ストアドプロシージャは、クラウド時代や専用の変換ツールが登場するずっと前から、RDBMSの定番機能として使われてきました。データパイプラインの構築やデータベース運用の自動化において、長らく中心的な役割を担ってきた存在です。本記事では、ストアドプロシージャとは何か、そしてSnowflakeのようなモダンなクラウドプラットフォームでその力をどう引き出すかを解説していきます。
ストアドプロシージャとは
ストアドプロシージャは、SQLに手続き型のロジックを加える仕組みです。条件分岐やループを利用でき、通常のSQLだけでは実現できない処理を組み立てられます。
UDFとストアドプロシージャの違い
Snowflakeではストアドプロシージャに加えて、ユーザー定義関数(UDF)も作成できます。両者の違いを押さえておくことは、UDFとストアドプロシージャ(SP)のどちらを使うべきかを判断するうえで欠かせません。
ストアドプロシージャは主に、古いデータのクリーンアップ、未使用テーブルの削除、独自のデータバックアップなど、Snowflakeの管理系タスクで使われます。一方、UDFは特定の営業担当者の売上計算や従業員ボーナスの算出のように、SELECTクエリの中で値を計算して返したい場面で力を発揮します。
ストアドプロシージャは、CALLキーワードを使って独立したステートメントとして呼び出します。
1CALL my_stored_procedure(input_param);
一方、UDFはSELECT文の一部として呼び出します。
1SELECT column1, my_udf(input_parameter) FROM table1;
もう一つの違いは戻り値です。ストアドプロシージャは処理を実行するだけで、何も返さない場合もあります。これに対してUDFは、必ず値を返す必要があります。
それでは代表的なユースケースを取り上げ、ストアドプロシージャとUDFのどちらが適しているかを見ていきましょう。
| ユースケース | UDFかストアドプロシージャか |
| 新規ユーザーと専用ウェアハウスの作成 | ストアドプロシージャ |
| 一時テーブルの一括削除 | ストアドプロシージャ |
| 未使用テーブルのクリーンアップ | ストアドプロシージャ |
| IPアドレスから都市を特定 | UDF |
| ユーザーエージェント文字列からブラウザ種別を抽出 | UDF |
| 注文ごとの割引額を計算 | UDF |
| ステージからテーブルへロード | ストアドプロシージャ |
対応プログラミング言語
Snowflakeでは、ストアドプロシージャの開発に複数の言語が利用できます。どの言語を選ぶかは、次のような点を踏まえて決めるとよいでしょう。
- 個人の言語的な好みや習熟度
- 必要なライブラリが揃っているか
- 既存コードとの整合性
- コードをインラインで持つか、外部(ステージ上のスタンドアロンファイル)に置くか
利用可能な言語と、インライン/ステージのどちらに対応しているかを以下にまとめます。
| 言語 | ハンドラーの配置 |
|---|---|
| Java | インラインまたはステージ |
| JavaScript | インライン |
| Scala | インラインまたはステージ |
| Snowflake SQL Scripting | インライン |
