El formato de almacenamiento único de Snowflake permite guardar datos de forma muy eficiente y a bajo costo. Para la mayoría de los clientes de Snowflake, el almacenamiento suele representar menos del 20% del gasto total. Aun así, casi siempre hay oportunidades importantes de optimización que se pueden aprovechar para reducir el uso innecesario.
En este artículo entramos a fondo en la estructura de costos y los precios del almacenamiento en Snowflake, las técnicas de optimización y cómo monitorear los costos. No abordamos las external tables de Snowflake, que permiten almacenar y consultar datos fuera de la plataforma.
Repaso de la arquitectura de Snowflake
Como ya vimos en nuestro artículo anterior sobre la arquitectura de Snowflake, la plataforma gestiona y escala los recursos de almacenamiento y cómputo de forma independiente.
Todas las tablas de la capa de almacenamiento usan el formato propietario de micro-particiones de Snowflake. Las micro-particiones son archivos pequeños e inmutables (menos de 16 MB comprimidos) con los metadatos guardados en la cabecera. Como son inmutables, actualizar una sola fila dentro de una micro-partición obliga a crear una micro-partición nueva por completo. Si esto se hace con frecuencia y a gran escala, el impacto en costos puede ser importante, como veremos más adelante.
Aunque el cómputo y el almacenamiento suelen llevarse toda la atención, la capa de Cloud Services también cumple un rol clave: administra los metadatos asociados a cada tabla y habilita funcionalidades tan importantes como Time Travel, Fail-Safe y Zero Copy Cloning.
Conceptos de almacenamiento en Snowflake
Como se señaló en el artículo reciente sobre los merges en Snowflake, el desacople entre almacenamiento y servicios en la nube abrió la puerta al concepto de versión de tabla. Esto significa que cada tabla se define por un timestamp de creación asociado, un conjunto de micro-particiones vinculadas y estadísticas precalculadas para cada micro-partición. Visto así, una tabla es básicamente un conjunto de punteros de metadatos que la describen.
La imagen siguiente ilustra el concepto. Se muestran los vínculos entre las tablas y los datos físicos (micro-particiones). La Tabla A y la Tabla B (un clon de A) comparten exactamente las mismas particiones. La Tabla C, también un clon, comparte esas mismas micro-particiones más una nueva creada por una modificación de datos (es decir, la inserción de nuevos registros).
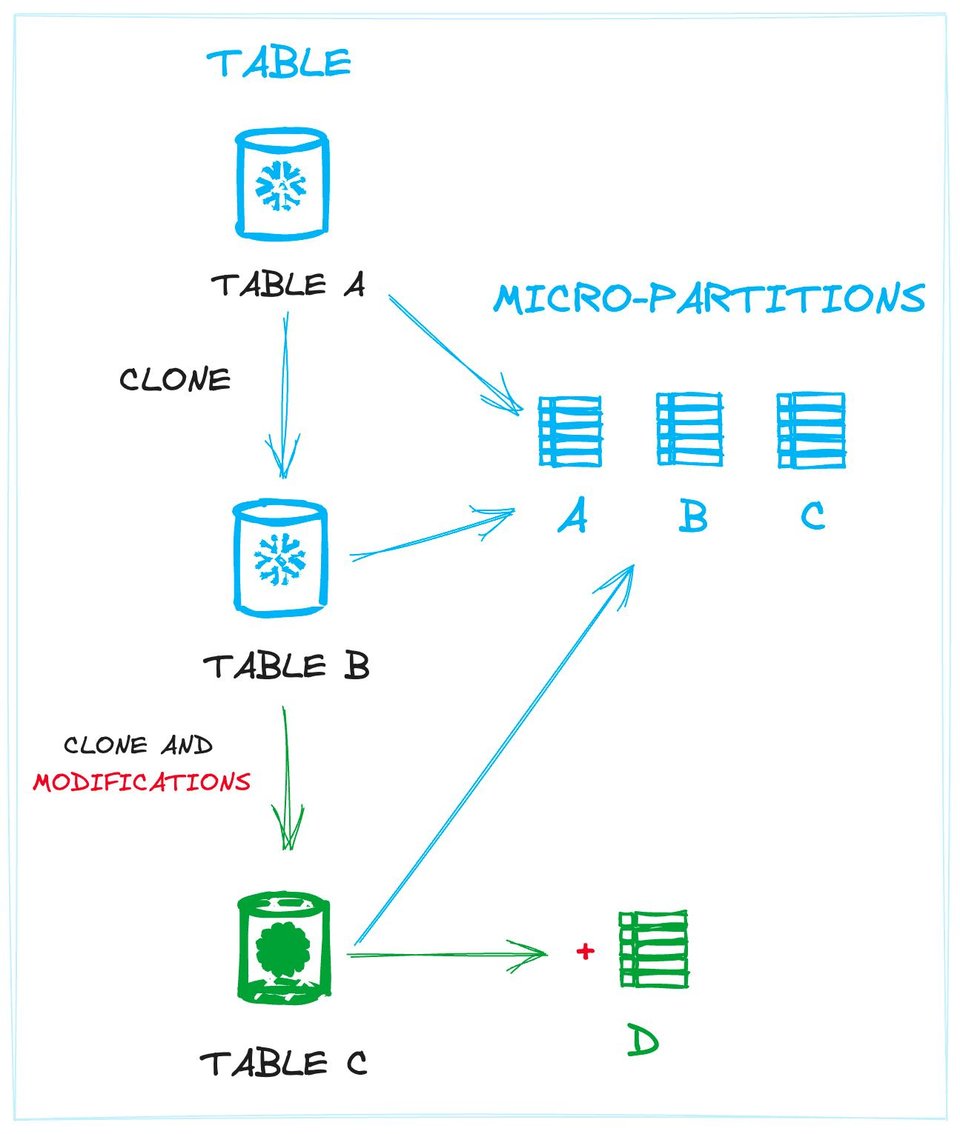
