Il formato di storage proprietario di Snowflake permette di archiviare i dati in modo estremamente efficiente ed economico. Per la maggior parte dei clienti Snowflake, i costi di storage incidono in genere per meno del 20% sulla spesa complessiva. Nonostante questo, esistono spesso opportunità significative di ottimizzazione che consentono di ridurre l'utilizzo superfluo.
In questo articolo analizziamo la struttura dei costi e il pricing dello storage Snowflake, le tecniche di ottimizzazione e le modalità di monitoraggio dei costi. Non trattiamo le external tables di Snowflake, che consentono di archiviare e interrogare dati esterni a Snowflake.
Architettura Snowflake in sintesi
Come abbiamo visto nel precedente articolo sull'architettura di Snowflake, Snowflake gestisce e scala in modo indipendente le risorse di storage e di compute.
Tutte le tabelle del layer di storage si basano sul formato proprietario delle micro-partition. Le micro-partition sono piccoli file di dati immutabili (<16MB compressi) con i metadati memorizzati nell'header. Trattandosi di file immutabili, aggiornare anche una singola riga in una micro-partition richiede la creazione di un'intera nuova micro-partition. Se ciò avviene di frequente e su larga scala, le ricadute sui costi possono essere notevoli, come vedremo più avanti.
Anche se compute e storage sono al centro dell'attenzione, anche il layer Cloud Services svolge un ruolo chiave nella gestione dei metadati associati a ciascuna tabella, abilitando funzionalità di storage di rilievo come Time Travel, Fail-Safe e Zero Copy Cloning.
Concetti di storage in Snowflake
Come evidenziato nel recente articolo sui merge in Snowflake, il disaccoppiamento tra storage e cloud services ha aperto la strada al concetto di versione di tabella. Ciò significa che ogni tabella è definita da un timestamp di creazione associato, da un insieme di micro-partition collegate e da statistiche pre-calcolate per ciascuna micro-partition. In questo modo, una tabella può essere intesa come un insieme di puntatori ai metadati che la descrivono.
L'immagine seguente illustra il concetto, mostrando i collegamenti tra le tabelle e i dati fisici (le micro-partition). La Tabella A e la Tabella B (un clone della A) condividono esattamente le stesse partition. La Tabella C, anch'essa un clone, condivide le stesse micro-partition più una nuova creata in seguito a una modifica dei dati (ad esempio l'inserimento di nuovi record).
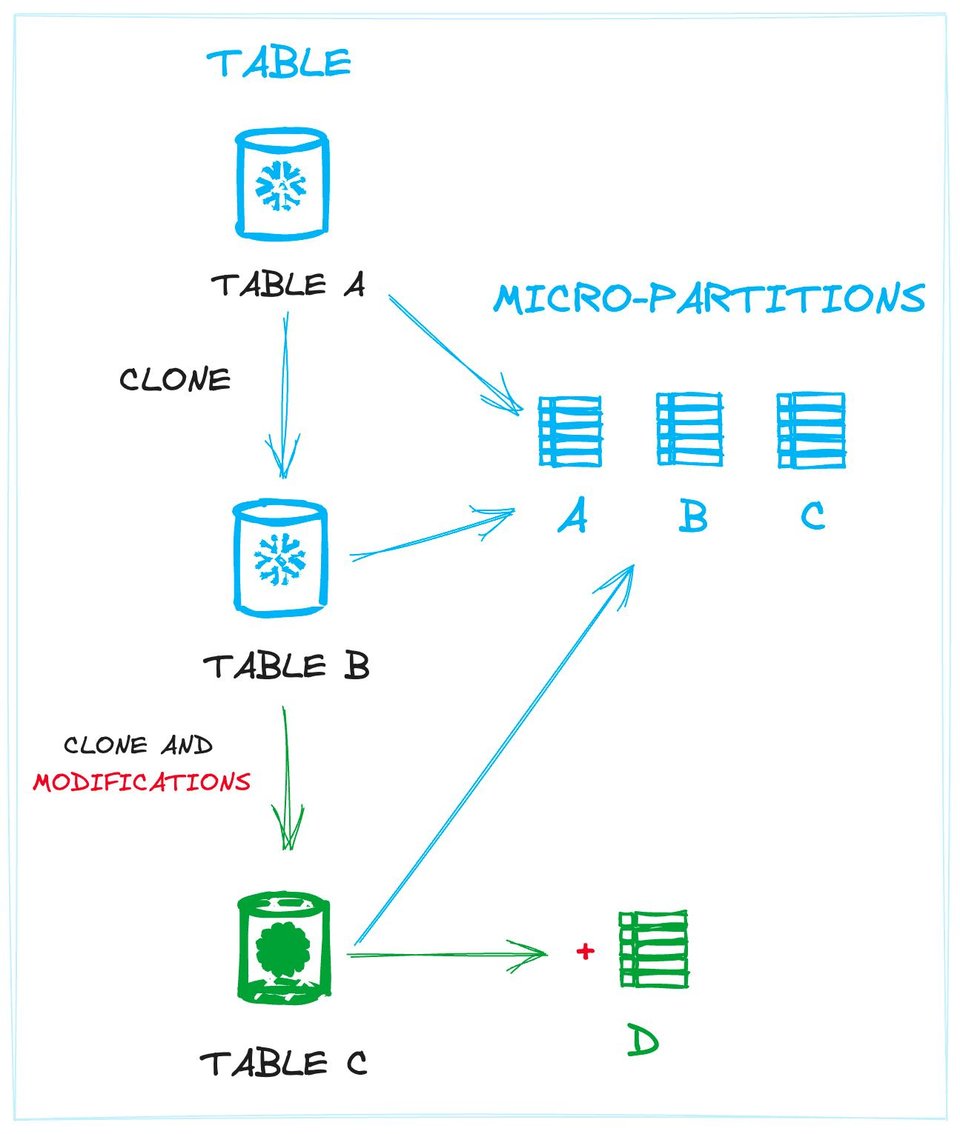
Definire le tabelle come una raccolta di micro-partition consente a Snowflake di evitare operazioni superflue su disco, perché le nuove tabelle possono essere collegate a micro-partition già esistenti ogniqualvolta è possibile. Questo disaccoppiamento permette di creare più tabelle distinte che condividono lo stesso insieme di file fisici, come avviene proprio durante lo zero-copy cloning.
