Play
Databricks e Snowflake sono oggi tra le piattaforme data cloud più diffuse sul mercato.
Alle origini affrontavano casi d'uso molto diversi: Snowflake come SQL data warehouse e Databricks come servizio gestito di Apache Spark. Agli inizi erano persino partner!
Oggi sono entrambe piattaforme data cloud a 360 gradi che coprono i casi d'uso più disparati. E, di conseguenza, sono concorrenti diretti.
Il 28 febbraio 2024 ho parlato con Jeff Chou di Sync Computing. La sua azienda lavora esclusivamente con clienti Databricks, mentre noi di SELECT lavoriamo esclusivamente con clienti Snowflake.
Proprio per questo abbiamo pensato che potesse essere interessante confrontarci con una conversazione autentica sulle due piattaforme. Nessuno dei due conosceva a fondo la piattaforma dell'altro, ma entrambi avevamo voglia di imparare l'uno dall'altro.
Ne è uscita una chiacchierata onesta e senza copione tra due addetti ai lavori. Niente benchmark di facciata. Niente fuffa di marketing.
Abbiamo parlato delle rispettive origini, dei casi d'uso più comuni che osserviamo sui clienti reali, dei punti di forza e di debolezza e della direzione che stanno prendendo.
Qui di seguito ho raccolto una sintesi dei temi principali che abbiamo affrontato.
Le origini
Agli inizi Databricks e Snowflake erano partner, ciascuna concentrata su un aspetto diverso della gestione dei dati. Snowflake era specializzata nel data warehousing, Databricks si era ritagliata uno spazio nello Spark gestito, per poi estendersi rapidamente ai workloads di machine learning (ML). Curiosamente, all'epoca si segnalavano clienti a vicenda.
Oggi entrambe le piattaforme sono profondamente trasformate. Guardando i rispettivi siti (snapshot al 27 febbraio 2024), Snowflake si autodefinisce oggi il "data cloud", mentre Databricks si presenta come la "data intelligence platform":
In sostanza, sono entrambe piattaforme data cloud complete e all-in-one al servizio dei casi d'uso più diversi.
Detto questo, ripercorrerne le origini resta interessante perché aiuta a spiegarne i punti di forza e di debolezza attuali.
Snowflake è stata fondata nel 2012 da esperti di data warehousing provenienti da Oracle e da un'altra società di data warehousing, VectorWise. È arrivata sul mercato 10 anni fa, nel 2014, con il suo prodotto di punta per il data warehousing, che spesso veniva definito "elastic data warehouse" grazie a un'architettura unica capace di scalare in modo indipendente compute e storage.
Poco dopo il lancio di Snowflake, Databricks ha presentato il proprio primo prodotto, in un ambito completamente diverso. Databricks è stata fondata dai creatori di Apache Spark, tutti ricercatori nell'area dell'high-performance computing a Berkeley. Il primo prodotto era un'offerta gestita di Apache Spark, con un'interfaccia notebook per eseguire job in modo interattivo su questi cluster di calcolo.
Snowflake ha cominciato a espandersi introducendo nel 2017 le funzionalità di data sharing, seguite nel 2019 da un marketplace dove i clienti potevano acquistare dataset gli uni dagli altri.
Negli stessi anni, Databricks ha approfondito l'ambito ML lanciando nel 2019 l'offerta gestita MLFlow, seguita nel 2020 dal model serving MLFlow.
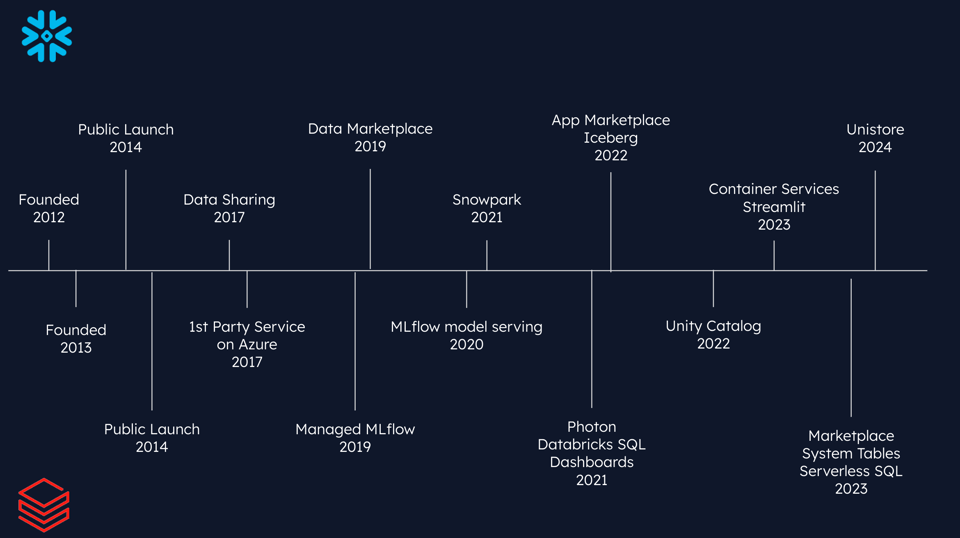
L'evoluzione delle due aziende
Un aspetto interessante da osservare è come ciascuna azienda abbia risposto alle richieste del mercato introducendo funzionalità in diretta concorrenza con l'altra.
