Les procédures stockées sont un pilier des SGBDR depuis bien longtemps, bien avant l'ère du cloud et l'arrivée des outils de transformation dédiés. Elles ont joué un rôle clé dans la construction des pipelines de données et l'automatisation des bases de données. Dans cet article, nous allons voir ce que sont les procédures stockées et comment exploiter pleinement leur potentiel sur les plateformes cloud modernes comme Snowflake.
Qu'est-ce qu'une procédure stockée ?
Les procédures stockées enrichissent le langage SQL d'une logique procédurale, ce qui permet d'utiliser des instructions conditionnelles, des boucles et de créer des fonctionnalités impossibles à réaliser autrement.
Différence entre UDF et procédures stockées
En plus des procédures stockées, vous pouvez créer des fonctions définies par l'utilisateur (UDF). Bien comprendre la distinction entre les deux est essentiel pour savoir quand utiliser une UDF et quand opter pour une procédure stockée (SP).
Les procédures stockées sont généralement utilisées pour des actions administratives dans Snowflake : nettoyer d'anciennes données, supprimer des tables inutilisées ou réaliser des sauvegardes personnalisées. Les UDF, à l'inverse, entrent en jeu lorsqu'il faut calculer et retourner une valeur au sein d'une requête SQL SELECT, comme le chiffre d'affaires d'un commercial ou les primes d'un employé.
L'appel d'une procédure stockée se fait avec le mot-clé CALL, sous la forme d'une instruction indépendante :
1CALL my_stored_procedure(input_param);
Les UDF, en revanche, s'appellent au sein d'une instruction SELECT :
1SELECT column1, my_udf(input_parameter) FROM table1;
Autre différence : la valeur de retour. Une procédure stockée peut ne rien retourner et se contenter d'exécuter une tâche. Une UDF, à l'inverse, doit toujours retourner une valeur.
Passons en revue quelques cas d'usage classiques pour déterminer ce qui convient le mieux :
| Cas d'usage | UDF ou procédure stockée ? |
| Créer un nouvel utilisateur et un warehouse dédié | Procédure stockée |
| Supprimer toutes les tables temporaires | Procédure stockée |
| Nettoyer les tables inutilisées | Procédure stockée |
| Déterminer la ville à partir d'une adresse IP | UDF |
| Extraire le type de navigateur d'une chaîne user agent | UDF |
| Calculer des remises sur des commandes | UDF |
| Charger une table depuis un stage | Procédure stockée |
Langages de programmation pris en charge
Snowflake prend en charge plusieurs langages pour développer des procédures stockées. Le choix dépend de plusieurs facteurs :
- Vos préférences et votre maîtrise du langage
- La disponibilité des bibliothèques nécessaires
- La cohérence avec le code existant dans les langages pris en charge
- Le choix de conserver le code en ligne ou en externe (sous forme de fichier autonome dans un stage)
Voici un récapitulatif des langages disponibles et de leur mode de gestion (en ligne ou via stage) :
| Langage | Emplacement du handler |
|---|---|
| Java | En ligne ou via stage |
| JavaScript | En ligne |
| Scala | En ligne ou via stage |
| Snowflake SQL Scripting | En ligne |
Chaque option a ses avantages et ses inconvénients. Le développement en ligne est souvent plus simple : vous peaufinez le code et l'intégrez directement à la définition de la SP. Le mode staged est intéressant pour le code compilé (Java, Scala), car il permet de réutiliser dans les procédures stockées Snowflake du code déjà compilé.