Definir las tablas como una colección de micro-particiones le permite a Snowflake evitar operaciones innecesarias en disco, porque las nuevas tablas pueden enlazarse a micro-particiones ya existentes siempre que sea posible. Este desacople permite crear varias tablas únicas que comparten el mismo conjunto de archivos físicos, justo lo que ocurre al hacer zero-copy cloning.
La estructura de almacenamiento de Snowflake le permite ofrecer un conjunto de funcionalidades de Continuous Data Protection (CDP), disponibles para todos los clientes. CDP incluye Time-Travel, Fail-Safe y Zero-Copy Cloning, que revisaremos a continuación.
Time Travel
Time Travel, también conocido como "data retention", ayuda a proteger los datos. Su función principal es respaldar datos (más exactamente, micro-particiones) durante un período determinado. Como efecto secundario, te permite viajar al pasado para consultar, recrear o recuperar objetos eliminados, usando los datos tal como estaban en un momento específico.
Time Travel viene configurado en 1 día por defecto y está disponible para todos los clientes, sin importar la edición de Snowflake. En Snowflake Standard se puede dejar en 0 (desactivado) o en el valor por defecto de 1 día. En Snowflake Enterprise Edition, el período de retención puede extenderse hasta 90 días para objetos permanentes. Las tablas transient y temporary están limitadas a 1 día para todos los clientes.
Time Travel se configura con el parámetro DATA_RETENTION_TIME_IN_DAYS. Lo vemos en más detalle más adelante, en la sección de optimización.
Consultar tablas en un punto específico del tiempo
AT OR BEFORE es una abstracción de sintaxis que te permite viajar al pasado y recuperar los datos tal como estaban en un período determinado. Tiene muchas opciones para precisar el punto histórico, así que conviene revisar la documentación oficial para saber cómo usar estos operadores correctamente. Acá va un ejemplo:
select
user_name,
feature_enabled_status
from users at(timestamp => 'Fri, 01 May 2023 17:20:00 -0700'::timestamp)
where
user_id = 5
;
Restaurar una tabla eliminada por accidente
Con Time Travel, borrar por error una tabla, esquema o base de datos importante deja de ser una pesadilla para los equipos de data engineering. Se puede restaurar fácilmente si todavía está dentro del período de retención. Acá tienes algunos detalles sobre esta funcionalidad, y un ejemplo rápido de cómo restaurar una hipotética tabla users eliminada por accidente:
1undrop table db.analytics.users
Configurar Time Travel
Time Travel se puede configurar en distintos niveles: cuenta, base de datos, esquema o tabla. Sigue un anidamiento jerárquico, así que si se define a nivel de tabla, esa configuración prevalece sobre cualquier ajuste hecho a nivel de esquema, base de datos o cuenta.