Snowflake ha sviluppato Snowpark, pensato inizialmente per migrare workloads Spark e poi evoluto in una piattaforma per workloads ML in Python. Ha inoltre investito molto sul supporto ad Apache Iceberg, così che i clienti possano gestire e sfruttare i propri data lake direttamente da Snowflake.
Sul versante opposto, Databricks ha lanciato funzionalità come Photon e Databricks SQL, ampliando la propria presenza nel territorio del data warehousing.
Lo si vede oggi in modo particolarmente evidente confrontando le interfacce per creare un virtual warehouse su Snowflake e un "SQL warehouse" su Databricks. Databricks ha praticamente ricalcato il design e le impostazioni dei virtual warehouse di Snowflake:

Anche se non compaiono nella slide della timeline qui sopra, tra la fine del 2023 e l'inizio del 2024 entrambe le aziende hanno annunciato numerose funzionalità AI/LLM. Siamo ancora agli albori in questo ambito, ma entrambe hanno fatto acquisizioni rilevanti e stanno investendo in modo massiccio.
Vantaggi di ciascuna piattaforma ed elementi differenzianti
Capire da dove sia partita ciascuna azienda è importante, perché aiuta a spiegarne i relativi punti di forza e di debolezza.
Grazie alle sue radici nel data warehousing, Snowflake offre un prodotto di SQL data warehousing decisamente più solido e completo. Per la maggior parte delle aziende è la funzionalità più importante e più utilizzata, dato che gran parte del valore generato dalle strategie sui dati nasce da un data warehouse ben gestito, in grado di alimentare i casi d'uso core di business intelligence.
Pochissime aziende con cui parlo usano Databricks come "data warehouse". Si affidano a Databricks piuttosto per i suoi potenti notebook Python e per il solido supporto ai workloads di data science. Per le aziende con data engineer molto tecnici che preferiscono lavorare con Apache Spark e Python, Databricks è spesso la scelta privilegiata per le data transformation. Un vantaggio di Databricks negli scenari ETL è la flessibilità e la personalizzazione di Spark. Per workloads analitici che elaborano dataset estremamente grandi può essere preferibile lavorare con Spark, perché si possono regolare più parametri e far girare il job a costi inferiori. La mia esperienza dice che questa considerazione ha senso soltanto per workloads da decine di migliaia di dollari l'anno: i costi umani legati alla manutenzione e allo sviluppo di queste data pipeline finiscono spesso per superare i risparmi ottenuti sul fronte compute.
Sul piano delle roadmap future e dell'evoluzione di prodotto, uno dei principali elementi differenzianti di Snowflake è il focus sulla piattaforma. A fine 2023 Snowflake ha rilasciato Snowpark Container Services, che consente ai clienti di eseguire applicazioni containerizzate dentro Snowflake. Combinato con il marketplace di native application, è evidente che Snowflake sta costruendo uno scenario futuro in cui clienti e partner potranno eseguire qualsiasi tipo di applicazione dati direttamente in Snowflake.
Databricks sembra invece puntare a offrire al cliente una soluzione gestita pronta all'uso per ogni caso d'uso. Due esempi chiari sono la funzionalità di dashboard e il data catalog. Con Snowflake, la maggior parte dei clienti acquista uno strumento di BI/dashboarding esterno che si appoggia a Snowflake. Allo stesso modo, acquista un prodotto separato di data catalog per gestire e tenere traccia di tutti i dataset. Databricks sta chiaramente provando a eliminare la necessità per il cliente di comprare strumenti separati. Nel 2020 ha acquisito Redash, trasformandola in una solida offerta di dashboard out-of-the-box. Sta inoltre investendo molto sul proprio Unity Catalog, pensato per sostituire i fornitori terzi di data catalog.