インラインとステージにはそれぞれメリットとデメリットがあります。インラインはシンプルで、コードを調整しながらSP定義に直接書き込めるのが利点です。ステージ方式はコンパイル済みコード(Java、Scala)と相性がよく、既存のコンパイル済みコードをSnowflakeのストアドプロシージャで再利用できます。
ストアドプロシージャの作成方法
Snowflake SQL Scriptingで作成する
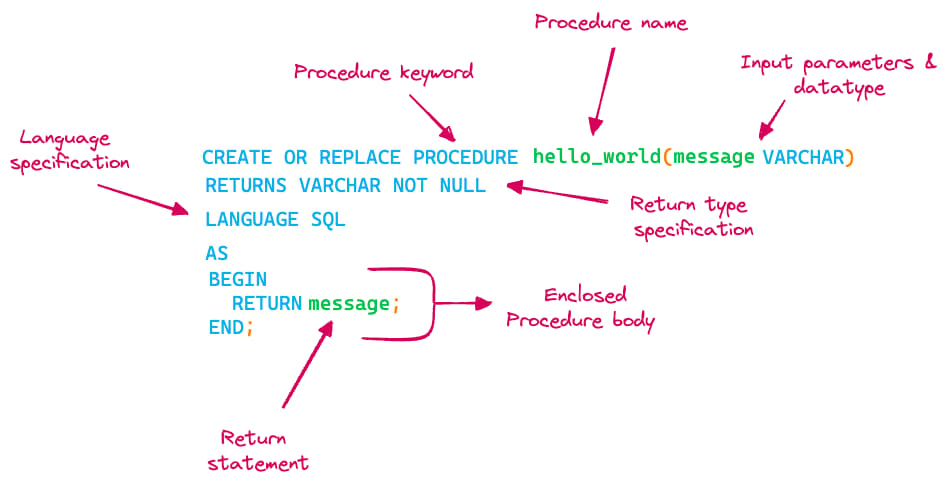
まずはSnowflake SQL Scriptingを使ったストアドプロシージャ(SP)の構文を掘り下げ、各キーワードの意味を読み解いていきましょう。図に示すとおり、ストアドプロシージャは次の要素から構成されます。
- ストアドプロシージャ名
- 入力パラメータ(引数)とそのデータ型
- 出力の戻り値型
- 言語の指定
- 実際のロジックを記述する本体部
上記のhello_worldストアドプロシージャは、引数として渡されたメッセージをそのまま返すだけのシンプルなものです。呼び出すと、出力されたメッセージを確認できます。

JavaScriptで作成する
続いて、同じhello_worldをJavaScriptで書き直してみましょう。コードは次のとおりです。
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
言語をJavaScriptに指定し、プロシージャ本体を囲む記号も$$に変えています。
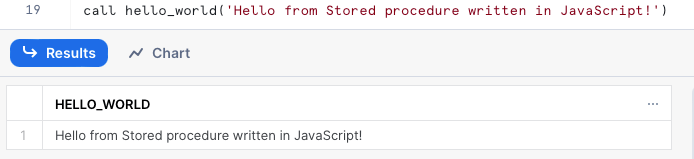
呼び出し方は同じです。
Pythonで作成する
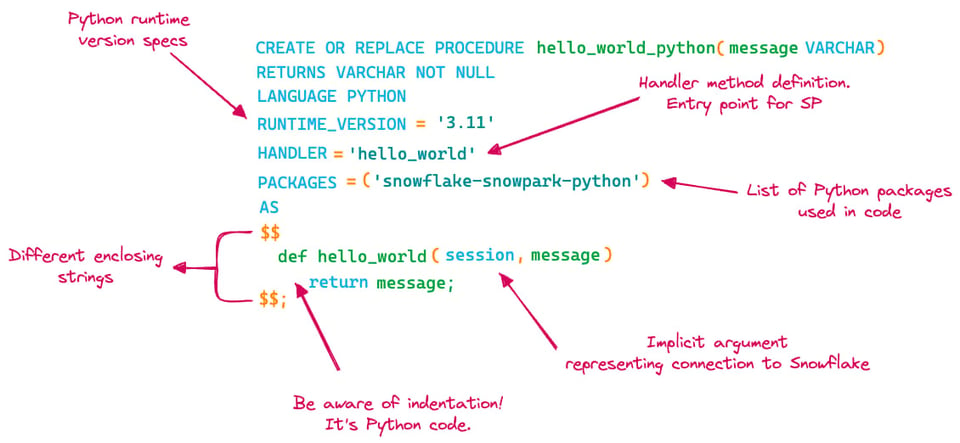
最後に、同じhello_worldプロシージャをPythonで書いてみましょう。
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
SQL ScriptingやJavaScriptと比べて、いくつか違いがあることに気づくはずです。図を更新して変更点を整理しましょう。
- Pythonでは、使用するバージョンを指定する必要があります
handlerの定義が必要です。これがストアドプロシージャ内で実行されるPython関数になります- ストアドプロシージャで使用するPythonパッケージを指定する必要があります
Python製ストアドプロシージャの呼び出し方も他の言語と変わりません。

ストアドプロシージャの呼び出し(実行)
続いて、ストアドプロシージャの実行方法、特に引数を渡して呼び出す方法を見ていきましょう。
引数の使い方
ストアドプロシージャでは、外部から渡せる引数を定義できます。hello_worldの例ではmessageという引数を使いました。呼び出し時に値を指定する方法もあわせて確認しておきましょう。
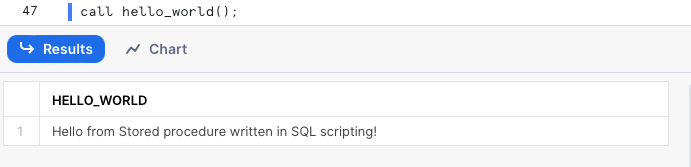
SP定義でデフォルト値を指定しておけば、その引数はオプションになります。呼び出し時に引数を省略すると、デフォルト値が使われます。先ほどの例をオプション引数を使う形に書き換えてみましょう。
create or replace procedure hello_world(message varchar DEFAULT 'Hello from Stored procedure written in SQL scripting!')
