In unserem vorherigen Beitrag zu Micro-Partitions haben wir uns angesehen, wie das einzigartige Speicherformat von Snowflake eine Query-Optimierung namens Pruning ermöglicht. Durchdachtes Query-Design in Kombination mit effektivem Clustering verbessert Pruning und damit die Abfragegeschwindigkeit deutlich. Wir zeigen, wie und wann Sie dieses leistungsstarke Snowflake-Feature einsetzen sollten.
Was ist Snowflake-Clustering?
Clustering beschreibt, wie die Daten einer Tabelle über die Micro-Partitions – die Speichereinheit in Snowflake – verteilt sind. Ist eine Tabelle gut geclustert, kann Snowflake anhand der Metadaten jeder Micro-Partition die Zahl der zu scannenden Dateien minimieren und so die Query-Performance erheblich verbessern. Damit zählt Clustering zu den wirkungsvollsten Optimierungstechniken, mit denen Snowflake-Anwender die Performance steigern und Kosten senken können.
Schauen wir uns das Konzept an einem Beispiel an.
Beispiel einer gut geclusterten Tabelle
Im folgenden Diagramm sehen Sie eine hypothetische Orders-Tabelle, die auf der Spalte created_at gut geclustert ist: Zeilen mit ähnlichen created_at-Werten liegen in denselben Micro-Partitions.

Snowflake hält für jede Spalte in jeder Micro-Partition Metadaten zu Minimal- und Maximalwert vor. In dieser Tabelle enthält jede Micro-Partition Datensätze mit einem eng begrenzten Bereich von created_at-Werten – die Tabelle ist auf dieser Spalte also gut geclustert. Die folgende Abfrage scannt nur die drei hervorgehobenen Micro-Partitions, da Snowflake anhand der where-Klausel und der Min-/Max-Metadaten erkennt, dass die übrigen ignoriert werden können. Dieses Verhalten heißt Query Pruning.
1select * from orders where created_at > '2022/08/14'
Wenig überraschend läuft die Abfrage spürbar schneller, wenn statt aller nur drei Micro-Partitions gescannt werden.
Wann sollten Sie Clustering einsetzen?
Die meisten Snowflake-Anwender müssen sich gar nicht mit Clustering beschäftigen. Wenn Ihre Abfragen schnell genug laufen und Sie komfortabel im Budget liegen, lohnt sich der Aufwand nicht. Aber: Wenn Performance und/oder Kosten für Sie eine Rolle spielen, sollten Sie Clustering definitiv auf dem Schirm haben.
Pruning ist wohl die wirkungsvollste Optimierungstechnik, die Snowflake-Anwendern zur Verfügung steht – denn die Menge der gescannten und verarbeiteten Daten zu reduzieren, ist ein Grundprinzip der Big-Data-Verarbeitung: "The fastest way to process data? Don't."
Die Snowflake-Dokumentation legt nahe, dass sich Clustering nur für Tabellen mit "mehreren Terabyte (TB) an Daten" lohnt. Unserer Erfahrung nach zeigen sich Performance-Vorteile aber schon bei Tabellen ab wenigen hundert Megabyte (MB).
Den passenden Clustering Key wählen
Um zu beurteilen, ob eine Tabelle für die typischen Abfragen gut geclustert ist, müssen Sie zunächst die Query-Muster kennen. Die access_history-View von Snowflake ist eine einfache Möglichkeit, historische Abfragen für eine bestimmte Tabelle abzurufen.
Häufig in where-Klauseln genutzte Filterspalten eignen sich gut als Clustering Keys. Zum Beispiel:
1select * from table_a where created_at > '2022-09-25'
Die obige Abfrage profitiert davon, wenn die Tabelle auf der Spalte created_at gut geclustert ist: Ähnliche Werte liegen dann in denselben Micro-Partitions, sodass nur wenige Micro-Partitions gescannt werden müssen. Diese Pruning-Entscheidung trifft der Query-Compiler im Cloud Services Layer – noch vor der eigentlichen Ausführung.
