Nel nostro articolo precedente sulle micro-partizioni abbiamo visto come il formato di archiviazione di Snowflake abiliti un'ottimizzazione delle query chiamata pruning. Unire la progettazione delle query a un clustering efficace può migliorare in modo significativo il pruning e, di conseguenza, la velocità di esecuzione. Vediamo come e quando sfruttare questa potente funzionalità di Snowflake.
Cos'è il clustering in Snowflake?
Il clustering descrive come i dati di una tabella sono distribuiti tra le micro-partizioni, l'unità di archiviazione di Snowflake. Quando una tabella è ben clusterizzata, Snowflake può sfruttare i metadati di ogni micro-partizione per ridurre al minimo il numero di file da scansionare, migliorando sensibilmente le prestazioni delle query. Per questo motivo, il clustering è una delle tecniche di ottimizzazione più potenti a disposizione degli utenti Snowflake per migliorare le prestazioni e ridurre i costi.
Vediamo il concetto con un esempio.
Esempio di tabella ben clusterizzata
Nel diagramma qui sotto abbiamo un'ipotetica tabella degli ordini ben clusterizzata sulla colonna created_at: le righe con valori created_at simili si trovano nelle stesse micro-partizioni.

Snowflake conserva i metadati relativi ai valori minimo e massimo di ogni colonna in ciascuna micro-partizione. In questa tabella ogni micro-partizione contiene record che ricadono in un intervallo ristretto di valori created_at: la tabella è quindi ben clusterizzata su quella colonna. La query seguente scansiona solo le prime tre micro-partizioni evidenziate, perché Snowflake sa di poter ignorare le altre grazie alla clausola where e ai metadati di valore minimo e massimo delle micro-partizioni. Questo comportamento prende il nome di query pruning.
1select * from orders where created_at > '2022/08/14'
Com'era prevedibile, scansionare solo tre micro-partizioni anziché tutte rende la query molto più rapida.
Quando conviene usare il clustering?
La maggior parte degli utenti Snowflake non ha bisogno di occuparsi del clustering. Se le query sono già abbastanza veloci e il budget è ampiamente sotto controllo, non vale la pena pensarci. Ma se prestazioni e/o costi sono una priorità, allora il clustering deve interessarvi eccome.
Il pruning è probabilmente la tecnica di ottimizzazione più potente a disposizione degli utenti Snowflake, perché ridurre la quantità di dati scansionati ed elaborati è un principio fondamentale dell'elaborazione di big data: "Qual è il modo più veloce per elaborare i dati? Non elaborarli."
La documentazione di Snowflake suggerisce che il clustering è utile solo per tabelle che contengono "diversi terabyte (TB) di dati". La nostra esperienza, però, ci dice che il clustering può portare benefici prestazionali già su tabelle di qualche centinaio di megabyte (MB).
Come scegliere una clustering key
Per capire se una tabella è ben clusterizzata rispetto alle query tipiche che la interrogano, bisogna prima conoscere questi pattern di query. La vista access_history di Snowflake offre un modo semplice per recuperare lo storico delle query su una determinata tabella.
Le chiavi usate spesso nei filtri della clausola where sono buone candidate come clustering key. Ad esempio:
1select * from table_a where created_at > '2022-09-25'
La query qui sopra trae vantaggio da una tabella ben clusterizzata sulla colonna created_at, perché i valori simili si trovano nella stessa micro-partizione e quindi vengono scansionate solo poche micro-partizioni. Questa decisione di pruning viene presa dal query compiler nel cloud services layer, prima dell'esecuzione.
In pratica, consigliamo di partire analizzando le query più costose del proprio account: emergeranno probabilmente query che, pur usando filtri, effettuano il pruning delle micro-partizioni in modo inefficace. Sono proprio queste le opportunità per migliorare il clustering delle tabelle.
Come abilitare il clustering in Snowflake?
Una volta individuate le colonne su cui clusterizzare, occorre scegliere il metodo. Le opzioni possono essere raggruppate in tre categorie.
1. Clustering naturale
Supponiamo di avere un processo ETL che aggiunge nuovi eventi a una tabella ogni ora. Una colonna inserted_at rappresenta il momento in cui gli eventi vengono caricati nella tabella. Le nuove micro-partizioni create avranno ciascuna un intervallo ristretto di valori inserted_at. Questa tabella eventi può quindi essere definita naturalmente clusterizzata sulla colonna inserted_at. Una query che filtra la tabella sulla colonna inserted_at effettuerà il pruning delle micro-partizioni in modo efficace.
