前回のマイクロパーティションに関する記事では、Snowflake独自のストレージ形式が「プルーニング」と呼ばれるクエリ最適化をどのように可能にしているかを掘り下げました。クエリ設計と効果的なクラスタリングを組み合わせれば、プルーニングが効きやすくなり、結果としてクエリ速度を大きく改善できます。本記事では、この強力なSnowflake機能をいつ、どう活用すべきかを解説します。
Snowflakeのクラスタリングとは
クラスタリングとは、あるテーブルのデータがSnowflakeのストレージ単位であるマイクロパーティションにどのように分散されているかを指す概念です。テーブルが適切にクラスタリングされていれば、Snowflakeは各マイクロパーティションのメタデータを活用してクエリがスキャンするファイル数を最小限に抑えられ、クエリ性能が大幅に向上します。この仕組みから、クラスタリングはSnowflakeユーザーがパフォーマンスを高め、コストを削減するうえで最も強力な最適化手法のひとつとされています。
具体例で見ていきましょう。
適切にクラスタリングされたテーブルの例
下図は、created_at列で適切にクラスタリングされた仮想のordersテーブルです。created_atの値が近い行が同じマイクロパーティションにまとまっているのがわかります。

Snowflakeはマイクロパーティションごとに各列の最小値・最大値のメタデータを保持しています。このテーブルでは、各マイクロパーティションが狭い範囲のcreated_at値のレコードのみを含んでいるため、当該列で適切にクラスタリングされていると言えます。次のクエリは、ハイライトされた最初の3つのマイクロパーティションのみをスキャンします。Snowflakeはwhere句と最小値・最大値のメタデータから、それ以外を無視してよいと判断できるためです。この挙動をクエリプルーニングと呼びます。
1select * from orders where created_at > '2022/08/14'
言うまでもなく、すべてではなく3つだけをスキャンすれば済むため、クエリは格段に速く実行されます。
クラスタリングを検討すべきタイミング
多くのSnowflakeユーザーにとって、クラスタリングは必ずしも考慮すべき要素ではありません。クエリが十分速く、予算にも余裕があるのなら、わざわざ手をつける必要はないでしょう。しかし、パフォーマンスやコストを重視するのであれば、クラスタリングは間違いなく押さえておくべきテーマです。
プルーニングはSnowflakeユーザーが使える最強の最適化手法と言っても過言ではありません。スキャン・処理するデータ量を減らすことは、ビッグデータ処理の根本原則だからです。「データを処理する最速の方法は? 処理しないことだ」というわけです。
Snowflakeの公式ドキュメントでは、クラスタリングが有効なのは「数テラバイト(TB)規模のデータを持つ」テーブルだけだとされています。しかし私たちの経験上、数百メガバイト(MB)規模のテーブルでもクラスタリングの効果が表れることがあります。
クラスタリングキーの選び方
あるテーブルが、よく実行されるクエリに対して適切にクラスタリングされているかを判断するには、まずそのクエリパターンを把握する必要があります。Snowflakeのaccess_historyビューを使えば、特定のテーブルに対する過去のクエリを簡単に取得できます。
where句で頻繁にフィルタ条件として使われる列は、クラスタリングキーの有力候補です。たとえば次のクエリを見てみましょう。
1select * from table_a where created_at > '2022-09-25'
このクエリは、created_at列で適切にクラスタリングされたテーブルから恩恵を受けます。近い値が同じマイクロパーティションにまとまっているため、スキャン対象のマイクロパーティション数を少なく抑えられるからです。このプルーニング判定は、実行に先立ちクラウドサービス層のクエリコンパイラによって行われます。
実務では、まずアカウント内で最もコストのかかるクエリから調べることをお勧めします。フィルタを使っているのにマイクロパーティションを十分にプルーニングできていないクエリが見つかる可能性が高く、テーブルクラスタリングを改善する糸口になります。
Snowflakeでクラスタリングを有効化する方法
クラスタリングする列が決まったら、次はクラスタリング手法を選びます。私たちは選択肢を次の3つに分類しています。
1. 自然クラスタリング(Natural clustering)
