O formato de storage exclusivo do Snowflake permite armazenar dados de forma altamente eficiente e econômica. Para a maioria dos clientes do Snowflake, os custos de storage costumam representar menos de 20% do gasto total. Mesmo assim, quase sempre há oportunidades relevantes de otimização para reduzir o uso desnecessário.
Neste post, vamos mergulhar na estrutura de custos e no pricing de storage do Snowflake, em técnicas de otimização e em como monitorar custos. Não vamos abordar as external tables do Snowflake, recurso que permite armazenar e consultar dados fora do Snowflake.
Recapitulando a arquitetura do Snowflake
Como mostramos no post anterior sobre a arquitetura do Snowflake, o Snowflake gerencia e escala storage e compute de forma independente.
Todas as tabelas na camada de storage usam o formato de arquivo proprietário das micro-partitions do Snowflake. As micro-partitions são pequenos arquivos de dados imutáveis (<16MB comprimidos), com metadados armazenados no header. Como esses arquivos são imutáveis, atualizar uma única linha em uma micro-partition exige criar uma micro-partition totalmente nova. Feito com frequência e em escala, isso pode ter um impacto enorme nos custos, como veremos adiante.
Apesar de compute e storage receberem a maior parte da atenção, a camada de Cloud Services também tem papel fundamental no gerenciamento dos metadados de cada tabela, viabilizando recursos importantes como Time Travel, Fail-Safe e Zero Copy Cloning.
Conceitos de storage do Snowflake
Como destacamos no post recente sobre merges no Snowflake, o desacoplamento entre storage e cloud services abriu caminho para o conceito de versão de tabela. Ou seja, cada tabela é definida por um timestamp de criação associado, um conjunto de micro-partitions vinculadas e estatísticas pré-computadas para cada micro-partition. Nessa lógica, dá para pensar em uma tabela como um conjunto de ponteiros de metadados que a definem.
A imagem abaixo ilustra esse conceito. Aparecem os vínculos entre as tabelas e os dados físicos (micro-partitions). A Tabela A e a Tabela B (um clone de A) compartilham exatamente as mesmas partições. A Tabela C, também um clone, compartilha as mesmas micro-partitions e ainda tem uma nova, criada por uma modificação de dados (no caso, a inserção de novos registros).
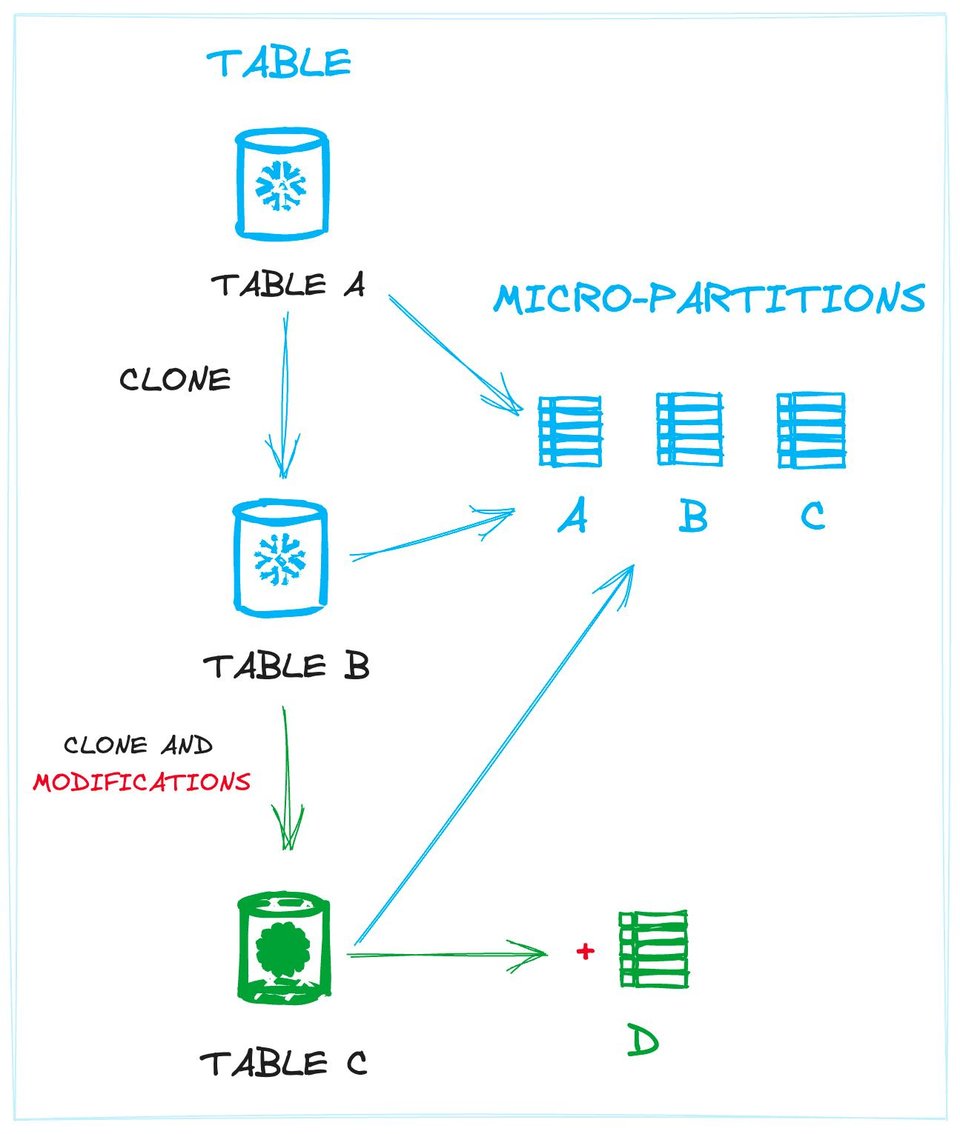