La struttura di storage di Snowflake consente di offrire una serie di funzionalità di Continuous Data Protection (CDP), disponibili per tutti i clienti. La CDP comprende Time-Travel, Fail-Safe e Zero-Copy Cloning, funzionalità che approfondiamo di seguito.
Time Travel
Time Travel, noto anche come "data retention", aiuta a proteggere i dati. La sua funzione principale è eseguire il backup dei dati (più precisamente, delle micro-partition) per un periodo determinato. Come effetto collaterale, consente di tornare indietro nel tempo per interrogare, ricreare o ripristinare (un-drop) oggetti, utilizzando i dati di un determinato momento storico.
Per impostazione predefinita, Time Travel è impostato su 1 giorno ed è disponibile per tutti i clienti, indipendentemente dall'edizione di Snowflake. Nell'edizione Snowflake Standard, Time Travel può essere impostato a 0 (disabilitato) oppure lasciato al valore predefinito di 1 giorno. Nell'edizione Snowflake Enterprise, il periodo di retention può essere esteso fino a 90 giorni per gli oggetti permanenti. Le tabelle transient e temporary sono invece limitate a 1 giorno per tutti i clienti.
Time Travel si configura tramite il parametro DATA_RETENTION_TIME_IN_DAYS. Ne parliamo più nel dettaglio nella sezione dedicata all'ottimizzazione.
Interrogare le tabelle a un momento preciso nel tempo
AT OR BEFORE è un'astrazione sintattica che consente di tornare indietro nel tempo e ripristinare i dati così come erano in un determinato periodo. Offre numerose opzioni per individuare il punto storico, quindi consigliamo di consultare la documentazione ufficiale per imparare a usare correttamente questi operatori. Ecco una query di esempio:
select
user_name,
feature_enabled_status
from users at(timestamp => 'Fri, 01 May 2023 17:20:00 -0700'::timestamp)
where
user_id = 5
;
Ripristinare una tabella eliminata per errore
Con Time Travel, eliminare per sbaglio una tabella, uno schema o un database importanti, l'incubo di ogni data engineer, non è più un problema. Si possono ripristinare facilmente se rientrano ancora nel periodo di retention. Qui trovate alcuni dettagli su questa funzionalità, ma ecco un rapido esempio di come ripristinare un'ipotetica tabella users eliminata per errore:
1undrop table db.analytics.users
Configurare Time Travel
Time Travel può essere configurato a diversi livelli: account, database, schema o tabella. Segue una struttura gerarchica annidata, quindi se viene definito a livello di tabella ha la priorità su qualsiasi impostazione effettuata a livello di schema, database o account.