Casi d'uso e confronto delle funzionalità chiave
Durante il webinar abbiamo passato in rassegna i casi d'uso principali di una piattaforma data cloud, elencando per ciascuno le funzionalità di Databricks e di Snowflake. I casi d'uso principali sono stati:
- Data Ingestion
- Data Transformation
- Analisi e reporting
- ML/AI
- Data Application
- Marketplace
- Data Governance e Management
Vediamoli uno per uno.
Data Ingestion
Per poter interagire con i dati occorre prima caricarli, o "esporli", al sistema sottostante. In Snowflake questo si fa di solito con il comando COPY INTO, che carica i dati in una tabella poi interrogabile via Snowflake. Snowflake offre anche funzionalità come Snowpipe per caricare i dati in automatico.
Tipicamente, la maggior parte dei clienti Snowflake usa anche soluzioni di terze parti come Fivetran, Stitch o Airbyte per caricare dati da varie sorgenti (database applicativi, API esterne, ecc.) dentro Snowflake.
Con Databricks, invece, la maggior parte dei clienti interagisce direttamente con i dati nel cloud storage. I Volumes gestiti sono comunque un concetto simile alle tabelle Snowflake: è Databricks a gestire la tabella per l'utente.
Con gli investimenti di Snowflake sul supporto ad Apache Iceberg, sempre più clienti lasceranno i dati direttamente nel cloud storage e li interrogheranno da lì, in modo analogo al modello Databricks.
| Snowflake | Databricks |
|---|---|
| COPY INTO tradizionale | Autoloader |
| Snowpipe | Integrazioni native (es. S3) |
| Connettori first party | Volumes |
| Soluzioni di terze parti (Fivetran/Stitch/Airbyte) | DBFS |
| Nessuna ingestion necessaria con Iceberg |
Data Transformation
Una volta esposti i dati alla piattaforma cloud, spesso si vogliono trasformare o arricchire. Entrambe le piattaforme propongono diverse soluzioni per farlo.
Essendo Snowflake un data warehouse basato su SQL, la maggior parte dei clienti esegue le data transformation in puro SQL combinando task, stored procedure o strumenti di trasformazione e orchestrazione di terze parti come dbt. Tutti i workloads SQL girano nei virtual warehouse di Snowflake.
Sul fronte Databricks, la maggior parte dei clienti usa i Jobs, che consentono di sottomettere un job Spark a un cluster eseguito su istanze compute nel proprio cloud. Con i recenti investimenti di Databricks sul prodotto serverless SQL warehousing, è sempre più frequente vedere data transformation in puro SQL con strumenti come dbt.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Notebook plots |
| Streamlit | SQL Visualizations |
| Connettori first party | Volumes |
| Soluzioni di terze parti (Tableau, Looker, PowerBI, ecc.) | Dashboard |
| Soluzioni di terze parti (Tableau, Looker, PowerBI, ecc.) |
Analisi e reporting
Sia Databricks sia Snowflake mettono a disposizione dei propri clienti diverse funzionalità per analisi e reporting. Snowflake consente di creare dashboard leggere direttamente in Snowsight, oppure di costruire data app personalizzate con Streamlit.
Databricks ha un prodotto di dashboarding molto ben fatto, che alcune aziende usano al posto di uno strumento di BI di terze parti.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Notebook plots |
| Streamlit | SQL Visualizations |
| Connettori first party | Volumes |
| Soluzioni di terze parti (Tableau, Looker, PowerBI, ecc.) | Dashboard |
| Soluzioni di terze parti (Tableau, Looker, PowerBI, ecc.) |
ML/AI
Come anticipato, entrambe le aziende stanno investendo molto nelle capacità di ML e AI. Grazie al focus iniziale su questo ambito, Databricks ha funzionalità ML più mature, come MLflow gestito e Model Serving.
Con il lancio di Snowpark Container Services mi aspetto che molti clienti Snowflake potranno presto iniziare a ospitare modelli ML direttamente in Snowflake.
| Snowflake | Databricks |
|---|---|
| Snowpark | MLflow |
| Snowpark Container Services | Model Serving |
| Snowflake Cortex | Forte supporto a Python |
Data Application
Un angolo di confronto interessante tra Snowflake e Databricks riguarda la costruzione delle "data application". Il termine è certamente ampio e aperto a interpretazione, quindi definirò "data application" un prodotto o una funzionalità usata per servire dati o insight in tempo reale a clienti esterni all'azienda. In altre parole, non un'applicazione di uso interno.