DATA_RETENTION_TIME_IN_DAYS es el parámetro que controla el comportamiento de Time Travel. Para entender tu configuración, empieza por revisar los valores por defecto a nivel de cuenta, base de datos y esquema.
1show parameters like '%DATA_RETENTION_TIME_IN_DAYS%' in {account, database, schema, table}
Probemos esto y ajustemos la configuración de retención en nuestro proyecto:
-- global config, account level
alter account set data_retention_time_in_days = 0;
-- unless stated downstream (schema or table),
-- all tables in the dbs have 1-day window
create or replace database staging_db data_retention_time_in_days=1;
use database staging_db;
-- unless stated downstream (table),
-- time travel is disabled for the tables in the schema
create or replace schema staging_schema data_retention_time_in_days=0;
use schema staging_schema;
-- create a table with time-travel of 1 day
create table test_table_zero (
Expand Code
Como decíamos, lo explícito siempre prevalece sobre lo implícito: si necesitas controlarlo para un objeto puntual, usa el parámetro en la sentencia create; de lo contrario, deja que lo gobiernen los ajustes globales.
Fail Safe
El almacenamiento Fail-Safe es la última línea de defensa. Solo es accesible para Snowflake y entra en juego únicamente después del período de retención. Es el último momento antes de que los datos se eliminen por completo y queden inaccesibles. No es configurable y dura 7 días, salvo en las tablas transient o temporary, donde Fail Safe no se aplica.
Fail-Safe está pensado como un recurso de último momento. Según la documentación de Snowflake:
Fail-safe no se provee como medio para acceder a datos históricos una vez terminado el período de retención de Time Travel. Es solo para uso de Snowflake, para recuperar datos que se hayan perdido o dañado por fallas operativas extremas.
Zero Copy Cloning
Zero-Copy Cloning te permite crear copias de objetos en segundos, sin importar su tamaño. Clonar una tabla en Snowflake no es una operación de creación de archivos de base de datos que genere datos nuevos en disco. Es, en realidad, una operación de metadatos que ocurre en Cloud Services, donde se define un nuevo objeto con punteros a las micro-particiones existentes de la tabla original.
Inmediatamente después de clonar una tabla no hay costos de almacenamiento adicionales, porque tanto la tabla padre como la clonada apuntan exactamente al mismo conjunto de micro-particiones. Pero si se actualizaran todos los registros de la tabla padre, los costos de almacenamiento se duplicarían: la tabla clonada seguirá apuntando a los archivos antiguos de micro-particiones (los que se acaban de actualizar) y obligará a mantenerlos vigentes, generando cargos de almacenamiento.
El ciclo de vida de una tabla en Snowflake
Ahora que ya presentamos conceptos importantes de almacenamiento como Time Travel y Fail Safe, veamos cómo una tabla permanente recorre un ciclo de vida por defecto, destacando los distintos períodos de time-travel y fail safe.
La imagen a continuación muestra el proceso. Tomamos una tabla permanente con 10 Tb de datos, con Time Travel activado en 1 día por defecto y 7 días de Fail Safe. Se muestra un intervalo de 10 días, incluyendo el almacenamiento que se facturaría cada día.
En el Día 1 se ejecuta una operación que actualiza todos los registros de la tabla, lo que provoca que se recree cada micro-partición. Los 10 Tb de micro-particiones antiguas pasan al almacenamiento de "Time Travel", donde aún se puede acceder a los datos durante las próximas 24 horas.
Al día siguiente, esos 10 Tb salen de Time Travel y entran al almacenamiento Fail Safe por los siguientes 7 días.
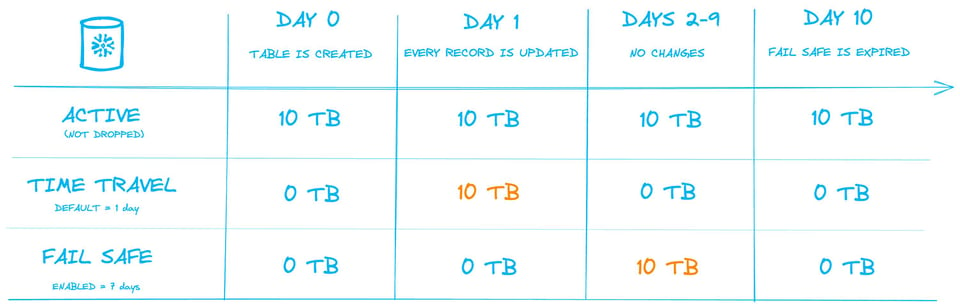
La conclusión clave es que, aunque la cantidad de datos almacenados en la tabla no cambia, el consumo diario promedio de almacenamiento en el período de 10 días sube a 18 Tb.
