As stored procedures são um recurso clássico dos RDBMS há muito tempo — bem antes da era da nuvem e das ferramentas dedicadas de transformação. Elas têm papel fundamental na construção de pipelines de dados e na automação de bancos de dados. Neste post, vamos ver o que são as stored procedures e como extrair todo o seu potencial em plataformas modernas baseadas em nuvem, como o Snowflake.
O que são Stored Procedures?
As stored procedures ampliam a linguagem SQL com lógica procedural, permitindo o uso de instruções condicionais, loops e a criação de funcionalidades que seriam impossíveis sem essas construções.
Diferença entre UDFs e Stored Procedures
Além das stored procedures, você também pode criar funções definidas pelo usuário (UDFs). Entender a diferença entre elas é essencial para decidir quando usar UDFs e quando optar por stored procedures (SP).
As stored procedures costumam ser usadas para ações administrativas no Snowflake, como limpar dados antigos, remover tabelas que não estão mais em uso ou fazer backups customizados de dados. Já as UDFs entram em cena quando você precisa calcular e retornar um valor como parte de uma consulta SQL SELECT — por exemplo, a receita de um determinado executivo de vendas ou o bônus de um funcionário.
A invocação de stored procedures usa a palavra-chave CALL como uma instrução independente:
1CALL my_stored_procedure(input_param);
Já as UDFs são chamadas como parte de uma instrução SELECT:
1SELECT column1, my_udf(input_parameter) FROM table1;
Outra diferença está no valor de retorno: as stored procedures podem não retornar nada, apenas executando uma tarefa. Já as UDFs precisam sempre retornar algum valor.
Vamos analisar alguns casos de uso típicos e descobrir se as stored procedures ou as UDFs são mais adequadas:
| Caso de uso | UDF ou Stored Procedure? |
| Criar um novo usuário e um warehouse dedicado | Stored Procedure |
| Apagar todas as tabelas temporárias | Stored Procedure |
| Limpar tabelas não utilizadas | Stored Procedure |
| Identificar a cidade a partir de um endereço IP | UDF |
| Extrair o tipo de navegador de uma string de user agent | UDF |
| Calcular descontos para pedidos | UDF |
| Carregar uma tabela a partir de um stage | Stored Procedure |
Linguagens de Programação Suportadas
O Snowflake suporta várias linguagens para o desenvolvimento de stored procedures. A escolha da mais adequada depende de alguns fatores:
- Preferência e familiaridade pessoal com a linguagem
- Disponibilidade das bibliotecas necessárias
- Consistência com o código já existente nas linguagens suportadas
- Se você quer manter o código in-line ou externamente (como um arquivo independente em um stage)
Aqui está um resumo das linguagens disponíveis e se cada uma suporta tratamento in-line ou em stage:
| Linguagem | Localização do Handler |
|---|---|
| Java | In-line ou em stage |
| JavaScript | In-line |
| Scala | In-line ou em stage |
| Snowflake SQL Scripting | In-line |
Tanto a opção in-line quanto a em stage têm seus prós e contras. O desenvolvimento in-line tende a ser mais simples, já que permite ajustar o código e colá-lo direto na definição da SP. Já o tratamento em stage é vantajoso para código compilado (Java, Scala), pois possibilita reaproveitar código já compilado nas stored procedures do Snowflake.