DATA_RETENTION_TIME_IN_DAYS è il parametro che governa il comportamento di Time Travel. Per capire le proprie impostazioni di time travel, conviene partire dai valori predefiniti a livello di account, database e schema.
1show parameters like '%DATA_RETENTION_TIME_IN_DAYS%' in {account, database, schema, table}
Proviamo ora a gestire la configurazione di retention all'interno del nostro progetto:
-- global config, account level
alter account set data_retention_time_in_days = 0;
-- unless stated downstream (schema or table),
-- all tables in the dbs have 1-day window
create or replace database staging_db data_retention_time_in_days=1;
use database staging_db;
-- unless stated downstream (table),
-- time travel is disabled for the tables in the schema
create or replace schema staging_schema data_retention_time_in_days=0;
use schema staging_schema;
-- create a table with time-travel of 1 day
create table test_table_zero (
Espandi codice
Come anticipato, l'esplicito ha sempre la meglio sull'implicito: se occorre controllare il comportamento per un oggetto specifico basta usare il parametro nello statement di creazione, altrimenti si lascia il controllo alle impostazioni di configurazione globali.
Fail Safe
Lo storage Fail-Safe è l'ultima linea di difesa. È accessibile esclusivamente a Snowflake ed entra in gioco solo al termine del periodo di retention. È l'ultimo momento utile prima che i dati vengano definitivamente rimossi e diventino inaccessibili. Non è configurabile e ha una durata di 7 giorni, tranne che per le tabelle transient o temporary, per le quali Fail Safe non viene affatto utilizzato.
Fail-Safe è concepito come soluzione di ultima istanza in senso stretto. Secondo la documentazione di Snowflake:
Fail-safe non è pensato come strumento per accedere ai dati storici dopo il termine del periodo di retention di Time Travel. È destinato esclusivamente all'uso da parte di Snowflake per recuperare dati eventualmente perduti o danneggiati a seguito di guasti operativi estremi.
Zero Copy Cloning
Lo Zero-Copy Cloning permette di creare una copia degli oggetti in pochi secondi, indipendentemente dalle loro dimensioni. Clonare una tabella in Snowflake non è un'operazione di creazione di file di database che porta a memorizzare nuovi dati su disco: si tratta semplicemente di un'operazione sui metadati che avviene nei Cloud Services, definendo un nuovo oggetto con puntatori alle micro-partition esistenti della tabella di origine.
Subito dopo la clonazione di una tabella non si registrano nuovi costi di storage, perché sia la tabella originale sia quella clonata puntano esattamente allo stesso insieme di micro-partition. Tuttavia, se tutti i record della tabella originale venissero aggiornati, i costi di storage raddoppierebbero: la tabella clonata continuerebbe infatti a puntare ai vecchi file di micro-partition (appena aggiornati), costringendo a mantenerli e generando di conseguenza costi di storage.
Il ciclo di vita di una tabella in Snowflake
Ora che abbiamo introdotto concetti di storage importanti come Time Travel e Fail Safe, vediamo come una tabella permanente attraversa il proprio ciclo di vita predefinito, mettendo in evidenza i diversi periodi di time-travel e fail safe.
L'immagine seguente mostra il processo. Consideriamo una tabella permanente da 10 Tb di dati, con Time Travel predefinito di 1 giorno abilitato e Fail Safe di 7 giorni. Viene rappresentato un intervallo di 10 giorni, comprese le quantità di storage che verrebbero addebitate ogni giorno.
Il Giorno 1 viene eseguita un'operazione che aggiorna ogni record della tabella, di fatto ricreando tutte le micro-partition. I 10 Tb di vecchie micro-partition entrano nello storage "Time Travel", dove gli utenti possono ancora accedere ai dati per le 24 ore successive.
Il giorno dopo, i 10 Tb di dati sono usciti da Time Travel e si trovano nello storage Fail Safe per i 7 giorni successivi.
