Dank seines einzigartigen Speicherformats lassen sich Daten in Snowflake besonders effizient und kostengünstig ablegen. Bei den meisten Snowflake-Kunden machen die Speicherkosten in der Regel weniger als 20 % der Gesamtausgaben aus. Trotzdem gibt es häufig erhebliches Optimierungspotenzial, um unnötigen Verbrauch zu reduzieren.
In diesem Beitrag schauen wir uns die Kostenstruktur und Preisgestaltung des Snowflake-Speichers an, beleuchten Optimierungstechniken und zeigen, wie sich Kosten überwachen lassen. Nicht behandeln wir Snowflakes External Tables, mit denen sich Daten außerhalb von Snowflake speichern und abfragen lassen.
Snowflake-Architektur im Überblick
Wie in unserem früheren Beitrag zur Snowflake-Architektur beschrieben, verwaltet und skaliert Snowflake Speicher- und Compute-Ressourcen unabhängig voneinander.
Alle Tabellen im Storage Layer nutzen Snowflakes proprietäres Micro-Partition-Dateiformat. Micro-Partitions sind kleine, unveränderliche Datendateien (<16 MB komprimiert), deren Metadaten im Header abgelegt sind. Da diese Dateien unveränderlich sind, erfordert das Aktualisieren einer einzelnen Zeile in einer Micro-Partition das Anlegen einer komplett neuen Micro-Partition. Geschieht das häufig und in großem Umfang, kann das spürbare Kostenfolgen haben – mehr dazu später im Beitrag.
Während Compute und Storage meist die meiste Aufmerksamkeit bekommen, spielt auch der Cloud-Services-Layer eine zentrale Rolle: Er verwaltet die Metadaten zu jeder Tabelle und ermöglicht damit Storage-Features wie Time Travel, Fail-Safe und Zero-Copy Cloning.
Snowflake-Speicherkonzepte
Wie bereits im aktuellen Beitrag zu Snowflake-Merges erläutert, hat die Entkopplung von Storage und Cloud Services in Snowflake das Konzept der Table Version erst möglich gemacht. Das bedeutet: Jede Tabelle ist definiert durch einen zugehörigen Erstellungszeitstempel, eine Menge verknüpfter Micro-Partitions sowie vorab berechnete Statistiken zu jeder Micro-Partition. Eine Tabelle lässt sich also als Sammlung von Metadaten-Pointern verstehen, die sie definieren.
