Play
Databricks et Snowflake figurent aujourd'hui parmi les plateformes data cloud les plus en vue du marché.
À leurs débuts, elles répondaient à des usages très différents : Snowflake comme entrepôt de données SQL, Databricks comme service Apache Spark managé. Elles étaient même partenaires à l'époque !
Aujourd'hui, ce sont deux plateformes data cloud aux multiples facettes, qui couvrent des cas d'usage variés. Et, de fait, deux concurrents directs.
Le 28 février 2024, j'ai échangé avec Jeff Chou, de Sync Computing. Son entreprise travaille exclusivement avec des clients Databricks, tandis que chez SELECT, nous nous adressons uniquement aux clients Snowflake.
Vu cette spécificité, il nous a semblé intéressant de nous retrouver pour parler franchement de chaque plateforme. Aucun de nous ne maîtrisait à fond celle de l'autre, mais nous étions curieux d'en apprendre davantage.
Une conversation honnête et sans script entre deux praticiens. Pas de benchmarks bidons. Pas de blabla marketing.
Nous avons parlé de leurs origines, des cas d'usage les plus courants chez nos clients, de leurs forces et faiblesses, et de la trajectoire qu'elles dessinent.
Vous trouverez ci-dessous une synthèse des points clés abordés.
Aux origines
Au départ, Databricks et Snowflake étaient partenaires, chacun se concentrant sur des facettes différentes de la gestion des données. Snowflake s'est spécialisé dans l'entreposage de données, tandis que Databricks s'est imposé sur Spark managé, avant de s'étendre rapidement aux workloads de machine learning (ML). Fait amusant : ils se renvoyaient mutuellement des clients.
Aujourd'hui, les deux plateformes ont profondément évolué. Sur leurs sites respectifs (capturés au 27 février 2024), Snowflake se présente désormais comme le "data cloud", tandis que Databricks se positionne comme la "data intelligence platform" :
Au fond, il s'agit de deux plateformes data cloud complètes et tout-en-un, qui couvrent une grande variété de cas d'usage.
Cela dit, il reste passionnant de revenir sur leurs origines : cela éclaire les forces et faiblesses relatives de chaque plateforme aujourd'hui.
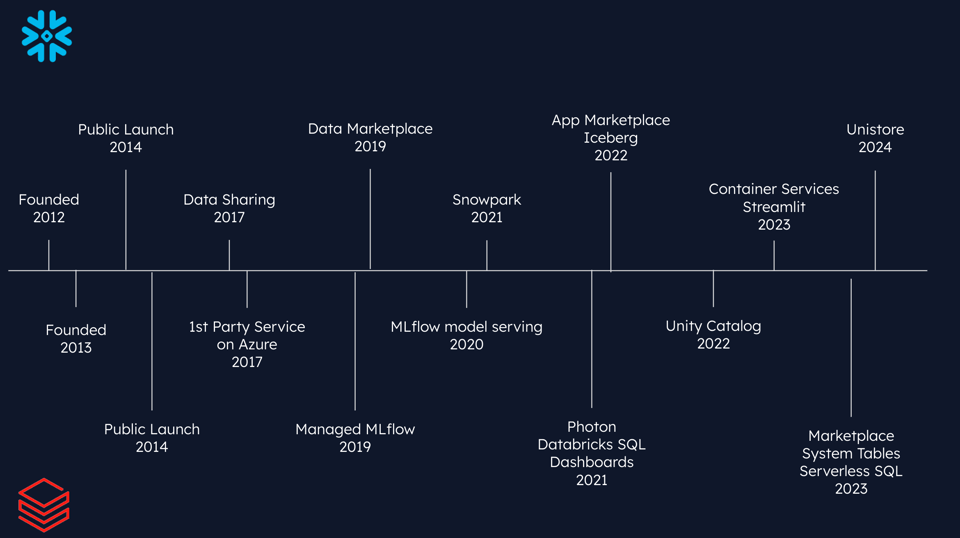
Snowflake a été fondé en 2012 par des experts du data warehousing issus d'Oracle et d'une autre entreprise du secteur, VectorWise. La société est arrivée sur le marché il y a 10 ans, en 2014, avec son produit phare de data warehousing, souvent qualifié d'elastic data warehouse en raison de son architecture unique, qui permet de faire évoluer indépendamment compute et stockage.