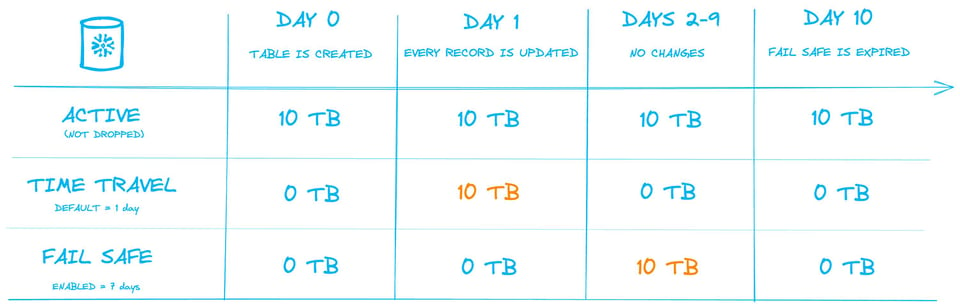
Il punto chiave è che, pur non cambiando la quantità di dati memorizzati nella tabella, il consumo medio giornaliero di storage nell'arco dei 10 giorni è salito a 18 Tb.
Esempio SQL
Per verificare in prima persona questo comportamento, è possibile utilizzare il codice SQL seguente:
-- Create a permanent table
CREATE TABLE db.public.orders AS
SELECT *
FROM snowflake_sample_data.tpch_sf1.orders
;
CREATE OR REPLACE TEMPORARY TABLE db.public.stg AS (
SELECT
o_orderkey
, o_totalprice
FROM db.public.orders SAMPLE BLOCK (1) -- ensure all micro-partitions invloved
)
;
-- We run this code 15 times to update a sufficient number of micro-partitions
Espandi codice
Giorno 0: tutte le versioni di tabella modificate vengono spostate in Time Travel, la dimensione della tabella attiva resta invariata

Giorni 1-8: Time Travel è terminato e i dati vengono spostati in Fail Safe
Sintesi e implicazioni
Le micro-partition sottostanti di ogni tabella Snowflake possono essere considerate "attive", "in time-travel" o "in fail safe". Le operazioni di scrittura sulla tabella innescano dietro le quinte la creazione di una "nuova versione della tabella", facendo passare le vecchie micro-partition associate alla versione precedente attraverso i periodi di time travel e fail-safe.
Come mostrato sopra, modificare un gran numero di record o aggiornare frequentemente un piccolo numero di record in una tabella permanente può comportare costi di storage molto più alti, perché le micro-partition obsolete devono attraversare i periodi di time travel e fail safe prima di essere completamente rimosse.
Come fattura lo storage Snowflake?
Snowflake fattura in proporzione alla quantità di dati memorizzati. I clienti pagano per la media giornaliera di dati compressi (Tb) archiviati nel proprio account, su base mensile. I dati memorizzati provengono da quattro fonti principali:
- File negli stage interni di Snowflake (compressi / non compressi)
- Tabelle nei vari database, incluso il relativo periodo di Time Travel
- Storage Fail-Safe per le tabelle permanenti
- Tabelle clonate che fanno riferimento a file di una tabella successivamente modificata
Come accennato nel precedente articolo sull'architettura Snowflake, Snowflake memorizza i dati nel servizio di storage del cloud provider sottostante (S3 per AWS, Blob per Azure, ecc.). Applica sostanzialmente un pricing pass-through: fattura cioè quanto il cloud provider sottostante addebita a Snowflake per memorizzare i dati. Gli utenti non pagano alcun sovrapprezzo rispetto a quanto pagherebbero normalmente.
Grazie al formato proprietario delle micro-partition, Snowflake riesce a raggiungere rapporti di compressione di almeno 3:1, rendendo i costi di storage molto più bassi rispetto a una gestione in autonomia dei dati.
Quanto costa lo storage Snowflake al terabyte?
Il prezzo al terabyte di Snowflake varia a seconda che si utilizzi Snowflake on-demand o che la capacità sia stata pagata in anticipo. Ad esempio, su AWS nella regione US East (Northern Virginia) il costo è di 40$/Tb on-demand e 23$/Tb per la capacità prepagata. In realtà esistono lievi differenze di prezzo tra regioni e piattaforme, dovute all'architettura multi-regione dei cloud provider che si riflette in un pricing pass-through, con Pacifico e Sud America in media tra i più costosi. I piani tariffari di storage sono consultabili qui.
Come stimare i costi mensili di storage?
Per illustrare come calcolare i costi di storage, consideriamo un volume di storage che cresce lentamente nell'arco di 30 giorni. Ecco una stima di massima dei costi:
1Day – Total Storage
2Day 1 – 1 Tb
3Day 2 – 2 Tb
4Day 3 – 10 Tb
5Day 5 – 20 Tb
6...
