretende substituir fornecedores terceirizados de data catalog.
Comparação de casos de uso e principais recursos
Durante o webinar, passamos pelos principais casos de uso de uma plataforma de data cloud e listamos os recursos de Databricks e Snowflake para cada um. Os principais casos de uso discutidos foram:
- Ingestão de dados
- Transformações de dados
- Análise e relatórios
- ML/AI
- Aplicações de dados
- Marketplace
- Governança e gestão de dados
Vamos detalhar cada um deles.
Ingestão de dados
Para interagir com os dados, primeiro é preciso carregá-los ou "expô-los" ao sistema subjacente. Na Snowflake, isso geralmente envolve rodar um comando COPY INTO para carregar os dados em uma tabela que você pode então consultar com a Snowflake. A Snowflake também oferece recursos como o Snowpipe para carregar dados automaticamente.
A maioria dos clientes Snowflake costuma usar também uma solução de terceiros, como Fivetran, Stitch ou Airbyte, para carregar dados de várias fontes (bancos de dados de aplicações, APIs externas, etc.) para a Snowflake.
Já na Databricks, a maioria dos clientes interage diretamente com os dados no cloud storage. O managed Volumes é um conceito parecido com as tabelas da Snowflake, em que a Databricks gerencia a tabela para você.
Com os investimentos da Snowflake em suporte ao Apache Iceberg, mais clientes vão deixar os dados direto no cloud storage e interagir com eles ali, num modelo parecido com o da Databricks.
| Snowflake | Databricks |
|---|---|
| COPY INTO tradicional | Autoloader |
| Snowpipe | Integrações nativas (ex.: S3) |
| Conectores first-party | Volumes |
| Terceiros (Fivetran/Stitch/Airbyte) | DBFS |
| Sem necessidade de ingestão ao usar Iceberg |
Transformações de dados
Depois que seus dados estão expostos à plataforma de nuvem, normalmente você quer transformá-los ou enriquecê-los de alguma forma. As duas plataformas oferecem uma variedade de soluções para isso.
Como a Snowflake é um data warehouse baseado em SQL, a maioria dos clientes faz suas transformações em SQL puro, combinando tasks, stored procedures ou ferramentas terceirizadas de transformação e orquestração, como o dbt. Todos os workloads SQL rodam nos virtual warehouses da Snowflake.
No lado da Databricks, a maioria dos clientes usa Jobs, que permitem submeter um job Spark a um cluster que roda em instâncias de compute na sua nuvem. Com os investimentos recentes da Databricks no produto serverless de SQL warehousing, está ficando mais comum ver transformações em SQL puro com ferramentas como o dbt.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Gráficos em notebooks |
| Streamlit | Visualizações SQL |
| Conectores first-party | Volumes |
| Terceiros (Tableau, Looker, PowerBI, etc.) | Dashboards |
| Terceiros (Tableau, Looker, PowerBI, etc.) |
Análise e relatórios
Tanto Databricks quanto Snowflake oferecem aos clientes diversos recursos para análise e geração de relatórios. A Snowflake permite criar dashboards leves diretamente no Snowsight, ou construir aplicações de dados customizadas usando Streamlit.
A Databricks tem um produto de dashboarding muito bem feito, que algumas empresas usam no lugar de uma ferramenta de BI de terceiros.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Gráficos em notebooks |
| Streamlit | Visualizações SQL |
| Conectores first-party | Volumes |
| Terceiros (Tableau, Looker, PowerBI, etc.) | Dashboards |
| Terceiros (Tableau, Looker, PowerBI, etc.) |
ML/AI
Como já mencionei, as duas empresas estão investindo pesado em recursos de ML e AI. Por causa do foco anterior nessa área, a Databricks tem alguns recursos de ML mais bem desenvolvidos, como o MLflow gerenciado e o Model Serving.
Com o lançamento do Snowpark Container Services, espero que muitos clientes Snowflake consigam rapidamente começar a hospedar modelos de ML diretamente na Snowflake.
| Snowflake | Databricks |
|---|---|
| Snowpark | MLflow |
| Snowpark Container Services | Model Serving |
| Snowflake Cortex | Forte suporte a Python |
Aplicações de dados
Um ângulo interessante para comparar Snowflake e Databricks é a construção de "aplicações de dados". O termo é, confesso, amplo e aberto a interpretações, então vou definir "aplicação de dados" como um produto ou recurso usado para servir dados ou insights em tempo real, externamente, a clientes fora da empresa. Em outras palavras, não é uma aplicação usada internamente.
