Le stored procedure sono da sempre un pilastro degli RDBMS, ben prima dell'era del cloud e degli strumenti di trasformazione dedicati. Hanno avuto un ruolo cruciale nella costruzione delle pipeline di dati e nell'automazione dei database. In questo articolo vediamo cosa sono le stored procedure e come sfruttarne il potenziale su piattaforme cloud moderne come Snowflake.
Cosa sono le stored procedure?
Le stored procedure estendono il linguaggio SQL con una logica procedurale, consentendo di usare istruzioni condizionali, cicli e di realizzare funzionalità altrimenti impossibili senza questi costrutti.
Differenza tra UDF e stored procedure
Oltre alle stored procedure, è possibile creare funzioni definite dall'utente (UDF). Capire la differenza è fondamentale per decidere quando usare le UDF e quando invece affidarsi alle stored procedure (SP).
Le stored procedure si usano in genere per le attività amministrative in Snowflake: pulizia di dati obsoleti, eliminazione di tabelle inutilizzate o backup personalizzato dei dati. Le UDF, invece, entrano in gioco quando bisogna calcolare e restituire un valore all'interno di una query SQL SELECT, come il fatturato di un determinato responsabile commerciale o i bonus dei dipendenti.
Per richiamare le stored procedure si usa la parola chiave CALL come istruzione indipendente:
1CALL my_stored_procedure(input_param);
Le UDF, al contrario, si richiamano all'interno di un'istruzione SELECT:
1SELECT column1, my_udf(input_parameter) FROM table1;
Un'altra differenza riguarda il valore restituito: le stored procedure possono non restituire nulla e limitarsi a eseguire un'operazione, mentre le UDF devono sempre restituire un valore.
Vediamo alcuni casi d'uso tipici per capire se sia più adatta una stored procedure o una UDF:
| Caso d'uso | UDF o stored procedure? |
| Creare un nuovo utente e un warehouse dedicato | Stored procedure |
| Eliminare tutte le tabelle temporanee | Stored procedure |
| Pulire le tabelle inutilizzate | Stored procedure |
| Determinare la città a partire da un indirizzo IP | UDF |
| Estrarre il tipo di browser da una stringa user agent | UDF |
| Calcolare gli sconti sugli ordini | UDF |
| Caricare una tabella da uno stage | Stored procedure |
Linguaggi di programmazione supportati
Snowflake supporta diversi linguaggi per sviluppare stored procedure. La scelta del più adatto dipende da vari fattori:
- Preferenze e competenze personali sul linguaggio
- Disponibilità delle librerie necessarie
- Coerenza con il codice già esistente nei linguaggi supportati
- Se si vuole mantenere il codice in-line oppure esterno (come file autonomo in uno stage)
Ecco una panoramica dei linguaggi disponibili, con l'indicazione del supporto per la modalità in-line o staged:
| Linguaggio | Posizione dell'handler |
|---|---|
| Java | In-line o staged |
| JavaScript | In-line |
| Scala | In-line o staged |
| Snowflake SQL Scripting | In-line |
Sia l'opzione in-line sia quella staged hanno pro e contro. Lo sviluppo in-line è generalmente più semplice: si può rifinire il codice e inserirlo direttamente nella definizione della SP. La modalità staged è invece vantaggiosa per il codice compilato (Java, Scala), perché permette di riutilizzare nelle stored procedure di Snowflake codice già compilato.
