Dans notre précédent article sur les micro-partitions, nous avons exploré comment le format de stockage unique de Snowflake permet une optimisation des requêtes appelée pruning. Associer une conception de requêtes soignée à un clustering efficace peut considérablement améliorer le pruning, et donc la vitesse des requêtes. Voyons quand et comment tirer parti de cette puissante fonctionnalité de Snowflake.
Qu'est-ce que le clustering dans Snowflake ?
Le clustering désigne la répartition des données entre les micro-partitions, l'unité de stockage de Snowflake, pour une table donnée. Lorsqu'une table est bien clusterisée, Snowflake peut s'appuyer sur les métadonnées de chaque micro-partition pour réduire au minimum le nombre de fichiers que la requête doit parcourir, ce qui améliore nettement les performances. C'est pourquoi le clustering figure parmi les techniques d'optimisation les plus puissantes à la disposition des utilisateurs de Snowflake pour améliorer les performances et réduire les coûts.
Illustrons ce concept par un exemple.
Exemple d'une table bien clusterisée
Dans le schéma ci-dessous, nous avons une table hypothétique de commandes bien clusterisée sur la colonne created_at, puisque les lignes aux valeurs created_at proches se trouvent dans les mêmes micro-partitions.

Snowflake conserve, pour chaque colonne et chaque micro-partition, les métadonnées de valeur minimale et maximale. Dans cette table, chaque micro-partition contient des enregistrements pour une plage restreinte de valeurs created_at : la table est donc bien clusterisée sur cette colonne. La requête suivante n'analyse que les trois premières micro-partitions mises en évidence, car Snowflake sait qu'il peut ignorer les autres grâce à la clause where et aux métadonnées de valeur minimale et maximale des micro-partitions. Ce comportement s'appelle le query pruning.
1select * from orders where created_at > '2022/08/14'
Sans surprise, analyser seulement trois micro-partitions au lieu de la totalité permet à la requête de s'exécuter beaucoup plus rapidement.
Quand utiliser le clustering ?
La plupart des utilisateurs de Snowflake n'ont pas à se soucier du clustering. Si vos requêtes s'exécutent assez vite et que votre budget reste confortable, ce n'est pas un sujet prioritaire. En revanche, si les performances et/ou les coûts vous importent, le clustering mérite toute votre attention.
Le pruning est sans doute la technique d'optimisation la plus puissante à la disposition des utilisateurs de Snowflake, car réduire le volume de données analysées et traitées est un principe fondamental du traitement big data : la façon la plus rapide de traiter des données ? Ne pas les traiter.
La documentation de Snowflake indique que le clustering n'est utile que pour les tables contenant plusieurs téraoctets (To) de données. D'après notre expérience, il peut toutefois apporter des gains de performance dès quelques centaines de mégaoctets (Mo).
Choisir une clé de clustering
Pour savoir si une table est bien clusterisée au regard des requêtes qui la sollicitent habituellement, il faut d'abord identifier ces schémas de requêtes. La vue access_history de Snowflake offre un moyen simple de retrouver l'historique des requêtes pour une table donnée.
Les clés de filtrage souvent utilisées dans la clause where sont de bons candidats comme clés de clustering. Par exemple :
1select * from table_a where created_at > '2022-09-25'
La requête ci-dessus tirera parti d'une table bien clusterisée sur la colonne created_at : les valeurs proches étant regroupées dans la même micro-partition, seul un petit nombre de micro-partitions sera analysé. Cette décision de pruning est prise par le compilateur de requêtes dans la couche des services cloud, avant l'exécution.
En pratique, nous recommandons de commencer par examiner les requêtes les plus coûteuses de votre compte, qui révéleront sans doute des requêtes ne prunant pas efficacement malgré l'utilisation de filtres. Ce sont autant d'opportunités d'améliorer le clustering des tables.
Comment activer le clustering dans Snowflake ?
Une fois identifiées les colonnes sur lesquelles vous souhaitez clusteriser, il vous faut choisir une méthode de clustering. Nous distinguons trois grandes approches.
1. Clustering naturel
Supposons qu'un processus ETL ajoute chaque heure de nouveaux événements à une table d'événements. Une colonne inserted_at représente l'instant où les événements sont chargés dans la table. Les nouvelles micro-partitions auront chacune une plage très resserrée de valeurs inserted_at. Cette table est dite naturellement clusterisée sur la colonne inserted_at. Une requête qui filtre cette table sur inserted_at prunera efficacement les micro-partitions.