In der Praxis empfehlen wir, mit den teuersten Abfragen in Ihrem Account zu starten. Dort finden sich häufig Abfragen, die trotz Filterung schlecht prunen – und damit klare Ansatzpunkte für besseres Clustering bieten.
Wie aktiviert man Clustering in Snowflake?
Sobald Sie wissen, auf welchen Spalten Sie clustern möchten, brauchen Sie eine Clustering-Methode. Wir unterscheiden dabei drei Varianten.
1. Natürliches Clustering
Angenommen, ein ETL-Prozess fügt einer Events-Tabelle stündlich neue Events hinzu. Eine Spalte inserted_at hält den Zeitpunkt fest, zu dem die Events in die Tabelle geladen werden. Neu erzeugte Micro-Partitions enthalten dann jeweils einen eng begrenzten Bereich von inserted_at-Werten. Diese Events-Tabelle ist auf der Spalte inserted_at natürlich geclustert. Eine Abfrage, die nach inserted_at filtert, kann Micro-Partitions effektiv prunen.
Wenn Sie ein Backfill einer Tabelle durchführen, für die Sie natürliches, Insertion-Order-basiertes Clustering nutzen möchten, sortieren Sie die Daten unbedingt vorab nach dem natürlichen Clustering Key. So sind sowohl die historischen Datensätze als auch die neu eingefügten gut geclustert.
Vorteile
- Kein zusätzlicher Aufwand und keine zusätzlichen Kosten
Nachteile
- Funktioniert nur für Abfragen, die nach einer Spalte filtern, die mit der Einfügereihenfolge korreliert
2. Automatic Clustering Service
Sowohl der Automatic Clustering Service als auch Option 3, manuelles Sortieren, sortieren die Daten einer Tabelle nach einem bestimmten Schlüssel. Die Sortieroperation kostet Rechenleistung – entweder erbringt sie Snowflake über den Automatic Clustering Service, oder Sie führen sie manuell aus. Das folgende Diagramm zeigt das Prinzip an einer Datumsspalte, eine Tabelle lässt sich aber nach jedem beliebigen Ausdruck oder jeder beliebigen Spalte neu clustern.
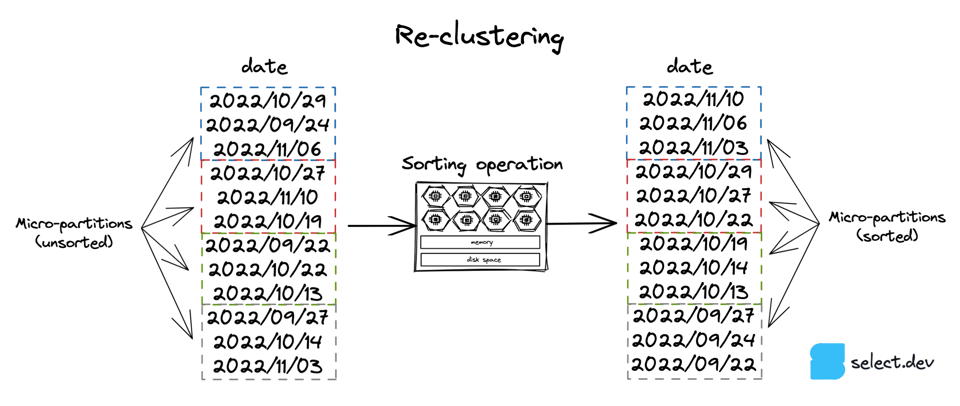
Der Automatic Clustering Service nutzt von Snowflake verwaltete Compute-Ressourcen für die Re-Clustering-Operation. Er läuft nur, wenn für eine Tabelle ein \"Clustering Key\" gesetzt wurde:
1-- you can cluster by one or more comma separated columns alter table my_table cluster by (column_to_cluster_by); -- or you can cluster by an expression alter table my_table cluster by (substring(column_to_cluster_by, 5, 15));
Der Automatic Clustering Service arbeitet im Hintergrund: Er erzeugt und verwirft Micro-Partitions so, dass sie gemäß dem definierten Clustering Key eng begrenzte Wertebereiche enthalten. Abgerechnet wird nach dem geleisteten Arbeitsaufwand – dieser hängt vom Clustering Key, der Tabellengröße und der Änderungshäufigkeit ab. Tabellen, die häufig modifiziert werden (Inserts, Updates, Deletes), verursachen entsprechend höhere Kosten beim Automatic Clustering. Wichtig zu wissen: Beim Re-Clustering nutzt der Service nur die ersten 5 Bytes einer Spalte. Das heißt: Spaltenwerte mit denselben Anfangszeichen lösen kein Re-Clustering aus.