Por causa do data warehouse SQL de alta performance, muitas empresas (como a SELECT) constroem suas aplicações diretamente em cima da Snowflake e servem as consultas das aplicações direto dos virtual warehouses da Snowflake. Você pode ver mais exemplos disso no programa Powered By da Snowflake. Com novos recursos como o Container Services, será possível hospedar aplicações web completas diretamente na Snowflake.
Para a Databricks, o principal caso de uso para "aplicações de dados externas" viria dos recursos de model serving que eles oferecem, embora algo parecido para servir consultas SQL deva se tornar possível em breve, com os investimentos que estão fazendo nos produtos de data warehousing.
| Snowflake | Databricks |
|---|---|
| Servir apps a partir da Snowflake | Model serving |
| Unistore (HTAP) - hybrid tables | Disparo de Jobs em tempo real |
| Data Sharing | Serverless SQL |
| Container Services |
Marketplace
Como cliente, muitas vezes você quer comprar aplicações ou datasets adicionais para usar na sua plataforma de data cloud. A Snowflake é a clara vencedora aqui, com um marketplace muito maduro, cheio de datasets e aplicações nativas que você pode rodar direto na sua conta Snowflake.
| Snowflake | Databricks |
|---|---|
| Marketplace muito maduro | Marketplace muito maduro |
| Native Apps | Parceiros de tecnologia |
| Cost Management Suite | Bem menos maduro, menor prioridade |
| Grande foco em parceiros |
Governança e gestão de dados
No lado de governança e gestão, as duas plataformas oferecem recursos prontos para usar.
A Snowflake disponibiliza centenas de datasets de metadados gratuitamente para todos os clientes no banco account usage da Snowflake. Eles têm uma suíte de cost management muito avançada, incluindo recursos poderosos como budgets e resource monitors. Recentemente, anunciaram o Snowflake Horizon, um novo conjunto de recursos para ajudar você a governar seus ativos de dados e usuários.
A Databricks tem uma oferta de data catalog muito forte com seu produto Unity Catalog, que ajuda os clientes a gerenciar e entender todos os dados do ambiente. Já no lado do cost management, a Databricks está bem mais atrasada, e só recentemente tornou esses dados acessíveis em system tables (o equivalente deles às views de account usage da Snowflake).
| Snowflake | Databricks |
|---|---|
| Centenas de datasets de metadados (account usage / information schema) | Unity Catalog |
| Snowflake Horizon | System tables |
| Cost Management Suite | Métricas de compute |
| Métricas de compute |
Preços e custos
Tanto a Databricks quanto a Snowflake adotam precificação baseada em uso, em que você paga pelo que consome. Para saber mais sobre o modelo de preços da Snowflake, você pode ler nosso post aqui. As informações de preço da Databricks estão no site deles. Uma coisa muito importante a notar no preço da Databricks é que existem dois conjuntos de cobranças:
- As cobranças de overhead/plataforma da Databricks
- Os custos da nuvem subjacente (AWS/Azure/GCP), referentes aos servidores que a Databricks sobe nessas contas
Como em qualquer plataforma em nuvem baseada em uso, os custos podem disparar rapidamente se não forem gerenciados ou monitorados de forma adequada.
A Databricks é mais barata que a Snowflake?
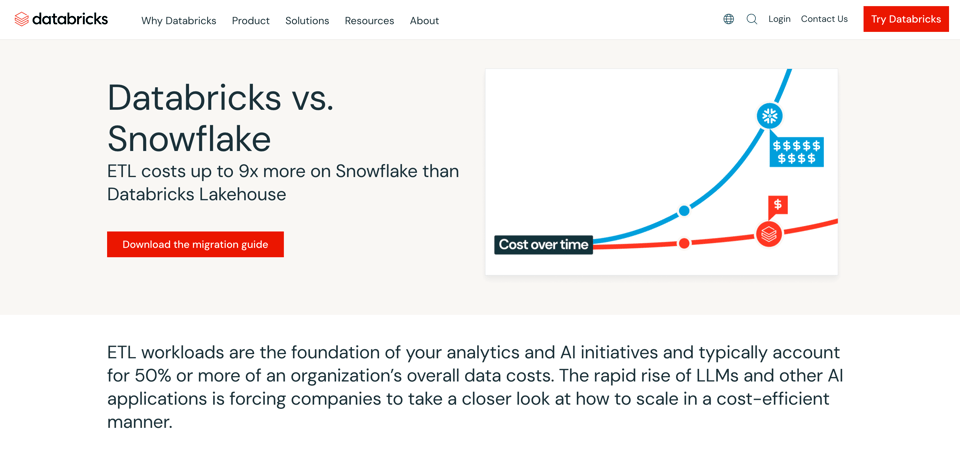
Uma pergunta comum é se a Databricks é mais barata que a Snowflake, em parte impulsionada por um forte esforço de marketing da Databricks, mostrado abaixo a partir do site deles:
Ao considerar o custo de qualquer processo ou aplicação de dados, há dois fatores importantes a levar em conta:
- Os custos de plataforma. O dinheiro que você paga à Databricks/Snowflake/seu provedor de nuvem.