Die folgende Grafik veranschaulicht dieses Konzept. Sie zeigt die Verknüpfungen zwischen Tabellen und den physischen Daten (Micro-Partitions). Tabelle A und Tabelle B (ein Klon von A) teilen sich exakt dieselben Partitionen. Tabelle C, ebenfalls ein Klon, teilt sich dieselben Micro-Partitions plus eine neue, die durch eine Datenänderung (z. B. das Einfügen neuer Datensätze) entstanden ist.
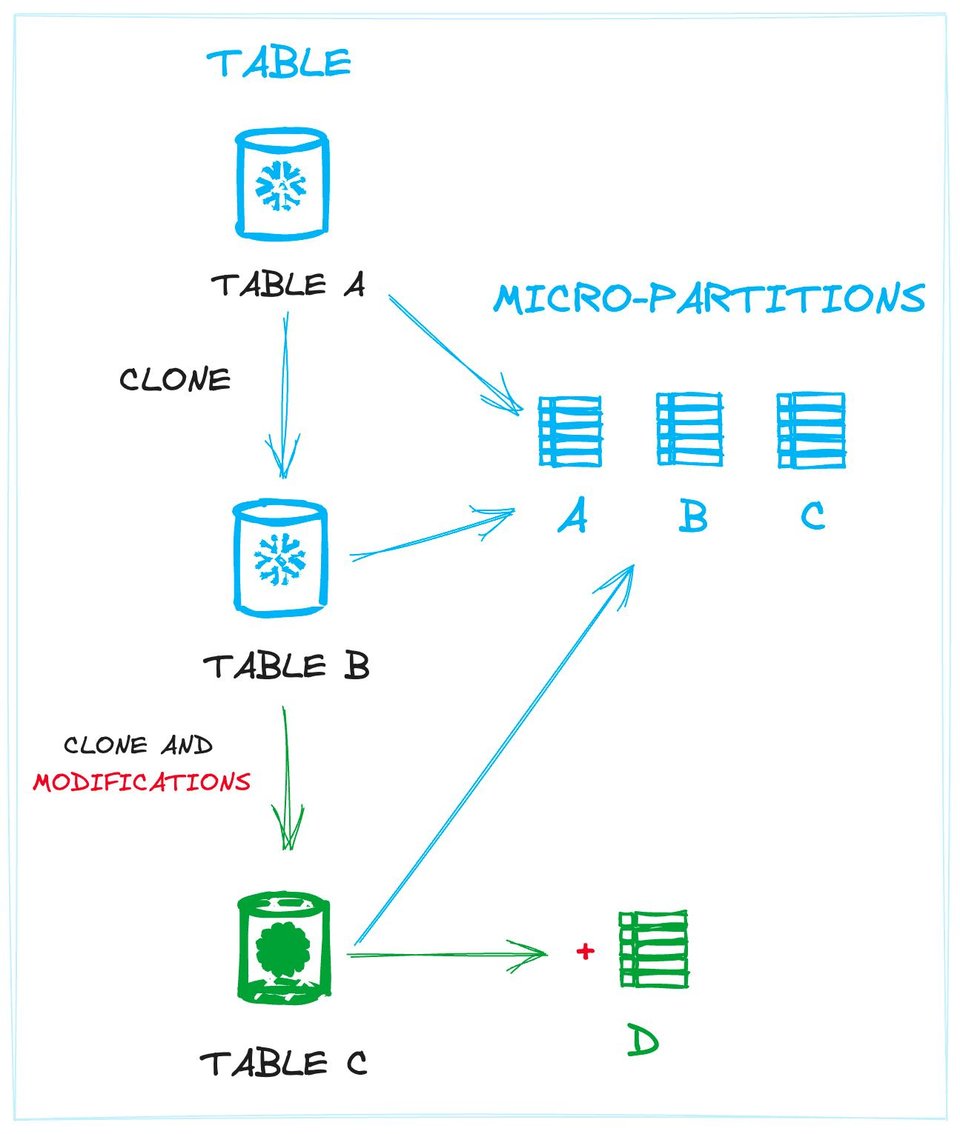
Indem Tabellen als Sammlung von Micro-Partitions definiert werden, vermeidet Snowflake unnötige Operationen auf der Festplatte: Neue Tabellen können – wo immer möglich – auf bereits vorhandene Micro-Partitions verweisen. Diese Entkopplung erlaubt es, mehrere eigenständige Tabellen anzulegen, die sich denselben Satz physischer Dateien teilen – genau das passiert beim Zero-Copy Cloning.
Die Speicherstruktur von Snowflake bildet die Grundlage für eine Reihe von Continuous Data Protection-Funktionen (CDP), die für alle Kunden verfügbar sind. CDP umfasst Time Travel, Fail-Safe und Zero-Copy Cloning – schauen wir uns das im Detail an.
Time Travel
Time Travel, auch als "Data Retention" bezeichnet, schützt die Daten der Nutzer. Die Hauptfunktion: Daten – genauer gesagt Micro-Partitions – werden für einen definierten Zeitraum gesichert. Als Nebeneffekt lässt sich damit in die Vergangenheit "reisen", um Objekte mit den Daten eines bestimmten Zeitpunkts abzufragen, neu zu erstellen oder ein versehentliches Drop rückgängig zu machen.
Time Travel ist standardmäßig auf 1 Tag eingestellt und für alle Kunden unabhängig von der Snowflake Edition verfügbar. In der Snowflake Standard Edition lässt sich Time Travel auf 0 setzen (deaktiviert) oder beim Standard von 1 Tag belassen. In der Snowflake Enterprise Edition kann der Retention-Zeitraum für permanente Objekte auf bis zu 90 Tage erweitert werden. Transient- und temporäre Tabellen sind für alle Kunden auf 1 Tag begrenzt.
Time Travel lässt sich über den Parameter DATA_RETENTION_TIME_IN_DAYS konfigurieren. Mehr dazu weiter unten im Optimierungsabschnitt.