Der Automatic Clustering Service ist einfach zu nutzen – aber auch einfach zu teuer. Wer ihn einsetzt, sollte sowohl die Kosten als auch die Auswirkungen auf die Abfragen genau im Blick behalten, um zu beurteilen, ob das Preis-Leistungs-Verhältnis stimmt. Wer tiefer einsteigen möchte: Dieser ausführliche Beitrag eines Snowflake-Engineers beschreibt die Funktionsweise im Detail.
Vorteile
- Der einfachste Weg, auf einem anderen als dem natürlichen Schlüssel zu clustern.
- Blockiert oder beeinträchtigt keine DML-Operationen.
Nachteile
- Unvorhersehbare Kosten.
- Snowflake erhebt auf Automatic Clustering eine höhere Marge als auf Warehouse-Compute – manuelles Re-Sorting kann dadurch günstiger sein.
3. Manuelles Sortieren
Bei vollständig neu erstellten Tabellen
Wenn eine Tabelle im Rahmen eines Transformations- oder Modellierungsprozesses ohnehin jedes Mal vollständig neu aufgebaut wird, lässt sie sich über ein order by-Statement in der CREATE TABLE AS (CTAS)-Abfrage auf jedem beliebigen Schlüssel perfekt clustern:
1create or replace my_table as ( with transformations as ( ... ) select * from transformations order by my_cluster_key )
In diesem Szenario empfehlen wir grundsätzlich manuelles Sortieren statt des Automatic Clustering Service: Die Tabelle ist genauso gut geclustert, aber zu deutlich geringeren Kosten.
Bei bestehenden Tabellen
Manuelles Re-Sorting einer bestehenden Tabelle nach einem bestimmten Schlüssel ersetzt die Tabelle schlicht durch eine sortierte Version ihrer selbst. Angenommen, wir haben eine Sales-Tabelle mit Einträgen für viele verschiedene Stores, und die meisten Abfragen filtern auf einen bestimmten Store. Mit folgender Abfrage stellen wir sicher, dass die Tabelle auf store_id gut geclustert ist:
1create or replace table sales as ( select * from sales order by store_id )
Kommen mit der Zeit neue Sales hinzu, bleiben die bestehenden Micro-Partitions weiterhin gut nach store_id geclustert – neue Micro-Partitions enthalten dagegen Datensätze für viele verschiedene Stores. Ältere Micro-Partitions prunen also weiterhin gut, neue nicht. Sobald die Performance unter ein akzeptables Niveau fällt, lässt sich die manuelle Re-Sort-Abfrage erneut ausführen, um wieder alle Micro-Partitions sauber auf store_id zu clustern.
Der Vorteil von manuellem Re-Sorting gegenüber dem Automatic Clustering Service: volle Kontrolle darüber, wie oft die Tabelle neu geclustert wird – und damit über die anfallenden Kosten. Die Gefahr dabei: Alle DML-Operationen, die während des create or replace table-Vorgangs auf die Tabelle laufen, gehen verloren. Manuelles Re-Sorting eignet sich daher nur für Tabellen mit vorhersehbaren oder pausierbaren DML-Mustern, bei denen sichergestellt ist, dass während des Re-Sorts keine DML-Operationen ausgeführt werden.
