Los stored procedures han sido un pilar de los RDBMS durante años, mucho antes de la era de la nube y de las herramientas de transformación dedicadas. Han cumplido un papel clave en la construcción de pipelines de datos y en la automatización de bases de datos. En este post vamos a ver qué son los stored procedures y cómo aprovechar su potencial en plataformas modernas basadas en la nube como Snowflake.
¿Qué son los Stored Procedures?
Los stored procedures extienden el lenguaje SQL con lógica procedural, lo que permite usar sentencias condicionales, bucles y crear funcionalidades que de otra forma serían imposibles sin estas construcciones.
Diferencia entre UDFs y Stored Procedures
Además de los stored procedures, puedes crear funciones definidas por el usuario (UDFs). Entender la diferencia entre ambos es clave a la hora de decidir cuándo usar UDFs y cuándo optar por stored procedures (SP).
Los stored procedures suelen usarse para acciones administrativas en Snowflake, como limpiar datos antiguos, eliminar tablas en desuso o hacer backups personalizados. Las UDFs, en cambio, entran en juego cuando necesitas calcular y devolver un valor como parte de una consulta SQL SELECT, por ejemplo los ingresos de un ejecutivo de ventas o los bonos de los empleados.
Los stored procedures se invocan con la palabra clave CALL como una sentencia independiente:
1CALL my_stored_procedure(input_param);
Las UDFs, en cambio, se llaman como parte de una sentencia SELECT:
1SELECT column1, my_udf(input_parameter) FROM table1;
Otra diferencia está en el valor de retorno: los stored procedures pueden no devolver nada y limitarse a ejecutar una tarea. Las UDFs, por el contrario, siempre deben devolver un valor.
Veamos algunos casos de uso típicos y determinemos cuándo conviene un stored procedure y cuándo una UDF:
| Caso de uso | ¿UDF o Stored Procedure? |
| Crear un nuevo usuario y un warehouse dedicado | Stored Procedure |
| Eliminar todas las tablas temporales | Stored Procedure |
| Limpiar tablas sin uso | Stored Procedure |
| Determinar la ciudad a partir de una dirección IP | UDF |
| Extraer el tipo de navegador desde una cadena user agent | UDF |
| Calcular descuentos para órdenes | UDF |
| Cargar una tabla desde un stage | Stored Procedure |
Lenguajes de programación soportados
Snowflake soporta varios lenguajes para desarrollar stored procedures. La elección del más adecuado depende de varios factores:
- Preferencia y conocimiento personal del lenguaje
- Disponibilidad de las librerías necesarias
- Consistencia con el código existente en los lenguajes soportados
- Si prefieres mantener el código in-line o de forma externa (como un archivo independiente en un stage)
Aquí tienes un resumen de los lenguajes disponibles, junto con información sobre si admiten manejo in-line o en stage:
| Lenguaje | Ubicación del handler |
|---|---|
| Java | In-line o en stage |
| JavaScript | In-line |
| Scala | In-line o en stage |
| Snowflake SQL Scripting | In-line |
Tanto la opción in-line como la opción en stage tienen sus pros y sus contras. El desarrollo in-line puede resultar más simple, ya que te permite afinar el código y agregarlo directamente a la definición del SP. El manejo en stage resulta conveniente para código compilado (Java, Scala), pues permite reutilizar código ya compilado dentro de los stored procedures de Snowflake.
