En nuestro post anterior sobre micro-partitions, vimos cómo el formato de almacenamiento único de Snowflake habilita una optimización de queries llamada pruning. Combinar un buen diseño de queries con un clustering efectivo puede mejorar drásticamente el pruning y, por lo tanto, la velocidad de las queries. Veamos cómo y cuándo conviene aprovechar esta poderosa función de Snowflake.
¿Qué es el clustering en Snowflake?
El clustering describe cómo se distribuyen los datos de una tabla entre las micro-partitions, que son la unidad de almacenamiento en Snowflake. Cuando una tabla está bien clusterizada, Snowflake aprovecha los metadatos de cada micro-partition para reducir al mínimo la cantidad de archivos que debe escanear la query, lo que mejora muchísimo el rendimiento. Por eso, el clustering es una de las técnicas de optimización más potentes que tienen a su alcance los usuarios de Snowflake para mejorar el rendimiento y reducir costos.
Veamos este concepto con un ejemplo.
Ejemplo de una tabla bien clusterizada
En el diagrama de abajo tenemos una tabla hipotética de órdenes bien clusterizada por la columna created_at, ya que las filas con valores similares de created_at se ubican en las mismas micro-partitions.

Snowflake guarda los metadatos de valor mínimo y máximo para cada columna en cada micro-partition. En esta tabla, cada micro-partition contiene registros con un rango acotado de valores de created_at, así que la tabla está bien clusterizada por esa columna. La siguiente query solo escanea las tres primeras micro-partitions resaltadas, porque Snowflake sabe que puede ignorar el resto a partir de la cláusula where y de los metadatos de valor mínimo y máximo de cada micro-partition. A este comportamiento se le llama query pruning.
1select * from orders where created_at > '2022/08/14'
Como era de esperarse, escanear solo tres micro-partitions en lugar de todas hace que la query corra considerablemente más rápido.
¿Cuándo conviene usar clustering?
La mayoría de los usuarios de Snowflake no necesita preocuparse por el clustering. Si tus queries corren lo suficientemente rápido y estás cómodo dentro del presupuesto, no vale la pena darle vueltas. Pero si te importan el rendimiento y/o el costo, sin duda deberías prestarle atención al clustering.
El pruning es posiblemente la técnica de optimización más potente que tienen a su disposición los usuarios de Snowflake, ya que reducir la cantidad de datos que se escanean y procesan es un principio fundamental en el procesamiento de big data: "¿La forma más rápida de procesar datos? No procesarlos."
La documentación de Snowflake sugiere que el clustering solo conviene en tablas que contengan "varios terabytes (TB) de datos". Sin embargo, según nuestra experiencia, el clustering puede aportar mejoras de rendimiento incluso en tablas a partir de cientos de megabytes (MB).
Cómo elegir una clustering key
Para saber si una tabla está bien clusterizada para las queries típicas que se ejecutan sobre ella, primero hay que conocer esos patrones de consulta. La vista access_history de Snowflake ofrece una forma sencilla de recuperar el historial de queries de una tabla determinada.
Las claves de filtrado que se usan con frecuencia en cláusulas where son buenas candidatas para clustering keys. Por ejemplo:
1select * from table_a where created_at > '2022-09-25'
La query anterior se beneficia de una tabla bien clusterizada por la columna created_at, ya que los valores similares quedarían contenidos en la misma micro-partition y solo se escanearía un pequeño número de micro-partitions. Esta decisión de pruning se toma en el compilador de queries de la capa de cloud services, antes de que comience la ejecución.
En la práctica, recomendamos empezar por explorar las queries más costosas de tu cuenta, lo que probablemente saque a la luz queries con pruning ineficaz a pesar de usar filtros. Allí están las oportunidades para mejorar el clustering de tus tablas.
¿Cómo habilitar el clustering en Snowflake?
Una vez que sepas por qué columnas quieres clusterizar, tendrás que elegir un método de clustering. Nos gusta agrupar las opciones en tres.
1. Clustering natural
Supongamos que hay un proceso ETL que agrega nuevos eventos a una tabla de eventos cada hora. Una columna inserted_at representa el momento en que los eventos se cargan en la tabla. Cada nueva micro-partition tendrá un rango acotado de valores de inserted_at. Diríamos que esta tabla de eventos está naturalmente clusterizada por la columna inserted_at. Una query que filtre esta tabla por la columna inserted_at va a hacer pruning de las micro-partitions de manera efectiva.