returns varchar not null
language sql
as
begin
return message;
end;
オプション引数と必須引数の扱い
オプション引数と必須引数の両方を持つ場合は、必須引数を先に並べる必要があります。これで、引数を省略して呼び出してもSnowflakeがデフォルト値を使ってくれます。
もちろん、呼び出し時にデフォルト値を上書きして新しい値を渡すこともできます。
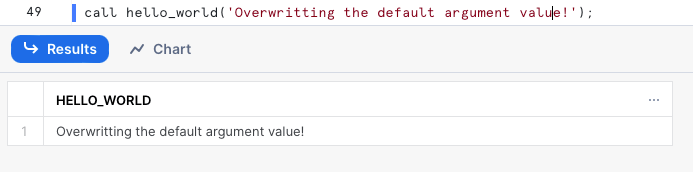
SQL文でバインド変数を使うには
引数は、ストアドプロシージャ内のSQLクエリにバインド変数として値を渡す目的でもよく使われます。これにより、引数に応じてSQLを動的に組み立てられます。日付、顧客ID、クリア対象のテーブル名などを渡すケースが代表的です。簡単な例として、SELECT文を動的に組み立て、指定したidに対応するテーブルの値を返してみましょう。
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
コードを展開
このストアドプロシージャには、新しい概念が2つ含まれています。1つ目は、入力引数をSQL文にバインドする方法です。引数名の前にコロンを付けて:idのように記述します。さらに、出力変数を宣言し、SELECT文の結果をSQLコードの中でその変数に渡しています。これは:into <variable_name>構文で実現します。
権限と実行モード
ストアドプロシージャは、テーブルやビューと同じデータベースオブジェクトです。つまり、ロールによって所有されます。OWNERSHIP権限のほかに、他ロールへ付与できるUSAGE権限もSPに対して用意されています。権限と実行に関しては、もう一つ押さえておきたいトピックがあります。Snowflakeでは、ストアドプロシージャの動作モードとして2種類を選べる、というものです。具体的には、Caller's Rights(呼び出し元の権限)とOwner's Rights(所有者の権限)のいずれかを使用できます。どちらで動かすかはプロシージャ作成時に指定し、デフォルトは所有者の権限です。それぞれのモードを順に説明していきましょう。
Caller's Rights(呼び出し元の権限)
呼び出し元の権限でSPを実行すると、SPは呼び出し元が持つ権限を使って動作します。呼び出し元のセッション情報にもアクセスでき、セッション変数を参照したり、クエリ内で使用したり、変更したりできます。こうしたセッションの変更は、SPの呼び出しが終わった後も維持されます。SPは呼び出し元のデータベース権限を使うため、呼び出し元と同じDBオブジェクトにアクセスできます。逆に、呼び出し元が権限を持たないステートメントやDBオブジェクトがSPに含まれていると、SPは権限エラーを発生させます。
Owner's Rights(所有者の権限)
このモードでは、プロシージャは所有者の権限で実行され、呼び出し元から切り離されます。つまり、呼び出し元が直接行えないことでもSP経由なら実行できます。これは、必要な権限を直接付与せずに他のロールへ作業を委譲したいときに便利な仕組みです。たとえば、古いデータを削除するSPを作成すれば、対象テーブルへのDELETE権限を付与しなくてもユーザーに削除処理を実行させられます。所有者の権限で動作するプロシージャは、呼び出し元のセッション情報にアクセスできず、変更もできません。また、SPの外で作成された変数にもアクセスできないため、必要であれば入力引数として値を渡す必要があります。
どちらのモードを使うべきか
用途次第です。他のユーザーに何かを委譲したい場合は、所有者の権限が向いています。SPの動作に支障がない場合や、プロシージャのコードを呼び出し元に公開したくない場合も、所有者の権限がおすすめです。一方、現在のセッション情報にアクセスする必要がある場合や、プロシージャが使うのは呼び出し元自身が所有・利用できるオブジェクトだけ、というケースでは呼び出し元の権限が適しています。両モードを表にまとめると次のとおりです。
| Caller's Rights(呼び出し元の権限) | Owner's Rights(所有者の権限) |
|---|---|
| 呼び出し元の権限で動作 | SP所有者の権限で動作 |
