No nosso post anterior sobre micro-partitions, mostramos como o formato de armazenamento único do Snowflake viabiliza uma otimização de queries chamada pruning. Combinar o design das queries com um clustering eficaz pode melhorar drasticamente o pruning e, consequentemente, a velocidade das queries. Vamos ver como e quando vale a pena aproveitar esse recurso poderoso do Snowflake.
O que é clustering no Snowflake?
Clustering é a forma como os dados de uma tabela se distribuem pelas micro-partitions, a unidade de armazenamento do Snowflake. Quando uma tabela está bem clusterizada, o Snowflake usa os metadados de cada micro-partition para reduzir ao mínimo o número de arquivos que a query precisa varrer, melhorando muito o desempenho. Por isso, o clustering é uma das técnicas de otimização mais poderosas à disposição dos usuários do Snowflake para melhorar o desempenho e reduzir custos.
Vamos ilustrar esse conceito com um exemplo.
Exemplo de uma tabela bem clusterizada
No diagrama abaixo, temos uma tabela hipotética de pedidos bem clusterizada na coluna created_at, já que linhas com valores parecidos de created_at ficam nas mesmas micro-partitions.

O Snowflake mantém metadados de valor mínimo e máximo para cada coluna em cada micro-partition. Nesta tabela, cada micro-partition contém registros dentro de uma faixa estreita de valores de created_at, então a tabela está bem clusterizada nessa coluna. A query a seguir varre apenas as três primeiras micro-partitions destacadas, porque o Snowflake sabe que pode ignorar as demais com base na cláusula where e nos metadados de valor mínimo e máximo das micro-partitions. Esse comportamento é o chamado query pruning.
1select * from orders where created_at > '2022/08/14'
Não é surpresa que varrer só três micro-partitions em vez de todas faz a query rodar bem mais rápido.
Quando usar clustering?
A maioria dos usuários do Snowflake não precisa se preocupar com clustering. Se suas queries rodam rápido o suficiente e você está tranquilo dentro do orçamento, não vale a pena perder tempo com isso. Mas, se desempenho e/ou custo importam para você, então clustering também importa.
O pruning é, sem dúvida, a técnica de otimização mais poderosa à disposição dos usuários do Snowflake, já que reduzir o volume de dados varridos e processados é um princípio fundamental no processamento de big data: "Qual é a forma mais rápida de processar dados? Não processar."
A documentação do Snowflake sugere que o clustering só compensa para tabelas com "múltiplos terabytes (TB) de dados". Na nossa experiência, porém, o clustering já traz ganhos de desempenho em tabelas a partir de centenas de megabytes (MB).
Como escolher uma clustering key
Para saber se uma tabela está bem clusterizada para as queries típicas que rodam nela, antes você precisa conhecer esses padrões de query. A view access_history do Snowflake é uma forma prática de recuperar o histórico de queries de uma determinada tabela.
Chaves usadas com frequência para filtrar em cláusulas where costumam ser boas candidatas a clustering keys. Por exemplo:
1select * from table_a where created_at > '2022-09-25'
A query acima se beneficia de uma tabela bem clusterizada na coluna created_at, pois valores parecidos ficariam contidos na mesma micro-partition, e só um pequeno número delas precisaria ser varrido. Essa decisão de pruning é feita pelo compilador de queries na camada de serviços de nuvem, antes da execução começar.
Na prática, recomendamos começar analisando as queries mais caras da sua conta, que provavelmente vão revelar queries com pruning ineficaz de micro-partitions apesar de usarem filtros. Essas são oportunidades claras para melhorar o clustering das tabelas.
Como habilitar o clustering no Snowflake?
Depois de definir em quais colunas você quer clusterizar, é hora de escolher o método. Gostamos de dividir as opções em três.
1. Clustering natural
Imagine que existe um processo de ETL inserindo novos eventos em uma tabela de eventos a cada hora. Uma coluna inserted_at representa o momento em que os eventos são carregados na tabela. Cada nova micro-partition criada terá uma faixa estreita de valores de inserted_at. Essa tabela de eventos é o que chamamos de tabela naturalmente clusterizada na coluna inserted_at. Uma query que filtra essa tabela pela coluna inserted_at vai fazer pruning das micro-partitions com eficácia.
Ao fazer o backfill de uma tabela na qual você quer aproveitar o clustering natural por ordem de inserção, lembre-se de ordenar os dados pela chave de clustering natural antes. Assim, tanto os registros históricos quanto os novos inseridos ficam bem clusterizados.