1時間ごとに新しいイベントをイベントテーブルへ追加するETLプロセスを考えてみましょう。inserted_at列は、イベントがテーブルにロードされた時刻を表します。新しく作成されるマイクロパーティションは、それぞれ狭い範囲のinserted_at値しか含みません。このイベントテーブルはinserted_at列で自然にクラスタリングされている、と表現できます。inserted_at列でフィルタするクエリは、マイクロパーティションを効果的にプルーニングできます。
挿入順による自然クラスタリングを活用したいテーブルでバックフィルを行う場合は、まず自然クラスタリングキーでデータをソートしてから投入してください。そうすれば、過去のレコードも新規挿入分と同様に適切にクラスタリングされた状態を保てます。
メリット
- 追加コストも追加作業も不要
デメリット
- データの挿入順と相関する列でフィルタするクエリにしか効果がない
2. 自動クラスタリングサービス
自動クラスタリングサービスと、3つ目の手動ソートは、いずれも特定のキーでテーブルデータをソートする方法です。ソート処理には計算リソースが必要で、自動クラスタリングサービスを使えばSnowflakeに任せられますし、手動で実行することもできます。下図では日付列を例にしていますが、テーブルは任意の式や列で再クラスタリングできます。
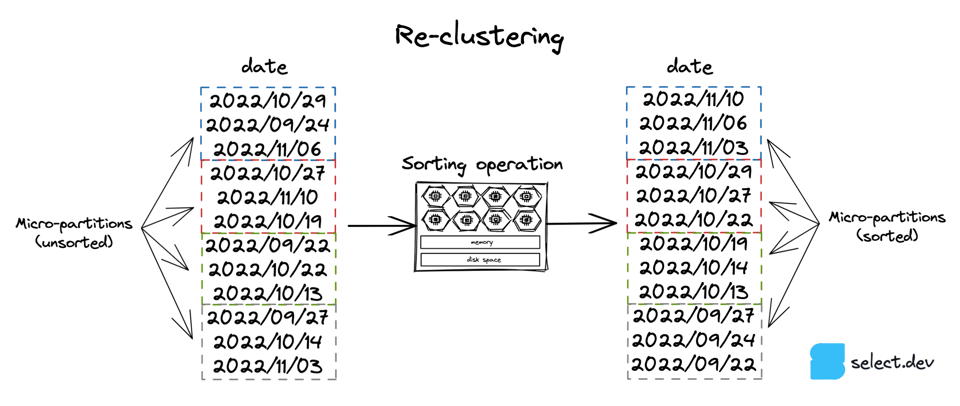
自動クラスタリングサービスは、Snowflake管理下のコンピュートリソースで再クラスタリング処理を行います。このサービスは、テーブルに「クラスタリングキー」が設定されている場合にのみ動作します。
1-- you can cluster by one or more comma separated columns alter table my_table cluster by (column_to_cluster_by); -- or you can cluster by an expression alter table my_table cluster by (substring(column_to_cluster_by, 5, 15));
自動クラスタリングサービスはバックグラウンドで動作し、指定したクラスタリングキーに基づいて、各マイクロパーティションが狭い範囲のレコードを含むようにマイクロパーティションを作成・破棄します。このサービスはSnowflakeが行う作業量に応じて課金され、その量はクラスタリングキー、テーブルサイズ、内容の変更頻度によって決まります。つまり、頻繁に変更(挿入・更新・削除)されるテーブルほど自動クラスタリングのコストは高くなります。なお、自動クラスタリングサービスは再クラスタリング時に列値の先頭5バイトしか使用しません。そのため、先頭数文字が同じ値ばかりの列では、サービスは再クラスタリングを行いません。
自動クラスタリングサービスは使い方こそ簡単ですが、コストが膨らみやすい面もあります。導入する場合は、コストとクエリへの影響の両方をモニタリングし、コストパフォーマンスが見合っているかを確認してください。自動クラスタリングサービスについて詳しく知りたい方は、Snowflakeのエンジニアによる内部動作の解説記事もぜひご覧ください。
メリット
- 自然キー以外のキーでクラスタリングするうえで、最も手間のかからない方法
- DML操作をブロックしたり妨げたりしない
デメリット
- コストが読みにくい
- 自動クラスタリングはウェアハウスのコンピュートよりもSnowflakeのマージンが高く、手動再ソートよりコスト効率が悪くなることがある
3. 手動ソート
毎回完全に作り直すテーブルの場合
変換・モデリング処理の一環としてテーブルを毎回完全に作り直しているなら、CTAS(create table as)クエリにorder byを加えるだけで、任意のキーで完璧にクラスタリングできます。
1create or replace my_table as ( with transformations as ( ... ) select * from transformations order by my_cluster_key )
テーブルが常に完全再作成されるこのようなケースでは、自動クラスタリングサービスより手動ソートを使うことを強くお勧めします。テーブルが適切にクラスタリングされるうえに、自動クラスタリングサービスよりはるかに低コストで実現できるためです。
既存テーブルに適用する場合
既存テーブルを特定のキーで手動再ソートするというのは、要するにテーブルをソート済みバージョンで上書きすることです。たとえば、多数の店舗のレコードを持つsalesテーブルがあり、ほとんどのクエリが特定店舗で絞り込んでいるとします。次のクエリを実行すれば、テーブルをstore_idで適切にクラスタリングされた状態にできます。