Vorteile
- Volle Kontrolle über den Clustering-Prozess.
- Günstigster Weg, um auf einem beliebigen Schlüssel perfektes Clustering zu erreichen.
Nachteile
- Höherer Aufwand als beim Automatic Clustering Service. Die Sortier-Abfrage muss entweder manuell ausgeführt oder über eine Orchestrierung automatisiert werden.
- Wird eine bestehende Tabelle durch eine sortierte Version ersetzt, gehen alle DML-Operationen verloren, die während des Re-Sorts laufen.
Welche Clustering-Strategie wann?
Setzen Sie wann immer möglich auf natürliches Clustering – per Definition entfällt damit jedes Re-Clustering. Transformationsprozesse mit inkrementeller Datenverarbeitung, die nur neue oder aktualisierte Daten verarbeiten, sollten aus genau diesem Grund immer eine inserted_at- oder updated_at-Spalte führen: Sie sind natürlich geclustert und ermöglichen effizientes Pruning.
Häufig zeigt sich, dass die meisten Abfragen einer Organisation nach denselben Spalten filtern, etwa region oder store_id. Wenn Abfragen mit solchen typischen Filtermustern Full Table Scans verursachen, sollten Sie – abhängig davon, wie die Tabelle befüllt wird – Automatic Clustering oder manuelles Re-Sorting auf der gefilterten Spalte einsetzen. Sind Sie unsicher, wie sich manuelles Re-Sorting umsetzen lässt, oder besteht das Risiko, dass während des Re-Sorts DML-Operationen laufen, greifen Sie zum Automatic Clustering Service.
Gute Kandidaten für Re-Clustering sind außerdem Tabellen, die auf einer Timestamp-Spalte abgefragt werden, die nicht zuverlässig mit dem Einfügezeitpunkt korreliert – natürliches Clustering scheidet hier aus. Ein typisches Beispiel: eine Events-Tabelle, die häufig auf event_created_at oder Ähnliches gefiltert wird, bei der Events aber verspätet eintreffen können, sodass sich die Zeitbereiche der Micro-Partitions überlappen. Ein Re-Clustering auf event_created_at sorgt dafür, dass die Abfragen gut prunen.
Unabhängig vom gewählten Clustering-Ansatz gilt: Sortieren Sie die Daten nach Möglichkeit nach dem gewünschten Clustering Key, bevor Sie sie in die Tabelle einfügen.
Fazit
Pruning entsteht letztlich aus dem Zusammenspiel von durchdachtem Query-Design und gutem Table Clustering. Je mehr Daten, desto wirkungsvoller das Pruning – mit dem Potenzial, die Performance einer Abfrage um Größenordnungen zu verbessern.
In künftigen Beiträgen vertiefen wir das Thema Clustering – unter anderem den Einsatz der Snowflake-Funktion system$clustering_information zur Analyse von Clustering-Statistiken. Wir betrachten außerdem Optionen für Fälle, in denen eine Tabelle auf mehr als einer Spalte gut geclustert sein muss – abonnieren Sie also gerne unten unseren Newsletter. Danke fürs Lesen! Bei Fragen oder zur Vertiefung erreichen Sie uns gerne über Twitter oder per E-Mail.
Niall Woodward · Co-Founder & CTO von SELECT
Niall ist Co-Founder & CTO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT war Niall Data Engineer bei Brooklyn Data Company und mehreren Startups. Als Open-Source-Enthusiast ist er außerdem Maintainer von SQLFluff und Autor von drei dbt-Paketen: dbt_artifacts, dbt_snowflake_monitoring und dbt_query_tags.