Come creare una stored procedure
Con Snowflake SQL Scripting
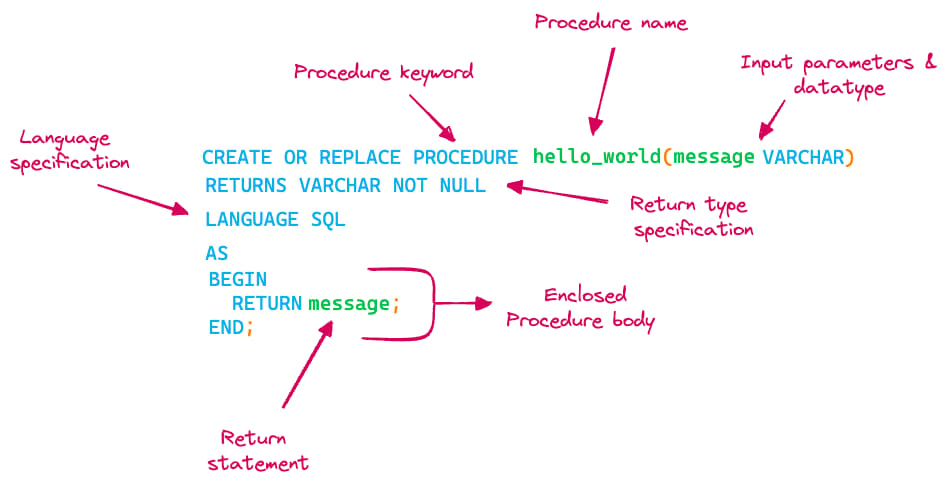
Analizziamo la sintassi per creare una stored procedure (SP) con il linguaggio Snowflake SQL Scripting e vediamo il significato delle varie parole chiave. Come mostra l'immagine, una stored procedure è composta dai seguenti elementi:
- Nome della stored procedure
- Parametri di input (argomenti) con i relativi tipi di dato
- Tipo di dato restituito in output
- Specifica del linguaggio
- Corpo della stored procedure, dove risiede la logica vera e propria
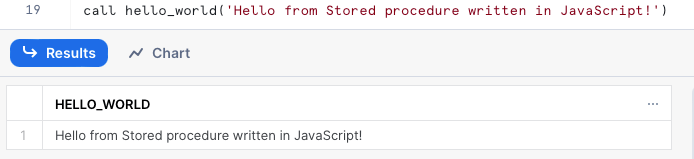
La stored procedure hello_world qui sopra restituisce semplicemente il messaggio passato come argomento. Richiamandola vediamo l'output stampato:

Con JavaScript
Modifichiamo l'esempio hello_world e riscriviamolo in JavaScript. Ecco il codice della stessa procedura, questa volta in JavaScript:
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Abbiamo indicato JavaScript come linguaggio, usando caratteri diversi per delimitare il corpo della procedura ($$).
La chiamata alla procedura resta invariata:
Con Python
In quest'ultimo esempio ricreiamo la stessa procedura hello_world in Python:
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
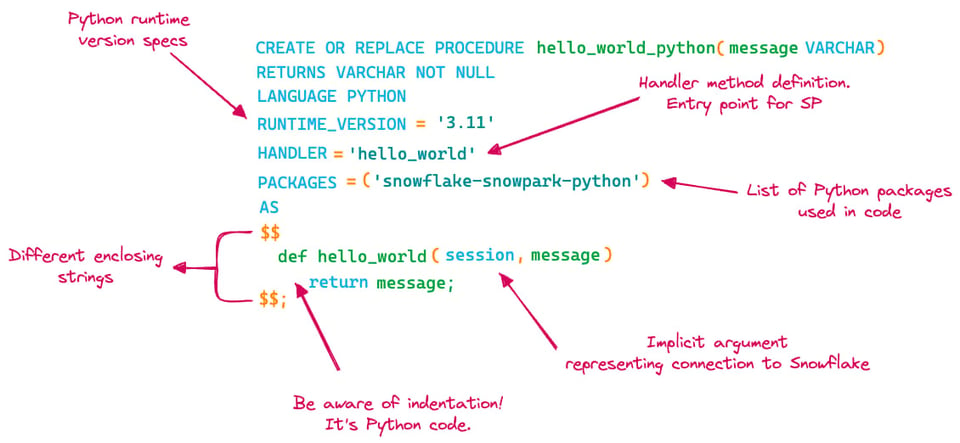
Rispetto a SQL Scripting o JavaScript ci sono diverse novità. Aggiorniamo lo schema e mettiamole in evidenza:
- Per Python bisogna indicare la versione del linguaggio da usare
- Va definito un
handler, cioè la funzione Python che verrà eseguita nella stored procedure - Vanno specificati i pacchetti Python che si intende utilizzare nella stored procedure
La chiamata della stored procedure in Python è identica a quella di qualsiasi altro linguaggio:

Chiamare (eseguire) le stored procedure
Vediamo ora come eseguire (o "chiamare") una stored procedure, in particolare passando degli argomenti.
Usare gli argomenti nelle stored procedure
Le stored procedure permettono di definire argomenti da passare dall'esterno. Nell'esempio hello_world abbiamo usato l'argomento message. Vediamo anche come specificarne il valore al momento della chiamata.