Tabellen zu einem bestimmten Zeitpunkt abfragen
AT OR BEFORE ist eine Syntax-Abstraktion, mit der sich in die Vergangenheit "reisen" und Daten so wiederherstellen lassen, wie sie zu einem bestimmten Zeitpunkt vorlagen. Es gibt zahlreiche Optionen, um den historischen Zeitpunkt zu bestimmen – ein Blick in die offizielle Doku lohnt sich, um diese Operatoren korrekt einzusetzen. Hier ein Beispiel-Query:
select
user_name,
feature_enabled_status
from users at(timestamp => 'Fri, 01 May 2023 17:20:00 -0700'::timestamp)
where
user_id = 5
;
Eine versehentlich gelöschte Tabelle wiederherstellen
Mit Time Travel wird das versehentliche Droppen einer wichtigen Tabelle, eines Schemas oder einer Datenbank vom Data-Engineering-Albtraum zur Lappalie. Solange das Objekt noch im Retention-Zeitraum liegt, lässt es sich problemlos wiederherstellen. Hier finden Sie Details zu dieser Funktion – und hier ein kurzes Beispiel, wie sich eine versehentlich gelöschte users-Tabelle wiederherstellen lässt:
1undrop table db.analytics.users
Time Travel konfigurieren
Time Travel lässt sich auf verschiedenen Ebenen konfigurieren – Account, Datenbank, Schema oder Tabelle. Dabei gilt eine hierarchische Verschachtelung: Wird Time Travel auf Tabellenebene definiert, hat das Vorrang vor allen Einstellungen auf Schema-, Datenbank- oder Account-Ebene.
Das Time-Travel-Verhalten wird über den Parameter DATA_RETENTION_TIME_IN_DAYS gesteuert. Um die eigenen Einstellungen zu verstehen, sollten Sie zunächst die Standardwerte auf Account-, Datenbank- und Schemaebene kennen.
1show parameters like '%DATA_RETENTION_TIME_IN_DAYS%' in {account, database, schema, table}
Probieren wir es aus und konfigurieren die Retention in unserem Projekt:
-- global config, account level
alter account set data_retention_time_in_days = 0;
-- unless stated downstream (schema or table),
-- all tables in the dbs have 1-day window
create or replace database staging_db data_retention_time_in_days=1;
use database staging_db;
-- unless stated downstream (table),
-- time travel is disabled for the tables in the schema
create or replace schema staging_schema data_retention_time_in_days=0;
use schema staging_schema;
-- create a table with time-travel of 1 day
create table test_table_zero (
Code ausklappen
Wie gesagt: Explizit schlägt implizit. Wer Time Travel für ein bestimmtes Objekt steuern möchte, setzt den Parameter im Create-Statement – ansonsten genügt die globale Konfiguration.
Fail-Safe
Fail-Safe-Storage ist die letzte Verteidigungslinie. Nur Snowflake selbst hat darauf Zugriff, und greift erst nach Ablauf des Retention-Zeitraums. Es ist der letzte Zeitpunkt, bevor die Daten endgültig entfernt werden und nicht mehr zugänglich sind. Fail-Safe ist nicht konfigurierbar und dauert 7 Tage – außer bei transienten oder temporären Tabellen, bei denen Fail-Safe gar nicht greift.
Fail-Safe ist als allerletztes Mittel gedacht. Laut Snowflake-Dokumentation:
Fail-Safe ist nicht dafür gedacht, nach Ablauf des Time-Travel-Retention-Zeitraums auf historische Daten zuzugreifen. Es dient ausschließlich Snowflake selbst dazu, Daten wiederherzustellen, die aufgrund extremer Betriebsausfälle verloren gegangen oder beschädigt sein könnten.
Zero-Copy Cloning
Zero-Copy Cloning erlaubt es, in Sekunden eine Kopie eines Objekts zu erstellen – unabhängig von dessen Größe. Eine Tabelle in Snowflake zu klonen, ist keine Operation, bei der eine Datenbankdatei angelegt und neue Daten auf Disk geschrieben werden. Stattdessen handelt es sich lediglich um eine Metadaten-Operation in den Cloud Services, die ein neues Objekt mit Pointern auf die bestehenden Micro-Partitions der geklonten Tabelle definiert.