Ejemplo SQL
Si quieres validar este comportamiento por tu cuenta, puedes usar el siguiente SQL:
-- Create a permanent table
CREATE TABLE db.public.orders AS
SELECT *
FROM snowflake_sample_data.tpch_sf1.orders
;
CREATE OR REPLACE TEMPORARY TABLE db.public.stg AS (
SELECT
o_orderkey
, o_totalprice
FROM db.public.orders SAMPLE BLOCK (1) -- ensure all micro-partitions invloved
)
;
-- We run this code 15 times to update a sufficient number of micro-partitions
Expand Code
Día 0: todas las versiones modificadas de la tabla pasan a Time Travel; el tamaño activo de la tabla se mantiene igual

Día 1-8: termina Time Travel y los datos pasan a Fail Safe
Resumen e implicaciones
Las micro-particiones que están detrás de cada tabla de Snowflake pueden considerarse "activas", "en time-travel" o "en fail safe". Las operaciones de escritura sobre la tabla disparan la creación de una "nueva versión de tabla" en segundo plano, lo que hace que las micro-particiones antiguas de la versión anterior atraviesen los períodos de time travel y fail-safe.
Como ya vimos, modificar una gran cantidad de registros o actualizar con frecuencia un número pequeño de registros en una tabla permanente puede derivar en costos de almacenamiento bastante más altos, porque las micro-particiones obsoletas deben recorrer los períodos de time travel y fail safe antes de eliminarse por completo.
¿Cómo cobra Snowflake el almacenamiento?
Snowflake te cobra de forma proporcional a la cantidad de datos almacenados. A los clientes se les factura mensualmente por el promedio diario de datos comprimidos (Tb) guardados en su cuenta. Los datos almacenados provienen de cuatro fuentes principales:
- Archivos en internal Snowflake stages (comprimidos o sin comprimir)
- Tablas en todas las bases de datos, incluyendo el período de Time Travel correspondiente
- Almacenamiento Fail-Safe para tablas permanentes
- Tablas clonadas que referencian archivos de una tabla que fue modificada después
Como ya comentamos en el artículo anterior sobre la arquitectura de Snowflake, Snowflake guarda tus datos en el servicio de almacenamiento del proveedor de nube subyacente (S3 en AWS, Blob en Azure, etc.). Aplica básicamente precios pass-through: te cobra lo mismo que el proveedor de nube le cobra a Snowflake por almacenar los datos. No pagas un sobreprecio más allá de lo que pagarías de manera habitual.
Gracias a su formato propietario de micro-particiones, Snowflake puede alcanzar ratios de compresión de al menos 3:1, lo que hace que almacenar datos salga bastante más barato que hacerlo por tu cuenta.
¿Cuánto cuesta el almacenamiento de Snowflake por terabyte?
El precio por terabyte en Snowflake varía según uses Snowflake on-demand o hayas pagado capacidad por adelantado. Por ejemplo, AWS en US East (Northern Virginia) cuesta $40/Tb on demand y $23/Tb para capacidad pre-comprada. En la práctica hay pequeñas diferencias de precio entre regiones y plataformas, derivadas de la arquitectura multi-región de los proveedores de nube y del modelo pass-through, donde el Pacífico y Sudamérica son en promedio los más caros. Puedes revisar los planes de precios de almacenamiento aquí.
¿Cómo estimar el gasto mensual de almacenamiento?
Para mostrar cómo calcular el gasto de almacenamiento, tomemos un volumen que crece lentamente durante 30 días. Acá va una estimación aproximada de los costos:
1Day – Total Storage
2Day 1 – 1 Tb
3Day 2 – 2 Tb
4Day 3 – 10 Tb
5Day 5 – 20 Tb
6...