Como Criar uma Stored Procedure
Usando Snowflake SQL Scripting
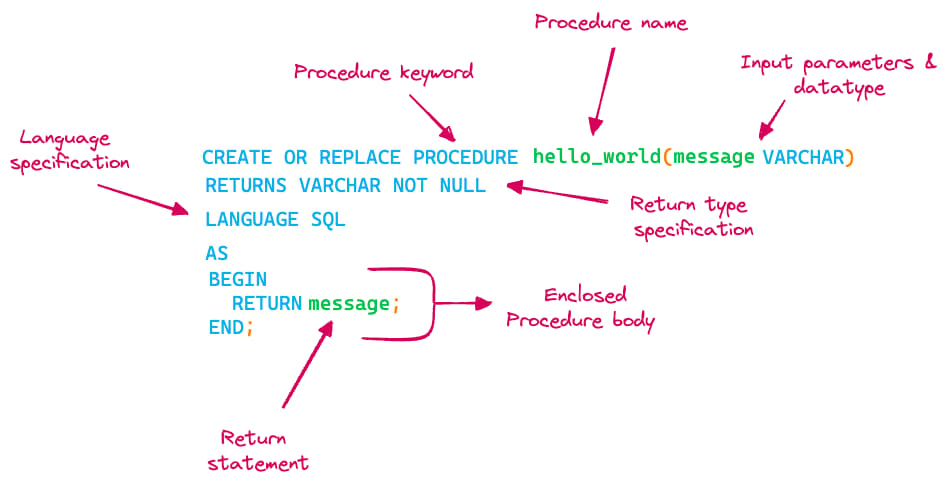
Vamos nos aprofundar na sintaxe de criação de stored procedures (SP) com a linguagem Snowflake SQL Scripting e entender o significado das diferentes palavras-chave. Como mostra a imagem, uma stored procedure é formada por:
- Nome da stored procedure
- Parâmetros de entrada (argumentos) com seus respectivos tipos de dados
- O tipo de retorno da saída da stored procedure
- A especificação da linguagem
- O corpo da stored procedure, onde a lógica de fato vai morar
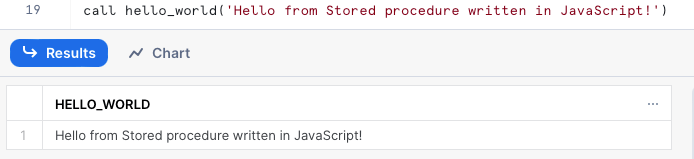
A stored procedure hello_world acima simplesmente retorna a mensagem passada como argumento. Ao chamá-la, vemos a saída sendo exibida:

Usando JavaScript
Vamos modificar o exemplo hello_world e recriá-lo em JavaScript. Aqui está o código da mesma procedure, agora em JavaScript:
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Definimos JavaScript como linguagem e usamos caracteres diferentes para delimitar o corpo da procedure ($$).
A forma de chamar a procedure continua a mesma:
Usando Python
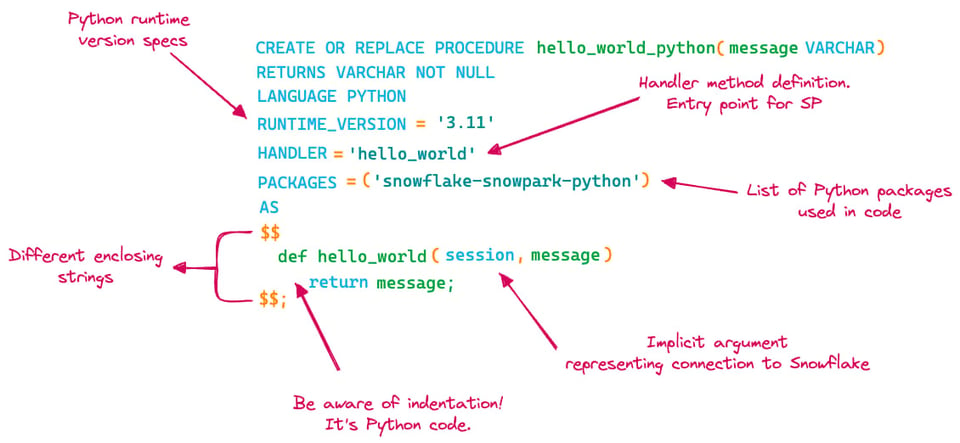
Neste último exemplo, vamos criar a mesma procedure hello_world em Python:
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
Dá pra notar várias mudanças em relação ao SQL Scripting ou ao JavaScript. Vamos atualizar nosso diagrama e destacar as diferenças:
- Para Python, é preciso especificar a versão do Python a ser usada
- É preciso definir um
handler, que é a função Python a ser executada na stored procedure - É preciso especificar quaisquer pacotes Python que serão usados na stored procedure
Chamar a stored procedure em Python funciona igual a qualquer outra linguagem:

Chamando (Executando) Stored Procedures
Agora vamos falar sobre como executar (ou "chamar") uma stored procedure, especialmente quando ela usa argumentos.