Direkt nach dem Klonen einer Tabelle fallen keine zusätzlichen Speicherkosten an, weil sowohl die Original- als auch die geklonte Tabelle auf exakt denselben Satz Micro-Partitions verweisen. Werden jedoch alle Datensätze der Originaltabelle aktualisiert, verdoppeln sich die Speicherkosten: Die geklonte Tabelle verweist weiterhin auf die alten (gerade aktualisierten) Micro-Partition-Dateien und sorgt dafür, dass diese erhalten bleiben – und somit Speicherkosten verursachen.
Der Lebenszyklus einer Tabelle in Snowflake
Nachdem wir wichtige Speicherkonzepte wie Time Travel und Fail-Safe vorgestellt haben, schauen wir uns nun an, wie eine permanente Tabelle den Standard-Lebenszyklus durchläuft – mit besonderem Blick auf die verschiedenen Time-Travel- und Fail-Safe-Zeiträume.
Die folgende Grafik zeigt diesen Prozess. Wir betrachten eine permanente Tabelle mit 10 TB Daten, aktiviertem Time Travel von 1 Tag (Default) und 7-tägigem Fail-Safe. Dargestellt ist ein Zeitraum von 10 Tagen – inklusive der Speichermengen, die pro Tag abgerechnet werden.
An Tag 1 wird eine Operation ausgeführt, die jeden Datensatz in der Tabelle aktualisiert – effektiv wird damit jede Micro-Partition neu erzeugt. Die kompletten 10 TB der alten Micro-Partitions wandern in den "Time Travel"-Storage, wo Nutzer für die nächsten 24 Stunden noch auf die Daten zugreifen können.
Am nächsten Tag verlassen die 10 TB Time Travel und liegen nun für die nächsten 7 Tage im Fail-Safe-Storage.
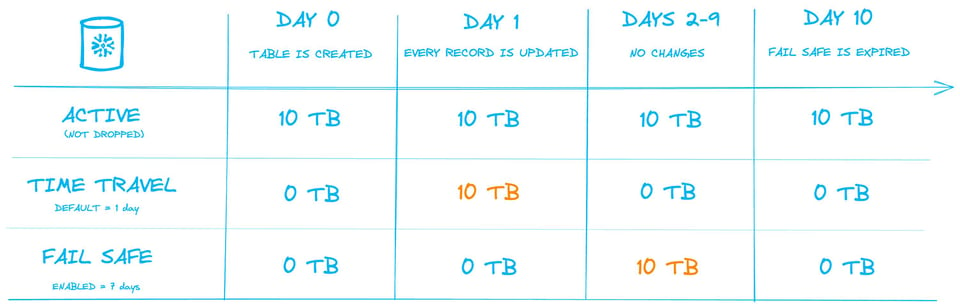
Die zentrale Erkenntnis: Obwohl sich die in der Tabelle gespeicherte Datenmenge nicht ändert, steigt der durchschnittliche tägliche Speicherverbrauch über den 10-Tages-Zeitraum auf 18 TB.
SQL-Beispiel
Wer dieses Verhalten selbst nachvollziehen möchte, kann das folgende SQL nutzen:
-- Create a permanent table
CREATE TABLE db.public.orders AS
SELECT *
FROM snowflake_sample_data.tpch_sf1.orders
;
CREATE OR REPLACE TEMPORARY TABLE db.public.stg AS (
SELECT
o_orderkey
, o_totalprice
FROM db.public.orders SAMPLE BLOCK (1) -- ensure all micro-partitions invloved
)
;
-- We run this code 15 times to update a sufficient number of micro-partitions
Code ausklappen
Tag 0: Alle modifizierten Tabellenversionen werden in Time Travel verschoben, die Größe der aktiven Tabelle bleibt gleich.

Tag 1–8: Time Travel ist vorbei, die Daten wandern in Fail-Safe.
Zusammenfassung & Konsequenzen
Die zugrunde liegenden Micro-Partitions jeder Snowflake-Tabelle lassen sich in drei Zustände einteilen: "aktiv", "in Time Travel" oder "in Fail-Safe". Schreiboperationen auf der Tabelle lösen im Hintergrund das Anlegen einer "neuen Table Version" aus – die alten, mit der vorherigen Version verknüpften Micro-Partitions durchlaufen dann die Time-Travel- und Fail-Safe-Zeiträume.