7Day 30 – 20 Tb
8
9Average Daily Storage Calculation = (1 + 2 + 10 * 2 + 20 * (30 - 5)) / 30 ~ 17.4 Tb per day
10
11Based on US East AWS prices:
121. On-Demand = 40$/Tb * 17.4Tb = 696$
132. Contract = 23$/Tb * 17.4Tb = 400$
Passando dall'on-demand a un contratto a pagamento, in questo esempio su AWS in US East i costi di storage si riducono immediatamente del 74%!
Modifiche frequenti e trappole dei costi di storage
Cambiamenti frequenti ai dati possono causare un'impennata improvvisa dei costi di storage, anche se il volume dei dati attivi resta invariato. Non appena viene eseguito un aggiornamento sulla tabella, la vecchia versione passa al periodo di retention ed è sostituita da quella ora attiva. Aggiornamenti orari o ancora più frequenti che coinvolgono una quota rilevante delle micro-partition fanno crescere notevolmente i costi di storage. Vediamo un caso estremo per illustrare le potenziali fonti di costi superflui.
Supponiamo di avere 1 Tb di tabelle permanenti aggiornate completamente 3 volte al giorno, con i periodi predefiniti di Time Travel e Fail Safe impostati rispettivamente a 1 e 7 giorni.
Come influisce tutto questo sui byte giornalieri di storage e, di conseguenza, sul costo totale?
Input:
- Active storage, 1Tb
- Time-travel: 1 day
- Fail-Safe: 7 days
- Full data update 3 times per day
Formula:
Time-Travel = Modified * Times per day
Fail-Safe = Time-Travel * 7 days
Total Storage = Active + Time-Travel + Fail-safe
Calculations:
Time-Travel = (1Tb * 3 daily updates) = 3Tb
Fail-Safe = 3 Tb * 7 days = 21Tb
Total Storage = 1Tb + 3Tb + 21Tb = **25Tb (!)**
Pur disponendo di appena 1 Tb di storage attivo, la nostra tabella sta consumando, e di conseguenza viene fatturata, per 25 Tb di storage! Se utilizzate un servizio come l'Automatic Clustering, che crea spesso nuove micro-partition mentre riorganizza i dati, il moltiplicatore può crescere ulteriormente.
Ove possibile, evitate aggiornamenti frequenti delle tabelle permanenti che coinvolgono molte micro-partition. In alternativa, valutate l'uso di tabelle transient o riducete il periodo di Time Travel (retention) per evitare costi inutili. Se i dati sono già sottoposti a backup su un cloud storage o su un altro sistema, ha davvero senso pagare anche per copie di backup aggiuntive in Snowflake?
Ottimizzare e ridurre i costi di storage
Ora che abbiamo costruito una comprensione di base di come Snowflake memorizza i dati e di come vengono fatturati, vediamo alcuni modi per ottimizzare i costi di storage e prevenire le brutte sorprese dovute a picchi improvvisi.
Ridurre al minimo i periodi di data retention
Ridurre il periodo di data retention (time travel) è un modo semplice per abbassare i costi di storage.
Innanzitutto, la nostra forte raccomandazione è di disabilitare Time-Travel (impostandolo a 0) per tutte le tabelle transient e temporary. Queste tabelle vengono eliminate e ricreate con regolarità, quindi nella maggior parte dei casi non ha senso effettuare il backup dei loro dati. Se i dati sono già sottoposti a backup altrove, valutate anche di convertire le tabelle permanenti in transient, per evitare spese inutili in backup Fail Safe e Time Travel.
In secondo luogo, mantenete il periodo di retention di Time-Travel più breve possibile. Vi serve davvero poter accedere ai dati eliminati 90 giorni dopo? O bastano 7 giorni di accesso?
Ridurre la frequenza degli aggiornamenti
Abbiamo illustrato il potenziale impatto degli aggiornamenti ad alta frequenza sul comportamento di time travel e fail-safe, sia pure in modo volutamente esagerato. In ogni caso, aggiornamenti frequenti delle tabelle, uniti alla configurazione di retention predefinita, portano alla memorizzazione di un'enorme quantità di dati. Conservare più copie dei record originali fa crescere i requisiti di storage di ordini di grandezza.