Peu après le lancement de Snowflake, Databricks a sorti son premier produit, dans un tout autre domaine. L'entreprise a été fondée par les créateurs d'Apache Spark, tous issus du monde universitaire et spécialisés dans le calcul haute performance à Berkeley. Leur premier produit était une offre managée d'Apache Spark, accompagnée d'une interface notebook permettant d'exécuter des jobs de façon interactive sur ces clusters de calcul.
Snowflake s'est ensuite étendu en introduisant le partage de données en 2017, puis une marketplace permettant aux clients d'acheter des jeux de données entre eux en 2019.
Sur la même période, Databricks a creusé son sillon dans le ML en lançant son offre managée MLFlow en 2019, suivie du model serving MLFlow en 2020.
Évolution des deux acteurs
Il est intéressant d'observer comment chaque entreprise a réagi aux attentes du marché en lançant des fonctionnalités concurrentes.
Snowflake a développé Snowpark, initialement pensé pour migrer des workloads Spark, avant d'évoluer en plateforme dédiée aux workloads ML en Python. L'entreprise a aussi beaucoup investi dans la prise en charge d'Apache Iceberg, afin que ses clients puissent gérer et exploiter leurs data lakes directement depuis Snowflake.
De son côté, Databricks a lancé des fonctionnalités comme Photon et Databricks SQL, étendant son emprise dans le data warehousing.
C'est particulièrement frappant aujourd'hui lorsqu'on compare les interfaces de création d'un virtual warehouse dans Snowflake et d'un SQL warehouse dans Databricks. On constate que Databricks a quasiment recopié le design et les réglages des virtual warehouses de Snowflake :

Même si cela n'apparaît pas dans la frise ci-dessus, les deux entreprises ont multiplié les annonces liées à l'IA et aux LLM fin 2023 et début 2024. Le terrain est encore neuf, mais les deux acteurs y ont réalisé d'importantes acquisitions et investissent massivement.
Avantages et différenciateurs clés de chaque plateforme
Comprendre comment chaque entreprise a démarré est essentiel : cela éclaire les forces et faiblesses relatives de chaque plateforme.
Grâce à ses origines dans le data warehousing, Snowflake propose un produit d'entrepôt de données SQL nettement plus solide et complet. Pour la plupart des entreprises, c'est la fonctionnalité la plus importante et la plus utilisée : l'essentiel de la valeur générée par une stratégie data provient d'un entrepôt bien géré, capable de servir les cas d'usage cœur de la business intelligence.
Très peu d'entreprises avec lesquelles j'échange utilisent Databricks comme data warehouse. Elles s'appuient plutôt sur Databricks pour ses puissants notebooks Python et son excellent support des workloads de data science. Pour les organisations dont les data engineers, très techniques, préfèrent travailler avec Apache Spark et Python, Databricks est souvent privilégié pour les transformations de données. L'un des atouts de Databricks pour l'ETL tient à la flexibilité et à la personnalisation offertes par Spark. Pour des workloads analytiques qui traitent de très gros volumes, Spark peut s'avérer préférable : on dispose de davantage de paramètres à ajuster pour faire tourner le job à moindre coût. D'expérience, cela n'a généralement de sens que pour des workloads coûtant plusieurs dizaines de milliers de dollars par an : les coûts humains liés à la maintenance et au développement de ces pipelines dépassent souvent les économies réalisées côté compute.
Du côté des feuilles de route et de l'évolution produit, l'un des principaux différenciateurs de Snowflake est son orientation plateforme. Fin 2023, Snowflake a lancé Snowpark Container Services, qui permet d'exécuter des applications conteneurisées dans Snowflake. Combiné à sa marketplace d'applications natives, on voit clairement que Snowflake construit un avenir où clients et partenaires pourront exécuter tout type d'application data directement dans Snowflake.
Databricks, lui, semble adopter une approche où le client bénéficie d'une solution managée prête à l'emploi pour chaque cas d'usage. Deux exemples parlants : ses fonctionnalités de dashboard et son data catalog. Avec Snowflake, la plupart des clients achètent un outil de BI ou de dashboarding externe qui vient se brancher sur Snowflake. De même, ils acquièrent un produit de data catalog distinct pour gérer et suivre l'ensemble de leurs jeux de données. Databricks cherche clairement à supprimer ce recours aux outils tiers. L'entreprise a racheté Redash en 2020 et en a fait une offre de dashboard solide et prête à l'emploi. Elle investit également massivement dans son Unity Catalog, qui vise à remplacer les fournisseurs de data catalog tiers.