Cuando hagas un backfill de una tabla en la que quieras aprovechar el clustering natural por orden de inserción, asegúrate de ordenar primero los datos por la clave de clustering natural. Así, tanto los registros históricos como los nuevos que se inserten quedarán bien clusterizados.
Ventajas
- No implica gasto ni esfuerzo adicional.
Desventajas
- Solo funciona con queries que filtran por una columna correlacionada con el orden en que se insertan los datos.
2. Servicio de clustering automático
Tanto el servicio de clustering automático como la opción 3, el ordenamiento manual, implican ordenar los datos de una tabla por una clave determinada. La operación de ordenamiento requiere cómputo, que puede ejecutar Snowflake mediante el servicio de clustering automático o hacerlo tú manualmente. El diagrama de abajo lo ilustra con una columna de fecha, pero una tabla se puede re-clusterizar por cualquier expresión o columna.
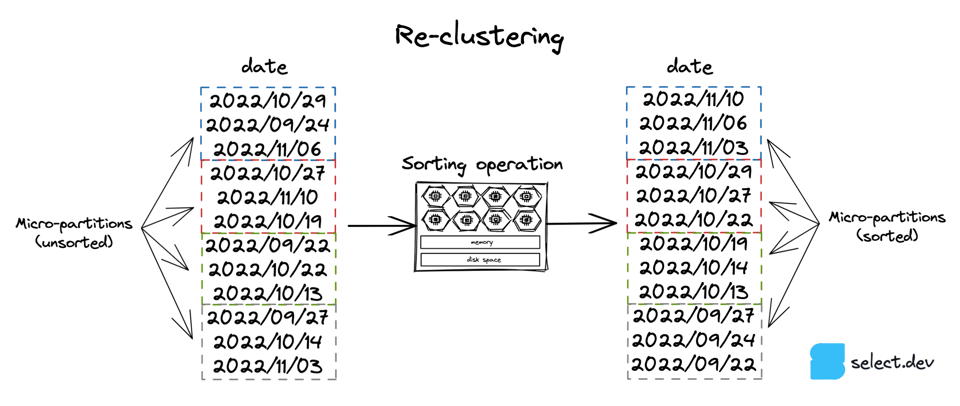
El servicio de clustering automático usa recursos de cómputo gestionados por Snowflake para realizar la operación de re-clustering. Este servicio solo se ejecuta si se definió una 'clustering key' para la tabla:
1-- you can cluster by one or more comma separated columns alter table my_table cluster by (column_to_cluster_by); -- or you can cluster by an expression alter table my_table cluster by (substring(column_to_cluster_by, 5, 15));
El servicio de clustering automático trabaja en segundo plano creando y destruyendo micro-partitions para que contengan rangos acotados de registros según la clustering key especificada. Se cobra en función de cuánto trabajo realice Snowflake, lo que depende de la clustering key, del tamaño de la tabla y de la frecuencia con que se modifica su contenido. Por eso, las tablas que se modifican con frecuencia (inserts, updates, deletes) tendrán costos de clustering automático más altos. Conviene mencionar que el servicio de clustering automático solo usa los primeros 5 bytes de una columna al hacer el re-clustering. Esto significa que los valores de una columna que compartan los primeros caracteres no harán que el servicio ejecute ningún re-clustering.
El servicio de clustering automático es simple de usar, pero también es fácil que se vaya de presupuesto. Si decides usarlo, asegúrate de monitorear tanto el costo como el impacto en las queries de la tabla para saber si la relación precio/rendimiento es buena. Si quieres conocer más sobre el servicio de clustering automático, echa un vistazo a este post detallado sobre su funcionamiento interno, escrito por uno de los engineers de Snowflake.
Ventajas
- Es la forma con menos esfuerzo de clusterizar por una clave distinta a la natural.
- No bloquea ni interfiere con operaciones DML.
Desventajas
- Costos impredecibles.
- Snowflake aplica un margen más alto al clustering automático que al cómputo del warehouse, por lo que puede resultar menos rentable que el re-ordenamiento manual.
3. Ordenamiento manual
Con tablas que se recrean por completo
Si una tabla siempre se recrea por completo como parte de un proceso de transformación/modelado, se la puede clusterizar de manera perfecta por cualquier clave agregando una sentencia order by a la query create table as (CTAS):
1create or replace my_table as ( with transformations as ( ... ) select * from transformations order by my_cluster_key )
En este escenario, en el que la tabla siempre se recrea por completo, recomendamos usar siempre el ordenamiento manual en lugar del servicio de clustering automático: la tabla queda bien clusterizada y a un costo mucho menor.