Cómo crear un Stored Procedure
Con Snowflake SQL Scripting
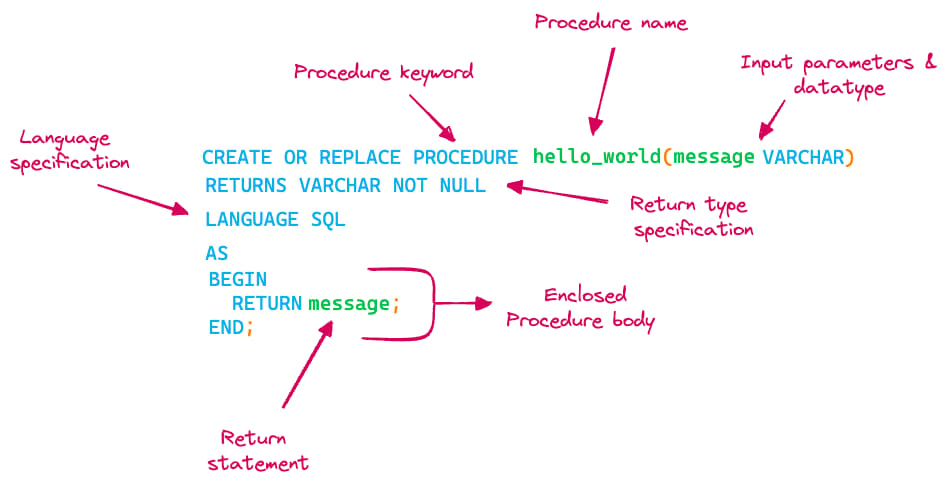
Veamos en detalle la sintaxis para crear stored procedures (SP) con el lenguaje Snowflake SQL Scripting y descifremos el significado de las distintas palabras clave. Como se muestra en la imagen, un stored procedure se compone de lo siguiente:
- Nombre del stored procedure
- Parámetros de entrada (argumentos) junto con sus tipos de datos
- Tipo de retorno de la salida del stored procedure
- Especificación del lenguaje
- Cuerpo del stored procedure, donde vivirá la lógica
El stored procedure hello_world de arriba simplemente devuelve el mensaje que se le pasa como argumento. Al llamarlo, se ve la salida impresa:

Con JavaScript
Modifiquemos el ejemplo hello_world y creémoslo en JavaScript. Aquí está el código del mismo procedimiento, pero ahora en JavaScript:
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Definimos JavaScript como el lenguaje y usamos otros caracteres para encerrar el cuerpo del procedimiento ($$).
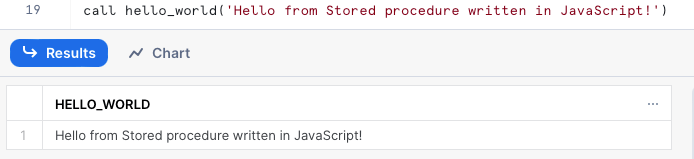
La llamada al procedimiento es igual:
Con Python
En este último ejemplo vamos a crear el mismo procedimiento hello_world en Python:
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
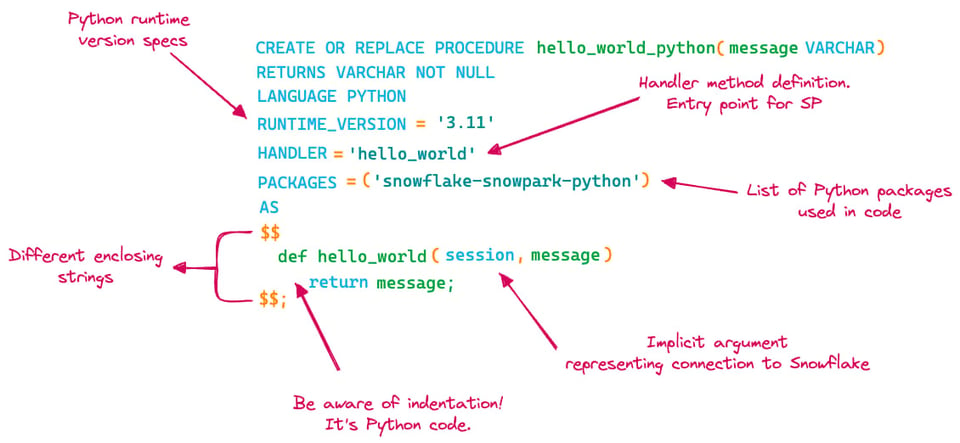
Se notan varios cambios respecto a SQL Scripting o JavaScript. Actualicemos el diagrama y destaquemos las diferencias:
- En Python hay que especificar la versión que se va a usar
- Hay que definir un
handler, que es la función de Python que se ejecutará en el stored procedure - Hay que especificar los paquetes de Python que utilizaremos en el stored procedure
La llamada al stored procedure de Python es igual que en cualquier otro lenguaje:

Llamar (ejecutar) Stored Procedures
A continuación, veamos cómo se ejecuta (o "llama") un stored procedure, sobre todo cuando recibe argumentos.