Lorsque vous effectuez un backfill d'une table pour laquelle vous souhaitez exploiter le clustering naturel par ordre d'insertion, pensez à trier d'abord les données selon la clé de clustering naturelle. Ainsi, les enregistrements historiques seront bien clusterisés, tout comme les nouveaux insérés par la suite.
Avantages
- Aucun coût ni effort supplémentaire
Inconvénients
- Ne fonctionne que pour les requêtes qui filtrent sur une colonne corrélée à l'ordre d'insertion des données
2. Service de clustering automatique
Le service de clustering automatique et l'option 3, le tri manuel, consistent à trier les données d'une table selon une clé donnée. L'opération de tri nécessite du calcul, qui peut être effectué soit par Snowflake via le service de clustering automatique, soit manuellement. Le schéma ci-dessous prend une colonne de date pour l'illustration, mais une table peut être reclusterisée selon n'importe quelle expression ou colonne.
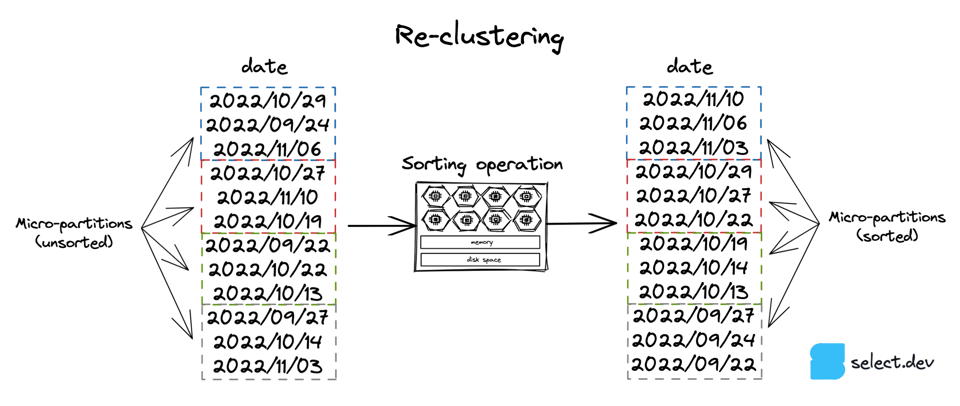
Le service de clustering automatique utilise des ressources de calcul gérées par Snowflake pour effectuer le reclustering. Ce service ne s'exécute que si une clustering key a été définie pour une table :
1-- you can cluster by one or more comma separated columns alter table my_table cluster by (column_to_cluster_by); -- or you can cluster by an expression alter table my_table cluster by (substring(column_to_cluster_by, 5, 15));
Le service de clustering automatique travaille en arrière-plan pour créer et supprimer des micro-partitions afin qu'elles contiennent des plages de valeurs bien resserrées selon la clé de clustering spécifiée. Il est facturé en fonction du travail effectué par Snowflake, qui dépend de la clé de clustering, de la taille de la table et de la fréquence à laquelle son contenu est modifié. Par conséquent, les tables fréquemment modifiées (inserts, updates, deletes) entraîneront des coûts de clustering automatique plus élevés. À noter que le service de clustering automatique n'utilise que les 5 premiers octets d'une colonne lors du reclustering. Autrement dit, des valeurs de colonne partageant les mêmes premiers caractères ne déclencheront aucun reclustering.
Le service de clustering automatique est simple à utiliser, mais il peut vite faire grimper la facture. Si vous y recourez, surveillez attentivement le coût et l'impact sur les requêtes de la table afin de vérifier que le rapport prix/performance reste intéressant. Pour aller plus loin sur le service de clustering automatique, consultez cet article détaillé sur son fonctionnement interne, rédigé par l'un des ingénieurs de Snowflake.
Avantages
- La méthode la moins coûteuse en effort pour clusteriser sur une clé différente de la clé naturelle.
- Ne bloque pas et n'interfère pas avec les opérations DML.
Inconvénients
- Coûts imprévisibles.
- Snowflake applique une marge plus élevée sur le clustering automatique que sur le compute des warehouses, ce qui peut le rendre moins rentable que le tri manuel.
3. Tri manuel
Sur des tables intégralement recréées
Si une table est toujours intégralement recréée dans le cadre d'un processus de transformation ou de modélisation, elle peut être parfaitement clusterisée sur n'importe quelle clé en ajoutant une instruction order by à la requête create table as (CTAS) :
1create or replace my_table as ( with transformations as ( ... ) select * from transformations order by my_cluster_key )
Dans ce cas de figure d'une table toujours intégralement recréée, nous recommandons systématiquement le tri manuel plutôt que le service de clustering automatique : la table sera parfaitement clusterisée, pour un coût bien inférieur.