Comment créer une procédure stockée
Avec Snowflake SQL Scripting
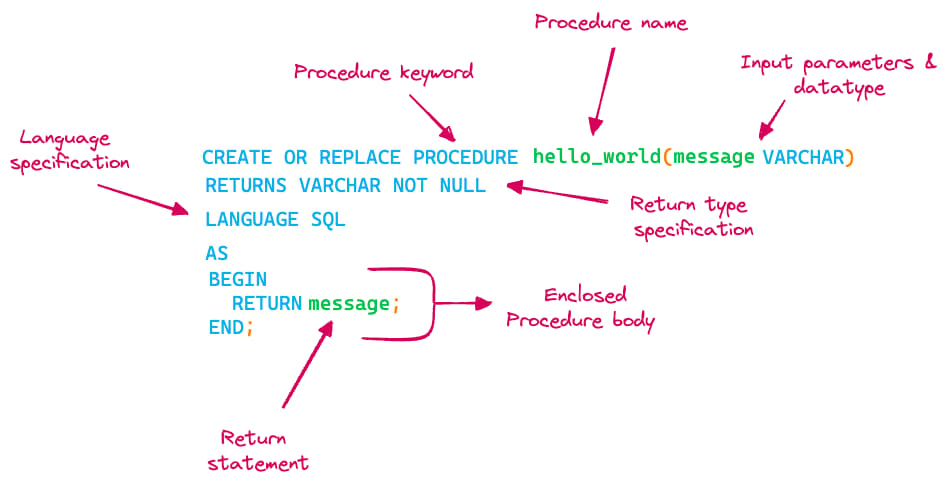
Penchons-nous sur la syntaxe de création d'une procédure stockée (SP) avec le langage Snowflake SQL Scripting et décryptons la signification des différents mots-clés. Comme illustré, une procédure stockée se compose des éléments suivants :
- Le nom de la procédure stockée
- Les paramètres d'entrée (arguments) et leurs types de données
- Le type de retour de la sortie
- La spécification du langage
- Le corps de la procédure, où réside la logique métier
La procédure stockée hello_world ci-dessus retourne simplement le message passé en argument. En l'appelant, on voit la sortie s'afficher :

Avec JavaScript
Modifions l'exemple hello_world pour le réécrire en JavaScript. Voici le code de la même procédure, cette fois en JavaScript :
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Nous avons défini JavaScript comme langage et utilisé des caractères différents pour délimiter le corps de la procédure ($$).
L'appel de la procédure reste identique :
Avec Python
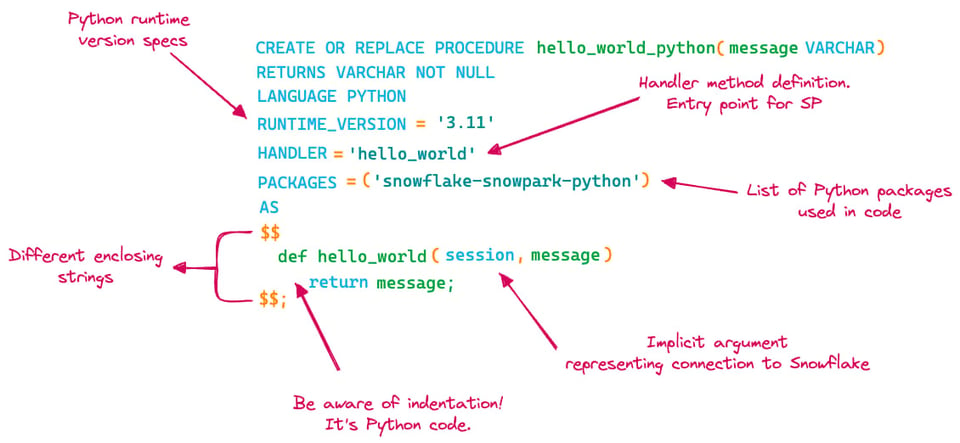
Pour ce dernier exemple, nous allons créer la même procédure hello_world en Python :
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
Plusieurs différences apparaissent par rapport à SQL Scripting ou JavaScript. Mettons à jour notre schéma pour mettre en évidence ces changements :
- Pour Python, il faut préciser la version de Python à utiliser
- Il faut définir un
handler, c'est-à-dire la fonction Python qui sera exécutée dans la procédure stockée - Il faut indiquer les paquets Python utilisés dans la procédure
L'appel d'une procédure stockée Python est identique à celui des autres langages :

Appeler (exécuter) des procédures stockées
Voyons maintenant comment exécuter (ou appeler) une procédure stockée, en particulier avec des arguments.
Utiliser des arguments dans les procédures stockées
Les procédures stockées permettent de définir des arguments transmis depuis l'extérieur. Nous avons utilisé l'argument message dans notre exemple hello_world. Vous voyez également comment renseigner la valeur lors de l'appel de la procédure.
Les arguments peuvent être optionnels s'ils disposent d'une valeur par défaut dans la définition de la SP. Dans ce cas, vous pouvez omettre l'argument lors de l'appel, et la valeur par défaut sera utilisée. Modifions notre exemple pour utiliser un argument optionnel.
create or replace procedure hello_world(message varchar DEFAULT 'Hello from Stored procedure written in SQL scripting!')
returns varchar not null
language sql
as
begin
return message;
end;
Gérer les arguments optionnels et obligatoires
Si vous avez à la fois des arguments optionnels et obligatoires, les arguments obligatoires doivent être déclarés en premier. Nous pouvons désormais appeler la procédure sans valeur d'argument, et Snowflake utilisera la valeur par défaut.