En tablas existentes
Re-ordenar manualmente una tabla existente por una clave determinada consiste, simplemente, en reemplazar la tabla por una versión ordenada de sí misma. Supongamos que tenemos una tabla de ventas con entradas de muchas tiendas distintas, y que la mayoría de las queries siempre filtran por una tienda específica. Podemos ejecutar la siguiente query para asegurarnos de que la tabla quede bien clusterizada por store_id:
1create or replace table sales as ( select * from sales order by store_id )
A medida que se agreguen nuevas ventas a la tabla con el tiempo, las micro-partitions existentes seguirán bien clusterizadas por store_id, pero las nuevas contendrán registros de muchas tiendas distintas. Eso significa que las micro-partitions más antiguas harán un buen pruning, pero las nuevas no. Cuando el rendimiento caiga por debajo de niveles aceptables, se puede volver a ejecutar la query de re-ordenamiento manual para que todas las micro-partitions queden bien clusterizadas por store_id.
La ventaja del re-ordenamiento manual frente al servicio de clustering automático es el control total sobre la frecuencia con la que se re-clusteriza la tabla y sobre el gasto asociado. Sin embargo, el riesgo de este enfoque es que cualquier operación DML que ocurra sobre la tabla mientras se ejecuta la operación create or replace table quedará deshecha. El re-ordenamiento manual solo debería usarse en tablas con patrones DML predecibles o que se puedan pausar, donde tengas la certeza de que no se ejecutarán operaciones DML mientras se realiza el re-ordenamiento.
Ventajas
- Brinda control total sobre el proceso de clustering.
- Es la forma más económica de lograr un clustering perfecto por cualquier clave.
Desventajas
- Requiere más esfuerzo que el servicio de clustering automático. El usuario tiene que ejecutar manualmente la query de ordenamiento o implementar una orquestación automatizada para hacerlo.
- Reemplazar una tabla existente por una versión ordenada de sí misma revierte cualquier operación DML que se ejecute durante el re-ordenamiento.
¿Qué estrategia de clustering deberías usar y cuándo?
Siempre conviene apuntar al clustering natural, ya que por definición no requiere re-clusterizar la tabla. Los procesos de transformación que usan procesamiento incremental para tratar solo datos nuevos o actualizados deberían incluir siempre una columna inserted_at o updated_at por este motivo: quedarán naturalmente clusterizadas y permitirán un pruning eficiente.
Es común que la mayoría de las queries de una organización filtren por las mismas columnas, como region o store_id. Si las queries con patrones de filtrado comunes están provocando escaneos completos de la tabla, considera usar clustering automático o re-ordenamiento manual para clusterizar por la columna que se filtra, según cómo se pueble la tabla. Si no tienes claro cómo implementar el re-ordenamiento manual o existe el riesgo de que se ejecuten operaciones DML durante el mismo, usa el servicio de clustering automático.
Otras buenas candidatas para el re-clustering son las tablas que se consultan por una columna timestamp que no siempre coincide con el momento en que se insertaron los datos, por lo que no se puede usar el clustering natural. Un ejemplo es una tabla de eventos que se consulta con frecuencia por event_created_at o similar, pero los eventos pueden llegar tarde y, por eso, las micro-partitions tienen rangos de tiempo superpuestos. Re-clusterizar la tabla por event_created_at hará que las queries hagan un buen pruning.
Sea cual sea el enfoque de clustering elegido, siempre es buena idea ordenar los datos por la clustering key deseada antes de insertarlos en la tabla.
Cierre
En definitiva, el pruning se consigue combinando un buen diseño de queries con un buen clustering de tablas. Cuantos más datos haya, más potente es el pruning, con el potencial de mejorar el rendimiento de una query en órdenes de magnitud.
Profundizaremos en el tema del clustering en próximos posts, incluyendo el uso de la función system$clustering_information de Snowflake para analizar estadísticas de clustering. También exploraremos las opciones para cuando una tabla necesita estar bien clusterizada por más de una columna, así que no dejes de suscribirte a nuestra lista de correo más abajo. Gracias por leer y, por favor, ponte en contacto vía Twitter o email: con gusto responderemos preguntas o conversaremos sobre estos temas con más detalle.
Niall Woodward·Co-founder & CTO de SELECT
Niall es Co-Founder & CTO de SELECT, una plataforma SaaS de gestión y optimización de costos de Snowflake. Antes de fundar SELECT, Niall fue data engineer en Brooklyn Data Company y en varias startups. Como entusiasta del open-source, también es maintainer de SQLFluff y creador de tres paquetes de dbt: dbt_artifacts, dbt_snowflake_monitoring y dbt_query_tags.