Definir tabelas como uma coleção de micro-partitions ajuda o Snowflake a evitar operações desnecessárias em disco, já que novas tabelas podem ser vinculadas a micro-partitions já existentes sempre que possível. Esse desacoplamento permite criar várias tabelas distintas que compartilham o mesmo conjunto de arquivos físicos, exatamente o que acontece no zero-copy cloning.
A estrutura de storage do Snowflake permite oferecer uma série de recursos de Continuous Data Protection (CDP), disponíveis para todos os clientes. O CDP é formado por Time-Travel, Fail-Safe e Zero-Copy Cloning, que vamos detalhar a seguir.
Time Travel
O Time Travel, também chamado de "retenção de dados", ajuda a proteger seus dados. Sua função principal é fazer backup dos dados (mais precisamente, das micro-partitions) por um período específico. Como efeito colateral, permite voltar no tempo para consultar, recriar ou recuperar objetos, usando os dados de um determinado momento.
O Time Travel vem configurado em 1 dia por padrão e está disponível para todos os clientes, independentemente da edição do Snowflake. Na edição Snowflake Standard, dá para configurar em 0 (desativado) ou manter o padrão de 1 dia. Na Snowflake Enterprise, o período de retenção pode chegar a 90 dias para objetos permanentes. Já as tabelas transient e temporary ficam limitadas a 1 dia para todos os clientes.
O Time Travel pode ser configurado pelo parâmetro DATA_RETENTION_TIME_IN_DAYS. Vamos detalhar isso mais adiante, na seção de otimização.
Consultando tabelas em um momento específico
O AT OR BEFORE é uma abstração de sintaxe que permite voltar no tempo e restaurar os dados como estavam em determinado período. Há várias opções para definir o ponto histórico, então confira a documentação oficial para usar esses operadores corretamente. Veja um exemplo de query:
select
user_name,
feature_enabled_status
from users at(timestamp => 'Fri, 01 May 2023 17:20:00 -0700'::timestamp)
where
user_id = 5
;
Restaurando uma tabela apagada por acidente
Com o Time Travel, apagar uma tabela, schema ou database importante deixou de ser pesadelo na vida do data engineer. Dá para restaurar facilmente, desde que ainda esteja dentro do período de retenção. Você encontra mais detalhes sobre essa funcionalidade, mas aqui vai um exemplo rápido de como restaurar uma hipotética tabela users apagada por engano:
1undrop table db.analytics.users
Configurando o Time Travel
O Time Travel pode ser configurado em diferentes níveis – account, database, schema ou table. Ele segue uma hierarquia aninhada, então, se for definido no nível da tabela, prevalece sobre qualquer configuração feita no nível de schema, database ou account.