Bien entendu, nous pouvons écraser la valeur par défaut et passer une nouvelle valeur lors de l'appel :
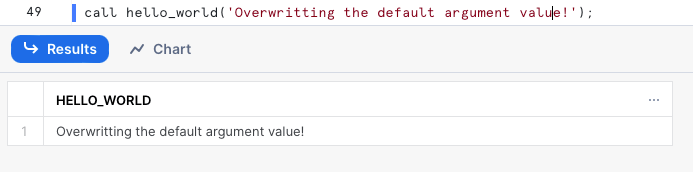
Comment utiliser des variables liées dans une instruction SQL ?
Les arguments servent aussi souvent à transmettre des valeurs aux requêtes SQL sous forme de variables liées (bind variables) au sein des procédures stockées. Cela permet de construire la requête SQL dynamiquement en fonction des arguments. On peut par exemple passer une date, un identifiant client ou le nom d'une table à nettoyer. Créons un exemple simple où nous construisons dynamiquement une instruction SELECT pour retourner les valeurs d'une table pour un id donné :
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Développer le code
Le code de la procédure stockée introduit deux nouveaux concepts. Le premier porte sur la liaison des arguments d'entrée aux instructions SQL. On utilise ici le caractère deux-points devant le nom de l'argument : :id. Le code déclare également une variable de sortie et y transmet le résultat de l'instruction SELECT, directement depuis le code SQL. Cela se fait via la syntaxe :into <variable_name>.
Privilèges et modes d'exécution
Les procédures stockées sont des objets de base de données, au même titre que les tables ou les vues. Elles appartiennent donc à un rôle. Outre le privilège OWNERSHIP, il existe également un privilège USAGE sur la SP, qui peut être accordé à d'autres rôles. Un autre point lié aux privilèges concerne l'exécution des procédures stockées. Snowflake prend en charge deux modes d'interaction : les Caller's Rights ou les Owner's Rights. Lors de la création d'une procédure, vous choisissez l'un ou l'autre. Le mode par défaut est Owner's Rights. Détaillons-les.
Caller's Rights
Lorsque vous exécutez une SP en mode Caller's Rights, celle-ci utilise les privilèges de l'appelant. Elle a également accès aux informations de session de l'appelant : elle peut consulter les variables de session, les utiliser dans des requêtes ou les modifier. Ces changements de session persistent après la fin de l'appel. La SP utilise les privilèges de base de données de l'appelant : elle accède aux mêmes objets DB que lui. Si la SP contient une instruction ou un objet DB que l'appelant n'a pas le droit d'utiliser, elle lèvera une erreur de permission.
Owner's Rights
Dans ce cas, la procédure s'exécute avec les droits du propriétaire et est découplée de l'appelant. La SP peut donc effectuer des opérations que l'appelant ne pourrait pas réaliser directement. C'est un excellent moyen de déléguer certaines tâches à d'autres rôles sans leur accorder les privilèges correspondants. Vous pouvez par exemple créer une SP pour supprimer d'anciennes données et la mettre à disposition des utilisateurs sans leur accorder le privilège DELETE sur les tables concernées. Une procédure exécutée avec les droits du propriétaire n'a pas accès aux informations de session de l'appelant et ne peut pas les modifier. La SP n'a pas non plus accès aux variables créées en dehors d'elle : si besoin, vous devez transmettre la valeur en argument d'entrée.
Quel mode choisir ?
Cela dépend de vos besoins. Si vous souhaitez déléguer une tâche à d'autres utilisateurs, optez pour les Owner's Rights. Choisissez ce même mode si cela n'empêche pas la SP de fonctionner correctement, ou si vous ne voulez pas exposer le code aux appelants. À l'inverse, utilisez les Caller's Rights si vous avez besoin d'accéder à la session courante ou si la procédure n'utilise que des objets que l'appelant possède ou peut utiliser. Récapitulons les deux options :
| Caller's Rights | Owner's Rights |
|---|---|
| S'exécute avec les privilèges de l'appelant | S'exécute avec les privilèges du propriétaire de la SP |
| Accès à la session courante de l'appelant | Accès limité à la session de l'appelant |
| Les modifications de session persistent après la fin de l'appel | Ne peut pas modifier l'état de la session |
| Peut consulter, définir et désactiver les variables et paramètres de session de l'appelant | Ne peut pas consulter, définir ni désactiver les variables et paramètres de session de l'appelant |
| Ne peut utiliser que les objets et opérations accessibles à l'appelant | Découplée des privilèges de l'appelant |
Types de retour
Une procédure peut retourner une valeur (nombre, chaîne, booléen). Il est aussi très courant qu'une SP ne retourne rien, car elle se contente parfois d'exécuter du code sans rien renvoyer.
