Play
DatabricksとSnowflakeは、現在のデータクラウドプラットフォーム市場で最も人気のある2大プロダクトです。
もともと両者は、まったく異なるユースケースから出発しました。SnowflakeはSQLデータウェアハウスとして、DatabricksはApache Sparkのマネージドサービスとしてのスタートです。創業初期にはパートナーだった時期すらありました。
そして現在、両者はいずれも多面的なデータクラウドプラットフォームへと成長し、幅広いユースケースをカバーしています。その結果、いまや真っ向から競合する関係になっています。
2024年2月28日、私はSync ComputingのJeff Chou氏と対談する機会を得ました。Jeff氏の会社はDatabricksユーザーだけを支援しており、私たちSELECTはSnowflakeユーザーだけを支援しています。
そんな両社だからこそ、それぞれのプラットフォームについて率直に語り合ったら面白いのでは、ということで実現した対談です。お互い相手側のプラットフォームに詳しいわけではありませんが、相手から学びたいという思いは強くありました。
これは現場の実務者2人による、台本なし・忖度なしの対話です。怪しいベンチマークも、マーケティング的な誇張も一切ありません。
両者の成り立ち、実際のユーザーで最も多いユースケース、それぞれの強みと弱み、そして今後の方向性について話し合いました。
以下に、議論の要点をまとめました。
両社の成り立ち
当初、DatabricksとSnowflakeはパートナーとして、データ管理のそれぞれ異なる領域に注力していました。Snowflakeはデータウェアハウスを専門とし、DatabricksはマネージドSparkで独自のポジションを築き、その後すぐに機械学習(ML)のワークロードへと領域を広げました。興味深いことに、両社はかつてお互いに顧客を紹介し合う関係でもあったのです。
そして現在、両プラットフォームは大きく姿を変えています。両社のウェブサイト(2024年2月27日時点のスナップショット)を見ると、Snowflakeは自らを「データクラウド」と称し、Databricksは「データインテリジェンスプラットフォーム」を掲げています。
突き詰めれば、両者ともさまざまなデータユースケースをカバーする、包括的なオールインワンのデータクラウドプラットフォームです。
とはいえ、両社の成り立ちをたどることは、今日のそれぞれの強み・弱みを理解するうえで非常に有益です。
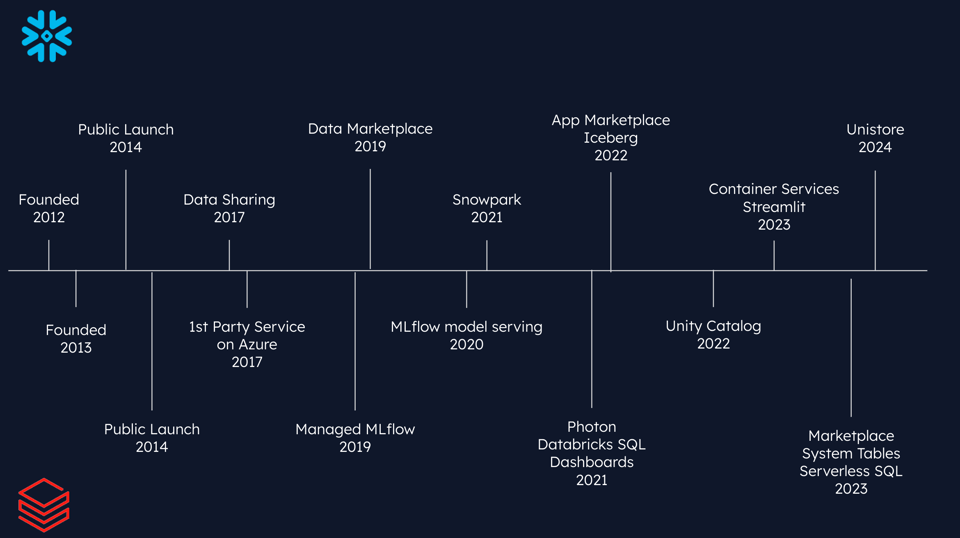
Snowflakeは2012年、Oracle出身者と、もう一つのデータウェアハウス企業VectorWise出身の専門家らによって設立されました。10年前の2014年、主力のデータウェアハウス製品を引っ提げて市場に参入。コンピュートとストレージを独立してスケールできる独自アーキテクチャから、しばしば「エラスティック・データウェアハウス」と呼ばれていました。
Snowflakeのローンチからまもなく、Databricksはまったく別の領域で最初のプロダクトを世に出しました。Databricksの創業者は、いずれもバークレー校で高性能コンピューティングの研究に携わっていた研究者で、Apache Sparkの開発者たちです。最初のプロダクトはApache Sparkのマネージドサービスで、コンピュートクラスター上でジョブをインタラクティブに実行できるノートブックインターフェースを備えていました。
Snowflakeは2017年にデータ共有機能を投入して領域を広げ、2019年には顧客同士でデータセットを売買できるマーケットプレイスを立ち上げました。
ほぼ同じ時期にDatabricksも、2019年にマネージドMLflow、2020年にMLflowのモデルサービングをローンチし、ML領域に深く踏み込んでいきました。
両社の進化
注目すべきは、両社が市場のニーズにどう応え、どのように競合機能を投入してきたかです。
Snowflakeは当初、Sparkワークロードの移行を狙ったSnowparkを開発し、これがPythonベースのMLワークロード向けプラットフォームへと発展しました。さらにApache Icebergのサポートにも大きく投資し、顧客がSnowflakeから直接データレイクを管理・活用できる環境を整えてきました。
一方Databricksは、PhotonやDatabricks SQLといった機能を投入し、データウェアハウス領域へと攻め込んでいます。