Prós
- Não exige gasto nem esforço adicional
Contras
- Só funciona para queries que filtram por uma coluna correlacionada à ordem de inserção dos dados
2. Serviço de clustering automático
O serviço de clustering automático e a opção 3, ordenação manual, consistem em ordenar os dados de uma tabela por uma chave específica. A operação de ordenação exige computação, que pode ser feita pelo Snowflake com o serviço de clustering automático ou manualmente. O diagrama abaixo usa uma coluna de data para ilustrar, mas uma tabela pode ser reclusterizada por qualquer expressão/coluna.
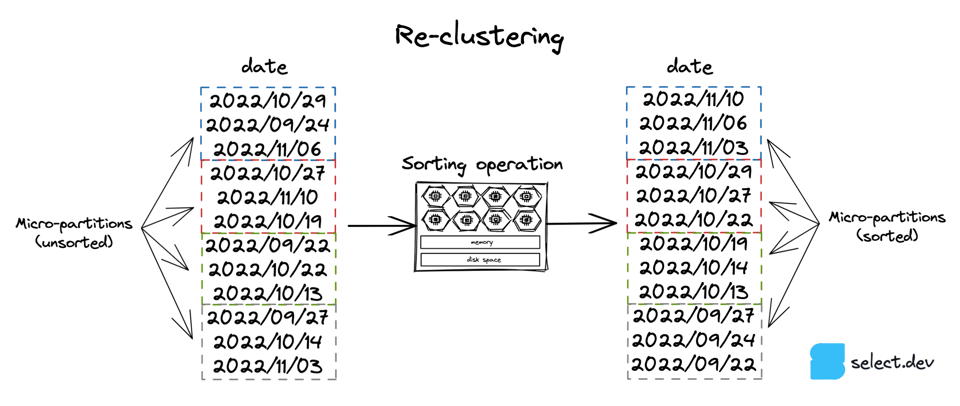
O serviço de clustering automático usa recursos de computação gerenciados pelo Snowflake para executar a operação de re-clustering. Esse serviço só roda se uma "clustering key" tiver sido definida para a tabela:
1-- you can cluster by one or more comma separated columns alter table my_table cluster by (column_to_cluster_by); -- or you can cluster by an expression alter table my_table cluster by (substring(column_to_cluster_by, 5, 15));
O serviço de clustering automático trabalha em segundo plano criando e destruindo micro-partitions para que cada uma contenha faixas estreitas de registros conforme a clustering key definida. A cobrança é feita pela quantidade de trabalho que o Snowflake executa, o que depende da clustering key, do tamanho da tabela e da frequência com que o conteúdo é modificado. Por isso, tabelas modificadas com frequência (inserts, updates, deletes) geram custos maiores de clustering automático. Vale notar que o serviço de clustering automático usa apenas os primeiros 5 bytes de uma coluna ao executar o re-clustering. Ou seja, valores de coluna com os mesmos primeiros caracteres não vão acionar nenhum re-clustering.
O serviço de clustering automático é simples de usar, mas também é fácil de torrar dinheiro com ele. Se optar por usá-lo, acompanhe tanto o custo quanto o impacto nas queries da tabela para avaliar se a relação preço/desempenho está boa. Se quiser se aprofundar no serviço de clustering automático, confira este post detalhado sobre o funcionamento interno, escrito por um dos engenheiros do Snowflake.
Prós
- A forma de menor esforço para clusterizar por uma chave diferente da natural.
- Não bloqueia nem interfere em operações DML.
Contras
- Custos imprevisíveis.
- O Snowflake aplica uma margem maior no clustering automático do que nos custos de computação de warehouse, o que pode tornar o clustering automático menos vantajoso em termos de custo do que a reordenação manual.
3. Ordenação manual
Em tabelas totalmente recriadas
Se uma tabela é sempre totalmente recriada como parte de um processo de transformação/modelagem, ela pode ficar perfeitamente clusterizada em qualquer chave bastando adicionar uma cláusula order by à query create table as (CTAS):
1create or replace my_table as ( with transformations as ( ... ) select * from transformations order by my_cluster_key )
Nesse cenário em que a tabela é sempre totalmente recriada, recomendamos sempre usar a ordenação manual no lugar do serviço de clustering automático: a tabela ficará bem clusterizada e o custo será muito menor do que o do serviço de clustering automático.