Usar argumentos en Stored Procedures
Los stored procedures permiten definir argumentos que puedes pasar desde fuera. En nuestro ejemplo hello_world usamos el argumento llamado message. También puedes ver cómo se especifica el valor al llamar al stored procedure.
Los argumentos pueden ser opcionales si tienen un valor por defecto definido en el SP. En ese caso, puedes omitirlos al llamar al SP y se usará el valor por defecto. Modifiquemos nuestro ejemplo para usar un argumento opcional.
create or replace procedure hello_world(message varchar DEFAULT 'Hello from Stored procedure written in SQL scripting!')
returns varchar not null
language sql
as
begin
return message;
end;
Trabajar con argumentos opcionales y obligatorios
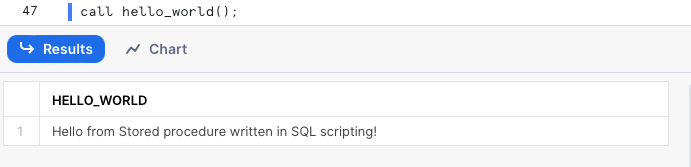
Si tienes argumentos opcionales y obligatorios al mismo tiempo, debes especificar primero los obligatorios. Ahora podemos llamar al procedimiento sin el valor del argumento y Snowflake usará el valor por defecto.
Por supuesto, también podemos sobrescribir el valor por defecto y pasar uno nuevo al llamar al procedimiento:
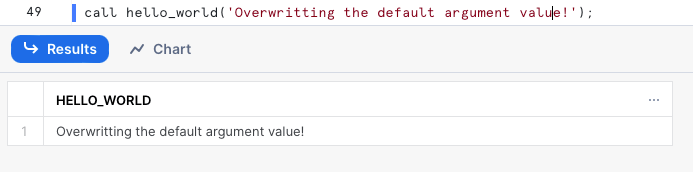
¿Cómo usar variables bind en una sentencia SQL?
Los argumentos también se usan a menudo para pasar valores a consultas SQL como variables bind dentro de los stored procedures. Esto permite construir la consulta SQL de forma dinámica a partir de los argumentos. Algunos ejemplos: pasar una fecha, el identificador de un cliente o el nombre de una tabla que se debe limpiar. Veamos un ejemplo simple en el que vamos a construir dinámicamente una sentencia SELECT y devolver los valores de una tabla para un id dado:
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Expandir código
El código del stored procedure introduce dos conceptos nuevos. El primero es cómo enlazar los argumentos de entrada con las sentencias SQL. Aquí usamos el carácter de dos puntos antes del nombre del argumento: :id. El código también declara una variable de salida y pasa el resultado de la sentencia SELECT a esa variable como parte del código SQL. Esto se hace con la sintaxis :into <variable_name>.
Privilegios y tipos de ejecución
Los stored procedures son objetos de base de datos, igual que las tablas o las vistas. Esto significa que pertenecen a un rol. Además del privilegio OWNERSHIP, también existe el privilegio USAGE sobre el SP, que se puede otorgar a otros roles. Hay otro tema relacionado con los privilegios y la ejecución de stored procedures: Snowflake soporta dos modos diferentes de interactuar con ellos. Puedes usar Caller’s Rights o Owner’s Rights. Al crear un procedimiento, defines si quieres usar los derechos del llamador o los del propietario. La opción por defecto es la de los derechos del propietario. Veamos ambos modos en detalle.
Caller’s Rights
Cuando se ejecuta un SP con caller’s rights, el SP utiliza los privilegios de quien lo llama. El procedimiento también tiene acceso a la información de la sesión del llamador: puede leer variables de sesión y usarlas en consultas o modificarlas. Esos cambios de sesión persisten una vez terminada la llamada al SP. El SP usa los privilegios de base de datos del llamador, por lo que puede acceder a los mismos objetos de BD que él. Si el SP contiene alguna sentencia u objeto de BD para el que el llamador no tiene permisos, se lanzará un error de permisos.
Owner’s Rights
En este caso, el procedimiento se ejecuta con los derechos del propietario y queda desacoplado del llamador. Esto significa que el SP puede hacer cosas que el llamador no podría hacer directamente. Es un buen ejemplo de cómo delegar tareas en otros roles sin tener que otorgarles los privilegios para hacerlas. Puedes crear un SP que elimine datos antiguos de tablas y permitir su uso a otros usuarios sin darles el privilegio DELETE sobre esas tablas. El procedimiento que se ejecuta con owner’s rights no tiene acceso a la información de sesión del llamador ni puede modificarla. Tampoco tiene acceso a variables creadas fuera del SP; si lo necesitas, debes pasar el valor como argumento de entrada.