- Os custos humanos. O dinheiro que você paga aos seus funcionários para construir e manter as aplicações e processos que eles criam.
A Databricks afirma que workloads de ETL podem rodar bem mais barato do que na Snowflake. Essa afirmação vem do fato de que jobs Spark podem ser muito ajustados. Existem dezenas de parâmetros diferentes em que os engineers podem passar dias (ou semanas) ajustando e fazendo experimentos.
A parte que muita gente, incluindo o marketing da Databricks, esquece de incluir nessas comparações é o custo humano associado a todo esse trabalho. Em alguns casos, pode fazer sentido pagar engineers para experimentar otimizar e ajustar um job, mas, para a maioria dos workloads de ETL, o overhead de custo humano costuma deixar o custo total mais alto.
Ao tomar qualquer decisão ou fazer qualquer comparação relacionada ao custo de cada plataforma, lembre-se de considerar o custo total de propriedade vindo de (a) o provedor da plataforma e (b) as pessoas que fazem o trabalho.
Participação de mercado
Como a Databricks é uma empresa de capital fechado, eles não divulgam o número exato de clientes nem a penetração em cada mercado.
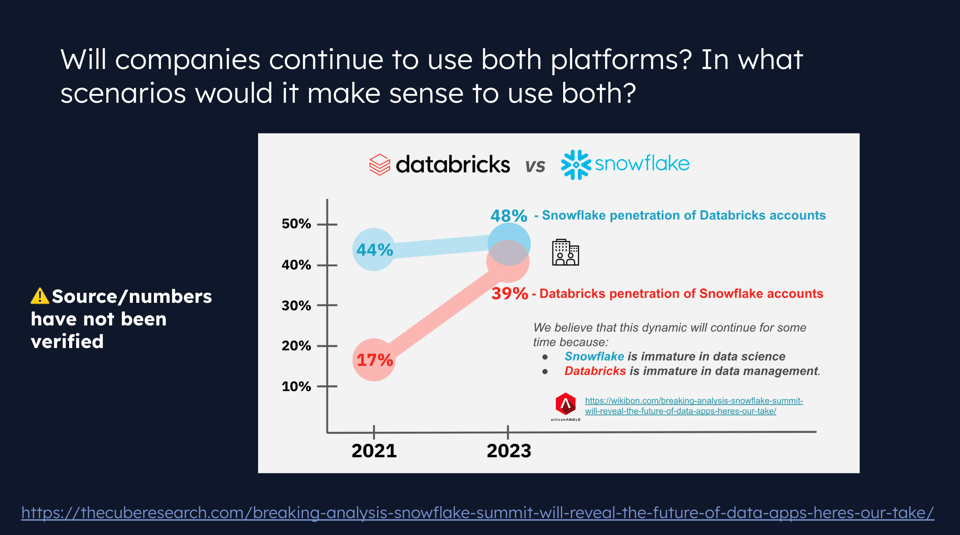
Uma coisa que discutimos no webinar foi quantos clientes usam as duas plataformas. As estatísticas do slide abaixo não são verificadas, mas mostram uma sobreposição crescente entre as duas plataformas.
Eu e o Jeff especulamos que essa sobreposição se deve aos focos historicamente diferentes de cada plataforma, que desde então convergiram.
Ian Whitestone·Co-founder & CEO da SELECT
Ian é Co-founder e CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos para Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times de ciência de dados e engenharia full stack na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e aumentar a observabilidade de custos.