Un type de retour particulier est la table. Voyons à travers des exemples comment écrire une procédure sans valeur de retour, puis une procédure qui retourne une table.
create or replace procedure no_return_value()
returns varchar null
language sql
as
begin
select 1;
select 2;
select 3;
select 4;
end;
Si vous consultez l'instruction CREATE PROCEDURE dans la documentation, vous verrez que le mot-clé RETURNS est obligatoire. Pour définir une procédure stockée sans valeur de retour, il faut donc déclarer un type de retour et omettre le mot-clé return dans le bloc de code. Il n'est pas nécessaire de spécifier explicitement la clause NULL dans le type de retour : RETURNS VARCHAR fonctionnerait tout aussi bien.
Lorsque vous appelez ce type de procédure, vous obtenez une valeur null en sortie :

Pour retourner une table, vous devez préciser que le type de retour est une table. Si vous connaissez les types des colonnes retournées, vous pouvez les déclarer dès maintenant avec leur nom. Sinon, vous pouvez le faire à l'exécution.
Pour retourner une table, nous devons introduire un autre type de données : RESULTSET. Ce type peut contenir le résultat d'une requête SQL. Si vous devez le traiter davantage, vous pouvez itérer sur les lignes ou simplement renvoyer le résultat, comme dans cet exemple :
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
Ici, nous attribuons une valeur par défaut à notre variable result, puis nous la retournons via la fonction table(). Lorsque vous appelez cette SP, vous obtenez en sortie une table à deux colonnes :
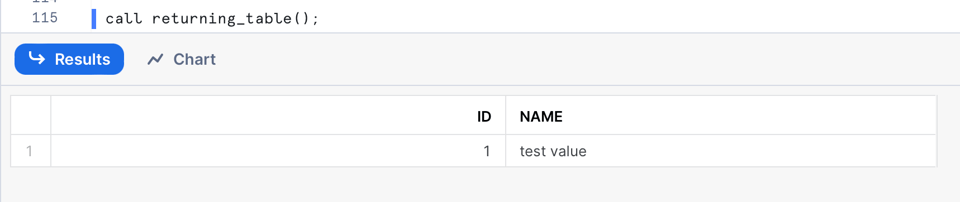
Exécuter plusieurs instructions SQL en itérant sur des résultats
Nous avons parcouru les concepts de base de l'écriture de procédures stockées dans Snowflake. Mettons-les maintenant en pratique sur des cas réels. Une tâche administrative classique consiste à exécuter dynamiquement plusieurs instructions SQL générées à partir des résultats d'une autre requête. Vous pouvez par exemple vouloir nettoyer toutes les tables vides. Il faut d'abord identifier toutes les tables comportant 0 enregistrement, puis les parcourir pour les supprimer. Voici une procédure stockée qui répond à ce besoin :
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Décortiquons la logique :
- Nous transmettons le nom de la base de données en paramètre afin de ne nettoyer les tables et vues que dans la DB définie.
- Nous déclarons une variable
RESULTSETtable_listcontenant les noms des tables vides issues de la requête. - Nous définissons également un cursor pour itérer sur les résultats, ainsi qu'une variable pour l'instruction
DROPque nous construirons et exécuterons dynamiquement dans la boucle. - Le corps de la procédure parcourt ensuite le résultat ligne par ligne et construit une instruction drop à partir des valeurs récupérées dans le cursor. Nous avons inclus à la fois les vues et les tables ; pour ne traiter que les tables, il suffit de modifier la requête d'entrée.
- Une fois l'instruction drop construite, on l'exécute via
EXECUTE IMMEDIATE.
Lorsque vous appelez la procédure stockée, elle retourne le message cleaning done. Vous pouvez retrouver les tables et vues supprimées dans l'historique des requêtes, ou modifier le message de retour pour y inclure également les noms des objets supprimés.