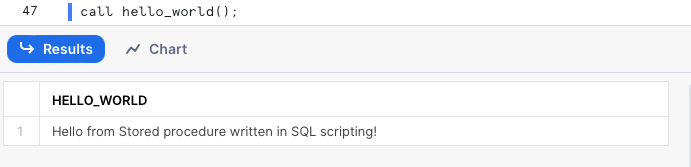
Gli argomenti possono essere opzionali se nella definizione della SP è previsto un valore predefinito. In tal caso si può omettere l'argomento durante la chiamata e Snowflake userà il valore di default. Modifichiamo l'esempio per usare un argomento opzionale.
create or replace procedure hello_world(message varchar DEFAULT 'Hello from Stored procedure written in SQL scripting!')
returns varchar not null
language sql
as
begin
return message;
end;
Gestire argomenti opzionali e obbligatori
Quando ci sono sia argomenti opzionali sia argomenti obbligatori, questi ultimi vanno indicati per primi. A questo punto possiamo richiamare la procedura senza passare il valore dell'argomento e Snowflake userà quello predefinito.
Naturalmente possiamo sovrascrivere il valore di default e passare un nuovo valore al momento della chiamata:
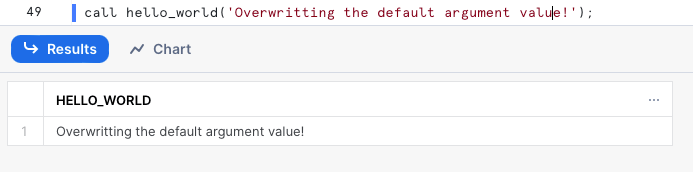
Come usare le bind variable in un'istruzione SQL?
Gli argomenti vengono spesso utilizzati anche per passare valori alle query SQL come bind variable all'interno delle stored procedure. In questo modo la query SQL può essere costruita dinamicamente in base agli argomenti. Esempi tipici sono il passaggio di una data, di un identificativo cliente o del nome di una tabella da svuotare. Creiamo un semplice esempio in cui costruiamo dinamicamente un'istruzione SELECT e restituiamo i valori di una tabella per un dato id:
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Espandi codice
Il codice della stored procedure introduce due nuovi concetti. Il primo riguarda come associare gli argomenti di input alle istruzioni SQL: qui usiamo il carattere due punti prima del nome dell'argomento, :id. Il codice dichiara inoltre una variabile di output e vi assegna il risultato dell'istruzione SELECT direttamente nel codice SQL, tramite la sintassi :into <variable_name>.
Privilegi e modalità di esecuzione
Le stored procedure sono oggetti del database, al pari di tabelle e viste, e quindi appartengono a un ruolo. Oltre al privilegio OWNERSHIP, esiste anche il privilegio USAGE sulla SP, che può essere concesso ad altri ruoli. C'è poi un altro aspetto legato ai privilegi e all'esecuzione delle stored procedure: Snowflake supporta due diverse modalità di interazione, Caller's Rights e Owner's Rights. Quando si crea una procedura si stabilisce quale delle due adottare. L'opzione predefinita è quella dei diritti del proprietario. Vediamo nel dettaglio entrambe le modalità.
Caller's Rights
Quando si esegue una SP con i diritti del chiamante, la procedura usa i privilegi del chiamante stesso. La procedura ha inoltre accesso alle informazioni di sessione del chiamante: può leggere le variabili di sessione, usarle nelle query e modificarle. Tali modifiche di sessione restano valide anche dopo il termine della chiamata alla SP. La SP utilizza i privilegi di database del chiamante e può quindi accedere agli stessi oggetti DB. Se la SP contiene istruzioni o oggetti DB su cui il chiamante non ha i permessi, viene generato un errore di autorizzazione.
Owner's Rights
In questo caso la procedura viene eseguita con i diritti del proprietario ed è disaccoppiata dal chiamante. Ciò significa che la SP può svolgere operazioni che il chiamante non potrebbe fare direttamente. È un ottimo modo per delegare attività ad altri ruoli senza concedere loro i relativi privilegi. Si può, ad esempio, creare una SP per eliminare i dati obsoleti dalle tabelle e renderla disponibile agli utenti, senza assegnare loro il privilegio DELETE su quelle tabelle. La procedura eseguita con i diritti del proprietario non ha accesso alle informazioni di sessione del chiamante e non può modificarle. La SP non accede nemmeno alle variabili create al di fuori di essa: se servono, vanno passate come argomenti di input.