Usando Argumentos em Stored Procedures
As stored procedures permitem definir argumentos que você pode passar externamente. Usamos o argumento chamado message no nosso exemplo hello_world. Você também consegue ver como especificar o valor na hora de chamar a stored procedure.
Os argumentos podem ser opcionais se tiverem um valor padrão definido na declaração da SP. Nesse caso, você pode omitir o argumento ao chamar a SP, e o valor padrão será usado. Vamos ajustar nosso exemplo para usar um argumento opcional.
create or replace procedure hello_world(message varchar DEFAULT 'Hello from Stored procedure written in SQL scripting!')
returns varchar not null
language sql
as
begin
return message;
end;
Trabalhando com Argumentos Opcionais e Obrigatórios
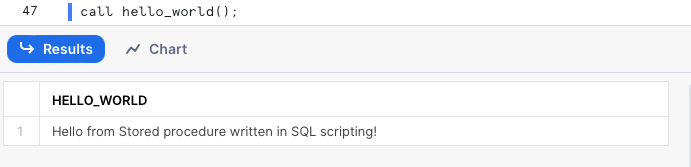
Se você tiver argumentos opcionais e obrigatórios ao mesmo tempo, precisa declarar primeiro os obrigatórios. Agora podemos chamar a procedure sem informar o valor do argumento e o Snowflake usará o padrão.
Mas, é claro, podemos sobrescrever o valor padrão e passar um novo valor ao chamar a procedure:
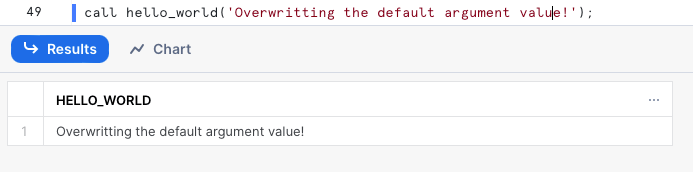
Como Usar Bind Variables em uma Instrução SQL?
Os argumentos também são bastante usados para passar valores às consultas SQL como bind variables dentro das stored procedures. Isso permite construir a consulta SQL dinamicamente com base nos argumentos. Alguns exemplos: passar uma data, um identificador de cliente ou o nome de uma tabela a ser limpa. Vamos criar um exemplo simples em que montaremos uma instrução SELECT dinamicamente e retornaremos valores de uma tabela para um determinado id:
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Expandir Código
O código da stored procedure traz dois conceitos novos. O primeiro é como vincular argumentos de entrada às instruções SQL. Aqui, usamos o caractere dois-pontos antes do nome do argumento: :id. O código também declara uma variável de saída e passa o resultado da instrução SELECT para essa variável dentro do próprio código SQL. Isso é feito com a sintaxe :into <variable_name>.
Privilégios e Tipos de Execução
Stored procedures são objetos de banco de dados, assim como tabelas ou views. Ou seja, pertencem a uma role. Além do privilégio OWNERSHIP, existe também o privilégio USAGE sobre a SP, que pode ser concedido a outras roles. Há ainda mais um ponto relacionado a privilégios e execução de stored procedures: o Snowflake suporta dois modos diferentes de interação com elas. Você pode usar Caller's Rights ou Owner's Rights. Ao criar uma procedure, você define qual dos dois quer utilizar. O padrão é Owner's Rights. Vamos explicar cada modo.
Caller's Rights
Quando você executa uma SP com caller's rights, ela usa os privilégios que o chamador possui. A procedure também tem acesso às informações de sessão do chamador — pode acessar variáveis de sessão e usá-las nas consultas ou modificá-las. Essas alterações de sessão continuam valendo depois que a chamada da SP termina. A SP usa os privilégios de banco de dados do chamador — ela acessa os mesmos objetos de DB que ele acessa. Se a SP contiver alguma instrução ou objeto de DB que o chamador não tenha permissão para usar, será gerado um erro de permissão.
Owner's Rights
Nesse caso, a procedure é executada com os direitos do proprietário e fica desacoplada do chamador. Isso significa que a SP pode fazer coisas que o chamador não conseguiria fazer diretamente. É um ótimo exemplo de como delegar tarefas a outras roles sem precisar conceder os privilégios para isso. Você pode criar uma SP para excluir dados antigos de tabelas e disponibilizá-la aos usuários sem dar a eles o privilégio DELETE nessas tabelas. A procedure executada com owner's rights não tem acesso às informações de sessão do chamador e também não pode modificá-las. A SP também não acessa variáveis criadas fora dela — se isso for necessário, é preciso passar o valor como argumento de entrada.