7Day 30 – 20 Tb
8
9Average Daily Storage Calculation = (1 + 2 + 10 * 2 + 20 * (30 - 5)) / 30 ~ 17.4 Tb per day
10
11Based on US East AWS prices:
121. On-Demand = 40$/Tb * 17.4Tb = 696$
132. Contract = 23$/Tb * 17.4Tb = 400$
¡Al pasar de on-demand a un contrato pagado, en este ejemplo en AWS US East puedes reducir tus costos de almacenamiento de inmediato en un 74%!
Modificaciones frecuentes y trampas en los costos de almacenamiento
Los cambios frecuentes en los datos pueden provocar un salto repentino en los costos de almacenamiento, aunque el volumen de datos activos siga siendo el mismo. Apenas se hace una actualización en una tabla, la versión antigua pasa al período de retención y queda reemplazada por la que ahora está activa. Las actualizaciones cada hora o más frecuentes que afectan a una buena parte de las micro-particiones disparan el costo de almacenamiento. Veamos un caso extremo para mostrar de dónde pueden venir esos costos innecesarios.
Supongamos que tenemos Tb de tablas permanentes que se actualizan por completo 3 veces al día, con los períodos por defecto de Time Travel y Fail Safe configurados en 1 y 7 días, respectivamente.
¿Cómo afecta esto al tamaño diario en bytes del almacenamiento y, en consecuencia, al costo total?
Input:
- Active storage, 1Tb
- Time-travel: 1 day
- Fail-Safe: 7 days
- Full data update 3 times per day
Formula:
Time-Travel = Modified * Times per day
Fail-Safe = Time-Travel * 7 days
Total Storage = Active + Time-Travel + Fail-safe
Calculations:
Time-Travel = (1Tb * 3 daily updates) = 3Tb
Fail-Safe = 3 Tb * 7 days = 21Tb
Total Storage = 1Tb + 3Tb + 21Tb = **25Tb (!)**
¡Aunque solo tenemos 1Tb de almacenamiento activo, nuestra tabla está consumiendo —y por lo tanto facturando— 25 Tb! Si encima usas un servicio como Automatic Clustering, que crea con frecuencia nuevas micro-particiones al reorganizar los datos, ese múltiplo puede ser todavía mayor.
Siempre que se pueda, evita las actualizaciones frecuentes que afecten a un gran número de micro-particiones en tablas permanentes. Si no es posible, considera usar tablas transient o reducir el período de Time Travel (retención) para evitar costos innecesarios. Si tus datos ya están respaldados en cloud storage o en otro sistema, ¿realmente necesitas pagar también por copias de respaldo adicionales en Snowflake?
Optimización y reducción de los costos de almacenamiento
Ahora que ya tenemos una base sólida sobre cómo se almacenan los datos en Snowflake y cómo se cobran, veamos algunas formas de optimizar el costo de almacenamiento y evitar sorpresas por picos repentinos.
Minimiza los períodos de retención de datos
Reducir el período de retención de datos (time travel) es una forma sencilla de bajar el costo de almacenamiento.
Antes que nada, nuestra recomendación firme es desactivar Time-Travel (ponerlo en 0) en todas las tablas transient y temporary. Estas tablas se eliminan y recrean con regularidad, así que en la mayoría de los casos no hace falta respaldar sus datos. Si tus datos ya están respaldados en otro lado, considera también pasar tus tablas permanentes a transient para no gastar de más en respaldos de Fail Safe y Time Travel.
En segundo lugar, mantén el período de retención de Time-Travel lo más bajo posible. ¿De verdad necesitas acceder a datos eliminados 90 días después? ¿O te alcanza con conservar el acceso por 7 días?
Minimiza la frecuencia de actualización
Ya ilustramos el impacto que pueden tener las actualizaciones de alta frecuencia sobre el comportamiento de time travel y fail-safe, aunque de manera bastante exagerada. De cualquier modo, las actualizaciones frecuentes sumadas a la configuración de retención por defecto generan una cantidad enorme de datos almacenados. Guardar múltiples copias de los registros originales aumenta las necesidades de almacenamiento en órdenes de magnitud.