Documenter les procédures stockées
Une procédure stockée est un morceau de code et doit, à ce titre, être correctement commentée pour faciliter sa maintenance et son usage futurs. Plusieurs options s'offrent à vous. Vous pouvez vous appuyer sur un outil externe comme un data catalog ou un wiki interne pour décrire la procédure stockée. Concentrez-vous toujours sur deux aspects :
- La documentation pour les utilisateurs et les appelants
- La documentation pour les développeurs
Voici quelques exemples de ce que la documentation devrait inclure :
- Décrire la logique et l'intention de la procédure stockée
- Indiquer les auteurs
- Préciser la localisation : base de données et schéma
- Décrire les paramètres d'entrée : noms, types de données et signification
- Décrire les valeurs de retour, les erreurs possibles et les exceptions
- Indiquer les prérequis
- Préciser les privilèges nécessaires
Vous pouvez ajouter des commentaires directement dans le code source pour y décrire l'algorithme. Ma dernière recommandation : placer le code source des procédures stockées sous contrôle de version (GIT). N'oubliez pas que les procédures stockées ne sont pas couvertes par le Time Travel de Snowflake. Vous ne pourrez pas récupérer directement dans Snowflake une version antérieure du code.
Exemples de procédures stockées
Récapitulons tous les exemples de procédures stockées présentés dans cet article, pour référence rapide :
Hello World
SQL Scripting
create or replace procedure hello_world(message varchar)
returns varchar not null
language sql
AS
begin
return message;
end;
JavaScript
create or replace procedure hello_world_javascript(message varchar)
returns varchar not null
language javascript
as
$$
return message;
$$;
Python
create or replace procedure hello_world_python(message varchar)
returns varchar not null
language python
runtime_version = 3.11
handler = 'hello_world'
packages = ('snowflake-snowpark-python')
as
$$
def hello_world(session, message):
return message;
$$;
Générer dynamiquement une requête SQL à partir d'arguments
-- create a test table
create table SP_TEST (
id number,
value varchar
);
-- insert data
insert into SP_TEST values (1, 'value 1');
insert into SP_TEST values (2, 'value 2');
-- create a stored procedure
CREATE PROCEDURE DYNAMIC_QUERY(ID number)
RETURNS VARCHAR
language sql
as
Développer le code
Retourner une table depuis une requête SQL
create or replace procedure returning_table()
returns table(id number, name varchar)
language sql
as
declare
result RESULTSET DEFAULT (SELECT 1 id, 'test value' name);
begin
return table(result);
end;
Exécuter plusieurs instructions SQL
create or replace procedure clean_empty_tables(db_name varchar)
returns varchar
language sql
as
declare
table_list RESULTSET DEFAULT (SELECT TABLE_NAME, TABLE_TYPE, TABLE_SCHEMA FROM SNOWFLAKE.ACCOUNT_USAGE.TABLES WHERE table_catalog = :db_name and row_count = 0 and deleted is null);
c1 CURSOR FOR table_list;
drop_statement varchar;
begin
for record in c1 do
drop_statement := 'DROP ' || record.table_type || ' ' || :db_name || '.' || record.table_schema || '.' || record.table_name || ';';
execute immediate drop_statement;
end for;
return 'cleaning done;';
end;
Envoyer des alertes pour les tâches suspendues
Voici un exemple tiré d'un précédent article. Cette procédure stockée, nommée task_state_monitor, prend un task_name en paramètre et vérifie l'état de la tâche. Si l'état est suspended, elle envoie une alerte par e-mail et retourne un message. Sinon, elle retourne un message indiquant que l'état de la tâche est correct.
create or replace procedure task_state_monitor(task_name string)
returns varchar not null
language SQL
AS
$$
DECLARE
task_state string;
c CURSOR FOR SELECT "state" from table(result_scan(last_query_id())) where "name" = ?;
BEGIN
show tasks;
open c USING (task_name);
fetch c into task_state;
IF(task_state = 'suspended') THEN
CALL SYSTEM$SEND_EMAIL(
'my_email_int',
Développer le code
Tomáš Sobotík·Senior Data Engineer & Snowflake SME chez Norlys
Tomas est Snowflake Data SuperHero de longue date et expert reconnu de Snowflake. Fort de plus de dix ans d'expérience dans l'univers de la donnée, il a occupé les rôles de data engineer, architecte et administrateur Snowflake sur de nombreux projets, dans des secteurs et des technologies très variés. Membre actif de la communauté, Tomas partage volontiers son expertise et inspire les autres. Il est également formateur chez O'Reilly, où il anime des sessions de formation en ligne en direct.