この流れは、Snowflakeの仮想ウェアハウス作成画面と、Databricksの「SQL warehouse」作成画面を見比べると一目瞭然です。DatabricksがSnowflakeの仮想ウェアハウスの設計や設定をほぼそのまま踏襲していることがわかります。

上のタイムラインには載っていませんが、両社とも2023年後半から2024年初頭にかけて、AI/LLM関連の機能発表を立て続けに行っています。この領域はまだ黎明期ですが、両社とも大型買収を実施しており、巨額の投資を続けています。
各プラットフォームの強みと主な差別化ポイント
両プラットフォームの相対的な強み・弱みを理解するには、両社がどう始まったかを知ることが重要です。
データウェアハウスから出発したSnowflakeは、SQLデータウェアハウス製品としてはるかに成熟しており、機能面でも充実しています。多くの企業にとって、これは最も重要かつ最も多く使われる機能でしょう。データ戦略から得られる価値の大半は、コアなBIユースケースを支える、しっかり管理されたデータウェアハウスから生まれるからです。
私が話を伺う企業のうち、Databricksを「データウェアハウス」として使っているケースはごくわずかです。多くの企業はむしろ、強力なPythonノートブックと手厚いデータサイエンス向けサポートを目当てにDatabricksを使っています。Apache SparkとPythonを好む技術志向の強いデータエンジニアを擁する企業では、データ変換にDatabricksを選ぶケースが多く見られます。ETLユースケースにおけるDatabricksの利点の一つは、Sparkの柔軟性とカスタマイズ性です。極めて大規模なデータセットを処理する分析ワークロードでは、より多くのパラメーターをチューニングしてジョブを安く回せるため、Sparkが好まれることもあります。ただし私の経験では、こうしたチューニングが意味を持つのは、年間数万ドル以上のコストがかかるワークロードに限られます。データパイプラインの保守・開発にかかる人件費が、コンピュート側で得られる削減額を上回ってしまうことが多いからです。
今後のロードマップとプロダクト進化という観点では、Snowflakeの主要な差別化要因はそのプラットフォーム志向にあります。2023年後半、SnowflakeはSnowpark Container Servicesをリリースし、コンテナ化されたアプリケーションをSnowflake上で実行できるようにしました。ネイティブアプリケーションのマーケットプレイスと組み合わせると、顧客やパートナーがあらゆる種類のデータアプリケーションをSnowflake上で直接動かせる未来を見据えていることは明らかです。
一方Databricksは、あらゆるユースケースに対して標準で完結するマネージドソリューションを提供する方向に舵を切っているようです。その典型例がダッシュボード機能とデータカタログです。Snowflakeでは、多くの顧客が外部のBI/ダッシュボードツールを別途導入して、その上に乗せて使います。データセットの管理・追跡のために、別のデータカタログ製品を導入するのも一般的です。Databricksは、顧客がこうしたツールを別途購入する必要をなくそうとしています。2020年にはRedashという会社を買収し、強力な標準搭載のダッシュボード機能へと育て上げました。同様に、サードパーティのデータカタログを置き換えることを目指すUnity Catalogにも巨額の投資を行っています。
ユースケースと主要機能の比較
ウェビナーでは、データクラウドプラットフォームの中核となるユースケースを取り上げ、それぞれについてDatabricksとSnowflakeの機能を比較しました。主に議論したユースケースは以下のとおりです。
- データ取り込み
- データ変換
- 分析・レポーティング
- ML/AI
- データアプリケーション
- マーケットプレイス
- データガバナンス・管理
それぞれ詳しく見ていきましょう。
データ取り込み
データを扱うには、まず基盤システムにロードする、あるいは「見える化」する必要があります。Snowflakeの場合、通常はCOPY INTOコマンドを実行してデータをテーブルに取り込み、そのテーブルに対してクエリを発行します。Snowflakeにはデータを自動でロードするSnowpipeのような機能もあります。