Grazie al suo SQL data warehouse ad alte prestazioni, molte aziende (come SELECT) costruiscono le proprie applicazioni direttamente sopra Snowflake, servendo le query applicative direttamente dai virtual warehouse Snowflake. Altri esempi si trovano nel programma Powered By di Snowflake. Con le nuove funzionalità come Container Services sarà possibile ospitare intere applicazioni web direttamente in Snowflake.
Per Databricks, il principale caso d'uso di "data application esterne" deriva dalle funzionalità di model serving offerte, anche se un serving SQL analogo dovrebbe diventare presto possibile grazie agli investimenti sui propri prodotti di data warehousing.
| Snowflake | Databricks |
|---|---|
| Erogazione di app da Snowflake | Model serving |
| Unistore (HTAP) - tabelle ibride | Trigger di Jobs al volo |
| Data Sharing | Serverless SQL |
| Container Services |
Marketplace
Come cliente, spesso si vogliono acquistare applicazioni o dataset aggiuntivi da utilizzare nella propria piattaforma data cloud. Qui Snowflake è il vincitore indiscusso, con un marketplace molto maturo, ricco sia di dataset sia di native application eseguibili direttamente nel proprio account Snowflake.
| Snowflake | Databricks |
|---|---|
| Marketplace molto maturo | Marketplace molto maturo |
| Native Apps | Technology partners |
| Cost Management Suite | Molto meno maturo, priorità inferiore |
| Forte focus sui partner |
Data Governance e Management
Sul fronte governance e management, entrambe le piattaforme offrono funzionalità pronte all'uso.
Snowflake mette gratuitamente a disposizione di tutti i clienti centinaia di dataset di metadati nel database account usage di Snowflake. Dispone inoltre di una suite di cost management molto avanzata, con funzionalità potenti come budget e resource monitor. Ha recentemente annunciato Snowflake Horizon, un nuovo set di funzionalità per governare asset di dati e utenti.
Databricks vanta un'offerta di data catalog molto solida con il prodotto Unity Catalog, che aiuta i clienti a gestire e a comprendere tutti i dati presenti nel loro ambiente. Sul fronte cost management Databricks è invece molto più indietro e solo di recente ha reso accessibili questi dati nelle system table (l'equivalente delle account usage view di Snowflake).
| Snowflake | Databricks |
|---|---|
| Centinaia di dataset di metadati (account usage / information schema) | Unity Catalog |
| Snowflake Horizon | System tables |
| Cost Management Suite | Compute metrics |
| Compute metrics |
Prezzi e costi
Sia Databricks sia Snowflake adottano un pricing usage-based: si paga ciò che si consuma. Per approfondire il modello di pricing di Snowflake, può leggere il nostro articolo qui. Le informazioni sui prezzi di Databricks si trovano sul sito ufficiale. Un aspetto importantissimo del pricing di Databricks è che gli addebiti sono di due tipi:
- I costi di overhead/piattaforma fatturati da Databricks
- I costi cloud sottostanti di AWS/Azure/GCP per i server che Databricks attiva in quegli account
Come ogni piattaforma cloud usage-based, i costi possono lievitare rapidamente se non vengono gestiti o monitorati con attenzione.
Databricks costa meno di Snowflake?
Una domanda ricorrente è se Databricks costi meno di Snowflake, anche per via di un forte sforzo di marketing di Databricks, illustrato qui sotto e tratto dal sito ufficiale:
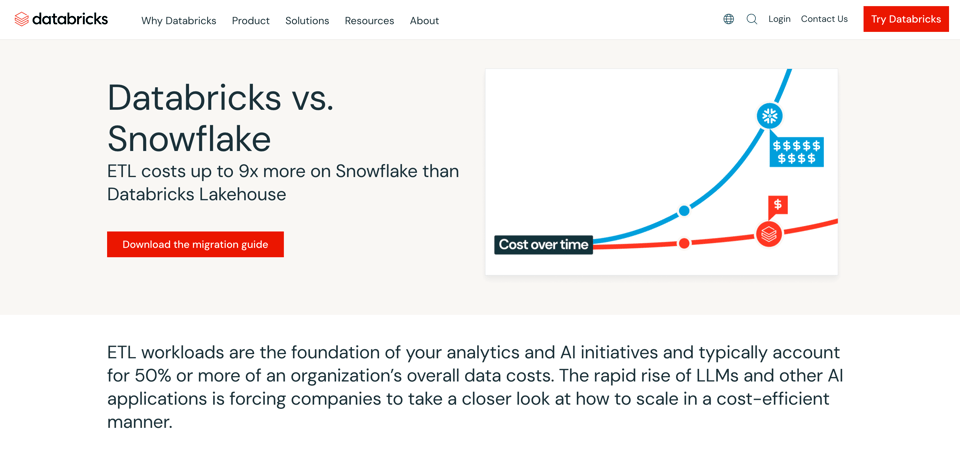
Quando si valuta il costo di un processo o di un'applicazione sui dati, ci sono due fattori importanti da tenere a mente:
- I costi di piattaforma. Il denaro versato a Databricks/Snowflake/al proprio cloud provider.