¿Qué modo conviene usar?
Depende de cada caso. Si quieres delegar algo a otros usuarios, usa owner’s rights. Usa el mismo modo si no impide que el SP funcione correctamente o si no quieres exponer el código del procedimiento a los llamadores. Por otro lado, conviene usar caller’s rights cuando necesitas acceso a la información de la sesión actual o cuando el procedimiento solo usa objetos de los que el llamador es propietario o que puede utilizar. Resumamos ambas opciones en una tabla:
| Caller’s Rights | Owner’s Rights |
|---|---|
| Se ejecuta con los privilegios del llamador | Se ejecuta con los privilegios del propietario del SP |
| Tiene acceso a la sesión actual del llamador | Acceso limitado a la sesión del llamador |
| Los cambios en la sesión persisten tras la llamada al SP | No puede cambiar el estado de la sesión |
| Puede ver, establecer y eliminar variables y parámetros de sesión del llamador | No puede ver, establecer ni eliminar variables ni parámetros de sesión del llamador |
| Solo puede usar los objetos y operaciones que el llamador tiene permitidos | Desacoplado de los privilegios del llamador |
Tipos de retorno
Los procedimientos pueden devolver un valor (número, string, boolean). También es muy común que un SP no devuelva nada, ya que puede limitarse a ejecutar código sin necesidad de retornar algo.
Un tipo de retorno especial de los SP es una tabla. Veamos algunos ejemplos sobre cómo escribir un procedimiento sin valor de retorno y un procedimiento que devuelve una tabla.
create or replace procedure no_return_value()
returns varchar null
language sql
as
begin
select 1;
select 2;
select 3;
select 4;
end;
Si revisas la sentencia CREATE PROCEDURE en la documentación, verás que la palabra clave RETURNS es obligatoria. Para definir un stored procedure sin valor de retorno, debes definir algún tipo de retorno y omitir la palabra clave return en el bloque de código del SP. No es necesario definir el tipo de retorno específicamente con la cláusula NULL; el código funcionaría igual sin ella, por ejemplo, RETURNS VARCHAR.
Cuando llamas a un procedimiento así, obtendrás un valor nulo como salida:

Para devolver una tabla, debes especificar el tipo de retorno como tabla. Si conoces los tipos de datos de las columnas devueltas, puedes indicarlos desde el inicio junto con los nombres de las columnas. De lo contrario, puedes hacerlo en tiempo de ejecución.
Para devolver una tabla, debemos introducir un tipo de dato más, llamado RESULTSET. Este tipo de dato puede contener el resultado de una consulta SQL. Si necesitas procesarlo después, puedes iterar sobre las filas o simplemente devolver el resultado, como haremos en este ejemplo:
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
En este ejemplo asignamos un valor por defecto a la variable result y luego la retornamos dentro de la función table(). Cuando llames a este SP, obtendrás como salida una tabla con dos columnas:
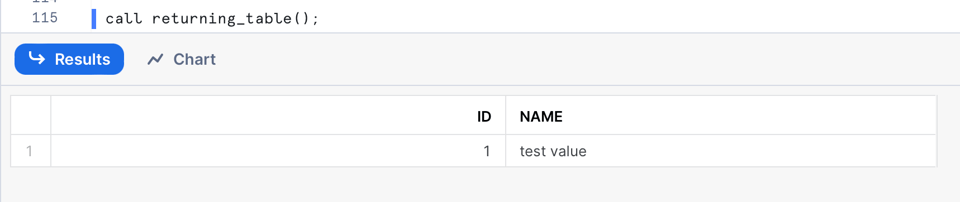
Ejecutar múltiples sentencias SQL recorriendo resultados
Ya recorrimos los conceptos básicos sobre cómo escribir stored procedures en Snowflake. Ahora intentemos juntar todos esos conceptos y crear casos de uso reales que muestren cómo aplicar los stored procedures a tareas concretas. Una tarea administrativa común podría ser ejecutar múltiples sentencias SQL creadas dinámicamente a partir de los resultados de otra consulta. Por ejemplo, quizás quieras limpiar todas las tablas vacías. Primero tienes que encontrar todas las tablas con 0 registros y luego recorrerlas y eliminarlas. Puedes resolverlo con el siguiente stored procedure:
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Repasemos el código para explicar la lógica.