Quale modalità scegliere?
Dipende dalle esigenze. Per delegare attività ad altri utenti conviene usare i diritti del proprietario. La stessa modalità è preferibile quando non compromette il corretto funzionamento della SP o quando non si vuole esporre il codice della procedura ai chiamanti. La modalità con diritti del chiamante è invece da scegliere quando serve accedere alle informazioni della sessione corrente o quando la procedura usa solo oggetti di proprietà del chiamante o a cui questi ha accesso. Riepiloghiamo entrambe le opzioni nella tabella:
| Caller's Rights | Owner's Rights |
|---|---|
| Esegue con i privilegi del chiamante | Esegue con i privilegi del proprietario della SP |
| Ha accesso alla sessione corrente del chiamante | Accesso limitato alla sessione del chiamante |
| Le modifiche alla sessione restano valide dopo la fine della chiamata alla SP | Non può modificare lo stato della sessione |
| Può leggere, impostare e annullare variabili e parametri di sessione del chiamante | Non può leggere, impostare o annullare variabili e parametri di sessione del chiamante |
| Può utilizzare solo gli oggetti e le operazioni accessibili al chiamante | Disaccoppiata dai privilegi del chiamante |
Tipi di ritorno
Le procedure possono restituire un valore (numero, stringa, booleano). È inoltre molto comune che una SP non restituisca nulla, limitandosi a eseguire del codice senza dover fornire un valore di ritorno.
Un tipo di ritorno particolare è la tabella. Vediamo alcuni esempi: una procedura senza valore di ritorno e una che restituisce una tabella.
create or replace procedure no_return_value()
returns varchar null
language sql
as
begin
select 1;
select 2;
select 3;
select 4;
end;
Consultando l'istruzione CREATE PROCEDURE nella documentazione, si scopre che la parola chiave RETURNS è obbligatoria. Per definire una stored procedure senza valore di ritorno occorre comunque indicare un tipo di dato e omettere la parola chiave return nel blocco di codice della SP. Non è strettamente necessario definire il tipo di ritorno con NULL: il codice funzionerebbe anche con RETURNS VARCHAR.
Chiamando una procedura di questo tipo si ottiene un valore null come output:

Per restituire una tabella bisogna indicare come tipo di ritorno proprio una tabella. Se si conoscono i tipi di dato delle colonne restituite si possono specificare subito insieme ai nomi delle colonne; altrimenti, lo si può fare a runtime.
Per restituire una tabella occorre introdurre un altro tipo di dato: RESULTSET. Questo tipo può contenere il risultato di una query SQL. Se serve elaborarlo ulteriormente si può iterare sulle righe, oppure restituire direttamente il risultato come facciamo in questo esempio:
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
In questo esempio assegniamo un valore di default alla variabile result e la restituiamo all'interno della funzione table(). Chiamando questa SP si ottiene come output una tabella con due colonne:
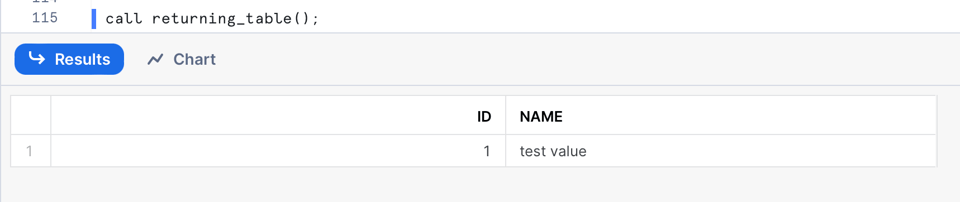
Eseguire più istruzioni SQL iterando sui risultati
Abbiamo visto i concetti di base per scrivere stored procedure in Snowflake. Ora proviamo a mettere insieme tutti questi elementi in casi d'uso reali, per mostrare come utilizzare le stored procedure in attività concrete. Un'attività amministrativa molto comune consiste nell'eseguire più istruzioni SQL costruite dinamicamente in base ai risultati di un'altra query. Ad esempio, può capitare di voler ripulire tutte le tabelle vuote: bisogna prima individuare quelle con 0 record e poi iterare per eliminarle. Si può risolvere con la seguente stored procedure:
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Vediamo la logica del codice nel dettaglio.