- I costi umani. Il denaro versato ai propri collaboratori per costruire e mantenere le applicazioni e i processi che realizzano.
Databricks afferma che i workloads ETL possono essere eseguiti a costi molto inferiori rispetto a Snowflake. L'affermazione nasce dal fatto che i job Spark si prestano a un tuning molto spinto. Esistono moltissimi parametri sui quali gli engineer possono passare giorni (o settimane) a sperimentare e mettere a punto.
Ciò che molti, compreso il marketing di Databricks, tendono a tralasciare in questi confronti è il costo umano associato a tutto questo lavoro. In certi scenari può avere senso retribuire degli engineer perché sperimentino sull'ottimizzazione e sul tuning di un job, ma per la maggior parte dei workloads ETL i costi umani di overhead finiscono spesso per far salire il costo totale.
Nel prendere decisioni o nel fare confronti sul costo di ciascuna piattaforma, ricordi sempre di considerare il costo totale di proprietà, dato da (a) provider della piattaforma e (b) persone che svolgono il lavoro.
Quota di mercato
Essendo Databricks un'azienda privata, non comunica il numero esatto di clienti né la propria penetrazione nei singoli mercati.
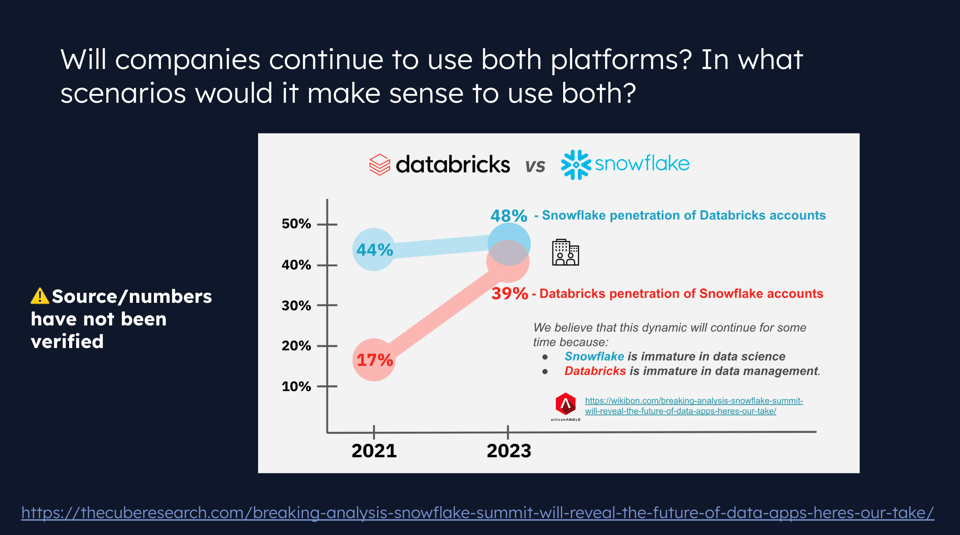
Un tema affrontato nel webinar è stato quanti clienti utilizzino entrambe le piattaforme. I dati nella slide qui sotto non sono verificati, ma mostrano una sovrapposizione crescente tra le due piattaforme.
Jeff e io abbiamo entrambi ipotizzato che questa sovrapposizione sia legata ai focus storicamente diversi delle due piattaforme, oggi sempre più convergenti.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder e CEO di SELECT, piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, ha trascorso 6 anni alla guida di team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha guidato il lavoro di ottimizzazione del data warehouse e di crescita dell'osservabilità dei costi.