| 呼び出し元の現在のセッションにアクセス可能 | 呼び出し元のセッションへのアクセスは制限される |
| セッションの変更はSP呼び出し終了後も保持される | セッション状態を変更できない |
| 呼び出し元のセッション変数・パラメータを参照/設定/解除できる | 呼び出し元のセッション変数・パラメータを参照/設定/解除できない |
| 呼び出し元が使えるオブジェクトと操作のみ利用可 | 呼び出し元の権限から切り離される |
戻り値の型
プロシージャは数値、文字列、ブール値などの値を返せますが、コードを実行するだけで何も返さない、というのもごく一般的なパターンです。
SPの特殊な戻り値型として、テーブルがあります。戻り値を持たないプロシージャと、テーブルを返すプロシージャの両方を、例を通して見ていきましょう。
create or replace procedure no_return_value()
returns varchar null
language sql
as
begin
select 1;
select 2;
select 3;
select 4;
end;
公式ドキュメントでCREATE PROCEDUREを確認するとわかるとおり、RETURNSキーワードは必須です。戻り値のないストアドプロシージャを定義するには、何らかの戻り値型を指定したうえで、コードブロック内のreturnキーワードを省きます。戻り値型は、必ずしもNULL付きで定義する必要はなく、RETURNS VARCHARのように書いても問題なく動作します。
こうしたプロシージャを呼び出すと、出力としてnullが返ります。

テーブルを返すには、戻り値型としてテーブルを指定します。返すカラムのデータ型が事前にわかっていれば、カラム名と一緒に指定しておけます。わからない場合は、実行時に指定することも可能です。
テーブルを返す前に、もう一つRESULTSETというデータ型を紹介しておきます。これはSQLクエリの結果を保持できる型です。さらに加工したい場合は行単位でイテレートできますし、今回のように結果をそのまま返すこともできます。
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
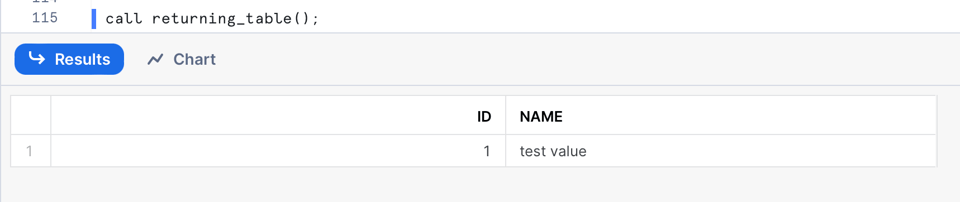
この例では、結果変数にデフォルト値を割り当て、table()関数で包んで返しています。このSPを呼び出すと、出力として2カラムのテーブルが得られます。
結果をループして複数のSQL文を実行する
ここまで、Snowflakeでストアドプロシージャを書くための基本概念を見てきました。次は、それらを組み合わせて実際のタスクに応用する具体例を作ってみましょう。よくある管理タスクの一つに、別のクエリ結果に応じて動的に組み立てた複数のSQL文を実行する、というものがあります。たとえば、空のテーブルをまとめて整理したい場合、まずレコード数が0のテーブルを洗い出し、それらを順に削除する必要があります。次のストアドプロシージャで実現できます。
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
ロジックを順に見ていきましょう。
- 指定したDB内のテーブルとビューだけを対象にするため、データベース名をパラメータとして受け取ります。
- クエリ結果として空のテーブル名を保持する
RESULTSET変数table_listを宣言します。 - 結果をイテレートするためのカーソルと、ループ内で動的に生成・実行する
DROP文を格納する変数も定義します。 - プロシージャ本体では、クエリ結果を1行ずつ処理し、カーソルから取り出した値をもとにDROP文を組み立てます。ここではビューとテーブルの両方を対象にしていますが、テーブルだけを対象にしたい場合は入力クエリを修正してください。
- DROP文を組み立てたら、
EXECUTE IMMEDIATEで実行します。
このストアドプロシージャを呼び出すと、'cleaning done'というメッセージが返ります。削除されたテーブル/ビューはクエリ履歴から確認できますし、戻り値のメッセージを変更して、削除したオブジェクト名を一緒に返すようにすることも可能です。

ストアドプロシージャのドキュメント化