- Passiamo il nome del database come parametro, così da ripulire tabelle e viste solo nel DB indicato.
- Dichiariamo una variabile
RESULTSETchiamatatable_list, che contiene i nomi delle tabelle vuote come risultato della query. - Definiamo anche un cursore per iterare sui risultati e una variabile per l'istruzione
DROPche costruiremo ed eseguiremo dinamicamente nel ciclo. - Il corpo della procedura scorre quindi il risultato della query riga per riga e costruisce un'istruzione DROP a partire dai valori del cursore. Abbiamo incluso sia viste sia tabelle: se si vogliono ripulire solo le tabelle, occorre modificare la query di input.
- Una volta creata l'istruzione DROP, la eseguiamo con
EXECUTE IMMEDIATE.
Quando si chiama la stored procedure, questa restituisce il messaggio 'cleaning done'. Le tabelle e le viste eliminate si possono consultare nella query history, oppure si può modificare il messaggio di ritorno per includere anche i nomi degli oggetti eliminati.

Documentare le stored procedure
Una stored procedure è codice e, in quanto tale, va commentata adeguatamente per semplificarne la manutenzione e l'utilizzo futuri. I modi per farlo sono diversi: si può ricorrere a uno strumento esterno come un data catalog o un wiki interno e descrivere lì la stored procedure. È sempre opportuno concentrarsi su due aspetti:
- Documentazione per utenti e chiamanti
- Documentazione per i programmatori
Ecco alcuni esempi di ciò che la documentazione dovrebbe includere:
- Descrizione della logica e degli obiettivi della stored procedure
- Indicazione degli autori
- Indicazione della posizione: database e schema
- Descrizione dei parametri di input: nomi, tipi di dato e significato
- Descrizione dei valori di ritorno, dei possibili errori e delle eccezioni
- Descrizione dei prerequisiti
- Privilegi necessari
I commenti si possono inserire direttamente nel codice sorgente per descrivere l'algoritmo. Un ultimo consiglio è di mantenere il codice sorgente delle stored procedure sotto controllo di versione (GIT). Ricordiamo infatti che le stored procedure non rientrano nel Time Travel di Snowflake: non è possibile recuperare direttamente in Snowflake la versione precedente del codice.
Esempi di stored procedure
Riepiloghiamo, per comodità di riferimento, tutti gli esempi di stored procedure presentati in questo articolo:
Hello World
SQL Scripting
create or replace procedure hello_world(message varchar)
returns varchar not null
language sql
AS
begin
return message;
end;
JavaScript
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Python
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
Generare dinamicamente una query SQL usando argomenti
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Espandi codice
Restituire una tabella da una query SQL
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
Eseguire più istruzioni SQL
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Inviare alert per i task sospesi
Ecco un esempio tratto da un articolo precedente del blog. Questa stored procedure, chiamata task_state_monitor, riceve come parametro un task_name e verifica lo stato del task. Se lo stato è 'suspended', invia un alert via email e restituisce un messaggio. In caso contrario, restituisce un messaggio che indica che lo stato del task è regolare.
create or replace procedure task_state_monitor(task_name string)
returns varchar not null
language SQL
AS
$$
DECLARE
task_state string;
c CURSOR FOR SELECT "state" from table(result_scan(last_query_id())) where "name" = ?;
BEGIN
show tasks;
open c USING (task_name);
fetch c into task_state;
IF(task_state = 'suspended') THEN
CALL SYSTEM$SEND_EMAIL(
'my_email_int',
Espandi codice
Tomáš Sobotík·Senior Data Engineer & Snowflake SME presso Norlys
Tomas è da anni Snowflake Data SuperHero e riconosciuto esperto di Snowflake. Vanta oltre dieci anni di esperienza nel mondo dei dati, durante i quali ha lavorato come data engineer, architect e admin Snowflake in progetti di settori e tecnologie diversi. Tomas è un membro di punta della community, dove condivide attivamente la propria esperienza e ispira gli altri. È inoltre instructor per O'Reilly, dove tiene sessioni di formazione live online.