DATA_RETENTION_TIME_IN_DAYS é o parâmetro que comanda o comportamento do Time Travel. Para entender as suas configurações de time travel, comece pelos defaults nos níveis de account, database e schema.
1show parameters like '%DATA_RETENTION_TIME_IN_DAYS%' in {account, database, schema, table}
Vamos colocar a mão na massa e ajustar a configuração de retenção no nosso projeto:
-- global config, account level
alter account set data_retention_time_in_days = 0;
-- unless stated downstream (schema or table),
-- all tables in the dbs have 1-day window
create or replace database staging_db data_retention_time_in_days=1;
use database staging_db;
-- unless stated downstream (table),
-- time travel is disabled for the tables in the schema
create or replace schema staging_schema data_retention_time_in_days=0;
use schema staging_schema;
-- create a table with time-travel of 1 day
create table test_table_zero (
Expandir código
Como já dissemos, o explícito sempre vence o implícito. Então, se precisar controlar um objeto específico, use o parâmetro no statement de create; caso contrário, deixe nas mãos das configurações globais.
Fail Safe
O storage Fail-Safe é a última linha de defesa. Só o Snowflake tem acesso a ele, e ele só entra em ação depois do período de retenção. É o último estágio antes de os dados serem completamente removidos e se tornarem inacessíveis. Não é configurável e dura 7 dias, exceto para tabelas transient ou temporary, casos em que o Fail Safe nem chega a ser usado.
O Fail-Safe foi pensado como recurso de último caso mesmo. Segundo a documentação do Snowflake:
O Fail-safe não é oferecido como forma de acessar dados históricos depois que o período de retenção do Time Travel termina. Ele é de uso exclusivo do Snowflake, para recuperar dados que possam ter sido perdidos ou danificados por falhas operacionais extremas.
Zero Copy Cloning
O Zero-Copy Cloning permite criar cópias de objetos em segundos, independentemente do tamanho. Clonar uma tabela no Snowflake não é uma operação de criação de arquivo de banco de dados que gera novos dados em disco. É apenas uma operação de metadados que acontece em Cloud Services, definindo um novo objeto com ponteiros para as micro-partitions existentes da tabela clonada.
Logo após clonar uma tabela, não há novos custos de storage, porque tanto a tabela pai quanto a clonada apontam para exatamente o mesmo conjunto de micro-partitions. Mas, se todos os registros da tabela pai forem atualizados, os custos de storage dobram, já que a tabela clonada continua apontando para os arquivos antigos de micro-partitions (que acabaram de ser atualizados) e precisa que eles continuem existindo, gerando cobrança de storage.
O ciclo de vida de uma tabela no Snowflake
Agora que apresentamos conceitos importantes de storage como Time Travel e Fail Safe, vamos mostrar como uma tabela permanente percorre o ciclo de vida padrão, destacando os diferentes períodos de time-travel e fail safe.
A imagem abaixo ilustra esse processo. Considere uma tabela permanente com 10 Tb de dados, com o Time Travel padrão de 1 dia ativado e Fail Safe de 7 dias. O intervalo mostrado é de 10 dias, com as quantidades de storage que seriam cobradas em cada dia.
No Dia 1, uma operação atualiza todos os registros da tabela, o que na prática faz com que cada micro-partition seja recriada. Os 10 Tb das micro-partitions antigas entram no storage de "Time Travel", onde os dados ainda ficam acessíveis pelas próximas 24 horas.
No dia seguinte, os 10 Tb saem do Time Travel e passam para o storage de Fail Safe pelos próximos 7 dias.