Elimina tablas que no se usan
La estrategia más obvia, pero probablemente una de las más efectivas, es deshacerte de los datos innecesarios. Todos hemos pasado por la situación de cargar datos al warehouse pensando en planes a futuro que después nunca llegan. Ian explicó con detalle cómo identificar tablas que no se usan en Snowflake, así que te recomiendo mucho revisar ese artículo para conocer las mejores formas de hacerlo.
Usa la clonación con criterio
Apenas se clona una tabla no hay costos adicionales de almacenamiento. Sin embargo, si la tabla original se elimina o actualiza, la versión clonada seguirá reteniendo las micro-particiones eliminadas o actualizadas y
set clone_group_id = (
select distinct clone_group_id
from snowflake.account_usage.table_storage_metrics
where table_name = 'TEST_TABLE'
and table_catalog = 'STAGING'
)
;
select
id,
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name,
id != clone_group_id as is_cloned
from snowflake.account_usage.table_storage_metrics
where clone_group_id = $clone_group_id
;
generará costos de almacenamiento.
Al eliminar una tabla, vale la pena revisar si existen clones y si también deberían eliminarse. Para eso puedes aprovechar el campo clone_group_id de la vista table_storage_metrics, que refleja la relación entre tablas originales y clonadas. Por ejemplo, puedes listar todos los clones de una tabla con el siguiente script:
¿Cómo monitorear los costos de almacenamiento en Snowflake?
Los clientes de Snowflake tienen acceso a una serie de vistas del sistema que cubren distintos aspectos del uso de la cuenta y de los objetos de Snowflake. Estas vistas viven en el esquema account_usage.
Monitorear los costos de almacenamiento por tabla
La vista table_storage_metrics se puede consultar para conocer el costo de almacenamiento por tabla. El usuario final tiene acceso al estado actual de cada tabla, su tamaño en bytes, su estado de clonación, esquema, tipo de tabla y mucho más. La tabla sirve para desglosar y rastrear de forma individual los bytes activos, en time-travel, en fail-safe o retenidos por clonación, como se mostró antes en el artículo.
Ian ya explicó cómo la identificación de tablas no utilizadas, combinada con los costos de almacenamiento de table_storage_metrics, juega un papel importante a la hora de identificar gastos innecesarios.
Acá va un ejemplo de consulta que muestra cómo usar table_storage_metrics:
use role accountadmin;
select
id as table_id, -- unique table identifier
id != clone_group_id as is_cloned -- if table is a clone
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name, -- full name
active_bytes,
time_travel_bytes,
failsafe_bytes,
retained_for_clone_bytes,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) / power(1024, 4) as total_storage_tb, -- storage in tbs
Expand Code
Tomar snapshots de table_storage_metrics
La vista table_storage_metrics contiene registros del uso actual de las tablas, así que si eliminas correctamente una tabla, sus registros desaparecen de ahí. Para monitorear las métricas de almacenamiento a lo largo del tiempo, hay que tomar snapshots de la tabla con cadencia horaria o diaria y construir lógica personalizada sobre ese histórico.
Monitorear el costo agregado de almacenamiento en el tiempo
Es un enfoque simplificado que permite rastrear todos los datos, incluyendo los usados por internal stage. Como contrapartida, la granularidad se limita al nivel de cuenta, así que no puedes obtener reportes más detallados.
Los clientes pueden usar la vista storage_usage para monitorear el costo diario de almacenamiento a nivel de cuenta. Hay más detalles aquí.
select
reader_account_name,
usage_date,
storage_bytes, -- all storage including time travel
stage_bytes, -- internal stages bytes
failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Un enfoque más granular para entender el costo de almacenamiento en tu cuenta es usar la vista database_storage_usage_history, que muestra el costo a nivel de base de datos. Vale destacar que el consumo de los internal stages no se incluye en esta vista. Hay más detalles en la documentación de Snowflake.
select
usage_date,
database_id,
database_name,
deleted, -- if database is active
average_database_bytes, -- all storage including time travel
average_failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Andrey Bystrov·Analytics Engineer en Deliveroo
Andrey es un profesional de datos con amplia experiencia, que actualmente trabaja como Analytics Engineer en Deliveroo. Le apasionan el modelado de datos y la optimización de SQL. Tiene un conocimiento profundo de la plataforma Snowflake y lo usa para ayudar a su equipo a construir pipelines de datos eficientes en rendimiento y en costos. Le entusiasma el tema y comparte regularmente sus aprendizajes con la comunidad.