Wie gezeigt, kann das Ändern einer großen Anzahl von Datensätzen oder das häufige Aktualisieren weniger Datensätze in einer permanenten Tabelle zu deutlich höheren Speicherkosten führen, da die veralteten Micro-Partitions erst Time Travel und Fail-Safe durchlaufen müssen, bevor sie endgültig entfernt werden.
Wie berechnet Snowflake die Speicherkosten?
Snowflake rechnet proportional zur gespeicherten Datenmenge ab. Kunden zahlen monatlich für die durchschnittlich pro Tag gespeicherten komprimierten Daten (TB) in ihrem Account. Die gespeicherten Daten stammen aus vier Hauptquellen:
- Dateien in internen Snowflake-Stages (komprimiert / unkomprimiert)
- Tabellen über alle Datenbanken hinweg, inklusive zugehörigem Time-Travel-Zeitraum
- Fail-Safe-Storage für permanente Tabellen
- Geklonte Tabellen, die auf Dateien einer inzwischen modifizierten Tabelle verweisen
Wie im vorherigen Beitrag zur Snowflake-Architektur beschrieben, speichert Snowflake die Daten im Speicherdienst des zugrunde liegenden Cloud-Anbieters (S3 bei AWS, Blob bei Azure usw.). Snowflake gibt diese Kosten im Wesentlichen 1:1 weiter – berechnet wird also genau das, was der Cloud-Anbieter Snowflake für die Speicherung berechnet. Einen Aufschlag gibt es nicht.
Dank Snowflakes proprietärem Micro-Partition-Dateiformat lassen sich Kompressionsraten von mindestens 3:1 erreichen – damit ist die Speicherung in Snowflake deutlich günstiger, als die Daten selbst zu hosten.
Wie viel kostet Snowflake-Storage pro Terabyte?
Der Preis pro Terabyte hängt davon ab, ob Sie Snowflake On-Demand nutzen oder Kapazität im Voraus eingekauft haben. AWS in der Region US East (Northern Virginia) kostet beispielsweise 40 $/TB On-Demand und 23 $/TB bei vorab erworbener Kapazität. In der Praxis gibt es leichte Preisunterschiede zwischen Regionen und Plattformen, bedingt durch die Multi-Region-Architektur der Cloud-Anbieter und das Pass-Through-Pricing – Pazifik und Südamerika sind im Schnitt am teuersten. Die Preispläne für Storage finden Sie hier.
Wie lassen sich die monatlichen Speicherkosten schätzen?
Um die Berechnung zu veranschaulichen, betrachten wir ein Speichervolumen, das über einen 30-Tage-Zeitraum langsam wächst. Hier eine grobe Kostenabschätzung:
1Day – Total Storage
2Day 1 – 1 Tb
3Day 2 – 2 Tb
4Day 3 – 10 Tb
5Day 5 – 20 Tb
6...
7Day 30 – 20 Tb
8
9Average Daily Storage Calculation = (1 + 2 + 10 * 2 + 20 * (30 - 5)) / 30 ~ 17.4 Tb per day
10
11Based on US East AWS prices:
121. On-Demand = 40$/Tb * 17.4Tb = 696$
132. Contract = 23$/Tb * 17.4Tb = 400$
Durch den Wechsel von On-Demand auf einen bezahlten Vertrag lassen sich die Speicherkosten in diesem Beispiel auf AWS in US East sofort um 74 % senken!
Häufige Änderungen und Speicherkostenfallen
Häufige Datenänderungen können einen plötzlichen Sprung bei den Speicherkosten auslösen – auch wenn das aktive Datenvolumen unverändert bleibt. Sobald eine Tabelle aktualisiert wird, wandert die alte Table Version in den Retention-Zeitraum und wird durch die jetzt aktive Version ersetzt. Stündliche oder noch häufigere Updates, die einen Großteil der Micro-Partitions betreffen, treiben die Speicherkosten massiv in die Höhe. Schauen wir uns ein Extrembeispiel an, um mögliche Quellen unnötiger Kosten zu verdeutlichen.
Angenommen, wir haben 1 TB an permanenten Tabellen, die 3-mal täglich vollständig aktualisiert werden. Time Travel und Fail-Safe sind auf den Standardwerten 1 bzw. 7 Tage.