多くのSnowflakeユーザーは、Fivetran、Stitch、Airbyteといったサードパーティのソリューションを使い、各種ソース(アプリケーションのデータベース、外部APIなど)からSnowflakeにデータをロードしています。
Databricksの場合、多くのユーザーはクラウドストレージ上のデータを直接扱います。とはいえマネージドVolumesは、テーブルをDatabricks側で管理してくれるという意味で、Snowflakeテーブルに近いコンセプトです。
SnowflakeがApache Icebergのサポートに投資したことで、データをクラウドストレージに置いたまま操作するユーザーも増えていくでしょう。これはDatabricksに近いモデルです。
| Snowflake | Databricks |
|---|---|
| 従来型のCOPY INTO | Autoloader |
| Snowpipe | ネイティブ連携(例:S3) |
| ファーストパーティコネクタ | Volumes |
| サードパーティ(Fivetran/Stitch/Airbyte) | DBFS |
| Iceberg利用時は取り込み不要 |
データ変換
データをプラットフォームに取り込んだら、次は何らかの形で変換・加工したくなるのが普通です。両プラットフォームとも、そのためのソリューションを幅広く提供しています。
SnowflakeはSQLベースのデータウェアハウスなので、多くのユーザーはタスク、ストアドプロシージャ、あるいはdbtのようなサードパーティの変換・オーケストレーションツールを組み合わせ、純粋なSQLでデータ変換を行います。SQLワークロードはすべてSnowflakeの仮想ウェアハウス上で実行されます。
Databricks側では、多くのユーザーがJobsを使い、クラウド上のコンピュートインスタンスで動くクラスターにSparkジョブを投入しています。最近のサーバーレスSQLウェアハウス製品への投資により、dbtなどを使った純粋なSQLによるデータ変換も増えてきています。
| Snowflake | Databricks |
|---|---|
| Snowsightダッシュボード | ノートブックのプロット |
| Streamlit | SQLビジュアライゼーション |
| ファーストパーティコネクタ | Volumes |
| サードパーティ(Tableau、Looker、PowerBIなど) | ダッシュボード |
| サードパーティ(Tableau、Looker、PowerBIなど) |
分析・レポーティング
DatabricksとSnowflakeは、いずれも分析・レポーティング向けの機能を多く備えています。SnowflakeではSnowsight上で軽量なダッシュボードを直接作成できるほか、Streamlitを使ったカスタムのデータアプリ構築も可能です。
Databricksは作り込まれたダッシュボード機能を備えており、サードパーティのBIツールの代わりに使う企業もあります。
| Snowflake | Databricks |
|---|---|
| Snowsightダッシュボード | ノートブックのプロット |
| Streamlit | SQLビジュアライゼーション |
| ファーストパーティコネクタ | Volumes |
| サードパーティ(Tableau、Looker、PowerBIなど) | ダッシュボード |
| サードパーティ(Tableau、Looker、PowerBIなど) |
ML/AI
前述のとおり、両社ともML・AI領域に巨額の投資を続けています。Databricksはこの領域に早くから注力していたため、マネージドMLflowやModel Servingといった、より成熟したML機能を備えています。
Snowpark Container Servicesの登場で、多くのSnowflakeユーザーもまもなくMLモデルをSnowflake上に直接ホストできるようになると見ています。
| Snowflake | Databricks |
|---|---|
| Snowpark | MLflow |
| Snowpark Container Services | Model Serving |
| Snowflake Cortex | 強力なPythonサポート |
データアプリケーション