Qual Modo Usar?
Depende da sua necessidade. Se você quer delegar algo a outros usuários, use owner's rights. Use o mesmo modo se isso não atrapalhar o funcionamento da SP ou se você não quer expor o código da procedure aos chamadores. Por outro lado, use caller's rights se precisar acessar informações da sessão atual ou se a procedure usar somente objetos que o chamador já tem permissão de usar. Vamos resumir as duas opções na tabela:
| Caller's Rights | Owner's Rights |
|---|---|
| Executa com os privilégios do chamador | Executa com os privilégios do proprietário da SP |
| Tem acesso à sessão atual do chamador | Acesso limitado à sessão do chamador |
| Alterações na sessão persistem após o término da chamada da SP | Não pode alterar o estado da sessão |
| Pode visualizar, definir e remover variáveis e parâmetros de sessão do chamador | Não pode visualizar, definir nem remover variáveis e parâmetros de sessão do chamador |
| Só pode usar objetos e operações disponíveis ao chamador | Desacoplada dos privilégios do chamador |
Tipos de Retorno
As procedures podem retornar um valor (number, string, boolean). Também é muito comum que uma SP não retorne nada, já que pode apenas executar algum código sem precisar devolver um valor.
Um tipo de retorno especial das SPs é a tabela. Vamos ver exemplos e mostrar como escrever uma procedure sem valor de retorno e uma procedure que retorna uma tabela.
create or replace procedure no_return_value()
returns varchar null
language sql
as
begin
select 1;
select 2;
select 3;
select 4;
end;
Se você consultar a instrução CREATE PROCEDURE na documentação, verá que a palavra-chave RETURNS é obrigatória. Para definir uma stored procedure sem valor de retorno, você precisa declarar algum tipo de dado de retorno e omitir a palavra-chave return no bloco de código da SP. Não é necessário definir o tipo de retorno especificamente com NULL; o código funcionaria do mesmo jeito apenas com RETURNS VARCHAR, por exemplo.
Ao chamar uma procedure desse tipo, você obterá um valor nulo como saída:

Para retornar uma tabela, é preciso especificar o tipo de retorno como tabela. Se você já conhece os tipos de dados das colunas retornadas, dá para informar logo de cara, junto com os nomes das colunas. Caso contrário, é possível fazer isso em tempo de execução.
Para retornar uma tabela, precisamos apresentar mais um tipo de dado: o RESULTSET. Ele armazena o resultado de uma consulta SQL. Se for preciso processá-lo, você pode iterar pelas linhas ou apenas retornar o resultado, como faremos neste exemplo:
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
Neste exemplo, atribuímos um valor padrão à variável result e depois a retornamos dentro da função table(). Ao chamar essa SP, você obterá como saída uma tabela com duas colunas:
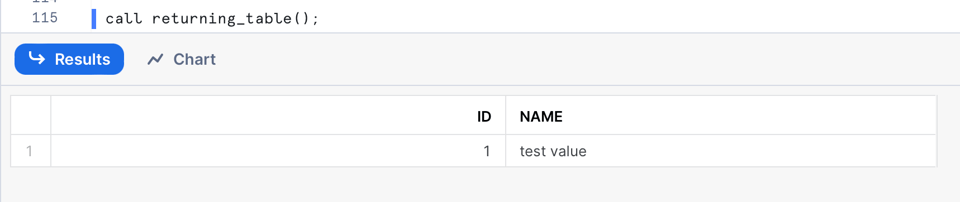
Executar Múltiplas Instruções SQL Iterando pelos Resultados
Já passamos pelos conceitos básicos para escrever stored procedures no Snowflake. Agora vamos juntar tudo isso e criar alguns casos de uso reais para mostrar como aplicar stored procedures em tarefas do dia a dia. Uma tarefa administrativa comum é executar múltiplas instruções SQL geradas dinamicamente a partir dos resultados de outra consulta. Por exemplo, você pode querer limpar todas as tabelas vazias. Primeiro, é preciso encontrar todas as tabelas com 0 registros e depois iterar por elas para excluí-las. Dá para resolver isso com a seguinte stored procedure:
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Vamos analisar o código para entender a lógica.