Wie wirkt sich das auf die täglich gespeicherten Bytes und damit auf die Gesamtkosten aus?
Input:
- Active storage, 1Tb
- Time-travel: 1 day
- Fail-Safe: 7 days
- Full data update 3 times per day
Formula:
Time-Travel = Modified * Times per day
Fail-Safe = Time-Travel * 7 days
Total Storage = Active + Time-Travel + Fail-safe
Calculations:
Time-Travel = (1Tb * 3 daily updates) = 3Tb
Fail-Safe = 3 Tb * 7 days = 21Tb
Total Storage = 1Tb + 3Tb + 21Tb = **25Tb (!)**
Obwohl wir nur 1 TB aktiven Storage haben, belegt unsere Tabelle 25 TB an Speicher – und wird entsprechend abgerechnet! Wer zusätzlich einen Service wie Automatic Clustering nutzt, der beim Reshuffeln der Daten laufend neue Micro-Partitions anlegt, sieht den Multiplikator noch weiter steigen.
Vermeiden Sie wo immer möglich häufige Tabellenupdates, die eine große Anzahl an Micro-Partitions in permanenten Tabellen betreffen. Wo das nicht geht, sollten Sie transiente Tabellen in Erwägung ziehen oder den Time-Travel-Zeitraum reduzieren, um unnötige Kosten zu vermeiden. Sind Ihre Daten ohnehin schon im Cloud Storage oder in einem anderen System gesichert – brauchen Sie dann wirklich zusätzliche Backup-Kopien in Snowflake?
Speicherkosten optimieren und senken
Nachdem wir ein grundlegendes Verständnis davon entwickelt haben, wie Daten in Snowflake gespeichert werden und wie abgerechnet wird, schauen wir uns einige Wege an, die Speicherkosten zu optimieren und unangenehme Überraschungen durch plötzliche Spitzen zu vermeiden.
Data-Retention-Zeiträume minimieren
Den Data-Retention-Zeitraum (Time Travel) zu reduzieren, ist ein einfacher Hebel, um Speicherkosten zu senken.
Unsere klare Empfehlung lautet vor allem: Deaktivieren Sie Time Travel (auf 0 setzen) für alle transienten und temporären Tabellen. Diese Tabellen werden regelmäßig gelöscht und neu angelegt – ein Backup ihrer Daten ist in den meisten Fällen unnötig. Wenn Ihre Daten ohnehin anderswo gesichert sind, sollten Sie zudem überlegen, permanente Tabellen in transiente umzuwandeln, um unnötige Ausgaben für Fail-Safe- und Time-Travel-Backups zu vermeiden.
Zweitens: Halten Sie den Time-Travel-Retention-Zeitraum so kurz wie möglich. Müssen Sie wirklich noch 90 Tage später auf gelöschte Daten zugreifen können? Oder reichen 7 Tage?
Update-Frequenz reduzieren
Wir haben – wenn auch zugespitzt – gezeigt, welche Auswirkungen hochfrequente Updates auf Time Travel und Fail-Safe haben können. Häufige Tabellenupdates in Kombination mit den Standard-Retention-Einstellungen führen unabhängig vom konkreten Szenario zu enormen Datenmengen. Mehrere Kopien der Originaldatensätze vorzuhalten, lässt den Speicherbedarf um Größenordnungen anwachsen.
Ungenutzte Tabellen löschen
Die offensichtlichste – und wahrscheinlich eine der effektivsten – Strategien ist es, unnötige Daten loszuwerden. Jeder kennt die Situation: Daten werden mit Blick auf künftige Pläne ins Warehouse geladen und dann nie wieder angefasst. Ian hat ausführlich beschrieben, wie sich ungenutzte Tabellen identifizieren lassen – ein klarer Lesetipp, um die besten Vorgehensweisen kennenzulernen.
Cloning mit Bedacht einsetzen
Direkt nach dem Klonen einer Tabelle fallen keine zusätzlichen Speicherkosten an. Wird die Originaltabelle jedoch gelöscht oder aktualisiert, hält die geklonte Version weiter an den gelöschten bzw. aktualisierten Micro-Partitions fest und
set clone_group_id = (
select distinct clone_group_id
from snowflake.account_usage.table_storage_metrics
where table_name = 'TEST_TABLE'
and table_catalog = 'STAGING'
)
;
select
id,
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name,
id != clone_group_id as is_cloned
from snowflake.account_usage.table_storage_metrics
where clone_group_id = $clone_group_id
;
verursacht so Speicherkosten.