Comparatif des cas d'usage et des fonctionnalités clés
Pendant le webinaire, nous avons passé en revue les principaux cas d'usage d'une plateforme data cloud, puis listé les fonctionnalités de Databricks et Snowflake pour chacun. Les cas d'usage abordés :
- Ingestion de données
- Transformations de données
- Analyse et reporting
- ML/IA
- Applications data
- Marketplace
- Gouvernance et gestion des données
Entrons dans le détail de chacun.
Ingestion de données
Pour interagir avec des données, il faut d'abord les charger ou les exposer au système sous-jacent. Côté Snowflake, cela passe généralement par une commande COPY INTO pour charger les données dans une table que vous pourrez ensuite interroger. Snowflake propose aussi des fonctionnalités comme Snowpipe pour automatiser ce chargement.
La plupart des clients Snowflake utilisent par ailleurs une solution tierce comme Fivetran, Stitch ou Airbyte pour charger des données depuis diverses sources (bases applicatives, API externes, etc.) vers Snowflake.
Avec Databricks, la plupart des clients interagissent directement avec les données dans le stockage cloud. Cela dit, les managed Volumes constituent un concept proche des tables Snowflake : Databricks gère la table pour vous.
Avec les investissements de Snowflake autour d'Apache Iceberg, de plus en plus de clients laisseront leurs données directement dans le stockage cloud et y interagiront, à la manière du modèle Databricks.
| Snowflake | Databricks |
|---|---|
| COPY INTO traditionnel | Autoloader |
| Snowpipe | Intégrations natives (ex. S3) |
| Connecteurs first party | Volumes |
| Solutions tierces (Fivetran/Stitch/Airbyte) | DBFS |
| Aucune ingestion requise avec Iceberg |
Transformations de données
Une fois vos données exposées à la plateforme cloud, vous souhaitez souvent les transformer ou les enrichir. Les deux plateformes offrent plusieurs solutions pour cela.
Snowflake étant un entrepôt de données SQL, la plupart des clients réalisent leurs transformations en pur SQL, en combinant tasks, stored procedures ou des outils tiers de transformation et d'orchestration comme dbt. Tous les workloads SQL s'exécutent dans les virtual warehouses de Snowflake.
Côté Databricks, la majorité des clients utilisent les Jobs, qui permettent de soumettre un job Spark à un cluster s'exécutant sur des instances compute dans votre cloud. Avec les récents investissements de Databricks dans son produit serverless SQL warehousing, il devient de plus en plus courant de voir des transformations en pur SQL avec des outils comme dbt.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Graphiques de notebook |
| Streamlit | Visualisations SQL |
| Connecteurs first party | Volumes |
| Solutions tierces (Tableau, Looker, PowerBI, etc.) | Dashboards |
| Solutions tierces (Tableau, Looker, PowerBI, etc.) |
Analyse et reporting
Databricks et Snowflake proposent à leurs clients de nombreuses fonctionnalités d'analyse et de reporting. Snowflake permet de créer des dashboards légers directement dans Snowsight, ou de construire des applications data sur mesure avec Streamlit.
Databricks propose un produit de dashboarding très abouti, que certaines entreprises utilisent en remplacement d'un outil de BI tiers.
| Snowflake | Databricks |
|---|---|
| Snowsight Dashboards | Graphiques de notebook |
| Streamlit | Visualisations SQL |
| Connecteurs first party | Volumes |
| Solutions tierces (Tableau, Looker, PowerBI, etc.) | Dashboards |
| Solutions tierces (Tableau, Looker, PowerBI, etc.) |
ML/IA
Comme évoqué plus haut, les deux entreprises investissent massivement dans le ML et l'IA. Du fait de son antériorité sur ce terrain, Databricks dispose de fonctionnalités plus matures, comme MLflow managé et le Model Serving.
Avec le lancement de Snowpark Container Services, je m'attends à ce que de nombreux clients Snowflake puissent rapidement héberger des modèles ML directement dans Snowflake.
| Snowflake | Databricks |
|---|---|
| Snowpark | MLflow |
| Snowpark Container Services | Model Serving |
| Snowflake Cortex | Support Python solide |
Applications data
Un angle intéressant pour comparer Snowflake et Databricks concerne la construction d'applications data. Le terme est volontairement large et sujet à interprétation : je définirai donc une application data comme un produit ou une fonctionnalité qui sert des données ou des insights en direct à des utilisateurs externes à l'entreprise. Autrement dit, ce n'est pas une application à usage interne.