- Passamos o nome do banco de dados como parâmetro para limpar tabelas e views apenas no DB indicado.
- Declaramos uma variável
RESULTSETchamadatable_list, que recebe os nomes das tabelas vazias como resultado da consulta. - Também definimos um cursor para iterar pelos resultados e uma variável para a instrução
DROP, que será criada e executada dinamicamente dentro do loop. - O corpo da procedure percorre o resultado da consulta linha por linha e monta uma instrução drop com base nos valores recuperados do cursor. Listamos tanto views quanto tabelas — se você quiser limpar apenas tabelas, basta ajustar a consulta de entrada.
- Depois de montada, a instrução drop é executada via
EXECUTE IMMEDIATE.
Quando você chamar a stored procedure, ela deve retornar a mensagem 'cleaning done'. Dá para encontrar as tabelas/views removidas no histórico de consultas, ou você pode ajustar a mensagem de retorno para incluir também os nomes dos objetos removidos.

Documentando Stored Procedures
Uma stored procedure é um trecho de código e, como tal, precisa estar bem comentada para facilitar a manutenção e o uso no futuro. Há várias formas de fazer isso. Você pode usar alguma ferramenta externa, como um data catalog ou uma wiki interna, para descrever a stored procedure lá. Em qualquer caso, sempre foque em dois aspectos:
- Documentação para usuários e chamadores
- Documentação para programadores
Veja alguns exemplos do que deve constar na documentação:
- Descrever a lógica e a finalidade da stored procedure
- Indicar os autores
- Informar a localização — banco de dados e schema
- Detalhar os parâmetros de entrada — nomes, tipos de dados e significado
- Descrever os valores de retorno, possíveis erros e exceções
- Listar os pré-requisitos
- Quais privilégios são necessários
Você também pode adicionar comentários direto no código-fonte e descrever o algoritmo. Minha última recomendação é manter o código-fonte das stored procedures sob controle de versão (GIT). Lembre-se de que stored procedures não fazem parte do Time Travel no Snowflake — você não consegue recuperar a versão anterior do código direto pelo Snowflake.
Exemplos de Stored Procedures
Vamos reunir todos os exemplos de stored procedures mostrados neste post para referência rápida:
Hello World
SQL Scripting
create or replace procedure hello_world(message varchar)
returns varchar not null
language sql
AS
begin
return message;
end;
Javascript
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Python
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
Gerar consulta SQL dinamicamente usando argumentos
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Expandir Código
Retornar uma tabela a partir de uma consulta SQL
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
Executar múltiplas instruções SQL
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Enviar alertas para tasks suspensas
Aqui está um exemplo retirado de um post anterior do blog. Essa stored procedure, chamada task_state_monitor, recebe um task_name como parâmetro e verifica o estado da task. Se o estado for 'suspended', ela envia um alerta por e-mail e retorna uma mensagem. Caso contrário, retorna uma mensagem indicando que o estado da task está OK.
create or replace procedure task_state_monitor(task_name string)
returns varchar not null
language SQL
AS
$$
DECLARE
task_state string;
c CURSOR FOR SELECT "state" from table(result_scan(last_query_id())) where "name" = ?;
BEGIN
show tasks;
open c USING (task_name);
fetch c into task_state;
IF(task_state = 'suspended') THEN
CALL SYSTEM$SEND_EMAIL(
'my_email_int',
Expandir Código
Tomáš Sobotík·Senior Data Engineer & Snowflake SME na Norlys
Tomas é um veterano Snowflake Data SuperHero e referência geral em assuntos relacionados ao Snowflake. Sua ampla experiência no mundo dos dados ultrapassa uma década, período em que atuou como data engineer, arquiteto e administrador Snowflake em diversos projetos, em setores e tecnologias variados. Tomas é um membro ativo da comunidade, compartilhando constantemente seu conhecimento e inspirando outras pessoas. Também é instrutor da O'Reilly, conduzindo treinamentos ao vivo online.