Beim Droppen einer Tabelle lohnt sich ein Blick darauf, ob Klone existieren – und ob diese ebenfalls gedroppt werden sollten. Dazu lässt sich das Feld clone_group_id in der View table_storage_metrics nutzen. Es bildet die Beziehung zwischen Original- und Klontabellen ab. Mit folgendem Skript lassen sich beispielsweise alle Klone einer Tabelle auflisten:
Wie überwacht man die Snowflake-Speicherkosten?
Snowflake-Kunden haben Zugriff auf eine Reihe von System-Views, die verschiedene Aspekte der Account-Nutzung und der Snowflake-Objekte abdecken. Diese Views liegen im Schema account_usage.
Speicherkosten pro Tabelle überwachen
Die View table_storage_metrics lässt sich abfragen, um die Speicherkosten pro Tabelle zu ermitteln. Verfügbar sind unter anderem der aktuelle Zustand jeder Tabelle, die Bytegröße, der Cloning-Status, das Schema und der Tabellentyp. Damit lassen sich – wie zuvor im Beitrag gezeigt – aktive, Time-Travel-, Fail-Safe- oder für Klone reservierte Bytes einzeln aufschlüsseln und nachverfolgen.
Ian hat bereits erklärt, wie die Identifizierung ungenutzter Tabellen in Kombination mit den Speicherkosten aus table_storage_metrics eine zentrale Rolle dabei spielt, unnötige Storage-Kosten aufzudecken.
Hier ein Beispiel-Query, wie sich table_storage_metrics nutzen lässt:
use role accountadmin;
select
id as table_id, -- unique table identifier
id != clone_group_id as is_cloned -- if table is a clone
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name, -- full name
active_bytes,
time_travel_bytes,
failsafe_bytes,
retained_for_clone_bytes,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) / power(1024, 4) as total_storage_tb, -- storage in tbs
Code ausklappen
Snapshots von table_storage_metrics
Die View table_storage_metrics enthält nur die aktuellen Tabellennutzungsdaten – wird eine Tabelle endgültig gelöscht, sind die zugehörigen Datensätze nicht mehr vorhanden. Um Tabellen-Storage-Metriken über die Zeit nachzuverfolgen, müssen Nutzer die View stündlich oder täglich snapshotten und darauf aufbauend eigene Logik implementieren.
Aggregierte Speicherkosten über die Zeit überwachen
Ein vereinfachter Ansatz, mit dem Kunden sämtliche Daten – einschließlich der von internen Stages genutzten – verfolgen können. Die Kehrseite: Die Granularität ist auf Account-Ebene begrenzt, detaillierte Reports sind damit nicht möglich.
Kunden können die View storage_usage nutzen, um die täglichen Speicherkosten auf Account-Ebene zu überwachen. Weitere Details finden Sie hier.
select
reader_account_name,
usage_date,
storage_bytes, -- all storage including time travel
stage_bytes, -- internal stages bytes
failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Ein granularerer Ansatz, um die Speicherkosten im Account zu verstehen, ist die View database_storage_usage_history, die Speicherkosten auf Datenbankebene zeigt. Zu beachten: Der Verbrauch interner Stages wird in dieser View nicht erfasst. Weitere Details finden sich in der Snowflake-Dokumentation.
select
usage_date,
database_id,
database_name,
deleted, -- if database is active
average_database_bytes, -- all storage including time travel
average_failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Andrey Bystrov · Analytics Engineer bei Deliveroo
Andrey ist ein erfahrener Data Practitioner und arbeitet aktuell als Analytics Engineer bei Deliveroo. Seine Leidenschaft gilt Data Modelling und SQL-Optimierung. Er kennt die Snowflake-Plattform in der Tiefe und nutzt dieses Wissen, um seinem Team beim Aufbau performanter und kosteneffizienter Data Pipelines zu helfen. Andrey teilt seine Erkenntnisse regelmäßig mit der Community.