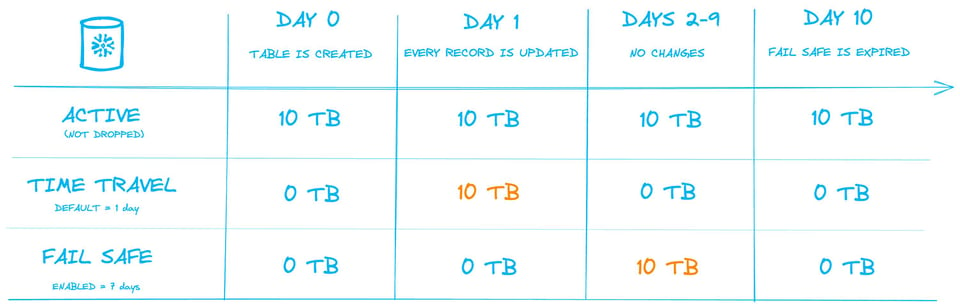
A grande sacada é que, apesar de o volume de dados armazenados na tabela não mudar, o consumo médio diário de storage nos 10 dias subiu para 18 Tb.
Exemplo em SQL
Se quiser validar esse comportamento por conta própria, é só usar o SQL abaixo:
-- Create a permanent table
CREATE TABLE db.public.orders AS
SELECT *
FROM snowflake_sample_data.tpch_sf1.orders
;
CREATE OR REPLACE TEMPORARY TABLE db.public.stg AS (
SELECT
o_orderkey
, o_totalprice
FROM db.public.orders SAMPLE BLOCK (1) -- ensure all micro-partitions invloved
)
;
-- We run this code 15 times to update a sufficient number of micro-partitions
Expandir código
Dia 0: todas as versões modificadas da tabela vão para o Time Travel, e o tamanho da tabela ativa segue o mesmo

Dias 1-8: o Time Travel acaba e os dados passam para o Fail Safe
Resumo e implicações
As micro-partitions de cada tabela do Snowflake podem estar em um de três estados: "ativas", "em time-travel" ou em "fail safe". Operações de escrita na tabela disparam, nos bastidores, a criação de uma "nova versão da tabela", o que faz as micro-partitions antigas associadas à versão anterior percorrerem os períodos de time travel e fail-safe.
Como vimos acima, modificar um grande volume de registros, ou atualizar com frequência um pequeno volume, em uma tabela permanente pode elevar bastante os custos de storage, já que as micro-partitions desatualizadas precisam circular pelo time travel e pelo fail safe antes de serem removidas de vez.
Como o Snowflake cobra pelo storage?
O Snowflake cobra proporcionalmente ao volume de dados armazenados. A cobrança é feita mensalmente, com base na média diária de dados comprimidos (Tb) armazenados na sua conta. Os dados armazenados vêm de quatro fontes principais:
- Arquivos em internal stages do Snowflake (comprimidos / não comprimidos)
- Tabelas em databases, incluindo o respectivo período de Time Travel
- Storage Fail-Safe para tabelas permanentes
- Tabelas clonadas que referenciam arquivos de uma tabela que foi modificada desde então
Como vimos no post anterior sobre a arquitetura do Snowflake, ele armazena seus dados no serviço de storage do provedor de nuvem subjacente (S3 na AWS, Blob no Azure, etc.). O Snowflake basicamente repassa o preço (pass-through pricing): cobra de você o mesmo valor que o provedor de nuvem cobra dele para armazenar os dados. Não há nenhum prêmio acima do que você pagaria normalmente.
Com o formato proprietário de arquivo micro-partition do Snowflake, é possível atingir taxas de compressão de pelo menos 3:1, o que torna o armazenamento dos dados muito mais barato do que guardá-los por conta própria.
Quanto custa o storage do Snowflake por terabyte?
O preço por terabyte no Snowflake varia conforme o uso seja on-demand ou se você já pagou capacidade antecipadamente. Por exemplo, na AWS em US East (Northern Virginia), o custo é de US$ 40/Tb on-demand e US$ 23/Tb para capacidade pré-comprada. Na prática, há pequenas diferenças de preço entre regiões e plataformas, por causa da arquitetura multirregião dos provedores de nuvem, que se reflete no pass-through pricing — Pacífico e América do Sul são, em média, as regiões mais caras. Você pode consultar os planos de preços de storage aqui.
Como estimar as despesas mensais de storage?
Para mostrar como calcular as despesas de storage, vamos considerar um volume crescendo aos poucos ao longo de 30 dias. Aqui vai uma estimativa aproximada dos custos:
1Dia – Storage total
2Dia 1 – 1 Tb
3Dia 2 – 2 Tb
4Dia 3 – 10 Tb
5Dia 5 – 20 Tb
6...