Em tabelas existentes
Reordenar manualmente uma tabela existente por uma chave específica simplesmente substitui a tabela por uma versão ordenada dela mesma. Vamos supor que temos uma tabela de vendas com registros de várias lojas diferentes, e a maioria das queries nessa tabela sempre filtra por uma loja específica. Podemos rodar a query abaixo para garantir que a tabela fique bem clusterizada por store_id:
1create or replace table sales as ( select * from sales order by store_id )
Conforme novas vendas são inseridas na tabela ao longo do tempo, as micro-partitions existentes continuam bem clusterizadas por store_id, mas as novas micro-partitions vão conter registros de várias lojas diferentes. Ou seja, as micro-partitions mais antigas fazem pruning bem, mas as novas não. Quando o desempenho cair abaixo de níveis aceitáveis, basta rodar a query de reordenação manual de novo para garantir que todas as micro-partitions voltem a ficar bem clusterizadas por store_id.
A vantagem da reordenação manual em relação ao serviço de clustering automático é ter controle total sobre a frequência com que a tabela é reclusterizada e o gasto associado. Por outro lado, o risco dessa abordagem é que quaisquer operações DML que ocorrerem na tabela enquanto a operação create or replace table estiver rodando serão desfeitas. A reordenação manual só deve ser usada em tabelas com padrões de DML previsíveis ou que podem ser pausados, em que você tenha certeza de que nenhuma operação DML vai rodar durante a reordenação.
Prós
- Oferece controle total sobre o processo de clustering.
- Forma mais barata de obter clustering perfeito em qualquer chave.
Contras
- Exige mais esforço do que o serviço de clustering automático. Cabe ao usuário executar a query de ordenação manualmente ou implementar uma orquestração automatizada para isso.
- Substituir uma tabela existente por uma versão ordenada dela mesma reverte quaisquer operações DML que rodem durante a reordenação.
Qual estratégia de clustering usar e quando?
Sempre que possível, aposte no clustering natural — por definição, ele não exige re-clustering da tabela. Processos de transformação que usam processamento incremental para tratar apenas dados novos/atualizados devem sempre adicionar uma coluna inserted_at ou updated_at justamente por isso: essas colunas ficam naturalmente clusterizadas e geram pruning eficiente.
É comum notar que a maioria das queries de uma organização filtra pelas mesmas colunas, como region ou store_id. Se queries com padrões de filtragem comuns estão provocando full table scans, então, dependendo de como a tabela é carregada, considere usar o clustering automático ou a reordenação manual para clusterizar pela coluna filtrada. Se você não tem certeza de como implementaria a reordenação manual ou existe risco de operações DML rodarem durante a reordenação, use o serviço de clustering automático.
Outras boas candidatas a re-clustering são tabelas consultadas por uma coluna de timestamp que nem sempre se correlaciona com o momento em que os dados foram inseridos, o que impede usar o clustering natural. Um exemplo é uma tabela de eventos consultada com frequência por event_created_at ou similar, em que eventos podem chegar atrasados e, por isso, as micro-partitions acabam tendo sobreposição de intervalos de tempo. Reclusterizar a tabela por event_created_at garante que as queries façam pruning de forma eficiente.
Independentemente da abordagem de clustering escolhida, é sempre uma boa ideia ordenar os dados pela clustering key desejada antes de inseri-los na tabela.
Encerrando
No fim das contas, o pruning é fruto da combinação entre design das queries e clustering das tabelas. Quanto maior o volume de dados, mais poderoso é o pruning, com potencial de melhorar o desempenho de uma query em ordens de magnitude.
Vamos nos aprofundar no tema de clustering em posts futuros, incluindo o uso da função system$clustering_information do Snowflake para analisar estatísticas de clustering. Também vamos explorar opções para quando uma tabela precisa ficar bem clusterizada em mais de uma coluna, então não deixe de assinar nossa newsletter abaixo. Obrigado pela leitura — fale com a gente pelo Twitter ou por e-mail, vai ser um prazer responder dúvidas ou discutir esses temas em mais detalhes.
Niall Woodward·Co-founder & CTO da SELECT
Niall é Co-Founder & CTO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Niall atuou como data engineer na Brooklyn Data Company e em várias startups. Entusiasta de open-source, ele também é mantenedor do SQLFluff e criador de três pacotes dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.