SnowflakeとDatabricksを比べるうえで面白い切り口の一つが、「データアプリケーション」の構築です。この言葉は確かに広く解釈の余地があるため、ここでは「社外の顧客に向けてライブのデータやインサイトを提供するためのプロダクトや機能」と定義します。つまり、社内利用のアプリケーションではない、という意味です。
Snowflakeは高性能なSQLデータウェアハウスを備えているため、多くの企業(SELECTもその一つです)はSnowflakeの上に直接アプリケーションを構築し、Snowflakeの仮想ウェアハウスから直接アプリケーションのクエリを処理しています。同様の事例はSnowflakeのPowered Byプログラムでも数多く確認できます。Container Servicesのような新機能により、本格的なWebアプリケーションをSnowflake上で直接ホストすることも可能になっていくでしょう。
Databricksの「外部向けデータアプリケーション」の主なユースケースは、いまのところモデルサービング機能ですが、データウェアハウス製品への投資が進めば、同様のSQLクエリ提供も近いうちに可能になるはずです。
| Snowflake | Databricks |
|---|---|
| Snowflakeからアプリを直接配信 | モデルサービング |
| Unistore(HTAP)- ハイブリッドテーブル | オンデマンドでのJobs起動 |
| データ共有 | サーバーレスSQL |
| Container Services |
マーケットプレイス
ユーザーとしては、自社のデータクラウド上で使うために、アプリケーションやデータセットを追加で購入したい場面がよくあります。この点ではSnowflakeに軍配が上がります。データセットと、Snowflakeアカウント上で直接実行できるネイティブアプリケーションの両方を擁する、非常に成熟したマーケットプレイスを備えているからです。
| Snowflake | Databricks |
|---|---|
| 非常に成熟したマーケットプレイス | 非常に成熟したマーケットプレイス |
| ネイティブアプリ | テクノロジーパートナー |
| コスト管理スイート | 成熟度は低く、優先度も低い |
| パートナー戦略への強い注力 |
データガバナンス・管理
ガバナンス・管理の面でも、両プラットフォームは標準機能を提供しています。
Snowflakeは、Snowflakeのアカウント使用状況データベースを通じて、数百ものメタデータデータセットをすべての顧客に無料で公開しています。budgetsやリソースモニターといった強力な機能を含む、非常に高度なコスト管理スイートを備えており、最近ではデータ資産とユーザーのガバナンスを支援する新機能群Snowflake Horizonも発表されました。
DatabricksはUnity Catalogという非常に強力なデータカタログ製品を擁しており、環境内のすべてのデータを管理・把握するのに役立っています。一方で、コスト管理の面では大きく遅れをとっており、つい最近になってシステムテーブル(Snowflakeのaccount usageビューに相当)でようやくデータにアクセスできるようになったばかりです。
| Snowflake | Databricks |
|---|---|
| 数百のメタデータデータセット(account usage/information schema) | Unity Catalog |
| Snowflake Horizon | システムテーブル |
| コスト管理スイート | コンピュートメトリクス |
| コンピュートメトリクス |
価格とコスト
DatabricksとSnowflakeはいずれも、使った分だけ支払う従量課金モデルを採用しています。Snowflakeの料金モデルについて詳しくは、こちらの記事をご覧ください。Databricksの料金情報は公式サイトで確認できます。Databricksの料金で押さえておくべき非常に重要なポイントは、課金が2階建てになっていることです。
- Databricksから請求されるプラットフォーム利用料(オーバーヘッド)
- Databricksが顧客のアカウント上で起動するサーバーに対して、AWS/Azure/GCPから請求される基盤クラウドの利用料
どんな従量課金型のクラウドでも同じですが、適切に管理・監視しなければコストはあっという間に膨れ上がります。
DatabricksはSnowflakeより安いのか?