Quando si effettua un backfill di una tabella su cui si vuole sfruttare il clustering naturale per ordine di inserimento, è importante ordinare prima i dati in base alla chiave di clustering naturale. In questo modo saranno ben clusterizzati sia i record storici sia quelli inseriti successivamente.
Pro
- Nessun costo o sforzo aggiuntivo
Contro
- Funziona solo per query che filtrano su una colonna correlata all'ordine di inserimento dei dati
2. Servizio di clustering automatico
Il servizio di clustering automatico e l'opzione 3, l'ordinamento manuale, prevedono entrambi l'ordinamento dei dati di una tabella in base a una chiave specifica. L'ordinamento richiede capacità di calcolo, che può essere fornita da Snowflake tramite il servizio di clustering automatico oppure gestita manualmente. Il diagramma sotto utilizza una colonna data come esempio, ma una tabella può essere ri-clusterizzata in base a qualsiasi espressione o colonna.
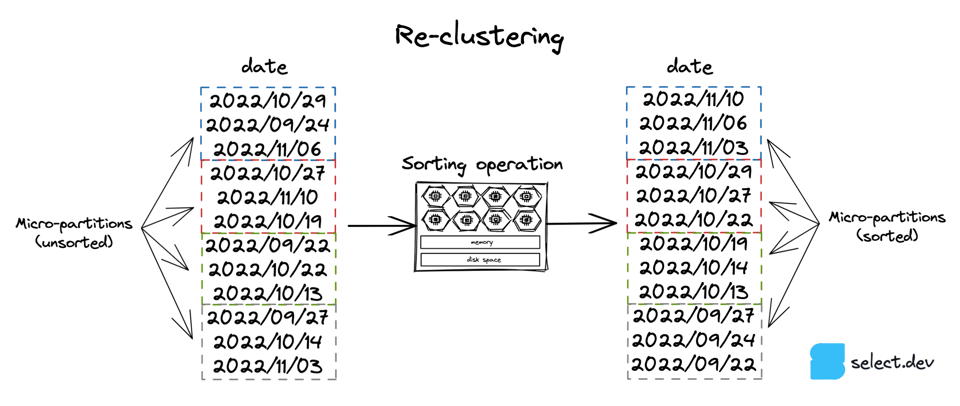
Il servizio di clustering automatico utilizza risorse di calcolo gestite da Snowflake per eseguire l'operazione di re-clustering. Si attiva solo se è stata impostata una "clustering key" sulla tabella:
1-- you can cluster by one or more comma separated columns alter table my_table cluster by (column_to_cluster_by); -- or you can cluster by an expression alter table my_table cluster by (substring(column_to_cluster_by, 5, 15));
Il servizio di clustering automatico lavora in background creando ed eliminando micro-partizioni affinché contengano intervalli ristretti di record in base alla clustering key specificata. Il costo del servizio dipende dalla quantità di lavoro svolto da Snowflake, che a sua volta dipende dalla clustering key, dalla dimensione della tabella e dalla frequenza con cui ne viene modificato il contenuto. Di conseguenza, le tabelle modificate spesso (insert, update, delete) generano costi di clustering automatico più elevati. Va inoltre ricordato che il servizio di clustering automatico utilizza solo i primi 5 byte di una colonna durante il re-clustering: i valori che condividono gli stessi primi caratteri non innescheranno alcun re-clustering.
Il servizio di clustering automatico è semplice da usare, ma è altrettanto facile spendere parecchio. Se decidete di adottarlo, monitorate sia i costi sia l'impatto sulle query della tabella, per verificare che il rapporto prezzo/prestazioni sia soddisfacente. Per approfondire il funzionamento del servizio di clustering automatico, date un'occhiata a questo articolo dettagliato scritto da uno degli ingegneri di Snowflake.
Pro
- Il modo più immediato per clusterizzare su una chiave diversa da quella naturale.
- Non blocca né interferisce con le operazioni DML.
Contro
- Costi imprevedibili.
- Snowflake applica un margine più alto sul clustering automatico rispetto ai costi di compute dei warehouse, e questo può rendere il clustering automatico meno conveniente del re-sorting manuale.
3. Ordinamento manuale
Con tabelle ricreate da zero
Se una tabella viene sempre ricreata interamente all'interno di un processo di trasformazione/modellazione, è possibile ottenere un clustering perfetto su qualsiasi chiave aggiungendo un'istruzione order by alla query di create table as (CTAS):
1create or replace my_table as ( with transformations as ( ... ) select * from transformations order by my_cluster_key )
In questo scenario, in cui la tabella viene sempre ricreata da zero, consigliamo l'ordinamento manuale rispetto al servizio di clustering automatico: la tabella risulterà ben clusterizzata e a un costo molto inferiore.