Sur des tables existantes
Trier manuellement une table existante selon une clé donnée revient simplement à remplacer la table par une version triée d'elle-même. Supposons que nous ayons une table sales contenant des entrées pour de nombreux magasins, et que la plupart des requêtes filtrent toujours sur un magasin précis. Nous pouvons exécuter la requête suivante pour garantir que la table est bien clusterisée sur store_id :
1create or replace table sales as ( select * from sales order by store_id )
À mesure que de nouvelles ventes seront ajoutées à la table, les micro-partitions existantes resteront bien clusterisées par store_id, mais les nouvelles contiendront des enregistrements pour de nombreux magasins différents. Autrement dit, les anciennes micro-partitions seront bien prunées, mais pas les nouvelles. Dès que les performances passent sous un seuil acceptable, il suffit de relancer la requête de tri manuel pour que toutes les micro-partitions soient à nouveau bien clusterisées sur store_id.
L'avantage du tri manuel par rapport au service de clustering automatique réside dans le contrôle total sur la fréquence de reclustering de la table et sur la dépense associée. Le revers de la médaille : toute opération DML effectuée sur la table pendant l'exécution du create or replace table sera annulée. Le tri manuel ne doit donc être utilisé que sur des tables aux schémas DML prévisibles ou pouvant être mis en pause, lorsque vous êtes certain qu'aucune opération DML ne s'exécutera pendant le tri.
Avantages
- Offre un contrôle total sur le processus de clustering.
- La méthode la moins coûteuse pour obtenir un clustering parfait sur n'importe quelle clé.
Inconvénients
- Effort plus important qu'avec le service de clustering automatique. L'utilisateur doit soit exécuter manuellement la requête de tri, soit mettre en place une orchestration automatisée.
- Remplacer une table existante par une version triée d'elle-même annule toute opération DML exécutée pendant le tri.
Quelle stratégie de clustering choisir, et quand ?
Privilégiez toujours le clustering naturel : par définition, il ne nécessite aucun reclustering. Les processus de transformation qui s'appuient sur un traitement incrémental pour ne traiter que les données nouvelles ou mises à jour devraient toujours ajouter une colonne inserted_at ou updated_at pour cette raison : naturellement clusterisées, elles permettent un pruning efficace.
On constate fréquemment que la plupart des requêtes d'une organisation filtrent sur les mêmes colonnes, comme region ou store_id. Si des requêtes aux schémas de filtrage communs provoquent des full scans de table, envisagez, selon le mode de remplissage de la table, le clustering automatique ou le tri manuel sur la colonne filtrée. Si vous ne savez pas comment mettre en place le tri manuel, ou s'il existe un risque que des opérations DML s'exécutent pendant le tri, optez pour le service de clustering automatique.
Autres bons candidats au reclustering : les tables interrogées sur une colonne timestamp qui ne correspond pas toujours à la date d'insertion des données — le clustering naturel n'est alors pas exploitable. C'est par exemple le cas d'une table d'événements souvent interrogée sur event_created_at ou similaire, mais où des événements peuvent arriver tardivement, ce qui fait se chevaucher les plages temporelles des micro-partitions. Reclusteriser la table sur event_created_at garantira un pruning efficace des requêtes.
Quelle que soit l'approche retenue, il est toujours judicieux de trier les données selon la clé de clustering souhaitée avant de les insérer dans la table.
Pour conclure
En définitive, le pruning repose sur la complémentarité entre la conception des requêtes et le clustering des tables. Plus le volume de données est important, plus le pruning gagne en puissance, avec un potentiel de gain de performance de plusieurs ordres de grandeur sur une requête.
Nous approfondirons le sujet du clustering dans de prochains articles, notamment l'usage de la fonction system$clustering_information de Snowflake pour analyser les statistiques de clustering. Nous explorerons aussi les options à privilégier lorsqu'une table doit être bien clusterisée sur plusieurs colonnes — pensez à vous abonner à notre newsletter ci-dessous. Merci pour votre lecture ; n'hésitez pas à nous contacter sur Twitter ou par email, nous serons ravis de répondre à vos questions ou d'approfondir ces sujets avec vous.
Niall Woodward·Co-fondateur et CTO de SELECT
Niall est Co-fondateur et CTO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Niall était data engineer chez Brooklyn Data Company et dans plusieurs startups. Passionné d'open source, il est également mainteneur de SQLFluff et créateur de trois packages dbt : dbt_artifacts, dbt_snowflake_monitoring et dbt_query_tags.