ストアドプロシージャもコードである以上、将来のメンテナンスや利用のしやすさを考えて、きちんとコメントを残しておくべきです。方法はいくつかあります。データカタログや社内Wikiといった外部ツールを使って、そこにプロシージャの情報を残すのもよいでしょう。意識したい観点は、次の2つです。
- 利用者・呼び出し元向けのドキュメント
- プログラマー向けのドキュメント
ドキュメントに盛り込むべき内容の例を挙げます。
- ストアドプロシージャのロジックと目的
- 作成者
- 配置場所(データベースとスキーマ)
- 入力パラメータ(名前、データ型、意味)
- 戻り値、想定されるエラー、例外
- 前提条件
- 必要な権限
ソースコードに直接コメントを書いてアルゴリズムを説明することもできます。最後に一つおすすめしたいのは、ストアドプロシージャのソースコードをバージョン管理(GIT)下に置くことです。SnowflakeのストアドプロシージャはTime Travelの対象外であることを忘れないでください(Time Travel)。以前のバージョンのコードをSnowflake内から直接取り戻すことはできません。
ストアドプロシージャのサンプル集
本記事で紹介したストアドプロシージャのサンプルを、リファレンスとしてまとめておきます。
Hello World
SQL Scripting
create or replace procedure hello_world(message varchar)
returns varchar not null
language sql
AS
begin
return message;
end;
Javascript
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Python
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
引数を使ってSQLクエリを動的に生成する
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
コードを展開
SQLクエリの結果をテーブルとして返す
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
複数のSQL文を実行する
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
停止中タスクのアラートを送信する
こちらは過去のブログ記事から引用した例です。task_state_monitorという名前のこのストアドプロシージャは、task_nameをパラメータとして受け取り、タスクの状態を確認します。状態がsuspended(停止中)であれば、メールアラートを送信し、メッセージを返します。それ以外の場合は、タスクが正常であることを示すメッセージを返します。
create or replace procedure task_state_monitor(task_name string)
returns varchar not null
language SQL
AS
$$
DECLARE
task_state string;
c CURSOR FOR SELECT "state" from table(result_scan(last_query_id())) where "name" = ?;
BEGIN
show tasks;
open c USING (task_name);
fetch c into task_state;
IF(task_state = 'suspended') THEN
CALL SYSTEM$SEND_EMAIL(
'my_email_int',
コードを展開
Tomáš Sobotík・Senior Data Engineer & Snowflake SME at Norlys
TomasはSnowflake Data SuperHeroとして長年活躍する、Snowflake全般のエキスパートです。データ業界での経験は10年以上に及び、Snowflakeのデータエンジニア、アーキテクト、管理者として、業界・技術を横断するさまざまなプロジェクトに携わってきました。コミュニティの中心メンバーの一人として、自らの知見を積極的に発信し、多くの人にインスピレーションを与えています。また、O'Reillyのインストラクターとして、ライブ形式のオンライントレーニングも担当しています。