Su tabelle esistenti
Riordinare manualmente una tabella esistente su una determinata chiave significa semplicemente sostituirla con una sua versione ordinata. Supponiamo di avere una tabella delle vendite con record relativi a molti negozi diversi e che la maggior parte delle query filtri sempre per uno specifico negozio. Possiamo eseguire la query seguente per garantire che la tabella sia ben clusterizzata su store_id:
1create or replace table sales as ( select * from sales order by store_id )
Man mano che con il tempo si aggiungono nuove vendite, le micro-partizioni esistenti resteranno ben clusterizzate per store_id, mentre quelle nuove conterranno record di molti negozi diversi. Le micro-partizioni più vecchie effettueranno quindi un buon pruning, mentre quelle nuove no. Quando le prestazioni scenderanno sotto livelli accettabili, basterà rieseguire la query di re-sorting manuale per riportare tutte le micro-partizioni a un buon clustering su store_id.
Il vantaggio del re-sorting manuale rispetto al servizio di clustering automatico è il controllo totale sulla frequenza del re-clustering e sulla spesa associata. Il rischio di questo approccio, però, è che qualsiasi operazione DML eseguita sulla tabella durante il create or replace table venga annullata. Il re-sorting manuale andrebbe usato solo su tabelle con pattern DML prevedibili o sospendibili, in cui si ha la certezza che nessuna operazione DML venga eseguita durante il riordinamento.
Pro
- Offre il controllo totale sul processo di clustering.
- È il modo più economico per ottenere un clustering perfetto su qualsiasi chiave.
Contro
- Richiede più impegno rispetto al servizio di clustering automatico. L'utente deve eseguire manualmente la query di ordinamento oppure implementarne un'orchestrazione automatizzata.
- Sostituire una tabella esistente con una sua versione ordinata annulla qualsiasi operazione DML eseguita durante il re-sorting.
Quale strategia di clustering scegliere e quando?
Puntate sempre a sfruttare il clustering naturale, perché per definizione non richiede alcun re-clustering della tabella. Proprio per questo motivo i processi di trasformazione che usano l'elaborazione incrementale per processare solo dati nuovi o aggiornati dovrebbero sempre aggiungere una colonna inserted_at o updated_at: saranno naturalmente clusterizzate e produrranno un pruning efficiente.
Capita spesso che la maggior parte delle query di un'organizzazione filtri sulle stesse colonne, come region o store_id. Se query con pattern di filtraggio ricorrenti causano scansioni complete delle tabelle, valutate, in base al modo in cui la tabella viene popolata, l'uso del clustering automatico o del re-sorting manuale per clusterizzare sulla colonna filtrata. Se non sapete come implementare il re-sorting manuale o se c'è il rischio che vengano eseguite operazioni DML durante il riordinamento, usate il servizio di clustering automatico.
Altri buoni candidati al re-clustering sono le tabelle interrogate su una colonna timestamp che non corrisponde sempre al momento di inserimento dei dati, dove quindi non è possibile sfruttare il clustering naturale. Un esempio è una tabella eventi interrogata spesso su event_created_at o simili, in cui gli eventi possono arrivare in ritardo e gli intervalli temporali delle micro-partizioni si sovrappongono. Effettuare il re-clustering della tabella su event_created_at garantirà un pruning efficace.
Qualunque sia l'approccio di clustering scelto, è sempre una buona idea ordinare i dati in base alla clustering key desiderata prima di inserirli nella tabella.
Conclusione
In definitiva, il pruning si ottiene combinando una buona progettazione delle query con un clustering efficace delle tabelle. Più cresce il volume dei dati, più diventa potente il pruning, con la possibilità di migliorare le prestazioni di una query di diversi ordini di grandezza.
Approfondiremo il tema del clustering nei prossimi articoli, incluso l'uso della funzione system$clustering_information di Snowflake per analizzare le statistiche di clustering. Vedremo anche le opzioni disponibili quando una tabella deve essere ben clusterizzata su più colonne: iscrivetevi quindi alla nostra mailing list qui sotto. Grazie per la lettura e non esitate a contattarci su Twitter o via email: saremo felici di rispondere alle vostre domande o di approfondire questi argomenti.
Niall Woodward·Co-founder & CTO di SELECT
Niall è Co-Founder e CTO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, è stato data engineer presso Brooklyn Data Company e diverse startup. Appassionato di open-source, è anche maintainer di SQLFluff e creatore di tre pacchetti dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.