- Pasamos el nombre de la base de datos como parámetro para limpiar tablas y vistas solo en la BD indicada.
- Declaramos una variable
RESULTSETtable_listque contiene los nombres de las tablas vacías como resultado de la consulta. - También definimos un cursor para iterar sobre los resultados y una variable para la sentencia
DROPque iremos creando y ejecutando dinámicamente dentro del bucle. - El cuerpo del procedimiento recorre el resultado de la consulta fila por fila y construye una sentencia drop a partir de los valores obtenidos del cursor. Incluimos tanto vistas como tablas, pero si quieres limpiar solo tablas, debes modificar la consulta de entrada.
- Una vez creada la sentencia drop, la ejecutamos con
EXECUTE IMMEDIATE.
Cuando llames al stored procedure, debería devolver el mensaje 'cleaning done'. Puedes encontrar las tablas/vistas eliminadas en el query history, o modificar el mensaje de retorno para devolver también los nombres de los objetos eliminados.

Documentar Stored Procedures
Un stored procedure es un fragmento de código y, como tal, debe estar bien comentado para facilitar su mantenimiento y uso a futuro. Existen varias formas de hacerlo. Puedes apoyarte en una herramienta externa, como un data catalog o un wiki interno, y describir allí el stored procedure. Conviene enfocarse siempre en dos aspectos:
- Documentación para usuarios y llamadores
- Documentación para programadores
Estos son algunos ejemplos de lo que debería incluirse en la documentación:
- Describir la lógica del stored procedure y su propósito
- Describir a los autores
- Describir la ubicación: base de datos y schema
- Describir los parámetros de entrada: nombres, tipos de datos y significado
- Describir los valores de retorno, posibles errores y excepciones
- Describir los prerrequisitos
- Cuáles son los privilegios necesarios
Puedes agregar comentarios directamente en el código fuente y describir el algoritmo. Una última recomendación de mi parte: mantén el código fuente de los stored procedures bajo control de versiones (GIT). Recuerda que los stored procedures no forman parte de Time Travel en Snowflake, por lo que no puedes obtener una versión anterior del código directamente desde Snowflake.
Ejemplos de Stored Procedures
Resumamos como referencia rápida todos los ejemplos de stored procedures que mostramos en este post:
Hello World
SQL Scripting
create or replace procedure hello_world(message varchar)
returns varchar not null
language sql
AS
begin
return message;
end;
Javascript
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Python
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
Generar dinámicamente una consulta SQL a partir de argumentos
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Expandir código
Devolver una tabla a partir de una consulta SQL
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
Ejecutar múltiples sentencias SQL
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Enviar alertas para tareas suspendidas
Aquí tienes un ejemplo de un post anterior del blog. Este stored procedure, llamado task_state_monitor, recibe un task_name como parámetro y verifica el estado de la task. Si el estado es 'suspended', envía una alerta por correo y devuelve un mensaje. En caso contrario, devuelve un mensaje indicando que el estado de la task es correcto.
create or replace procedure task_state_monitor(task_name string)
returns varchar not null
language SQL
AS
$$
DECLARE
task_state string;
c CURSOR FOR SELECT "state" from table(result_scan(last_query_id())) where "name" = ?;
BEGIN
show tasks;
open c USING (task_name);
fetch c into task_state;
IF(task_state = 'suspended') THEN
CALL SYSTEM$SEND_EMAIL(
'my_email_int',
Expandir código
Tomáš Sobotík·Senior Data Engineer & Snowflake SME en Norlys
Tomas es un Snowflake Data SuperHero de larga trayectoria y un experto en Snowflake en general. Su amplia experiencia en el mundo de los datos abarca más de una década, durante la cual se ha desempeñado como data engineer, arquitecto y administrador de Snowflake en proyectos de distintas industrias y tecnologías. Tomas es un miembro activo de la comunidad, donde comparte su experiencia e inspira a otros. También es instructor de O'Reilly y dicta sesiones de capacitación en vivo en línea.