Eliminare le tabelle inutilizzate
La strategia più ovvia, ma probabilmente tra le più efficaci, è liberarsi dei dati superflui. Ci siamo trovati tutti in situazioni in cui i dati vengono caricati nel warehouse pensando a possibili usi futuri, salvo poi restare inutilizzati per sempre. Ian ha spiegato nel dettaglio come identificare le tabelle inutilizzate in Snowflake, quindi consigliamo vivamente di leggere quell'articolo per scoprire le strategie migliori.
Usare il cloning con cautela
Subito dopo la clonazione di una tabella non si registrano costi di storage aggiuntivi. Tuttavia, se la tabella originale viene eliminata o aggiornata, la versione clonata continuerà a trattenere le micro-partition eliminate/aggiornate e
set clone_group_id = (
select distinct clone_group_id
from snowflake.account_usage.table_storage_metrics
where table_name = 'TEST_TABLE'
and table_catalog = 'STAGING'
)
;
select
id,
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name,
id != clone_group_id as is_cloned
from snowflake.account_usage.table_storage_metrics
where clone_group_id = $clone_group_id
;
genererà costi di storage.
Quando si elimina una tabella, vale la pena verificare se esistono cloni e se è il caso di eliminare anche quelli. A questo scopo si può sfruttare il campo clone_group_id nella view table_storage_metrics. Questo campo rappresenta la relazione tra tabelle originali e clonate. Ad esempio, è possibile elencare tutti i cloni di una tabella con il seguente script:
Come monitorare i costi di storage di Snowflake?
I clienti Snowflake hanno accesso a numerose system view che coprono diversi aspetti dell'utilizzo dell'account e degli oggetti Snowflake. Queste view si trovano nello schema account_usage.
Monitorare i costi di storage delle tabelle
La view table_storage_metrics può essere interrogata per conoscere i costi di storage per ciascuna tabella. Stato attuale di ogni tabella, dimensione in byte, stato di cloning, schema, tipo di tabella e molto altro sono a disposizione dell'utente finale. La tabella può servire a scomporre e tracciare singolarmente i byte attivi, in time-travel, in fail-safe o trattenuti per i cloni, come mostrato in precedenza nell'articolo.
Ian ha già spiegato come l'individuazione delle tabelle inutilizzate, insieme ai costi di storage ricavati da table_storage_metrics, abbia un ruolo importante nello scovare costi di storage superflui.
Ecco una query di esempio che mostra come utilizzare table_storage_metrics:
use role accountadmin;
select
id as table_id, -- unique table identifier
id != clone_group_id as is_cloned -- if table is a clone
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name, -- full name
active_bytes,
time_travel_bytes,
failsafe_bytes,
retained_for_clone_bytes,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) / power(1024, 4) as total_storage_tb, -- storage in tbs
Espandi codice
Snapshot di table_storage_metrics
La view table_storage_metrics contiene i record di utilizzo corrente delle tabelle, quindi se si elimina correttamente una tabella i relativi record non saranno più presenti. Per monitorare le metriche di storage delle tabelle nel tempo è necessario creare uno snapshot della tabella con cadenza oraria o giornaliera e costruire su questa base una logica personalizzata.
Monitorare i costi di storage aggregati nel tempo
Un approccio semplificato consente ai clienti di tracciare tutti i dati, inclusi quelli usati dagli stage interni. Di contro, la granularità è limitata al livello di account, quindi non è possibile ottenere report più dettagliati.
I clienti possono utilizzare la view storage_usage per monitorare i costi giornalieri di storage a livello di account. Maggiori dettagli sono disponibili qui.
select
reader_account_name,
usage_date,
storage_bytes, -- all storage including time travel
stage_bytes, -- internal stages bytes
failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Un approccio più granulare per analizzare i costi di storage del proprio account consiste nell'utilizzare la view database_storage_usage_history, che mostra i costi di storage a livello di database. Va segnalato che il consumo degli stage interni non è incluso in questa view. Maggiori dettagli sono disponibili nella documentazione di Snowflake.
select
usage_date,
database_id,
database_name,
deleted, -- if database is active
average_database_bytes, -- all storage including time travel
average_failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Andrey Bystrov · Analytics Engineer presso Deliveroo
Andrey è un data practitioner esperto, attualmente Analytics Engineer presso Deliveroo. Nutre una forte passione per il data modelling e l'ottimizzazione SQL. Vanta una conoscenza approfondita della piattaforma Snowflake e mette queste competenze al servizio del suo team per costruire pipeline di dati performanti ed efficienti dal punto di vista dei costi. Appassionato della materia, condivide regolarmente con la community ciò che impara.