7Dia 30 – 20 Tb
8
9Cálculo da média diária de storage = (1 + 2 + 10 * 2 + 20 * (30 - 5)) / 30 ~ 17,4 Tb por dia
10
11Com base nos preços da AWS em US East:
121. On-Demand = US$ 40/Tb * 17,4Tb = US$ 696
132. Contrato = US$ 23/Tb * 17,4Tb = US$ 400
Ao migrar de on-demand para um contrato pago, neste exemplo, você já reduz os custos de storage em 74% na AWS em US East!
Modificações frequentes e armadilhas nos custos de storage
Mudanças frequentes nos dados podem provocar variações repentinas nos custos de storage, mesmo quando o volume de dados ativos continua o mesmo. Assim que uma tabela é atualizada, a versão antiga vai para o período de retenção e dá lugar à nova versão ativa. Atualizações de hora em hora (ou ainda mais frequentes) que afetam grande parte das micro-partitions elevam bastante o seu custo de storage. Vamos analisar um caso extremo para deixar claro de onde podem surgir custos desnecessários.
Suponha que você tenha 1 Tb de tabelas permanentes totalmente atualizadas 3 vezes por dia, com os períodos padrão de Time Travel e Fail Safe definidos em 1 e 7 dias, respectivamente.
Como isso afeta o tamanho diário em bytes do storage e, por consequência, o custo total?
Entrada:
- Storage ativo, 1Tb
- Time-travel: 1 dia
- Fail-Safe: 7 dias
- Atualização completa dos dados 3 vezes por dia
Fórmula:
Time-Travel = Modificado * Vezes por dia
Fail-Safe = Time-Travel * 7 dias
Storage Total = Ativo + Time-Travel + Fail-safe
Cálculos:
Time-Travel = (1Tb * 3 atualizações diárias) = 3Tb
Fail-Safe = 3 Tb * 7 dias = 21Tb
Storage Total = 1Tb + 3Tb + 21Tb = **25Tb (!)**
Mesmo com apenas 1Tb de storage ativo, a tabela está consumindo — e sendo cobrada — por 25 Tb de storage! Se você usa algo como Automatic Clustering, que cria novas micro-partitions com frequência ao reorganizar os dados, esse multiplicador pode ser ainda maior.
Sempre que possível, evite atualizações frequentes que afetem um grande número de micro-partitions em tabelas permanentes. Se não der para evitar, considere usar tabelas transient ou reduzir o período de Time Travel (retenção) para fugir de custos desnecessários. Se seus dados já têm backup em cloud storage ou em outro sistema, faz sentido pagar por cópias adicionais de backup no Snowflake também?
Otimizando e reduzindo custos de storage
Agora que já temos um entendimento sólido de como os dados são armazenados no Snowflake e de como funciona a cobrança, vamos ver algumas formas de otimizar seus custos de storage e evitar surpresas com picos repentinos.
Reduza os períodos de retenção de dados
Reduzir o período de retenção de dados (time travel) é uma forma simples de baixar os custos de storage.
Antes de mais nada, recomendamos fortemente desativar o Time-Travel (defina como 0) em todas as tabelas transient e temporary. Essas tabelas são apagadas e recriadas com frequência, então, na maioria dos casos, não faz sentido fazer backup dos dados. Se você já tem backup dos dados em outro lugar, considere também converter suas tabelas permanentes em transient para evitar gastos desnecessários com Fail Safe e Time Travel.
Em segundo lugar, mantenha o período de retenção do Time-Travel o mais baixo possível. Você precisa mesmo acessar dados deletados 90 dias depois? Ou 7 dias já resolvem?
Reduza a frequência de atualizações
Mostramos o impacto que atualizações de alta frequência podem ter no comportamento de time travel e fail-safe, ainda que de forma um tanto exagerada. De todo modo, atualizações frequentes em tabelas, combinadas com a configuração padrão de retenção, resultam em um volume enorme de dados armazenados. Guardar várias cópias dos registros originais aumenta os requisitos de storage em ordens de magnitude.