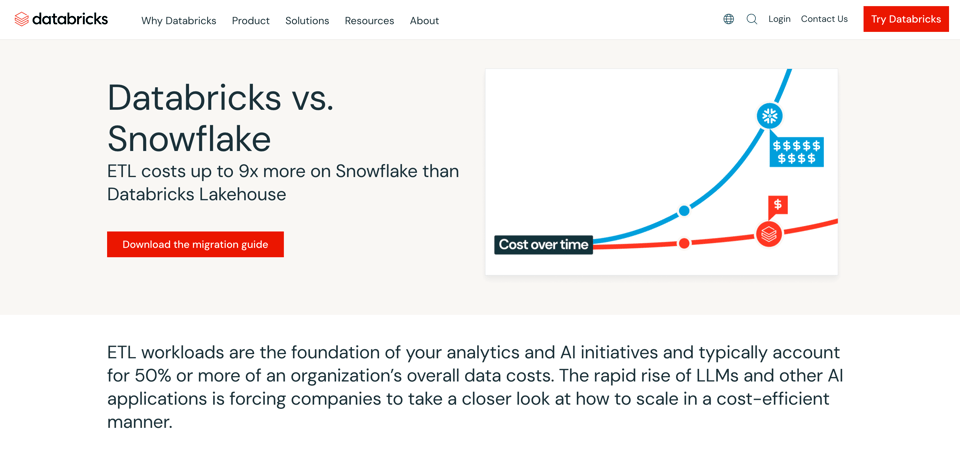
よく聞かれる質問の一つが、「DatabricksはSnowflakeより安いのか?」というものです。その背景の一つには、Databricksによる積極的なマーケティングがあります(下の画像は公式サイトより)。
データ処理やアプリケーションのコストを評価する際には、2つの重要な要素を見る必要があります。
- プラットフォームコスト。Databricks/Snowflake/クラウドプロバイダーに支払う費用です。
- 人件費。アプリケーションやプロセスを構築・維持する従業員に支払う費用です。
DatabricksはETLワークロードをSnowflakeよりはるかに安く実行できると主張しています。これは、Sparkジョブを徹底的にチューニングできることに根拠があります。エンジニアが何日も、ときには何週間もかけて調整・検証できるパラメーターが膨大に存在するのです。
ただ、Databricksのマーケティングを含め、こうした比較で多くの人が見落としているのが、その作業にかかる人件費です。ジョブの最適化やチューニングをエンジニアに任せる価値があるケースもありますが、ほとんどのETLワークロードでは、人件費を含めた総コストはむしろ高くつくのが現実です。
各プラットフォームのコストを意思決定や比較に使う際は、(a)プラットフォーム提供者への支払いと、(b)作業を担う人にかかる費用の両方を含めた総保有コストで判断するようにしてください。
市場シェア
Databricksは未上場企業のため、正確な顧客数や各市場でのシェアは公表されていません。
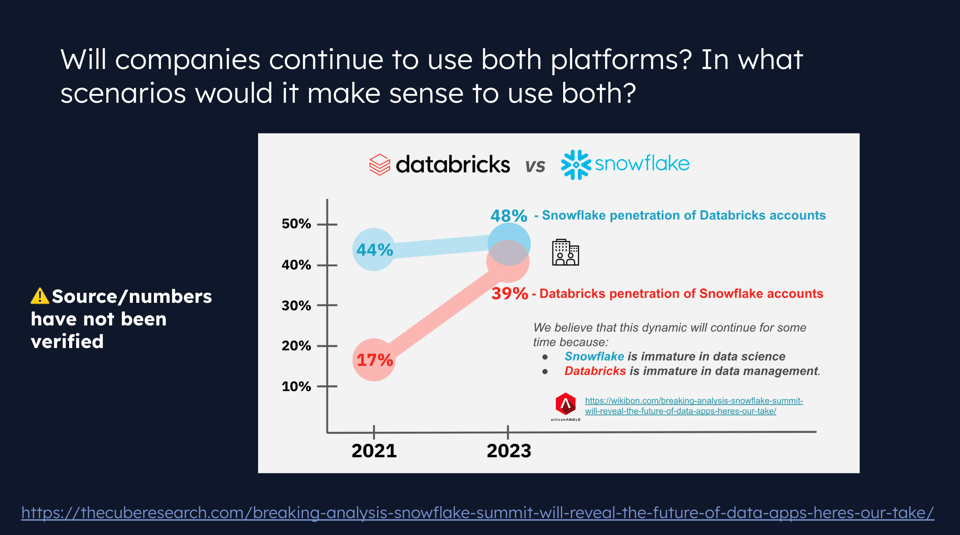
ウェビナーで議論したトピックの一つが、両プラットフォームを併用している顧客がどれくらいいるか、という点でした。下のスライドの数字は未検証ながら、両プラットフォームの利用が重なる領域が広がっていることを示しています。
Jeffも私も、この重なりは、もともと異なる領域に注力していた両プラットフォームが徐々に同じ方向へ収斂してきた結果ではないかと推測しています。
Ian Whitestone・SELECT 共同創業者兼CEO
Ianは、Snowflakeのコスト管理・最適化SaaSプラットフォームであるSELECTの共同創業者兼CEOです。SELECTの創業前は、ShopifyとCapital Oneでフルスタックのデータサイエンス&エンジニアリングチームを6年間率いていました。Shopifyでは、データウェアハウスの最適化とコストの可視化を主導しました。