Grâce à son entrepôt SQL haute performance, de nombreuses entreprises (comme SELECT) construisent leurs applications directement sur Snowflake et servent les requêtes applicatives depuis les virtual warehouses Snowflake. D'autres exemples sont visibles dans le programme Powered By de Snowflake. Avec les nouvelles fonctionnalités comme Container Services, il sera possible d'héberger des applications web complètes directement dans Snowflake.
Côté Databricks, le principal cas d'usage d'applications data externes repose sur les fonctionnalités de model serving, même si un service de requêtes SQL équivalent devrait bientôt voir le jour grâce aux investissements réalisés dans les produits de data warehousing.
| Snowflake | Databricks |
|---|---|
| Servir des applications depuis Snowflake | Model serving |
| Unistore (HTAP) - tables hybrides | Déclenchement de Jobs à la volée |
| Data Sharing | Serverless SQL |
| Container Services |
Marketplace
En tant que client, vous souhaitez souvent acheter des applications ou des jeux de données supplémentaires à utiliser sur votre plateforme data cloud. Snowflake se détache nettement ici, avec une marketplace très mature regroupant à la fois des jeux de données et des applications natives, exécutables directement dans votre compte Snowflake.
| Snowflake | Databricks |
|---|---|
| Marketplace très mature | Marketplace très mature |
| Native Apps | Partenaires technologiques |
| Cost Management Suite | Bien moins mature, moins prioritaire |
| Forte priorité aux partenaires |
Gouvernance et gestion des données
Sur le volet gouvernance et gestion, les deux plateformes proposent des fonctionnalités prêtes à l'emploi.
Snowflake met gratuitement à disposition de tous ses clients des centaines de jeux de métadonnées via la base account usage. La plateforme dispose d'une suite de cost management très avancée, avec des fonctionnalités puissantes comme les budgets et les resource monitors. Snowflake a récemment annoncé Snowflake Horizon, un ensemble de nouvelles capacités pour gouverner vos assets data et vos utilisateurs.
Databricks propose une offre de data catalog très solide avec Unity Catalog, qui aide les clients à gérer et à comprendre l'ensemble des données de leur environnement. En revanche, Databricks accuse un retard important sur la gestion des coûts : ces données ne sont accessibles que depuis peu via les system tables (leur équivalent des vues account usage de Snowflake).
| Snowflake | Databricks |
|---|---|
| Centaines de jeux de métadonnées (account usage / information schema) | Unity Catalog |
| Snowflake Horizon | System tables |
| Cost Management Suite | Métriques compute |
| Métriques compute |
Tarification et coûts
Databricks et Snowflake proposent tous deux une tarification à l'usage : vous ne payez que ce que vous consommez. Pour en savoir plus sur le modèle tarifaire de Snowflake, lisez notre article ici. Les informations tarifaires de Databricks sont disponibles sur leur site. Un point essentiel à retenir : la tarification Databricks comporte deux types de frais :
- Les frais de plateforme/overhead facturés par Databricks
- Les coûts cloud sous-jacents AWS/Azure/GCP, correspondant aux serveurs que Databricks provisionne dans ces comptes
Comme pour toute plateforme cloud facturée à l'usage, les coûts peuvent vite s'envoler s'ils ne sont pas correctement pilotés et surveillés.
Databricks est-il moins cher que Snowflake ?
La question revient souvent. Elle est en partie alimentée par un effort marketing soutenu de Databricks, illustré ci-dessous depuis leur site :
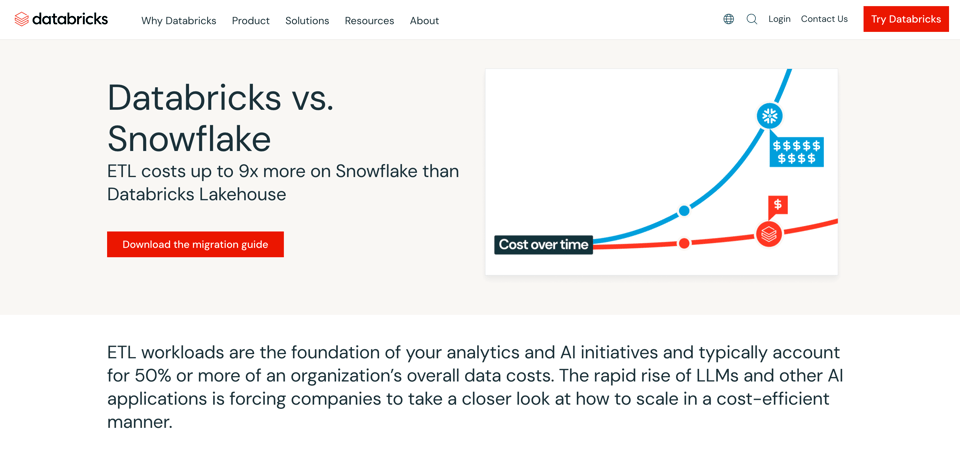
Pour évaluer le coût d'un processus ou d'une application data, deux facteurs essentiels sont à prendre en compte :
- Les coûts de plateforme. L'argent versé à Databricks/Snowflake/votre fournisseur cloud.