Apague tabelas que não estão sendo usadas
A estratégia mais óbvia, mas provavelmente uma das mais eficazes, é se livrar dos dados desnecessários. Todo mundo já passou por aquela situação em que os dados são carregados no warehouse pensando em planos futuros e ficam intocados para sempre. O Ian explicou em detalhes como identificar tabelas não utilizadas no Snowflake, então recomendo muito conferir o post para conhecer as melhores formas de fazer isso.
Use clonagem com cautela
Logo após clonar uma tabela, não há custos extras de storage. Mas, se a tabela original for apagada ou atualizada, a versão clonada continuará segurando as micro-partitions deletadas/atualizadas e
set clone_group_id = (
select distinct clone_group_id
from snowflake.account_usage.table_storage_metrics
where table_name = 'TEST_TABLE'
and table_catalog = 'STAGING'
)
;
select
id,
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name,
id != clone_group_id as is_cloned
from snowflake.account_usage.table_storage_metrics
where clone_group_id = $clone_group_id
;
vai gerar custos de storage.
Ao dropar uma tabela, vale checar se existem clones e se eles também devem ser dropados. Para isso, dá para usar o campo clone_group_id na view table_storage_metrics. Esse campo reflete a relação entre as tabelas originais e suas clonadas. Por exemplo, você pode listar todos os clones de uma tabela com o script abaixo:
Como monitorar os custos de storage do Snowflake?
Os clientes do Snowflake têm acesso a várias system views que cobrem diferentes aspectos do uso da conta e dos objetos do Snowflake. Essas views ficam no schema account_usage.
Monitorando custos de storage por tabela
A view table_storage_metrics pode ser consultada para descobrir os custos de storage por tabela. O estado atual de cada tabela, tamanho em bytes, status de clonagem, schema, tipo de tabela e muito mais ficam disponíveis para o usuário final. Dá para usar essa tabela para abrir e acompanhar individualmente os bytes ativos, em time-travel, em fail-safe ou retidos por clonagem, como mostramos antes no post.
O Ian já explicou como a identificação de tabelas não utilizadas, somada aos custos de storage da table_storage_metrics, é peça-chave para encontrar custos de storage desnecessários.
Veja um exemplo de query mostrando como usar a table_storage_metrics:
use role accountadmin;
select
id as table_id, -- unique table identifier
id != clone_group_id as is_cloned -- if table is a clone
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name, -- full name
active_bytes,
time_travel_bytes,
failsafe_bytes,
retained_for_clone_bytes,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) / power(1024, 4) as total_storage_tb, -- storage in tbs
Expandir código
Snapshot da table_storage_metrics
A view table_storage_metrics só traz registros atuais de uso das tabelas. Ou seja, se você apagar a tabela do jeito certo, os registros somem. Para acompanhar as métricas de storage por tabela ao longo do tempo, é preciso fazer snapshot dessa view em cadência horária ou diária e construir uma lógica customizada por cima.
Monitorando custos agregados de storage ao longo do tempo
Uma abordagem mais simples permite acompanhar todos os dados, incluindo o que é usado pelas internal stages. Em compensação, a granularidade dos dados fica limitada ao nível de account, então não dá para gerar relatórios mais detalhados.
Os clientes podem usar a view storage_usage para monitorar os custos diários de storage no nível de account. Veja mais detalhes aqui.
select
reader_account_name,
usage_date,
storage_bytes, -- all storage including time travel
stage_bytes, -- internal stages bytes
failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Uma abordagem mais granular para entender os custos de storage da sua conta é usar a view database_storage_usage_history, que mostra os custos de storage no nível de database. Vale observar que o consumo das internal stages não entra nessa view. Mais detalhes na documentação do Snowflake.
select
usage_date,
database_id,
database_name,
deleted, -- if database is active
average_database_bytes, -- all storage including time travel
average_failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Andrey Bystrov·Analytics Engineer na Deliveroo
Andrey é um profissional experiente em dados, atualmente Analytics Engineer na Deliveroo. Ele tem grande paixão por modelagem de dados e otimização de SQL. Conhece a fundo a plataforma Snowflake e usa esse conhecimento para ajudar o time a construir data pipelines performáticos e econômicos. Andrey adora o tema e compartilha seus aprendizados com a comunidade com frequência.