1create or replace table sales as ( select * from sales order by store_id )
時間の経過とともに新しい売上が追加されていくと、既存のマイクロパーティションはstore_idで適切にクラスタリングされた状態を保ちますが、新しいマイクロパーティションには多数の店舗のレコードが混在することになります。つまり、古いマイクロパーティションではプルーニングがよく効くものの、新しいマイクロパーティションでは効きが悪くなります。性能が許容範囲を下回ったタイミングで再度手動再ソートクエリを実行すれば、すべてのマイクロパーティションをstore_idで適切にクラスタリングされた状態に戻せます。
手動再ソートが自動クラスタリングサービスより優れている点は、再クラスタリングの頻度と関連コストを完全にコントロールできることです。一方で注意点もあります。create or replace table処理の実行中にテーブルへ行われたDML操作は、すべて巻き戻されてしまいます。手動再ソートは、DMLパターンが予測可能、あるいは一時停止可能で、再ソート中にDMLが走らないと確信できるテーブルに対してのみ使うべきです。
メリット
- クラスタリングプロセスを完全にコントロールできる
- 任意のキーで完璧なクラスタリングを最も低コストで実現できる
デメリット
- 自動クラスタリングサービスより手間がかかる。ソートクエリを手動実行するか、自動オーケストレーションを構築する必要がある
- 既存テーブルをソート済みバージョンで上書きすると、再ソート中に実行されたDML操作が巻き戻る
どのクラスタリング戦略を、いつ選ぶべきか
まずは自然クラスタリングを活かせないかを常に検討しましょう。定義上、再クラスタリングが一切不要だからです。新規・更新データだけを処理するインクリメンタルな変換プロセスでは、inserted_atやupdated_at列を必ず追加することをお勧めします。これらの列は自然にクラスタリングされ、効率的なプルーニングをもたらします。
多くの組織では、ほとんどのクエリがregionやstore_idといった同じ列でフィルタしているのがよく見られます。こうした共通のフィルタパターンを持つクエリがフルテーブルスキャンを引き起こしている場合は、テーブルの投入方法に応じて、自動クラスタリングか手動再ソートで該当列をクラスタリングすることを検討してください。手動再ソートの実装方法に不安がある場合や、再ソート中にDMLが走るリスクがある場合は、自動クラスタリングサービスを選びましょう。
再クラスタリングが有効なもうひとつのケースは、タイムスタンプ列でクエリされるものの、その列がデータの挿入時刻と必ずしも一致しないテーブルです。自然クラスタリングが使えないこのパターンの例として、event_created_atなどで頻繁にクエリされるイベントテーブルが挙げられます。イベントが遅れて到着することがあるため、マイクロパーティションの時間範囲が重なってしまうのです。この場合、event_created_atで再クラスタリングすれば、クエリのプルーニングが効くようになります。
どのクラスタリング手法を選ぶにせよ、テーブルにデータを挿入する前に、目的のクラスタリングキーでデータをソートしておくのは常に良い習慣です。
おわりに
結局のところ、プルーニングはクエリ設計とテーブルクラスタリングが噛み合ってはじめて実現します。データが大きいほどプルーニングの効果は増し、クエリ性能を桁違いに改善できる可能性があります。
クラスタリングについては今後の記事でさらに掘り下げていきます。Snowflakeのsystem$clustering_information関数を使ったクラスタリング統計の分析方法や、複数列で適切にクラスタリングしたい場合の選択肢なども取り上げる予定です。ぜひ下記のメーリングリストにご登録ください。お読みいただきありがとうございました。ご質問やこれらのトピックについて詳しく議論したい方は、お気軽にTwitterまたはメールでご連絡ください。
Niall Woodward·Co-founder & CTO of SELECT
Niallは、Snowflakeのコスト管理・最適化SaaSプラットフォームであるSELECTの共同創業者兼CTOです。SELECTを立ち上げる前は、Brooklyn Data Companyや複数のスタートアップでデータエンジニアとして活動していました。オープンソースの愛好家でもあり、SQLFluffのメンテナーを務めるほか、dbt_artifacts、dbt_snowflake_monitoring、dbt_query_tagsという3つのdbtパッケージの作者でもあります。