- Les coûts humains. Les salaires versés à vos équipes pour construire et maintenir les applications et processus qu'elles créent.
Databricks affirme que les workloads ETL coûtent bien moins cher à exécuter que sur Snowflake. Cet argument s'appuie sur le fait que les jobs Spark se prêtent à un tuning poussé. Il existe une multitude de paramètres sur lesquels les ingénieurs peuvent passer des jours, voire des semaines, à expérimenter.
Ce que beaucoup, y compris le marketing de Databricks, oublient de mentionner dans ces comparaisons, ce sont les coûts humains associés à ce travail. Dans certains cas, il peut être justifié de mobiliser des ingénieurs pour optimiser et tuner un job ; mais pour la majorité des workloads ETL, ces coûts humains supplémentaires font souvent grimper le coût total.
Quand vous arbitrez ou comparez le coût de chaque plateforme, pensez bien au coût total de possession, en intégrant à la fois (a) le fournisseur de la plateforme et (b) les personnes qui réalisent le travail.
Parts de marché
Databricks étant une entreprise privée, elle ne communique pas le nombre exact de ses clients ni sa pénétration sur chaque marché.
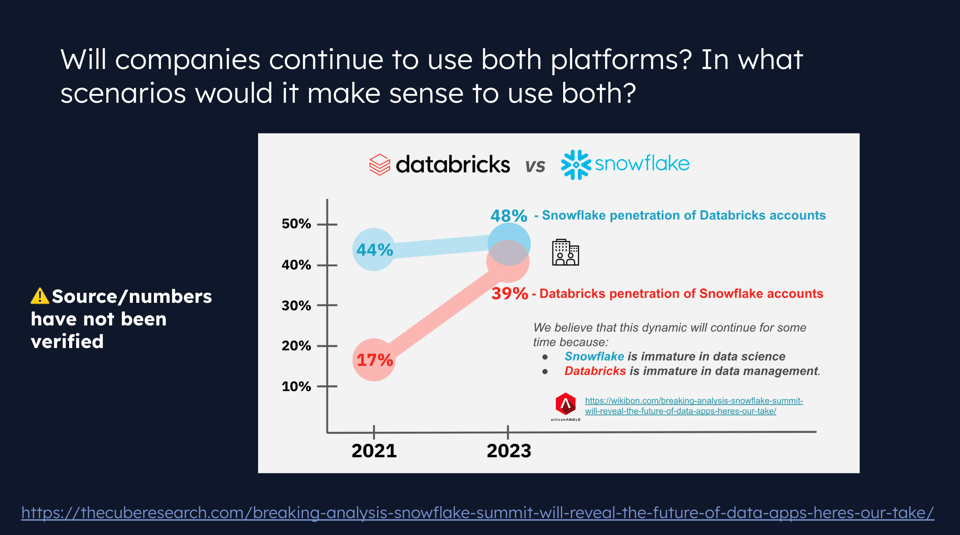
Pendant le webinaire, nous avons notamment évoqué le nombre de clients qui utilisent les deux plateformes. Les statistiques de la diapositive ci-dessous ne sont pas vérifiées, mais elles montrent un recouvrement croissant entre les deux.
Jeff et moi pensons tous deux que ce recouvrement s'explique par les orientations historiquement différentes de chaque plateforme, qui se sont depuis rapprochées.
Ian Whitestone · Cofondateur et CEO de SELECT
Ian est cofondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant SELECT, Ian a passé 6 ans à diriger des équipes full stack de data science et d'engineering chez Shopify et Capital One. Chez Shopify, Ian a piloté les chantiers d'optimisation du data warehouse et de renforcement de l'observabilité des coûts.